Apache spark pull latest #11
Commits on Dec 20, 2017
-
[SPARK-22832][ML] BisectingKMeans unpersist unused datasets
## What changes were proposed in this pull request? unpersist unused datasets ## How was this patch tested? existing tests and local check in Spark-Shell Author: Zheng RuiFeng <[email protected]> Closes #20017 from zhengruifeng/bkm_unpersist.
-
[SPARK-22849] ivy.retrieve pattern should also consider
classifier## What changes were proposed in this pull request? In the previous PR #5755 (comment), we dropped `(-[classifier])` from the retrieval pattern. We should add it back; otherwise, > If this pattern for instance doesn't has the [type] or [classifier] token, Ivy will download the source/javadoc artifacts to the same file as the regular jar. ## How was this patch tested? The existing tests Author: gatorsmile <[email protected]> Closes #20037 from gatorsmile/addClassifier.
-
[SPARK-22830] Scala Coding style has been improved in Spark Examples
## What changes were proposed in this pull request? * Under Spark Scala Examples: Some of the syntax were written like Java way, It has been re-written as per scala style guide. * Most of all changes are followed to println() statement. ## How was this patch tested? Since, All changes proposed are re-writing println statements in scala way, manual run used to test println. Author: chetkhatri <[email protected]> Closes #20016 from chetkhatri/scala-style-spark-examples.
-
[SPARK-22847][CORE] Remove redundant code in AppStatusListener while …
…assigning schedulingPool for stage ## What changes were proposed in this pull request? In AppStatusListener's onStageSubmitted(event: SparkListenerStageSubmitted) method, there are duplicate code: ``` // schedulingPool was assigned twice with the same code stage.schedulingPool = Option(event.properties).flatMap { p => Option(p.getProperty("spark.scheduler.pool")) }.getOrElse(SparkUI.DEFAULT_POOL_NAME) ... ... ... stage.schedulingPool = Option(event.properties).flatMap { p => Option(p.getProperty("spark.scheduler.pool")) }.getOrElse(SparkUI.DEFAULT_POOL_NAME) ``` But, it does not make any sense to do this and there are no comment to explain for this. ## How was this patch tested? N/A Author: wuyi <[email protected]> Closes #20033 from Ngone51/dev-spark-22847.
Commits on Dec 21, 2017
-
[SPARK-22845][SCHEDULER] Modify spark.kubernetes.allocation.batch.del…
…ay to take time instead of int ## What changes were proposed in this pull request? Fixing configuration that was taking an int which should take time. Discussion in #19946 (comment) Made the granularity milliseconds as opposed to seconds since there's a use-case for sub-second reactions to scale-up rapidly especially with dynamic allocation. ## How was this patch tested? TODO: manual run of integration tests against this PR. PTAL cc/ mccheah liyinan926 kimoonkim vanzin mridulm jiangxb1987 ueshin Author: foxish <[email protected]> Closes #20032 from foxish/fix-time-conf.
-
[SPARK-22810][ML][PYSPARK] Expose Python API for LinearRegression wit…
…h huber loss. ## What changes were proposed in this pull request? Expose Python API for _LinearRegression_ with _huber_ loss. ## How was this patch tested? Unit test. Author: Yanbo Liang <[email protected]> Closes #19994 from yanboliang/spark-22810.
-
[SPARK-22387][SQL] Propagate session configs to data source read/writ…
…e options ## What changes were proposed in this pull request? Introduce a new interface `SessionConfigSupport` for `DataSourceV2`, it can help to propagate session configs with the specified key-prefix to all data source operations in this session. ## How was this patch tested? Add new test suite `DataSourceV2UtilsSuite`. Author: Xingbo Jiang <[email protected]> Closes #19861 from jiangxb1987/datasource-configs.
-
[SPARK-19634][SQL][ML][FOLLOW-UP] Improve interface of dataframe vect…
…orized summarizer ## What changes were proposed in this pull request? Make several improvements in dataframe vectorized summarizer. 1. Make the summarizer return `Vector` type for all metrics (except "count"). It will return "WrappedArray" type before which won't be very convenient. 2. Make `MetricsAggregate` inherit `ImplicitCastInputTypes` trait. So it can check and implicitly cast input values. 3. Add "weight" parameter for all single metric method. 4. Update doc and improve the example code in doc. 5. Simplified test cases. ## How was this patch tested? Test added and simplified. Author: WeichenXu <[email protected]> Closes #19156 from WeichenXu123/improve_vec_summarizer.
-
[SPARK-22848][SQL] Eliminate mutable state from Stack
## What changes were proposed in this pull request? This PR eliminates mutable states from the generated code for `Stack`. ## How was this patch tested? Existing test suites Author: Kazuaki Ishizaki <[email protected]> Closes #20035 from kiszk/SPARK-22848.
-
[SPARK-22324][SQL][PYTHON] Upgrade Arrow to 0.8.0
## What changes were proposed in this pull request? Upgrade Spark to Arrow 0.8.0 for Java and Python. Also includes an upgrade of Netty to 4.1.17 to resolve dependency requirements. The highlights that pertain to Spark for the update from Arrow versoin 0.4.1 to 0.8.0 include: * Java refactoring for more simple API * Java reduced heap usage and streamlined hot code paths * Type support for DecimalType, ArrayType * Improved type casting support in Python * Simplified type checking in Python ## How was this patch tested? Existing tests Author: Bryan Cutler <[email protected]> Author: Shixiong Zhu <[email protected]> Closes #19884 from BryanCutler/arrow-upgrade-080-SPARK-22324.
-
[SPARK-22852][BUILD] Exclude -Xlint:unchecked from sbt javadoc flags
## What changes were proposed in this pull request? Moves the -Xlint:unchecked flag in the sbt build configuration from Compile to (Compile, compile) scope, allowing publish and publishLocal commands to work. ## How was this patch tested? Successfully published the spark-launcher subproject from within sbt successfully, where it fails without this patch. Author: Erik LaBianca <[email protected]> Closes #20040 from easel/javadoc-xlint.
-
[SPARK-22855][BUILD] Add -no-java-comments to sbt docs/scalacOptions
Prevents Scala 2.12 scaladoc from blowing up attempting to parse java comments. ## What changes were proposed in this pull request? Adds -no-java-comments to docs/scalacOptions under Scala 2.12. Also moves scaladoc configs out of the TestSettings and into the standard sharedSettings section in SparkBuild.scala. ## How was this patch tested? SBT_OPTS=-Dscala-2.12 sbt ++2.12.4 tags/publishLocal Author: Erik LaBianca <[email protected]> Closes #20042 from easel/scaladoc-212.
-
[SPARK-22668][SQL] Ensure no global variables in arguments of method …
…split by CodegenContext.splitExpressions() ## What changes were proposed in this pull request? Passing global variables to the split method is dangerous, as any mutating to it is ignored and may lead to unexpected behavior. To prevent this, one approach is to make sure no expression would output global variables: Localizing lifetime of mutable states in expressions. Another approach is, when calling `ctx.splitExpression`, make sure we don't use children's output as parameter names. Approach 1 is actually hard to do, as we need to check all expressions and operators that support whole-stage codegen. Approach 2 is easier as the callers of `ctx.splitExpressions` are not too many. Besides, approach 2 is more flexible, as children's output may be other stuff that can't be parameter name: literal, inlined statement(a + 1), etc. close #19865 close #19938 ## How was this patch tested? existing tests Author: Wenchen Fan <[email protected]> Closes #20021 from cloud-fan/codegen.
-
[SPARK-22786][SQL] only use AppStatusPlugin in history server
## What changes were proposed in this pull request? In #19681 we introduced a new interface called `AppStatusPlugin`, to register listeners and set up the UI for both live and history UI. However I think it's an overkill for live UI. For example, we should not register `SQLListener` if users are not using SQL functions. Previously we register the `SQLListener` and set up SQL tab when `SparkSession` is firstly created, which indicates users are going to use SQL functions. But in #19681 , we register the SQL functions during `SparkContext` creation. The same thing should apply to streaming too. I think we should keep the previous behavior, and only use this new interface for history server. To reflect this change, I also rename the new interface to `SparkHistoryUIPlugin` This PR also refines the tests for sql listener. ## How was this patch tested? existing tests Author: Wenchen Fan <[email protected]> Closes #19981 from cloud-fan/listener.
-
[SPARK-22822][TEST] Basic tests for WindowFrameCoercion and DecimalPr…
…ecision ## What changes were proposed in this pull request? Test Coverage for `WindowFrameCoercion` and `DecimalPrecision`, this is a Sub-tasks for [SPARK-22722](https://issues.apache.org/jira/browse/SPARK-22722). ## How was this patch tested? N/A Author: Yuming Wang <[email protected]> Closes #20008 from wangyum/SPARK-22822.
-
[SPARK-22042][FOLLOW-UP][SQL] ReorderJoinPredicates can break when ch…
…ild's partitioning is not decided ## What changes were proposed in this pull request? This is a followup PR of #19257 where gatorsmile had left couple comments wrt code style. ## How was this patch tested? Doesn't change any functionality. Will depend on build to see if no checkstyle rules are violated. Author: Tejas Patil <[email protected]> Closes #20041 from tejasapatil/followup_19257.
-
[SPARK-22861][SQL] SQLAppStatusListener handles multi-job executions.
When one execution has multiple jobs, we need to append to the set of stages, not replace them on every job. Added unit test and ran existing tests on jenkins Author: Imran Rashid <[email protected]> Closes #20047 from squito/SPARK-22861.
Commits on Dec 22, 2017
-
[SPARK-22648][K8S] Spark on Kubernetes - Documentation
What changes were proposed in this pull request? This PR contains documentation on the usage of Kubernetes scheduler in Spark 2.3, and a shell script to make it easier to build docker images required to use the integration. The changes detailed here are covered by #19717 and #19468 which have merged already. How was this patch tested? The script has been in use for releases on our fork. Rest is documentation. cc rxin mateiz (shepherd) k8s-big-data SIG members & contributors: foxish ash211 mccheah liyinan926 erikerlandson ssuchter varunkatta kimoonkim tnachen ifilonenko reviewers: vanzin felixcheung jiangxb1987 mridulm TODO: - [x] Add dockerfiles directory to built distribution. (#20007) - [x] Change references to docker to instead say "container" (#19995) - [x] Update configuration table. - [x] Modify spark.kubernetes.allocation.batch.delay to take time instead of int (#20032) Author: foxish <[email protected]> Closes #19946 from foxish/update-k8s-docs.
-
[SPARK-22854][UI] Read Spark version from event logs.
The code was ignoring SparkListenerLogStart, which was added somewhat recently to record the Spark version used to generate an event log. Author: Marcelo Vanzin <[email protected]> Closes #20049 from vanzin/SPARK-22854.
-
[SPARK-22750][SQL] Reuse mutable states when possible
## What changes were proposed in this pull request? The PR introduces a new method `addImmutableStateIfNotExists ` to `CodeGenerator` to allow reusing and sharing the same global variable between different Expressions. This helps reducing the number of global variables needed, which is important to limit the impact on the constant pool. ## How was this patch tested? added UTs Author: Marco Gaido <[email protected]> Author: Marco Gaido <[email protected]> Closes #19940 from mgaido91/SPARK-22750.
-
[SPARK-22450][CORE][MLLIB][FOLLOWUP] safely register class for mllib …
…- LabeledPoint/VectorWithNorm/TreePoint ## What changes were proposed in this pull request? register following classes in Kryo: `org.apache.spark.mllib.regression.LabeledPoint` `org.apache.spark.mllib.clustering.VectorWithNorm` `org.apache.spark.ml.feature.LabeledPoint` `org.apache.spark.ml.tree.impl.TreePoint` `org.apache.spark.ml.tree.impl.BaggedPoint` seems also need to be registered, but I don't know how to do it in this safe way. WeichenXu123 cloud-fan ## How was this patch tested? added tests Author: Zheng RuiFeng <[email protected]> Closes #19950 from zhengruifeng/labeled_kryo.
-
[SPARK-22866][K8S] Fix path issue in Kubernetes dockerfile
## What changes were proposed in this pull request? The path was recently changed in #19946, but the dockerfile was not updated. This is a trivial 1 line fix. ## How was this patch tested? `./sbin/build-push-docker-images.sh -r spark-repo -t latest build` cc/ vanzin mridulm rxin jiangxb1987 liyinan926 Author: Anirudh Ramanathan <[email protected]> Author: foxish <[email protected]> Closes #20051 from foxish/patch-1.
-
[SPARK-22862] Docs on lazy elimination of columns missing from an enc…
…oder This behavior has confused some users, so lets clarify it. Author: Michael Armbrust <[email protected]> Closes #20048 from marmbrus/datasetAsDocs.
-
[SPARK-22874][PYSPARK][SQL] Modify checking pandas version to use Loo…
…seVersion. ## What changes were proposed in this pull request? Currently we check pandas version by capturing if `ImportError` for the specific imports is raised or not but we can compare `LooseVersion` of the version strings as the same as we're checking pyarrow version. ## How was this patch tested? Existing tests. Author: Takuya UESHIN <[email protected]> Closes #20054 from ueshin/issues/SPARK-22874.
-
[SPARK-22346][ML] VectorSizeHint Transformer for using VectorAssemble…
…r in StructuredSteaming ## What changes were proposed in this pull request? A new VectorSizeHint transformer was added. This transformer is meant to be used as a pipeline stage ahead of VectorAssembler, on vector columns, so that VectorAssembler can join vectors in a streaming context where the size of the input vectors is otherwise not known. ## How was this patch tested? Unit tests. Please review http://spark.apache.org/contributing.html before opening a pull request. Author: Bago Amirbekian <[email protected]> Closes #19746 from MrBago/vector-size-hint.
Commits on Dec 23, 2017
-
[SPARK-22789] Map-only continuous processing execution
## What changes were proposed in this pull request? Basic continuous execution, supporting map/flatMap/filter, with commits and advancement through RPC. ## How was this patch tested? new unit-ish tests (exercising execution end to end) Author: Jose Torres <[email protected]> Closes #19984 from jose-torres/continuous-impl.
-
[SPARK-22833][IMPROVEMENT] in SparkHive Scala Examples
## What changes were proposed in this pull request? SparkHive Scala Examples Improvement made: * Writing DataFrame / DataSet to Hive Managed , Hive External table using different storage format. * Implementation of Partition, Reparition, Coalesce with appropriate example. ## How was this patch tested? * Patch has been tested manually and by running ./dev/run-tests. Author: chetkhatri <[email protected]> Closes #20018 from chetkhatri/scala-sparkhive-examples.
-
[SPARK-20694][EXAMPLES] Update SQLDataSourceExample.scala
## What changes were proposed in this pull request? Create table using the right DataFrame. peopleDF->usersDF peopleDF: +----+-------+ | age| name| +----+-------+ usersDF: +------+--------------+----------------+ | name|favorite_color|favorite_numbers| +------+--------------+----------------+ ## How was this patch tested? Manually tested. Author: CNRui <[email protected]> Closes #20052 from CNRui/patch-2.
-
[HOTFIX] Fix Scala style checks
## What changes were proposed in this pull request? This PR fixes a style that broke the build. ## How was this patch tested? Manually tested. Author: hyukjinkwon <[email protected]> Closes #20065 from HyukjinKwon/minor-style.
-
[SPARK-22844][R] Adds date_trunc in R API
## What changes were proposed in this pull request? This PR adds `date_trunc` in R API as below: ```r > df <- createDataFrame(list(list(a = as.POSIXlt("2012-12-13 12:34:00")))) > head(select(df, date_trunc("hour", df$a))) date_trunc(hour, a) 1 2012-12-13 12:00:00 ``` ## How was this patch tested? Unit tests added in `R/pkg/tests/fulltests/test_sparkSQL.R`. Author: hyukjinkwon <[email protected]> Closes #20031 from HyukjinKwon/r-datetrunc. -
[SPARK-22889][SPARKR] Set overwrite=T when install SparkR in tests
## What changes were proposed in this pull request? Since all CRAN checks go through the same machine, if there is an older partial download or partial install of Spark left behind the tests fail. This PR overwrites the install files when running tests. This shouldn't affect Jenkins as `SPARK_HOME` is set when running Jenkins tests. ## How was this patch tested? Test manually by running `R CMD check --as-cran` Author: Shivaram Venkataraman <[email protected]> Closes #20060 from shivaram/sparkr-overwrite-cran.
Commits on Dec 24, 2017
-
[SPARK-22465][CORE] Add a safety-check to RDD defaultPartitioner
## What changes were proposed in this pull request? In choosing a Partitioner to use for a cogroup-like operation between a number of RDDs, the default behaviour was if some of the RDDs already have a partitioner, we choose the one amongst them with the maximum number of partitions. This behaviour, in some cases, could hit the 2G limit (SPARK-6235). To illustrate one such scenario, consider two RDDs: rDD1: with smaller data and smaller number of partitions, alongwith a Partitioner. rDD2: with much larger data and a larger number of partitions, without a Partitioner. The cogroup of these two RDDs could hit the 2G limit, as a larger amount of data is shuffled into a smaller number of partitions. This PR introduces a safety-check wherein the Partitioner is chosen only if either of the following conditions are met: 1. if the number of partitions of the RDD associated with the Partitioner is greater than or equal to the max number of upstream partitions; or 2. if the number of partitions of the RDD associated with the Partitioner is less than and within a single order of magnitude of the max number of upstream partitions. ## How was this patch tested? Unit tests in PartitioningSuite and PairRDDFunctionsSuite Author: sujithjay <[email protected]> Closes #20002 from sujithjay/SPARK-22465.
Commits on Dec 25, 2017
-
[SPARK-22707][ML] Optimize CrossValidator memory occupation by models…
… in fitting ## What changes were proposed in this pull request? Via some test I found CrossValidator still exists memory issue, it will still occupy `O(n*sizeof(model))` memory for holding models when fitting, if well optimized, it should be `O(parallelism*sizeof(model))` This is because modelFutures will hold the reference to model object after future is complete (we can use `future.value.get.get` to fetch it), and the `Future.sequence` and the `modelFutures` array holds references to each model future. So all model object are keep referenced. So it will still occupy `O(n*sizeof(model))` memory. I fix this by merging the `modelFuture` and `foldMetricFuture` together, and use `atomicInteger` to statistic complete fitting tasks and when all done, trigger `trainingDataset.unpersist`. I ever commented this issue on the old PR [SPARK-19357] #16774 (review) unfortunately, at that time I do not realize that the issue still exists, but now I confirm it and create this PR to fix it. ## Discussion I give 3 approaches which we can compare, after discussion I realized none of them is ideal, we have to make a trade-off. **After discussion with jkbradley , choose approach 3** ### Approach 1 ~~The approach proposed by MrBago at~~ #19904 (comment) ~~This approach resolve the model objects referenced issue, allow the model objects to be GCed in time. **BUT, in some cases, it still do not resolve the O(N) model memory occupation issue**. Let me use an extreme case to describe it:~~ ~~suppose we set `parallelism = 1`, and there're 100 paramMaps. So we have 100 fitting & evaluation tasks. In this approach, because of `parallelism = 1`, the code have to wait 100 fitting tasks complete, **(at this time the memory occupation by models already reach 100 * sizeof(model) )** and then it will unpersist training dataset and then do 100 evaluation tasks.~~ ### Approach 2 ~~This approach is my PR old version code~~ 2cc7c28 ~~This approach can make sure at any case, the peak memory occupation by models to be `O(numParallelism * sizeof(model))`, but, it exists an issue that, in some extreme case, the "unpersist training dataset" will be delayed until most of the evaluation tasks complete. Suppose the case `parallelism = 1`, and there're 100 fitting & evaluation tasks, each fitting&evaluation task have to be executed one by one, so only after the first 99 fitting&evaluation tasks and the 100th fitting task complete, the "unpersist training dataset" will be triggered.~~ ### Approach 3 After I compared approach 1 and approach 2, I realized that, in the case which parallelism is low but there're many fitting & evaluation tasks, we cannot achieve both of the following two goals: - Make the peak memory occupation by models(driver-side) to be O(parallelism * sizeof(model)) - unpersist training dataset before most of the evaluation tasks started. So I vote for a simpler approach, move the unpersist training dataset to the end (Does this really matters ?) Because the goal 1 is more important, we must make sure the peak memory occupation by models (driver-side) to be O(parallelism * sizeof(model)), otherwise it will bring high risk of OOM. Like following code: ``` val foldMetricFutures = epm.zipWithIndex.map { case (paramMap, paramIndex) => Future[Double] { val model = est.fit(trainingDataset, paramMap).asInstanceOf[Model[_]] //...other minor codes val metric = eval.evaluate(model.transform(validationDataset, paramMap)) logDebug(s"Got metric metricformodeltrainedwithparamMap.") metric } (executionContext) } val foldMetrics = foldMetricFutures.map(ThreadUtils.awaitResult(_, Duration.Inf)) trainingDataset.unpersist() // <------- unpersist at the end validationDataset.unpersist() ``` ## How was this patch tested? N/A Author: WeichenXu <[email protected]> Closes #19904 from WeichenXu123/fix_cross_validator_memory_issue.
-
[SPARK-22893][SQL] Unified the data type mismatch message
## What changes were proposed in this pull request? We should use `dataType.simpleString` to unified the data type mismatch message: Before: ``` spark-sql> select cast(1 as binary); Error in query: cannot resolve 'CAST(1 AS BINARY)' due to data type mismatch: cannot cast IntegerType to BinaryType; line 1 pos 7; ``` After: ``` park-sql> select cast(1 as binary); Error in query: cannot resolve 'CAST(1 AS BINARY)' due to data type mismatch: cannot cast int to binary; line 1 pos 7; ``` ## How was this patch tested? Exist test. Author: Yuming Wang <[email protected]> Closes #20064 from wangyum/SPARK-22893.
-
[SPARK-22874][PYSPARK][SQL][FOLLOW-UP] Modify error messages to show …
…actual versions. ## What changes were proposed in this pull request? This is a follow-up pr of #20054 modifying error messages for both pandas and pyarrow to show actual versions. ## How was this patch tested? Existing tests. Author: Takuya UESHIN <[email protected]> Closes #20074 from ueshin/issues/SPARK-22874_fup1.
Commits on Dec 26, 2017
-
[SPARK-22893][SQL][HOTFIX] Fix a error message of VersionsSuite
## What changes were proposed in this pull request? #20064 breaks Jenkins tests because it missed to update one error message for Hive 0.12 and Hive 0.13. This PR fixes that. - https://amplab.cs.berkeley.edu/jenkins/view/Spark%20QA%20Test%20(Dashboard)/job/spark-master-test-sbt-hadoop-2.7/3924/ - https://amplab.cs.berkeley.edu/jenkins/view/Spark%20QA%20Test%20(Dashboard)/job/spark-master-test-sbt-hadoop-2.6/3977/ - https://amplab.cs.berkeley.edu/jenkins/view/Spark%20QA%20Test%20(Dashboard)/job/spark-master-test-maven-hadoop-2.7/4226/ - https://amplab.cs.berkeley.edu/jenkins/view/Spark%20QA%20Test%20(Dashboard)/job/spark-master-test-maven-hadoop-2.6/4260/ ## How was this patch tested? Pass the Jenkins without failure. Author: Dongjoon Hyun <[email protected]> Closes #20079 from dongjoon-hyun/SPARK-22893.
-
[SPARK-20168][DSTREAM] Add changes to use kinesis fetches from specif…
…ic timestamp ## What changes were proposed in this pull request? Kinesis client can resume from a specified timestamp while creating a stream. We should have option to pass a timestamp in config to allow kinesis to resume from the given timestamp. The patch introduces a new `KinesisInitialPositionInStream` that takes the `InitialPositionInStream` with the `timestamp` information that can be used to resume kinesis fetches from the provided timestamp. ## How was this patch tested? Unit Tests cc : budde brkyvz Author: Yash Sharma <[email protected]> Closes #18029 from yssharma/ysharma/kcl_resume.
-
[SPARK-21552][SQL] Add DecimalType support to ArrowWriter.
## What changes were proposed in this pull request? Decimal type is not yet supported in `ArrowWriter`. This is adding the decimal type support. ## How was this patch tested? Added a test to `ArrowConvertersSuite`. Author: Takuya UESHIN <[email protected]> Closes #18754 from ueshin/issues/SPARK-21552.
-
[SPARK-22901][PYTHON] Add deterministic flag to pyspark UDF
## What changes were proposed in this pull request? In SPARK-20586 the flag `deterministic` was added to Scala UDF, but it is not available for python UDF. This flag is useful for cases when the UDF's code can return different result with the same input. Due to optimization, duplicate invocations may be eliminated or the function may even be invoked more times than it is present in the query. This can lead to unexpected behavior. This PR adds the deterministic flag, via the `asNondeterministic` method, to let the user mark the function as non-deterministic and therefore avoid the optimizations which might lead to strange behaviors. ## How was this patch tested? Manual tests: ``` >>> from pyspark.sql.functions import * >>> from pyspark.sql.types import * >>> df_br = spark.createDataFrame([{'name': 'hello'}]) >>> import random >>> udf_random_col = udf(lambda: int(100*random.random()), IntegerType()).asNondeterministic() >>> df_br = df_br.withColumn('RAND', udf_random_col()) >>> random.seed(1234) >>> udf_add_ten = udf(lambda rand: rand + 10, IntegerType()) >>> df_br.withColumn('RAND_PLUS_TEN', udf_add_ten('RAND')).show() +-----+----+-------------+ | name|RAND|RAND_PLUS_TEN| +-----+----+-------------+ |hello| 3| 13| +-----+----+-------------+ ``` Author: Marco Gaido <[email protected]> Author: Marco Gaido <[email protected]> Closes #19929 from mgaido91/SPARK-22629.
-
[SPARK-22833][EXAMPLE] Improvement SparkHive Scala Examples
## What changes were proposed in this pull request? Some improvements: 1. Point out we are using both Spark SQ native syntax and HQL syntax in the example 2. Avoid using the same table name with temp view, to not confuse users. 3. Create the external hive table with a directory that already has data, which is a more common use case. 4. Remove the usage of `spark.sql.parquet.writeLegacyFormat`. This config was introduced by #8566 and has nothing to do with Hive. 5. Remove `repartition` and `coalesce` example. These 2 are not Hive specific, we should put them in a different example file. BTW they can't accurately control the number of output files, `spark.sql.files.maxRecordsPerFile` also controls it. ## How was this patch tested? N/A Author: Wenchen Fan <[email protected]> Closes #20081 from cloud-fan/minor.
-
[SPARK-22894][SQL] DateTimeOperations should accept SQL like string type
## What changes were proposed in this pull request? `DateTimeOperations` accept [`StringType`](https://github.com/apache/spark/blob/ae998ec2b5548b7028d741da4813473dde1ad81e/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/analysis/TypeCoercion.scala#L669), but: ``` spark-sql> SELECT '2017-12-24' + interval 2 months 2 seconds; Error in query: cannot resolve '(CAST('2017-12-24' AS DOUBLE) + interval 2 months 2 seconds)' due to data type mismatch: differing types in '(CAST('2017-12-24' AS DOUBLE) + interval 2 months 2 seconds)' (double and calendarinterval).; line 1 pos 7; 'Project [unresolvedalias((cast(2017-12-24 as double) + interval 2 months 2 seconds), None)] +- OneRowRelation spark-sql> ``` After this PR: ``` spark-sql> SELECT '2017-12-24' + interval 2 months 2 seconds; 2018-02-24 00:00:02 Time taken: 0.2 seconds, Fetched 1 row(s) ``` ## How was this patch tested? unit tests Author: Yuming Wang <[email protected]> Closes #20067 from wangyum/SPARK-22894.
Commits on Dec 27, 2017
-
[SPARK-22846][SQL] Fix table owner is null when creating table throug…
…h spark sql or thriftserver ## What changes were proposed in this pull request? fix table owner is null when create new table through spark sql ## How was this patch tested? manual test. 1、first create a table 2、then select the table properties from mysql which connected to hive metastore Please review http://spark.apache.org/contributing.html before opening a pull request. Author: xu.wenchun <[email protected]> Closes #20034 from BruceXu1991/SPARK-22846.
-
[SPARK-22324][SQL][PYTHON][FOLLOW-UP] Update setup.py file.
## What changes were proposed in this pull request? This is a follow-up pr of #19884 updating setup.py file to add pyarrow dependency. ## How was this patch tested? Existing tests. Author: Takuya UESHIN <[email protected]> Closes #20089 from ueshin/issues/SPARK-22324/fup1.
-
[SPARK-22904][SQL] Add tests for decimal operations and string casts
## What changes were proposed in this pull request? Test coverage for arithmetic operations leading to: 1. Precision loss 2. Overflow Moreover, tests for casting bad string to other input types and for using bad string as operators of some functions. ## How was this patch tested? added tests Author: Marco Gaido <[email protected]> Closes #20084 from mgaido91/SPARK-22904.
Commits on Dec 28, 2017
-
[SPARK-22899][ML][STREAMING] Fix OneVsRestModel transform on streamin…
…g data failed. ## What changes were proposed in this pull request? Fix OneVsRestModel transform on streaming data failed. ## How was this patch tested? UT will be added soon, once #19979 merged. (Need a helper test method there) Author: WeichenXu <[email protected]> Closes #20077 from WeichenXu123/fix_ovs_model_transform.
-
[SPARK-18016][SQL][FOLLOW-UP] Code Generation: Constant Pool Limit - …
…reduce entries for mutable state ## What changes were proposed in this pull request? This PR addresses additional review comments in #19811 ## How was this patch tested? Existing test suites Author: Kazuaki Ishizaki <[email protected]> Closes #20036 from kiszk/SPARK-18066-followup.
-
[SPARK-22909][SS] Move Structured Streaming v2 APIs to streaming folder
## What changes were proposed in this pull request? This PR moves Structured Streaming v2 APIs to streaming folder as following: ``` sql/core/src/main/java/org/apache/spark/sql/sources/v2/streaming ├── ContinuousReadSupport.java ├── ContinuousWriteSupport.java ├── MicroBatchReadSupport.java ├── MicroBatchWriteSupport.java ├── reader │ ├── ContinuousDataReader.java │ ├── ContinuousReader.java │ ├── MicroBatchReader.java │ ├── Offset.java │ └── PartitionOffset.java └── writer └── ContinuousWriter.java ``` ## How was this patch tested? Jenkins Author: Shixiong Zhu <[email protected]> Closes #20093 from zsxwing/move. -
[SPARK-22757][KUBERNETES] Enable use of remote dependencies (http, s3…
…, gcs, etc.) in Kubernetes mode ## What changes were proposed in this pull request? This PR expands the Kubernetes mode to be able to use remote dependencies on http/https endpoints, GCS, S3, etc. It adds steps for configuring and appending the Kubernetes init-container into the driver and executor pods for downloading remote dependencies. [Init-containers](https://kubernetes.io/docs/concepts/workloads/pods/init-containers/), as the name suggests, are containers that are run to completion before the main containers start, and are often used to perform initialization tasks prior to starting the main containers. We use init-containers to localize remote application dependencies before the driver/executors start running. The code that the init-container runs is also included. This PR also adds a step to the driver and executors for mounting user-specified secrets that may store credentials for accessing data storage, e.g., S3 and Google Cloud Storage (GCS), into the driver and executors. ## How was this patch tested? * The patch contains unit tests which are passing. * Manual testing: `./build/mvn -Pkubernetes clean package` succeeded. * Manual testing of the following cases: * [x] Running SparkPi using container-local spark-example jar. * [x] Running SparkPi using container-local spark-example jar with user-specific secret mounted. * [x] Running SparkPi using spark-example jar hosted remotely on an https endpoint. cc rxin felixcheung mateiz (shepherd) k8s-big-data SIG members & contributors: mccheah foxish ash211 ssuchter varunkatta kimoonkim erikerlandson tnachen ifilonenko liyinan926 reviewers: vanzin felixcheung jiangxb1987 mridulm Author: Yinan Li <[email protected]> Closes #19954 from liyinan926/init-container.
-
[SPARK-22648][K8S] Add documentation covering init containers and sec…
…rets ## What changes were proposed in this pull request? This PR updates the Kubernetes documentation corresponding to the following features/changes in #19954. * Ability to use remote dependencies through the init-container. * Ability to mount user-specified secrets into the driver and executor pods. vanzin jiangxb1987 foxish Author: Yinan Li <[email protected]> Closes #20059 from liyinan926/doc-update.
-
[SPARK-22843][R] Adds localCheckpoint in R
## What changes were proposed in this pull request? This PR proposes to add `localCheckpoint(..)` in R API. ```r df <- localCheckpoint(createDataFrame(iris)) ``` ## How was this patch tested? Unit tests added in `R/pkg/tests/fulltests/test_sparkSQL.R` Author: hyukjinkwon <[email protected]> Closes #20073 from HyukjinKwon/SPARK-22843.
-
[SPARK-21208][R] Adds setLocalProperty and getLocalProperty in R
## What changes were proposed in this pull request? This PR adds `setLocalProperty` and `getLocalProperty`in R. ```R > df <- createDataFrame(iris) > setLocalProperty("spark.job.description", "Hello world!") > count(df) > setLocalProperty("spark.job.description", "Hi !!") > count(df) ``` <img width="775" alt="2017-12-25 4 18 07" src="https://user-images.githubusercontent.com/6477701/34335213-60655a7c-e990-11e7-88aa-12debe311627.png"> ```R > print(getLocalProperty("spark.job.description")) NULL > setLocalProperty("spark.job.description", "Hello world!") > print(getLocalProperty("spark.job.description")) [1] "Hello world!" > setLocalProperty("spark.job.description", "Hi !!") > print(getLocalProperty("spark.job.description")) [1] "Hi !!" ``` ## How was this patch tested? Manually tested and a test in `R/pkg/tests/fulltests/test_context.R`. Author: hyukjinkwon <[email protected]> Closes #20075 from HyukjinKwon/SPARK-21208. -
[SPARK-20392][SQL][FOLLOWUP] should not add extra AnalysisBarrier
## What changes were proposed in this pull request? I found this problem while auditing the analyzer code. It's dangerous to introduce extra `AnalysisBarrer` during analysis, as the plan inside it will bypass all analysis afterward, which may not be expected. We should only preserve `AnalysisBarrer` but not introduce new ones. ## How was this patch tested? existing tests Author: Wenchen Fan <[email protected]> Closes #20094 from cloud-fan/barrier.
-
[SPARK-22917][SQL] Should not try to generate histogram for empty/nul…
…l columns ## What changes were proposed in this pull request? For empty/null column, the result of `ApproximatePercentile` is null. Then in `ApproxCountDistinctForIntervals`, a `MatchError` (for `endpoints`) will be thrown if we try to generate histogram for that column. Besides, there is no need to generate histogram for such column. In this patch, we exclude such column when generating histogram. ## How was this patch tested? Enhanced test cases for empty/null columns. Author: Zhenhua Wang <[email protected]> Closes #20102 from wzhfy/no_record_hgm_bug.
-
[MINOR][BUILD] Fix Java linter errors
## What changes were proposed in this pull request? This PR cleans up a few Java linter errors for Apache Spark 2.3 release. ## How was this patch tested? ```bash $ dev/lint-java Using `mvn` from path: /usr/local/bin/mvn Checkstyle checks passed. ``` We can see the result from [Travis CI](https://travis-ci.org/dongjoon-hyun/spark/builds/322470787), too. Author: Dongjoon Hyun <[email protected]> Closes #20101 from dongjoon-hyun/fix-java-lint.
-
[SPARK-22875][BUILD] Assembly build fails for a high user id
## What changes were proposed in this pull request? Add tarLongFileMode=posix configuration for the assembly plugin ## How was this patch tested? Reran build successfully ``` ./build/mvn package -Pbigtop-dist -DskipTests -rf :spark-assembly_2.11 [INFO] Spark Project Assembly ............................. SUCCESS [ 23.082 s] ``` Author: Gera Shegalov <[email protected]> Closes #20055 from gerashegalov/gera/tarLongFileMode.
-
[SPARK-22836][UI] Show driver logs in UI when available.
Port code from the old executors listener to the new one, so that the driver logs present in the application start event are kept. Author: Marcelo Vanzin <[email protected]> Closes #20038 from vanzin/SPARK-22836.
-
[SPARK-22890][TEST] Basic tests for DateTimeOperations
## What changes were proposed in this pull request? Test Coverage for `DateTimeOperations`, this is a Sub-tasks for [SPARK-22722](https://issues.apache.org/jira/browse/SPARK-22722). ## How was this patch tested? N/A Author: Yuming Wang <[email protected]> Closes #20061 from wangyum/SPARK-22890.
-
[SPARK-11035][CORE] Add in-process Spark app launcher.
This change adds a new launcher that allows applications to be run in a separate thread in the same process as the calling code. To achieve that, some code from the child process implementation was moved to abstract classes that implement the common functionality, and the new launcher inherits from those. The new launcher was added as a new class, instead of implemented as a new option to the existing SparkLauncher, to avoid ambigous APIs. For example, SparkLauncher has ways to set the child app's environment, modify SPARK_HOME, or control the logging of the child process, none of which apply to in-process apps. The in-process launcher has limitations: it needs Spark in the context class loader of the calling thread, and it's bound by Spark's current limitation of a single client-mode application per JVM. It also relies on the recently added SparkApplication trait to make sure different apps don't mess up each other's configuration, so config isolation is currently limited to cluster mode. I also chose to keep the same socket-based communication for in-process apps, even though it might be possible to avoid it for in-process mode. That helps both implementations share more code. Tested with new and existing unit tests, and with a simple app that uses the launcher; also made sure the app ran fine with older launcher jar to check binary compatibility. Author: Marcelo Vanzin <[email protected]> Closes #19591 from vanzin/SPARK-11035.
-
[SPARK-22818][SQL] csv escape of quote escape
## What changes were proposed in this pull request? Escape of escape should be considered when using the UniVocity csv encoding/decoding library. Ref: https://github.com/uniVocity/univocity-parsers#escaping-quote-escape-characters One option is added for reading and writing CSV: `escapeQuoteEscaping` ## How was this patch tested? Unit test added. Author: soonmok-kwon <[email protected]> Closes #20004 from ep1804/SPARK-22818.
{kind=link}
Commits on Dec 29, 2017
-
[SPARK-22905][MLLIB] Fix ChiSqSelectorModel save implementation
## What changes were proposed in this pull request? Currently, in `ChiSqSelectorModel`, save: ``` spark.createDataFrame(dataArray).repartition(1).write... ``` The default partition number used by createDataFrame is "defaultParallelism", Current RoundRobinPartitioning won't guarantee the "repartition" generating the same order result with local array. We need fix it. ## How was this patch tested? N/A Author: WeichenXu <[email protected]> Closes #20088 from WeichenXu123/fix_chisq_model_save.
-
[SPARK-22313][PYTHON][FOLLOWUP] Explicitly import warnings namespace …
…in flume.py ## What changes were proposed in this pull request? This PR explicitly imports the missing `warnings` in `flume.py`. ## How was this patch tested? Manually tested. ```python >>> import warnings >>> warnings.simplefilter('always', DeprecationWarning) >>> from pyspark.streaming import flume >>> flume.FlumeUtils.createStream(None, None, None) Traceback (most recent call last): File "<stdin>", line 1, in <module> File "/.../spark/python/pyspark/streaming/flume.py", line 60, in createStream warnings.warn( NameError: global name 'warnings' is not defined ``` ```python >>> import warnings >>> warnings.simplefilter('always', DeprecationWarning) >>> from pyspark.streaming import flume >>> flume.FlumeUtils.createStream(None, None, None) /.../spark/python/pyspark/streaming/flume.py:65: DeprecationWarning: Deprecated in 2.3.0. Flume support is deprecated as of Spark 2.3.0. See SPARK-22142. DeprecationWarning) ... ``` Author: hyukjinkwon <[email protected]> Closes #20110 from HyukjinKwon/SPARK-22313-followup. -
[SPARK-22891][SQL] Make hive client creation thread safe
## What changes were proposed in this pull request? This is to walk around the hive issue: https://issues.apache.org/jira/browse/HIVE-11935 ## How was this patch tested? (Please explain how this patch was tested. E.g. unit tests, integration tests, manual tests) (If this patch involves UI changes, please attach a screenshot; otherwise, remove this) Please review http://spark.apache.org/contributing.html before opening a pull request. Author: Feng Liu <[email protected]> Closes #20109 from liufengdb/synchronized.
-
[SPARK-22834][SQL] Make insertion commands have real children to fix …
…UI issues ## What changes were proposed in this pull request? With #19474, children of insertion commands are missing in UI. To fix it: 1. Create a new physical plan `DataWritingCommandExec` to exec `DataWritingCommand` with children. So that the other commands won't be affected. 2. On creation of `DataWritingCommand`, a new field `allColumns` must be specified, which is the output of analyzed plan. 3. In `FileFormatWriter`, the output schema will use `allColumns` instead of the output of optimized plan. Before code changes:  After code changes:  ## How was this patch tested? Unit test Author: Wang Gengliang <[email protected]> Closes #20020 from gengliangwang/insert.
-
[SPARK-22892][SQL] Simplify some estimation logic by using double ins…
…tead of decimal ## What changes were proposed in this pull request? Simplify some estimation logic by using double instead of decimal. ## How was this patch tested? Existing tests. Author: Zhenhua Wang <[email protected]> Closes #20062 from wzhfy/simplify_by_double.
-
[SPARK-22916][SQL] shouldn't bias towards build right if user does no…
…t specify ## What changes were proposed in this pull request? When there are no broadcast hints, the current spark strategies will prefer to building the right side, without considering the sizes of the two tables. This patch added the logic to consider the sizes of the two tables for the build side. To make the logic clear, the build side is determined by two steps: 1. If there are broadcast hints, the build side is determined by `broadcastSideByHints`; 2. If there are no broadcast hints, the build side is determined by `broadcastSideBySizes`; 3. If the broadcast is disabled by the config, it falls back to the next cases. ## How was this patch tested? (Please explain how this patch was tested. E.g. unit tests, integration tests, manual tests) (If this patch involves UI changes, please attach a screenshot; otherwise, remove this) Please review http://spark.apache.org/contributing.html before opening a pull request. Author: Feng Liu <[email protected]> Closes #20099 from liufengdb/fix-spark-strategies.
-
[SPARK-21657][SQL] optimize explode quadratic memory consumpation
## What changes were proposed in this pull request? The issue has been raised in two Jira tickets: [SPARK-21657](https://issues.apache.org/jira/browse/SPARK-21657), [SPARK-16998](https://issues.apache.org/jira/browse/SPARK-16998). Basically, what happens is that in collection generators like explode/inline we create many rows from each row. Currently each exploded row contains also the column on which it was created. This causes, for example, if we have a 10k array in one row that this array will get copy 10k times - to each of the row. this results a qudratic memory consumption. However, it is a common case that the original column gets projected out after the explode, so we can avoid duplicating it. In this solution we propose to identify this situation in the optimizer and turn on a flag for omitting the original column in the generation process. ## How was this patch tested? 1. We added a benchmark test to MiscBenchmark that shows x16 improvement in runtimes. 2. We ran some of the other tests in MiscBenchmark and they show 15% improvements. 3. We ran this code on a specific case from our production data with rows containing arrays of size ~200k and it reduced the runtime from 6 hours to 3 mins. Author: oraviv <[email protected]> Author: uzadude <[email protected]> Author: uzadude <[email protected]> Closes #19683 from uzadude/optimize_explode.
-
[SPARK-22921][PROJECT-INFRA] Choices for Assigning Jira on Merge
In general jiras are assigned to the original reporter or one of the commentors. This updates the merge script to give you a simple choice to do that, so you don't have to do it manually. Author: Imran Rashid <[email protected]> Closes #20107 from squito/SPARK-22921.
-
[SPARK-22370][SQL][PYSPARK][FOLLOW-UP] Fix a test failure when xmlrun…
…ner is installed. ## What changes were proposed in this pull request? This is a follow-up pr of #19587. If `xmlrunner` is installed, `VectorizedUDFTests.test_vectorized_udf_check_config` fails by the following error because the `self` which is a subclass of `unittest.TestCase` in the UDF `check_records_per_batch` can't be pickled anymore. ``` PicklingError: Cannot pickle files that are not opened for reading: w ``` This changes the UDF not to refer the `self`. ## How was this patch tested? Tested locally. Author: Takuya UESHIN <[email protected]> Closes #20115 from ueshin/issues/SPARK-22370_fup1.
-
[SPARK-20654][CORE] Add config to limit disk usage of the history ser…
…ver. This change adds a new configuration option and support code that limits how much disk space the SHS will use. The default value is pretty generous so that applications will, hopefully, only rarely need to be replayed because of their disk stored being evicted. This works by keeping track of how much data each application is using. Also, because it's not possible to know, before replaying, how much space will be needed, it's possible that usage will exceed the configured limit temporarily. The code uses the concept of a "lease" to try to limit how much the SHS will exceed the limit in those cases. Active UIs are also tracked, so they're never deleted. This works in tandem with the existing option of how many active UIs are loaded; because unused UIs will be unloaded, their disk stores will also become candidates for deletion. If the data is not deleted, though, re-loading the UI is pretty quick. Author: Marcelo Vanzin <[email protected]> Closes #20011 from vanzin/SPARK-20654.
-
[SPARK-22864][CORE] Disable allocation schedule in ExecutorAllocation…
…ManagerSuite. The scheduled task was racing with the test code and could influence the values returned to the test, triggering assertions. The change adds a new config that is only used during testing, and overrides it on the affected test suite. The issue in the bug can be reliably reproduced by reducing the interval in the test (e.g. to 10ms). While there, fixed an exception that shows up in the logs while these tests run, and simplified some code (which was also causing misleading log messages in the log output of the test). Author: Marcelo Vanzin <[email protected]> Closes #20050 from vanzin/SPARK-22864.
-
[SPARK-22905][ML][FOLLOWUP] Fix GaussianMixtureModel save
## What changes were proposed in this pull request? make sure model data is stored in order. WeichenXu123 ## How was this patch tested? existing tests Author: Zheng RuiFeng <[email protected]> Closes #20113 from zhengruifeng/gmm_save.
-
[SPARK-22920][SPARKR] sql functions for current_date, current_timesta…
…mp, rtrim/ltrim/trim with trimString ## What changes were proposed in this pull request? Add sql functions ## How was this patch tested? manual, unit tests Author: Felix Cheung <[email protected]> Closes #20105 from felixcheung/rsqlfuncs.
-
[SPARK-22921][PROJECT-INFRA] Bug fix in jira assigning
Small bug fix from last pr, ran a successful merge with this code. Author: Imran Rashid <[email protected]> Closes #20117 from squito/SPARK-22921.
{kind=link}
{kind=link}
Commits on Dec 30, 2017
-
[SPARK-22922][ML][PYSPARK] Pyspark portion of the fit-multiple API
## What changes were proposed in this pull request? Adding fitMultiple API to `Estimator` with default implementation. Also update have ml.tuning meta-estimators use this API. ## How was this patch tested? Unit tests. Author: Bago Amirbekian <[email protected]> Closes #20058 from MrBago/python-fitMultiple.
-
[SPARK-22734][ML][PYSPARK] Added Python API for VectorSizeHint.
(Please fill in changes proposed in this fix) Python API for VectorSizeHint Transformer. (Please explain how this patch was tested. E.g. unit tests, integration tests, manual tests) doc-tests. Author: Bago Amirbekian <[email protected]> Closes #20112 from MrBago/vectorSizeHint-PythonAPI.
-
[SPARK-22881][ML][TEST] ML regression package testsuite add Structure…
…dStreaming test ## What changes were proposed in this pull request? ML regression package testsuite add StructuredStreaming test In order to make testsuite easier to modify, new helper function added in `MLTest`: ``` def testTransformerByGlobalCheckFunc[A : Encoder]( dataframe: DataFrame, transformer: Transformer, firstResultCol: String, otherResultCols: String*) (globalCheckFunction: Seq[Row] => Unit): Unit ``` ## How was this patch tested? N/A Author: WeichenXu <[email protected]> Author: Bago Amirbekian <[email protected]> Closes #19979 from WeichenXu123/ml_stream_test. -
[SPARK-22771][SQL] Concatenate binary inputs into a binary output
## What changes were proposed in this pull request? This pr modified `concat` to concat binary inputs into a single binary output. `concat` in the current master always output data as a string. But, in some databases (e.g., PostgreSQL), if all inputs are binary, `concat` also outputs binary. ## How was this patch tested? Added tests in `SQLQueryTestSuite` and `TypeCoercionSuite`. Author: Takeshi Yamamuro <[email protected]> Closes #19977 from maropu/SPARK-22771.
-
[SPARK-21475][Core]Revert "[SPARK-21475][CORE] Use NIO's Files API to…
… replace FileInputStream/FileOutputStream in some critical paths" ## What changes were proposed in this pull request? This reverts commit 5fd0294 because of a huge performance regression. I manually fixed a minor conflict in `OneForOneBlockFetcher.java`. `Files.newInputStream` returns `sun.nio.ch.ChannelInputStream`. `ChannelInputStream` doesn't override `InputStream.skip`, so it's using the default `InputStream.skip` which just consumes and discards data. This causes a huge performance regression when reading shuffle files. ## How was this patch tested? Jenkins Author: Shixiong Zhu <[email protected]> Closes #20119 from zsxwing/revert-SPARK-21475.
-
[TEST][MINOR] remove redundant
EliminateSubqueryAliasesin test code## What changes were proposed in this pull request? The `analyze` method in `implicit class DslLogicalPlan` already includes `EliminateSubqueryAliases`. So there's no need to call `EliminateSubqueryAliases` again after calling `analyze` in some test code. ## How was this patch tested? Existing tests. Author: Zhenhua Wang <[email protected]> Closes #20122 from wzhfy/redundant_code.
-
[SPARK-22919] Bump httpclient versions
Hi all, I would like to bump the PATCH versions of both the Apache httpclient Apache httpcore. I use the SparkTC Stocator library for connecting to an object store, and I would align the versions to reduce java version mismatches. Furthermore it is good to bump these versions since they fix stability and performance issues: https://archive.apache.org/dist/httpcomponents/httpclient/RELEASE_NOTES-4.5.x.txt https://www.apache.org/dist/httpcomponents/httpcore/RELEASE_NOTES-4.4.x.txt Cheers, Fokko ## What changes were proposed in this pull request? Update the versions of the httpclient and httpcore. Only update the PATCH versions, so no breaking changes. ## How was this patch tested? (Please explain how this patch was tested. E.g. unit tests, integration tests, manual tests) (If this patch involves UI changes, please attach a screenshot; otherwise, remove this) Please review http://spark.apache.org/contributing.html before opening a pull request. Author: Fokko Driesprong <[email protected]> Closes #20103 from Fokko/SPARK-22919-bump-httpclient-versions.
-
[SPARK-22924][SPARKR] R API for sortWithinPartitions
## What changes were proposed in this pull request? Add to `arrange` the option to sort only within partition ## How was this patch tested? manual, unit tests Author: Felix Cheung <[email protected]> Closes #20118 from felixcheung/rsortwithinpartition.
Commits on Dec 31, 2017
-
[SPARK-22363][SQL][TEST] Add unit test for Window spilling
## What changes were proposed in this pull request? There is already test using window spilling, but the test coverage is not ideal. In this PR the already existing test was fixed and additional cases added. ## How was this patch tested? Automated: Pass the Jenkins. Author: Gabor Somogyi <[email protected]> Closes #20022 from gaborgsomogyi/SPARK-22363.
-
[SPARK-22895][SQL] Push down the deterministic predicates that are af…
…ter the first non-deterministic ## What changes were proposed in this pull request? Currently, we do not guarantee an order evaluation of conjuncts in either Filter or Join operator. This is also true to the mainstream RDBMS vendors like DB2 and MS SQL Server. Thus, we should also push down the deterministic predicates that are after the first non-deterministic, if possible. ## How was this patch tested? Updated the existing test cases. Author: gatorsmile <[email protected]> Closes #20069 from gatorsmile/morePushDown.
-
[SPARK-22397][ML] add multiple columns support to QuantileDiscretizer
## What changes were proposed in this pull request? add multi columns support to QuantileDiscretizer. When calculating the splits, we can either merge together all the probabilities into one array by calculating approxQuantiles on multiple columns at once, or compute approxQuantiles separately for each column. After doing the performance comparision, we found it’s better to calculating approxQuantiles on multiple columns at once. Here is how we measuring the performance time: ``` var duration = 0.0 for (i<- 0 until 10) { val start = System.nanoTime() discretizer.fit(df) val end = System.nanoTime() duration += (end - start) / 1e9 } println(duration/10) ``` Here is the performance test result: |numCols |NumRows | compute each approxQuantiles separately|compute multiple columns approxQuantiles at one time| |--------|----------|--------------------------------|-------------------------------------------| |10 |60 |0.3623195839 |0.1626658607 | |10 |6000 |0.7537239841 |0.3869370046 | |22 |6000 |1.6497598557 |0.4767903059 | |50 |6000 |3.2268305752 |0.7217818396 | ## How was this patch tested? add UT in QuantileDiscretizerSuite to test multi columns supports Author: Huaxin Gao <[email protected]> Closes #19715 from huaxingao/spark_22397. -
[MINOR][DOCS] s/It take/It takes/g
## What changes were proposed in this pull request? Fixing three small typos in the docs, in particular: It take a `RDD` -> It takes an `RDD` (twice) It take an `JavaRDD` -> It takes a `JavaRDD` I didn't create any Jira issue for this minor thing, I hope it's ok. ## How was this patch tested? visually by clicking on 'preview' Author: Jirka Kremser <[email protected]> Closes #20108 from Jiri-Kremser/docs-typo.
-
[SPARK-13030][ML] Create OneHotEncoderEstimator for OneHotEncoder as …
…Estimator ## What changes were proposed in this pull request? This patch adds a new class `OneHotEncoderEstimator` which extends `Estimator`. The `fit` method returns `OneHotEncoderModel`. Common methods between existing `OneHotEncoder` and new `OneHotEncoderEstimator`, such as transforming schema, are extracted and put into `OneHotEncoderCommon` to reduce code duplication. ### Multi-column support `OneHotEncoderEstimator` adds simpler multi-column support because it is new API and can be free from backward compatibility. ### handleInvalid Param support `OneHotEncoderEstimator` supports `handleInvalid` Param. It supports `error` and `keep`. ## How was this patch tested? Added new test suite `OneHotEncoderEstimatorSuite`. Author: Liang-Chi Hsieh <[email protected]> Closes #19527 from viirya/SPARK-13030.
Commits on Jan 1, 2018
-
-
[SPARK-21616][SPARKR][DOCS] update R migration guide and vignettes
## What changes were proposed in this pull request? update R migration guide and vignettes ## How was this patch tested? manually Author: Felix Cheung <[email protected]> Closes #20106 from felixcheung/rreleasenote23.
-
-
[SPARK-22530][PYTHON][SQL] Adding Arrow support for ArrayType
## What changes were proposed in this pull request? This change adds `ArrayType` support for working with Arrow in pyspark when creating a DataFrame, calling `toPandas()`, and using vectorized `pandas_udf`. ## How was this patch tested? Added new Python unit tests using Array data. Author: Bryan Cutler <[email protected]> Closes #20114 from BryanCutler/arrow-ArrayType-support-SPARK-22530.
-
[SPARK-21893][SPARK-22142][TESTS][FOLLOWUP] Enables PySpark tests for…
… Flume and Kafka in Jenkins ## What changes were proposed in this pull request? This PR proposes to enable PySpark tests for Flume and Kafka in Jenkins by explicitly setting the environment variables in `modules.py`. Seems we are not taking the dependencies into account when calculating environment variables: https://github.com/apache/spark/blob/3a07eff5af601511e97a05e6fea0e3d48f74c4f0/dev/run-tests.py#L554-L561 ## How was this patch tested? Manual tests with Jenkins in #20126. **Before** - https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/85559/consoleFull ``` [info] Setup the following environment variables for tests: ... ``` **After** - https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/85560/consoleFull ``` [info] Setup the following environment variables for tests: ENABLE_KAFKA_0_8_TESTS=1 ENABLE_FLUME_TESTS=1 ... ``` Author: hyukjinkwon <[email protected]> Closes #20128 from HyukjinKwon/SPARK-21893.
Commits on Jan 2, 2018
-
[SPARK-22932][SQL] Refactor AnalysisContext
## What changes were proposed in this pull request? Add a `reset` function to ensure the state in `AnalysisContext ` is per-query. ## How was this patch tested? The existing test cases Author: gatorsmile <[email protected]> Closes #20127 from gatorsmile/refactorAnalysisContext.
-
[SPARK-22897][CORE] Expose stageAttemptId in TaskContext
## What changes were proposed in this pull request? stageAttemptId added in TaskContext and corresponding construction modification ## How was this patch tested? Added a new test in TaskContextSuite, two cases are tested: 1. Normal case without failure 2. Exception case with resubmitted stages Link to [SPARK-22897](https://issues.apache.org/jira/browse/SPARK-22897) Author: Xianjin YE <[email protected]> Closes #20082 from advancedxy/SPARK-22897.
Commits on Jan 3, 2018
-
[SPARK-22938] Assert that SQLConf.get is accessed only on the driver.
## What changes were proposed in this pull request? Assert if code tries to access SQLConf.get on executor. This can lead to hard to detect bugs, where the executor will read fallbackConf, falling back to default config values, ignoring potentially changed non-default configs. If a config is to be passed to executor code, it needs to be read on the driver, and passed explicitly. ## How was this patch tested? Check in existing tests. Author: Juliusz Sompolski <[email protected]> Closes #20136 from juliuszsompolski/SPARK-22938.
-
[SPARK-22934][SQL] Make optional clauses order insensitive for CREATE…
… TABLE SQL statement ## What changes were proposed in this pull request? Currently, our CREATE TABLE syntax require the EXACT order of clauses. It is pretty hard to remember the exact order. Thus, this PR is to make optional clauses order insensitive for `CREATE TABLE` SQL statement. ``` CREATE [TEMPORARY] TABLE [IF NOT EXISTS] [db_name.]table_name [(col_name1 col_type1 [COMMENT col_comment1], ...)] USING datasource [OPTIONS (key1=val1, key2=val2, ...)] [PARTITIONED BY (col_name1, col_name2, ...)] [CLUSTERED BY (col_name3, col_name4, ...) INTO num_buckets BUCKETS] [LOCATION path] [COMMENT table_comment] [TBLPROPERTIES (key1=val1, key2=val2, ...)] [AS select_statement] ``` The proposal is to make the following clauses order insensitive. ``` [OPTIONS (key1=val1, key2=val2, ...)] [PARTITIONED BY (col_name1, col_name2, ...)] [CLUSTERED BY (col_name3, col_name4, ...) INTO num_buckets BUCKETS] [LOCATION path] [COMMENT table_comment] [TBLPROPERTIES (key1=val1, key2=val2, ...)] ``` The same idea is also applicable to Create Hive Table. ``` CREATE [EXTERNAL] TABLE [IF NOT EXISTS] [db_name.]table_name [(col_name1[:] col_type1 [COMMENT col_comment1], ...)] [COMMENT table_comment] [PARTITIONED BY (col_name2[:] col_type2 [COMMENT col_comment2], ...)] [ROW FORMAT row_format] [STORED AS file_format] [LOCATION path] [TBLPROPERTIES (key1=val1, key2=val2, ...)] [AS select_statement] ``` The proposal is to make the following clauses order insensitive. ``` [COMMENT table_comment] [PARTITIONED BY (col_name2[:] col_type2 [COMMENT col_comment2], ...)] [ROW FORMAT row_format] [STORED AS file_format] [LOCATION path] [TBLPROPERTIES (key1=val1, key2=val2, ...)] ``` ## How was this patch tested? Added test cases Author: gatorsmile <[email protected]> Closes #20133 from gatorsmile/createDataSourceTableDDL. -
[SPARK-20236][SQL] dynamic partition overwrite
## What changes were proposed in this pull request? When overwriting a partitioned table with dynamic partition columns, the behavior is different between data source and hive tables. data source table: delete all partition directories that match the static partition values provided in the insert statement. hive table: only delete partition directories which have data written into it This PR adds a new config to make users be able to choose hive's behavior. ## How was this patch tested? new tests Author: Wenchen Fan <[email protected]> Closes #18714 from cloud-fan/overwrite-partition.
-
[SPARK-22896] Improvement in String interpolation
## What changes were proposed in this pull request? * String interpolation in ml pipeline example has been corrected as per scala standard. ## How was this patch tested? * manually tested. Author: chetkhatri <[email protected]> Closes #20070 from chetkhatri/mllib-chetan-contrib.
-
[SPARK-20960][SQL] make ColumnVector public
## What changes were proposed in this pull request? move `ColumnVector` and related classes to `org.apache.spark.sql.vectorized`, and improve the document. ## How was this patch tested? existing tests. Author: Wenchen Fan <[email protected]> Closes #20116 from cloud-fan/column-vector.
Commits on Jan 4, 2018
-
[SPARK-22944][SQL] improve FoldablePropagation
## What changes were proposed in this pull request? `FoldablePropagation` is a little tricky as it needs to handle attributes that are miss-derived from children, e.g. outer join outputs. This rule does a kind of stop-able tree transform, to skip to apply this rule when hit a node which may have miss-derived attributes. Logically we should be able to apply this rule above the unsupported nodes, by just treating the unsupported nodes as leaf nodes. This PR improves this rule to not stop the tree transformation, but reduce the foldable expressions that we want to propagate. ## How was this patch tested? existing tests Author: Wenchen Fan <[email protected]> Closes #20139 from cloud-fan/foldable.
-
[SPARK-22933][SPARKR] R Structured Streaming API for withWatermark, t…
…rigger, partitionBy ## What changes were proposed in this pull request? R Structured Streaming API for withWatermark, trigger, partitionBy ## How was this patch tested? manual, unit tests Author: Felix Cheung <[email protected]> Closes #20129 from felixcheung/rwater.
-
[SPARK-22950][SQL] Handle ChildFirstURLClassLoader's parent
## What changes were proposed in this pull request? ChildFirstClassLoader's parent is set to null, so we can't get jars from its parent. This will cause ClassNotFoundException during HiveClient initialization with builtin hive jars, where we may should use spark context loader instead. ## How was this patch tested? add new ut cc cloud-fan gatorsmile Author: Kent Yao <[email protected]> Closes #20145 from yaooqinn/SPARK-22950.
-
[SPARK-22945][SQL] add java UDF APIs in the functions object
## What changes were proposed in this pull request? Currently Scala users can use UDF like ``` val foo = udf((i: Int) => Math.random() + i).asNondeterministic df.select(foo('a)) ``` Python users can also do it with similar APIs. However Java users can't do it, we should add Java UDF APIs in the functions object. ## How was this patch tested? new tests Author: Wenchen Fan <[email protected]> Closes #20141 from cloud-fan/udf. -
[SPARK-22939][PYSPARK] Support Spark UDF in registerFunction
## What changes were proposed in this pull request? ```Python import random from pyspark.sql.functions import udf from pyspark.sql.types import IntegerType, StringType random_udf = udf(lambda: int(random.random() * 100), IntegerType()).asNondeterministic() spark.catalog.registerFunction("random_udf", random_udf, StringType()) spark.sql("SELECT random_udf()").collect() ``` We will get the following error. ``` Py4JError: An error occurred while calling o29.__getnewargs__. Trace: py4j.Py4JException: Method __getnewargs__([]) does not exist at py4j.reflection.ReflectionEngine.getMethod(ReflectionEngine.java:318) at py4j.reflection.ReflectionEngine.getMethod(ReflectionEngine.java:326) at py4j.Gateway.invoke(Gateway.java:274) at py4j.commands.AbstractCommand.invokeMethod(AbstractCommand.java:132) at py4j.commands.CallCommand.execute(CallCommand.java:79) at py4j.GatewayConnection.run(GatewayConnection.java:214) at java.lang.Thread.run(Thread.java:745) ``` This PR is to support it. ## How was this patch tested? WIP Author: gatorsmile <[email protected]> Closes #20137 from gatorsmile/registerFunction. -
[SPARK-22771][SQL] Add a missing return statement in Concat.checkInpu…
…tDataTypes ## What changes were proposed in this pull request? This pr is a follow-up to fix a bug left in #19977. ## How was this patch tested? Added tests in `StringExpressionsSuite`. Author: Takeshi Yamamuro <[email protected]> Closes #20149 from maropu/SPARK-22771-FOLLOWUP.
-
[SPARK-21475][CORE][2ND ATTEMPT] Change to use NIO's Files API for ex…
…ternal shuffle service ## What changes were proposed in this pull request? This PR is the second attempt of #18684 , NIO's Files API doesn't override `skip` method for `InputStream`, so it will bring in performance issue (mentioned in #20119). But using `FileInputStream`/`FileOutputStream` will also bring in memory issue (https://dzone.com/articles/fileinputstream-fileoutputstream-considered-harmful), which is severe for long running external shuffle service. So here in this proposal, only fixing the external shuffle service related code. ## How was this patch tested? Existing tests. Author: jerryshao <[email protected]> Closes #20144 from jerryshao/SPARK-21475-v2.
-
[SPARK-22850][CORE] Ensure queued events are delivered to all event q…
…ueues. The code in LiveListenerBus was queueing events before start in the queues themselves; so in situations like the following: bus.post(someEvent) bus.addToEventLogQueue(listener) bus.start() "someEvent" would not be delivered to "listener" if that was the first listener in the queue, because the queue wouldn't exist when the event was posted. This change buffers the events before starting the bus in the bus itself, so that they can be delivered to all registered queues when the bus is started. Also tweaked the unit tests to cover the behavior above. Author: Marcelo Vanzin <[email protected]> Closes #20039 from vanzin/SPARK-22850.
-
[SPARK-22953][K8S] Avoids adding duplicated secret volumes when init-…
…container is used ## What changes were proposed in this pull request? User-specified secrets are mounted into both the main container and init-container (when it is used) in a Spark driver/executor pod, using the `MountSecretsBootstrap`. Because `MountSecretsBootstrap` always adds new secret volumes for the secrets to the pod, the same secret volumes get added twice, one when mounting the secrets to the main container, and the other when mounting the secrets to the init-container. This PR fixes the issue by separating `MountSecretsBootstrap.mountSecrets` out into two methods: `addSecretVolumes` for adding secret volumes to a pod and `mountSecrets` for mounting secret volumes to a container, respectively. `addSecretVolumes` is only called once for each pod, whereas `mountSecrets` is called individually for the main container and the init-container (if it is used). Ref: apache-spark-on-k8s#594. ## How was this patch tested? Unit tested and manually tested. vanzin This replaces #20148. hex108 foxish kimoonkim Author: Yinan Li <[email protected]> Closes #20159 from liyinan926/master.
Commits on Jan 5, 2018
-
[SPARK-22957] ApproxQuantile breaks if the number of rows exceeds MaxInt
## What changes were proposed in this pull request? 32bit Int was used for row rank. That overflowed in a dataframe with more than 2B rows. ## How was this patch tested? Added test, but ignored, as it takes 4 minutes. Author: Juliusz Sompolski <[email protected]> Closes #20152 from juliuszsompolski/SPARK-22957.
-
[SPARK-22825][SQL] Fix incorrect results of Casting Array to String
## What changes were proposed in this pull request? This pr fixed the issue when casting arrays into strings; ``` scala> val df = spark.range(10).select('id.cast("integer")).agg(collect_list('id).as('ids)) scala> df.write.saveAsTable("t") scala> sql("SELECT cast(ids as String) FROM t").show(false) +------------------------------------------------------------------+ |ids | +------------------------------------------------------------------+ |org.apache.spark.sql.catalyst.expressions.UnsafeArrayData8bc285df| +------------------------------------------------------------------+ ``` This pr modified the result into; ``` +------------------------------+ |ids | +------------------------------+ |[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]| +------------------------------+ ``` ## How was this patch tested? Added tests in `CastSuite` and `SQLQuerySuite`. Author: Takeshi Yamamuro <[email protected]> Closes #20024 from maropu/SPARK-22825. -
[SPARK-22949][ML] Apply CrossValidator approach to Driver/Distributed…
… memory tradeoff for TrainValidationSplit ## What changes were proposed in this pull request? Avoid holding all models in memory for `TrainValidationSplit`. ## How was this patch tested? Existing tests. Author: Bago Amirbekian <[email protected]> Closes #20143 from MrBago/trainValidMemoryFix.
-
[SPARK-22757][K8S] Enable spark.jars and spark.files in KUBERNETES mode
## What changes were proposed in this pull request? We missed enabling `spark.files` and `spark.jars` in #19954. The result is that remote dependencies specified through `spark.files` or `spark.jars` are not included in the list of remote dependencies to be downloaded by the init-container. This PR fixes it. ## How was this patch tested? Manual tests. vanzin This replaces #20157. foxish Author: Yinan Li <[email protected]> Closes #20160 from liyinan926/SPARK-22757.
-
[SPARK-22961][REGRESSION] Constant columns should generate QueryPlanC…
…onstraints ## What changes were proposed in this pull request? #19201 introduced the following regression: given something like `df.withColumn("c", lit(2))`, we're no longer picking up `c === 2` as a constraint and infer filters from it when joins are involved, which may lead to noticeable performance degradation. This patch re-enables this optimization by picking up Aliases of Literals in Projection lists as constraints and making sure they're not treated as aliased columns. ## How was this patch tested? Unit test was added. Author: Adrian Ionescu <[email protected]> Closes #20155 from adrian-ionescu/constant_constraints.
-
[SPARK-22940][SQL] HiveExternalCatalogVersionsSuite should succeed on…
… platforms that don't have wget ## What changes were proposed in this pull request? Modified HiveExternalCatalogVersionsSuite.scala to use Utils.doFetchFile to download different versions of Spark binaries rather than launching wget as an external process. On platforms that don't have wget installed, this suite fails with an error. cloud-fan : would you like to check this change? ## How was this patch tested? 1) test-only of HiveExternalCatalogVersionsSuite on several platforms. Tested bad mirror, read timeout, and redirects. 2) ./dev/run-tests Author: Bruce Robbins <[email protected]> Closes #20147 from bersprockets/SPARK-22940-alt.
-
[SPARK-13030][ML] Follow-up cleanups for OneHotEncoderEstimator
## What changes were proposed in this pull request? Follow-up cleanups for the OneHotEncoderEstimator PR. See some discussion in the original PR: #19527 or read below for what this PR includes: * configedCategorySize: I reverted this to return an Array. I realized the original setup (which I had recommended in the original PR) caused the whole model to be serialized in the UDF. * encoder: I reorganized the logic to show what I meant in the comment in the previous PR. I think it's simpler but am open to suggestions. I also made some small style cleanups based on IntelliJ warnings. ## How was this patch tested? Existing unit tests Author: Joseph K. Bradley <[email protected]> Closes #20132 from jkbradley/viirya-SPARK-13030.
Commits on Jan 6, 2018
-
[SPARK-22914][DEPLOY] Register history.ui.port
## What changes were proposed in this pull request? Register spark.history.ui.port as a known spark conf to be used in substitution expressions even if it's not set explicitly. ## How was this patch tested? Added unit test to demonstrate the issue Author: Gera Shegalov <[email protected]> Author: Gera Shegalov <[email protected]> Closes #20098 from gerashegalov/gera/register-SHS-port-conf.
-
[SPARK-22937][SQL] SQL elt output binary for binary inputs
## What changes were proposed in this pull request? This pr modified `elt` to output binary for binary inputs. `elt` in the current master always output data as a string. But, in some databases (e.g., MySQL), if all inputs are binary, `elt` also outputs binary (Also, this might be a small surprise). This pr is related to #19977. ## How was this patch tested? Added tests in `SQLQueryTestSuite` and `TypeCoercionSuite`. Author: Takeshi Yamamuro <[email protected]> Closes #20135 from maropu/SPARK-22937.
-
[SPARK-22960][K8S] Revert use of ARG base_image in images
## What changes were proposed in this pull request? This PR reverts the `ARG base_image` before `FROM` in the images of driver, executor, and init-container, introduced in #20154. The reason is Docker versions before 17.06 do not support this use (`ARG` before `FROM`). ## How was this patch tested? Tested manually. vanzin foxish kimoonkim Author: Yinan Li <[email protected]> Closes #20170 from liyinan926/master.
-
[SPARK-22930][PYTHON][SQL] Improve the description of Vectorized UDFs…
… for non-deterministic cases ## What changes were proposed in this pull request? Add tests for using non deterministic UDFs in aggregate. Update pandas_udf docstring w.r.t to determinism. ## How was this patch tested? test_nondeterministic_udf_in_aggregate Author: Li Jin <[email protected]> Closes #20142 from icexelloss/SPARK-22930-pandas-udf-deterministic.
-
[SPARK-22793][SQL] Memory leak in Spark Thrift Server
# What changes were proposed in this pull request? 1. Start HiveThriftServer2. 2. Connect to thriftserver through beeline. 3. Close the beeline. 4. repeat step2 and step 3 for many times. we found there are many directories never be dropped under the path `hive.exec.local.scratchdir` and `hive.exec.scratchdir`, as we know the scratchdir has been added to deleteOnExit when it be created. So it means that the cache size of FileSystem `deleteOnExit` will keep increasing until JVM terminated. In addition, we use `jmap -histo:live [PID]` to printout the size of objects in HiveThriftServer2 Process, we can find the object `org.apache.spark.sql.hive.client.HiveClientImpl` and `org.apache.hadoop.hive.ql.session.SessionState` keep increasing even though we closed all the beeline connections, which may caused the leak of Memory. # How was this patch tested? manual tests This PR follw-up the #19989 Author: zuotingbing <[email protected]> Closes #20029 from zuotingbing/SPARK-22793.
-
[SPARK-21786][SQL] When acquiring 'compressionCodecClassName' in 'Par…
…quetOptions', `parquet.compression` needs to be considered. [SPARK-21786][SQL] When acquiring 'compressionCodecClassName' in 'ParquetOptions', `parquet.compression` needs to be considered. ## What changes were proposed in this pull request? Since Hive 1.1, Hive allows users to set parquet compression codec via table-level properties parquet.compression. See the JIRA: https://issues.apache.org/jira/browse/HIVE-7858 . We do support orc.compression for ORC. Thus, for external users, it is more straightforward to support both. See the stackflow question: https://stackoverflow.com/questions/36941122/spark-sql-ignores-parquet-compression-propertie-specified-in-tblproperties In Spark side, our table-level compression conf compression was added by #11464 since Spark 2.0. We need to support both table-level conf. Users might also use session-level conf spark.sql.parquet.compression.codec. The priority rule will be like If other compression codec configuration was found through hive or parquet, the precedence would be compression, parquet.compression, spark.sql.parquet.compression.codec. Acceptable values include: none, uncompressed, snappy, gzip, lzo. The rule for Parquet is consistent with the ORC after the change. Changes: 1.Increased acquiring 'compressionCodecClassName' from `parquet.compression`,and the precedence order is `compression`,`parquet.compression`,`spark.sql.parquet.compression.codec`, just like what we do in `OrcOptions`. 2.Change `spark.sql.parquet.compression.codec` to support "none".Actually in `ParquetOptions`,we do support "none" as equivalent to "uncompressed", but it does not allowed to configured to "none". 3.Change `compressionCode` to `compressionCodecClassName`. ## How was this patch tested? Add test. Author: fjh100456 <[email protected]> Closes #20076 from fjh100456/ParquetOptionIssue.
-
[SPARK-22901][PYTHON][FOLLOWUP] Adds the doc for asNondeterministic f…
…or wrapped UDF function ## What changes were proposed in this pull request? This PR wraps the `asNondeterministic` attribute in the wrapped UDF function to set the docstring properly. ```python from pyspark.sql.functions import udf help(udf(lambda x: x).asNondeterministic) ``` Before: ``` Help on function <lambda> in module pyspark.sql.udf: <lambda> lambda (END ``` After: ``` Help on function asNondeterministic in module pyspark.sql.udf: asNondeterministic() Updates UserDefinedFunction to nondeterministic. .. versionadded:: 2.3 (END) ``` ## How was this patch tested? Manually tested and a simple test was added. Author: hyukjinkwon <[email protected]> Closes #20173 from HyukjinKwon/SPARK-22901-followup. -
[HOTFIX] Fix style checking failure
## What changes were proposed in this pull request? This PR is to fix the style checking failure. ## How was this patch tested? N/A Author: gatorsmile <[email protected]> Closes #20175 from gatorsmile/stylefix.
Commits on Jan 7, 2018
-
[SPARK-22973][SQL] Fix incorrect results of Casting Map to String
## What changes were proposed in this pull request? This pr fixed the issue when casting maps into strings; ``` scala> Seq(Map(1 -> "a", 2 -> "b")).toDF("a").write.saveAsTable("t") scala> sql("SELECT cast(a as String) FROM t").show(false) +----------------------------------------------------------------+ |a | +----------------------------------------------------------------+ |org.apache.spark.sql.catalyst.expressions.UnsafeMapData38bdd75d| +----------------------------------------------------------------+ ``` This pr modified the result into; ``` +----------------+ |a | +----------------+ |[1 -> a, 2 -> b]| +----------------+ ``` ## How was this patch tested? Added tests in `CastSuite`. Author: Takeshi Yamamuro <[email protected]> Closes #20166 from maropu/SPARK-22973.
Commits on Jan 8, 2018
-
[SPARK-22985] Fix argument escaping bug in from_utc_timestamp / to_ut…
…c_timestamp codegen ## What changes were proposed in this pull request? This patch adds additional escaping in `from_utc_timestamp` / `to_utc_timestamp` expression codegen in order to a bug where invalid timezones which contain special characters could cause generated code to fail to compile. ## How was this patch tested? New regression tests in `DateExpressionsSuite`. Author: Josh Rosen <[email protected]> Closes #20182 from JoshRosen/SPARK-22985-fix-utc-timezone-function-escaping-bugs.
-
[SPARK-22566][PYTHON] Better error message for
_merge_typein Panda……s to Spark DF conversion ## What changes were proposed in this pull request? It provides a better error message when doing `spark_session.createDataFrame(pandas_df)` with no schema and an error occurs in the schema inference due to incompatible types. The Pandas column names are propagated down and the error message mentions which column had the merging error. https://issues.apache.org/jira/browse/SPARK-22566 ## How was this patch tested? Manually in the `./bin/pyspark` console, and with new tests: `./python/run-tests` <img width="873" alt="screen shot 2017-11-21 at 13 29 49" src="https://user-images.githubusercontent.com/3977115/33080121-382274e0-cecf-11e7-808f-057a65bb7b00.png"> I state that the contribution is my original work and that I license the work to the Apache Spark project under the project’s open source license. Author: Guilherme Berger <[email protected]> Closes #19792 from gberger/master.
-
[SPARK-22979][PYTHON][SQL] Avoid per-record type dispatch in Python d…
…ata conversion (EvaluatePython.fromJava) ## What changes were proposed in this pull request? Seems we can avoid type dispatch for each value when Java objection (from Pyrolite) -> Spark's internal data format because we know the schema ahead. I manually performed the benchmark as below: ```scala test("EvaluatePython.fromJava / EvaluatePython.makeFromJava") { val numRows = 1000 * 1000 val numFields = 30 val random = new Random(System.nanoTime()) val types = Array( BooleanType, ByteType, FloatType, DoubleType, IntegerType, LongType, ShortType, DecimalType.ShortDecimal, DecimalType.IntDecimal, DecimalType.ByteDecimal, DecimalType.FloatDecimal, DecimalType.LongDecimal, new DecimalType(5, 2), new DecimalType(12, 2), new DecimalType(30, 10), CalendarIntervalType) val schema = RandomDataGenerator.randomSchema(random, numFields, types) val rows = mutable.ArrayBuffer.empty[Array[Any]] var i = 0 while (i < numRows) { val row = RandomDataGenerator.randomRow(random, schema) rows += row.toSeq.toArray i += 1 } val benchmark = new Benchmark("EvaluatePython.fromJava / EvaluatePython.makeFromJava", numRows) benchmark.addCase("Before - EvaluatePython.fromJava", 3) { _ => var i = 0 while (i < numRows) { EvaluatePython.fromJava(rows(i), schema) i += 1 } } benchmark.addCase("After - EvaluatePython.makeFromJava", 3) { _ => val fromJava = EvaluatePython.makeFromJava(schema) var i = 0 while (i < numRows) { fromJava(rows(i)) i += 1 } } benchmark.run() } ``` ``` EvaluatePython.fromJava / EvaluatePython.makeFromJava: Best/Avg Time(ms) Rate(M/s) Per Row(ns) Relative ------------------------------------------------------------------------------------------------ Before - EvaluatePython.fromJava 1265 / 1346 0.8 1264.8 1.0X After - EvaluatePython.makeFromJava 571 / 649 1.8 570.8 2.2X ``` If the structure is nested, I think the advantage should be larger than this. ## How was this patch tested? Existing tests should cover this. Also, I manually checked if the values from before / after are actually same via `assert` when performing the benchmarks. Author: hyukjinkwon <[email protected]> Closes #20172 from HyukjinKwon/type-dispatch-python-eval. -
[SPARK-22983] Don't push filters beneath aggregates with empty groupi…
…ng expressions ## What changes were proposed in this pull request? The following SQL query should return zero rows, but in Spark it actually returns one row: ``` SELECT 1 from ( SELECT 1 AS z, MIN(a.x) FROM (select 1 as x) a WHERE false ) b where b.z != b.z ``` The problem stems from the `PushDownPredicate` rule: when this rule encounters a filter on top of an Aggregate operator, e.g. `Filter(Agg(...))`, it removes the original filter and adds a new filter onto Aggregate's child, e.g. `Agg(Filter(...))`. This is sometimes okay, but the case above is a counterexample: because there is no explicit `GROUP BY`, we are implicitly computing a global aggregate over the entire table so the original filter was not acting like a `HAVING` clause filtering the number of groups: if we push this filter then it fails to actually reduce the cardinality of the Aggregate output, leading to the wrong answer. In 2016 I fixed a similar problem involving invalid pushdowns of data-independent filters (filters which reference no columns of the filtered relation). There was additional discussion after my fix was merged which pointed out that my patch was an incomplete fix (see #15289), but it looks I must have either misunderstood the comment or forgot to follow up on the additional points raised there. This patch fixes the problem by choosing to never push down filters in cases where there are no grouping expressions. Since there are no grouping keys, the only columns are aggregate columns and we can't push filters defined over aggregate results, so this change won't cause us to miss out on any legitimate pushdown opportunities. ## How was this patch tested? New regression tests in `SQLQueryTestSuite` and `FilterPushdownSuite`. Author: Josh Rosen <[email protected]> Closes #20180 from JoshRosen/SPARK-22983-dont-push-filters-beneath-aggs-with-empty-grouping-expressions.
-
[SPARK-21865][SQL] simplify the distribution semantic of Spark SQL
## What changes were proposed in this pull request? **The current shuffle planning logic** 1. Each operator specifies the distribution requirements for its children, via the `Distribution` interface. 2. Each operator specifies its output partitioning, via the `Partitioning` interface. 3. `Partitioning.satisfy` determines whether a `Partitioning` can satisfy a `Distribution`. 4. For each operator, check each child of it, add a shuffle node above the child if the child partitioning can not satisfy the required distribution. 5. For each operator, check if its children's output partitionings are compatible with each other, via the `Partitioning.compatibleWith`. 6. If the check in 5 failed, add a shuffle above each child. 7. try to eliminate the shuffles added in 6, via `Partitioning.guarantees`. This design has a major problem with the definition of "compatible". `Partitioning.compatibleWith` is not well defined, ideally a `Partitioning` can't know if it's compatible with other `Partitioning`, without more information from the operator. For example, `t1 join t2 on t1.a = t2.b`, `HashPartitioning(a, 10)` should be compatible with `HashPartitioning(b, 10)` under this case, but the partitioning itself doesn't know it. As a result, currently `Partitioning.compatibleWith` always return false except for literals, which make it almost useless. This also means, if an operator has distribution requirements for multiple children, Spark always add shuffle nodes to all the children(although some of them can be eliminated). However, there is no guarantee that the children's output partitionings are compatible with each other after adding these shuffles, we just assume that the operator will only specify `ClusteredDistribution` for multiple children. I think it's very hard to guarantee children co-partition for all kinds of operators, and we can not even give a clear definition about co-partition between distributions like `ClusteredDistribution(a,b)` and `ClusteredDistribution(c)`. I think we should drop the "compatible" concept in the distribution model, and let the operator achieve the co-partition requirement by special distribution requirements. **Proposed shuffle planning logic after this PR** (The first 4 are same as before) 1. Each operator specifies the distribution requirements for its children, via the `Distribution` interface. 2. Each operator specifies its output partitioning, via the `Partitioning` interface. 3. `Partitioning.satisfy` determines whether a `Partitioning` can satisfy a `Distribution`. 4. For each operator, check each child of it, add a shuffle node above the child if the child partitioning can not satisfy the required distribution. 5. For each operator, check if its children's output partitionings have the same number of partitions. 6. If the check in 5 failed, pick the max number of partitions from children's output partitionings, and add shuffle to child whose number of partitions doesn't equal to the max one. The new distribution model is very simple, we only have one kind of relationship, which is `Partitioning.satisfy`. For multiple children, Spark only guarantees they have the same number of partitions, and it's the operator's responsibility to leverage this guarantee to achieve more complicated requirements. For example, non-broadcast joins can use the newly added `HashPartitionedDistribution` to achieve co-partition. ## How was this patch tested? existing tests. Author: Wenchen Fan <[email protected]> Closes #19080 from cloud-fan/exchange.
-
[SPARK-22952][CORE] Deprecate stageAttemptId in favour of stageAttemp…
…tNumber ## What changes were proposed in this pull request? 1. Deprecate attemptId in StageInfo and add `def attemptNumber() = attemptId` 2. Replace usage of stageAttemptId with stageAttemptNumber ## How was this patch tested? I manually checked the compiler warning info Author: Xianjin YE <[email protected]> Closes #20178 from advancedxy/SPARK-22952.
-
[SPARK-22992][K8S] Remove assumption of the DNS domain
## What changes were proposed in this pull request? Remove the use of FQDN to access the driver because it assumes that it's set up in a DNS zone - `cluster.local` which is common but not ubiquitous Note that we already access the in-cluster API server through `kubernetes.default.svc`, so, by extension, this should work as well. The alternative is to introduce DNS zones for both of those addresses. ## How was this patch tested? Unit tests cc vanzin liyinan926 mridulm mccheah Author: foxish <[email protected]> Closes #20187 from foxish/cluster.local.
-
[SPARK-22912] v2 data source support in MicroBatchExecution
## What changes were proposed in this pull request? Support for v2 data sources in microbatch streaming. ## How was this patch tested? A very basic new unit test on the toy v2 implementation of rate source. Once we have a v1 source fully migrated to v2, we'll need to do more detailed compatibility testing. Author: Jose Torres <[email protected]> Closes #20097 from jose-torres/v2-impl.
{kind=link}
Commits on Jan 9, 2018
-
[SPARK-22972] Couldn't find corresponding Hive SerDe for data source …
…provider org.apache.spark.sql.hive.orc ## What changes were proposed in this pull request? Fix the warning: Couldn't find corresponding Hive SerDe for data source provider org.apache.spark.sql.hive.orc. ## How was this patch tested? test("SPARK-22972: hive orc source") assert(HiveSerDe.sourceToSerDe("org.apache.spark.sql.hive.orc") .equals(HiveSerDe.sourceToSerDe("orc"))) Author: xubo245 <[email protected]> Closes #20165 from xubo245/HiveSerDe. -
[SPARK-22990][CORE] Fix method isFairScheduler in JobsTab and StagesTab
## What changes were proposed in this pull request? In current implementation, the function `isFairScheduler` is always false, since it is comparing String with `SchedulingMode` Author: Wang Gengliang <[email protected]> Closes #20186 from gengliangwang/isFairScheduler.
-
[SPARK-22984] Fix incorrect bitmap copying and offset adjustment in G…
…enerateUnsafeRowJoiner ## What changes were proposed in this pull request? This PR fixes a longstanding correctness bug in `GenerateUnsafeRowJoiner`. This class was introduced in #7821 (July 2015 / Spark 1.5.0+) and is used to combine pairs of UnsafeRows in TungstenAggregationIterator, CartesianProductExec, and AppendColumns. ### Bugs fixed by this patch 1. **Incorrect combining of null-tracking bitmaps**: when concatenating two UnsafeRows, the implementation "Concatenate the two bitsets together into a single one, taking padding into account". If one row has no columns then it has a bitset size of 0, but the code was incorrectly assuming that if the left row had a non-zero number of fields then the right row would also have at least one field, so it was copying invalid bytes and and treating them as part of the bitset. I'm not sure whether this bug was also present in the original implementation or whether it was introduced in #7892 (which fixed another bug in this code). 2. **Incorrect updating of data offsets for null variable-length fields**: after updating the bitsets and copying fixed-length and variable-length data, we need to perform adjustments to the offsets pointing the start of variable length fields's data. The existing code was _conditionally_ adding a fixed offset to correct for the new length of the combined row, but it is unsafe to do this if the variable-length field has a null value: we always represent nulls by storing `0` in the fixed-length slot, but this code was incorrectly incrementing those values. This bug was present since the original version of `GenerateUnsafeRowJoiner`. ### Why this bug remained latent for so long The PR which introduced `GenerateUnsafeRowJoiner` features several randomized tests, including tests of the cases where one side of the join has no fields and where string-valued fields are null. However, the existing assertions were too weak to uncover this bug: - If a null field has a non-zero value in its fixed-length data slot then this will not cause problems for field accesses because the null-tracking bitmap should still be correct and we will not try to use the incorrect offset for anything. - If the null tracking bitmap is corrupted by joining against a row with no fields then the corruption occurs in field numbers past the actual field numbers contained in the row. Thus valid `isNullAt()` calls will not read the incorrectly-set bits. The existing `GenerateUnsafeRowJoinerSuite` tests only exercised `.get()` and `isNullAt()`, but didn't actually check the UnsafeRows for bit-for-bit equality, preventing these bugs from failing assertions. It turns out that there was even a [GenerateUnsafeRowJoinerBitsetSuite](https://github.com/apache/spark/blob/03377d2522776267a07b7d6ae9bddf79a4e0f516/sql/catalyst/src/test/scala/org/apache/spark/sql/catalyst/expressions/codegen/GenerateUnsafeRowJoinerBitsetSuite.scala) but it looks like it also didn't catch this problem because it only tested the bitsets in an end-to-end fashion by accessing them through the `UnsafeRow` interface instead of actually comparing the bitsets' bytes. ### Impact of these bugs - This bug will cause `equals()` and `hashCode()` to be incorrect for these rows, which will be problematic in case`GenerateUnsafeRowJoiner`'s results are used as join or grouping keys. - Chained / repeated invocations of `GenerateUnsafeRowJoiner` may result in reads from invalid null bitmap positions causing fields to incorrectly become NULL (see the end-to-end example below). - It looks like this generally only happens in `CartesianProductExec`, which our query optimizer often avoids executing (usually we try to plan a `BroadcastNestedLoopJoin` instead). ### End-to-end test case demonstrating the problem The following query demonstrates how this bug may result in incorrect query results: ```sql set spark.sql.autoBroadcastJoinThreshold=-1; -- Needed to trigger CartesianProductExec create table a as select * from values 1; create table b as select * from values 2; SELECT t3.col1, t1.col1 FROM a t1 CROSS JOIN b t2 CROSS JOIN b t3 ``` This should return `(2, 1)` but instead was returning `(null, 1)`. Column pruning ends up trimming off all columns from `t2`, so when `t2` joins with another table this triggers the bitmap-copying bug. This incorrect bitmap is subsequently copied again when performing the final join, causing the final output to have an incorrectly-set null bit for the first field. ## How was this patch tested? Strengthened the assertions in existing tests in GenerateUnsafeRowJoinerSuite. Also verified that the end-to-end test case which uncovered this now passes. Author: Josh Rosen <[email protected]> Closes #20181 from JoshRosen/SPARK-22984-fix-generate-unsaferow-joiner-bitmap-bugs.
-
[SPARK-21292][DOCS] refreshtable example
## What changes were proposed in this pull request? doc update Author: Felix Cheung <[email protected]> Closes #20198 from felixcheung/rrefreshdoc.
-
[SPARK-21293][SPARKR][DOCS] structured streaming doc update
## What changes were proposed in this pull request? doc update Author: Felix Cheung <[email protected]> Closes #20197 from felixcheung/rwadoc.
-
[SPARK-23000] Fix Flaky test suite DataSourceWithHiveMetastoreCatalog…
…Suite in Spark 2.3 ## What changes were proposed in this pull request? https://amplab.cs.berkeley.edu/jenkins/job/spark-branch-2.3-test-sbt-hadoop-2.6/ The test suite DataSourceWithHiveMetastoreCatalogSuite of Branch 2.3 always failed in hadoop 2.6 The table `t` exists in `default`, but `runSQLHive` reported the table does not exist. Obviously, Hive client's default database is different. The fix is to clean the environment and use `DEFAULT` as the database. ``` org.apache.spark.sql.execution.QueryExecutionException: FAILED: SemanticException [Error 10001]: Line 1:14 Table not found 't' Stacktrace sbt.ForkMain$ForkError: org.apache.spark.sql.execution.QueryExecutionException: FAILED: SemanticException [Error 10001]: Line 1:14 Table not found 't' at org.apache.spark.sql.hive.client.HiveClientImpl$$anonfun$runHive$1.apply(HiveClientImpl.scala:699) at org.apache.spark.sql.hive.client.HiveClientImpl$$anonfun$runHive$1.apply(HiveClientImpl.scala:683) at org.apache.spark.sql.hive.client.HiveClientImpl$$anonfun$withHiveState$1.apply(HiveClientImpl.scala:272) at org.apache.spark.sql.hive.client.HiveClientImpl.liftedTree1$1(HiveClientImpl.scala:210) at org.apache.spark.sql.hive.client.HiveClientImpl.retryLocked(HiveClientImpl.scala:209) at org.apache.spark.sql.hive.client.HiveClientImpl.withHiveState(HiveClientImpl.scala:255) at org.apache.spark.sql.hive.client.HiveClientImpl.runHive(HiveClientImpl.scala:683) at org.apache.spark.sql.hive.client.HiveClientImpl.runSqlHive(HiveClientImpl.scala:673) ``` ## How was this patch tested? N/A Author: gatorsmile <[email protected]> Closes #20196 from gatorsmile/testFix.
-
[SPARK-22998][K8S] Set missing value for SPARK_MOUNTED_CLASSPATH in t…
…he executors ## What changes were proposed in this pull request? The environment variable `SPARK_MOUNTED_CLASSPATH` is referenced in the executor's Dockerfile, where its value is added to the classpath of the executor. However, the scheduler backend code missed setting it when creating the executor pods. This PR fixes it. ## How was this patch tested? Unit tested. vanzin Can you help take a look? Thanks! foxish Author: Yinan Li <[email protected]> Closes #20193 from liyinan926/master.
-
[SPARK-16060][SQL] Support Vectorized ORC Reader
## What changes were proposed in this pull request? This PR adds an ORC columnar-batch reader to native `OrcFileFormat`. Since both Spark `ColumnarBatch` and ORC `RowBatch` are used together, it is faster than the current Spark implementation. This replaces the prior PR, #17924. Also, this PR adds `OrcReadBenchmark` to show the performance improvement. ## How was this patch tested? Pass the existing test cases. Author: Dongjoon Hyun <[email protected]> Closes #19943 from dongjoon-hyun/SPARK-16060.
-
[SPARK-22981][SQL] Fix incorrect results of Casting Struct to String
## What changes were proposed in this pull request? This pr fixed the issue when casting structs into strings; ``` scala> val df = Seq(((1, "a"), 0), ((2, "b"), 0)).toDF("a", "b") scala> df.write.saveAsTable("t") scala> sql("SELECT CAST(a AS STRING) FROM t").show +-------------------+ | a| +-------------------+ |[0,1,1800000001,61]| |[0,2,1800000001,62]| +-------------------+ ``` This pr modified the result into; ``` +------+ | a| +------+ |[1, a]| |[2, b]| +------+ ``` ## How was this patch tested? Added tests in `CastSuite`. Author: Takeshi Yamamuro <[email protected]> Closes #20176 from maropu/SPARK-22981.
Commits on Jan 10, 2018
-
[SPARK-23005][CORE] Improve RDD.take on small number of partitions
## What changes were proposed in this pull request? In current implementation of RDD.take, we overestimate the number of partitions we need to try by 50%: `(1.5 * num * partsScanned / buf.size).toInt` However, when the number is small, the result of `.toInt` is not what we want. E.g, 2.9 will become 2, which should be 3. Use Math.ceil to fix the problem. Also clean up the code in RDD.scala. ## How was this patch tested? Unit test Author: Wang Gengliang <[email protected]> Closes #20200 from gengliangwang/Take.
-
[MINOR] fix a typo in BroadcastJoinSuite
## What changes were proposed in this pull request? `BroadcastNestedLoopJoinExec` should be `BroadcastHashJoinExec` ## How was this patch tested? N/A Author: Wenchen Fan <[email protected]> Closes #20202 from cloud-fan/typo.
-
[SPARK-23018][PYTHON] Fix createDataFrame from Pandas timestamp serie…
…s assignment ## What changes were proposed in this pull request? This fixes createDataFrame from Pandas to only assign modified timestamp series back to a copied version of the Pandas DataFrame. Previously, if the Pandas DataFrame was only a reference (e.g. a slice of another) each series will still get assigned back to the reference even if it is not a modified timestamp column. This caused the following warning "SettingWithCopyWarning: A value is trying to be set on a copy of a slice from a DataFrame." ## How was this patch tested? existing tests Author: Bryan Cutler <[email protected]> Closes #20213 from BryanCutler/pyspark-createDataFrame-copy-slice-warn-SPARK-23018.
-
[SPARK-23009][PYTHON] Fix for non-str col names to createDataFrame fr…
…om Pandas ## What changes were proposed in this pull request? This the case when calling `SparkSession.createDataFrame` using a Pandas DataFrame that has non-str column labels. The column name conversion logic to handle non-string or unicode in python2 is: ``` if column is not any type of string: name = str(column) else if column is unicode in Python 2: name = column.encode('utf-8') ``` ## How was this patch tested? Added a new test with a Pandas DataFrame that has int column labels Author: Bryan Cutler <[email protected]> Closes #20210 from BryanCutler/python-createDataFrame-int-col-error-SPARK-23009. -
[SPARK-22982] Remove unsafe asynchronous close() call from FileDownlo…
…adChannel ## What changes were proposed in this pull request? This patch fixes a severe asynchronous IO bug in Spark's Netty-based file transfer code. At a high-level, the problem is that an unsafe asynchronous `close()` of a pipe's source channel creates a race condition where file transfer code closes a file descriptor then attempts to read from it. If the closed file descriptor's number has been reused by an `open()` call then this invalid read may cause unrelated file operations to return incorrect results. **One manifestation of this problem is incorrect query results.** For a high-level overview of how file download works, take a look at the control flow in `NettyRpcEnv.openChannel()`: this code creates a pipe to buffer results, then submits an asynchronous stream request to a lower-level TransportClient. The callback passes received data to the sink end of the pipe. The source end of the pipe is passed back to the caller of `openChannel()`. Thus `openChannel()` returns immediately and callers interact with the returned pipe source channel. Because the underlying stream request is asynchronous, errors may occur after `openChannel()` has returned and after that method's caller has started to `read()` from the returned channel. For example, if a client requests an invalid stream from a remote server then the "stream does not exist" error may not be received from the remote server until after `openChannel()` has returned. In order to be able to propagate the "stream does not exist" error to the file-fetching application thread, this code wraps the pipe's source channel in a special `FileDownloadChannel` which adds an `setError(t: Throwable)` method, then calls this `setError()` method in the FileDownloadCallback's `onFailure` method. It is possible for `FileDownloadChannel`'s `read()` and `setError()` methods to be called concurrently from different threads: the `setError()` method is called from within the Netty RPC system's stream callback handlers, while the `read()` methods are called from higher-level application code performing remote stream reads. The problem lies in `setError()`: the existing code closed the wrapped pipe source channel. Because `read()` and `setError()` occur in different threads, this means it is possible for one thread to be calling `source.read()` while another asynchronously calls `source.close()`. Java's IO libraries do not guarantee that this will be safe and, in fact, it's possible for these operations to interleave in such a way that a lower-level `read()` system call occurs right after a `close()` call. In the best-case, this fails as a read of a closed file descriptor; in the worst-case, the file descriptor number has been re-used by an intervening `open()` operation and the read corrupts the result of an unrelated file IO operation being performed by a different thread. The solution here is to remove the `stream.close()` call in `onError()`: the thread that is performing the `read()` calls is responsible for closing the stream in a `finally` block, so there's no need to close it here. If that thread is blocked in a `read()` then it will become unblocked when the sink end of the pipe is closed in `FileDownloadCallback.onFailure()`. After making this change, we also need to refine the `read()` method to always check for a `setError()` result, even if the underlying channel `read()` call has succeeded. This patch also makes a slight cleanup to a dodgy-looking `catch e: Exception` block to use a safer `try-finally` error handling idiom. This bug was introduced in SPARK-11956 / #9941 and is present in Spark 1.6.0+. ## How was this patch tested? This fix was tested manually against a workload which non-deterministically hit this bug. Author: Josh Rosen <[email protected]> Closes #20179 from JoshRosen/SPARK-22982-fix-unsafe-async-io-in-file-download-channel.
-
[SPARK-16060][SQL][FOLLOW-UP] add a wrapper solution for vectorized o…
…rc reader ## What changes were proposed in this pull request? This is mostly from #13775 The wrapper solution is pretty good for string/binary type, as the ORC column vector doesn't keep bytes in a continuous memory region, and has a significant overhead when copying the data to Spark columnar batch. For other cases, the wrapper solution is almost same with the current solution. I think we can treat the wrapper solution as a baseline and keep improving the writing to Spark solution. ## How was this patch tested? existing tests. Author: Wenchen Fan <[email protected]> Closes #20205 from cloud-fan/orc.
-
[SPARK-22993][ML] Clarify HasCheckpointInterval param doc
## What changes were proposed in this pull request? Add a note to the `HasCheckpointInterval` parameter doc that clarifies that this setting is ignored when no checkpoint directory has been set on the spark context. ## How was this patch tested? No tests necessary, just a doc update. Author: sethah <[email protected]> Closes #20188 from sethah/als_checkpoint_doc.
-
[SPARK-22997] Add additional defenses against use of freed MemoryBlocks
## What changes were proposed in this pull request? This patch modifies Spark's `MemoryAllocator` implementations so that `free(MemoryBlock)` mutates the passed block to clear pointers (in the off-heap case) or null out references to backing `long[]` arrays (in the on-heap case). The goal of this change is to add an extra layer of defense against use-after-free bugs because currently it's hard to detect corruption caused by blind writes to freed memory blocks. ## How was this patch tested? New unit tests in `PlatformSuite`, including new tests for existing functionality because we did not have sufficient mutation coverage of the on-heap memory allocator's pooling logic. Author: Josh Rosen <[email protected]> Closes #20191 from JoshRosen/SPARK-22997-add-defenses-against-use-after-free-bugs-in-memory-allocator.
-
[SPARK-23019][CORE] Wait until SparkContext.stop() finished in SparkL…
…auncherSuite ## What changes were proposed in this pull request? In current code ,the function `waitFor` call https://github.com/apache/spark/blob/cfcd746689c2b84824745fa6d327ffb584c7a17d/core/src/test/java/org/apache/spark/launcher/SparkLauncherSuite.java#L155 only wait until DAGScheduler is stopped, while SparkContext.clearActiveContext may not be called yet. https://github.com/apache/spark/blob/1c9f95cb771ac78775a77edd1abfeb2d8ae2a124/core/src/main/scala/org/apache/spark/SparkContext.scala#L1924 Thus, in the Jenkins test https://amplab.cs.berkeley.edu/jenkins/job/spark-branch-2.3-test-maven-hadoop-2.6/ , `JdbcRDDSuite` failed because the previous test `SparkLauncherSuite` exit before SparkContext.stop() is finished. To repo: ``` $ build/sbt > project core > testOnly *SparkLauncherSuite *JavaJdbcRDDSuite ``` To Fix: Wait for a reasonable amount of time to avoid creating two active SparkContext in JVM in SparkLauncherSuite. Can' come up with any better solution for now. ## How was this patch tested? Unit test Author: Wang Gengliang <[email protected]> Closes #20221 from gengliangwang/SPARK-23019.
-
[SPARK-22951][SQL] fix aggregation after dropDuplicates on empty data…
… frames ## What changes were proposed in this pull request? (courtesy of liancheng) Spark SQL supports both global aggregation and grouping aggregation. Global aggregation always return a single row with the initial aggregation state as the output, even there are zero input rows. Spark implements this by simply checking the number of grouping keys and treats an aggregation as a global aggregation if it has zero grouping keys. However, this simple principle drops the ball in the following case: ```scala spark.emptyDataFrame.dropDuplicates().agg(count($"*") as "c").show() // +---+ // | c | // +---+ // | 1 | // +---+ ``` The reason is that: 1. `df.dropDuplicates()` is roughly translated into something equivalent to: ```scala val allColumns = df.columns.map { col } df.groupBy(allColumns: _*).agg(allColumns.head, allColumns.tail: _*) ``` This translation is implemented in the rule `ReplaceDeduplicateWithAggregate`. 2. `spark.emptyDataFrame` contains zero columns and zero rows. Therefore, rule `ReplaceDeduplicateWithAggregate` makes a confusing transformation roughly equivalent to the following one: ```scala spark.emptyDataFrame.dropDuplicates() => spark.emptyDataFrame.groupBy().agg(Map.empty[String, String]) ``` The above transformation is confusing because the resulting aggregate operator contains no grouping keys (because `emptyDataFrame` contains no columns), and gets recognized as a global aggregation. As a result, Spark SQL allocates a single row filled by the initial aggregation state and uses it as the output, and returns a wrong result. To fix this issue, this PR tweaks `ReplaceDeduplicateWithAggregate` by appending a literal `1` to the grouping key list of the resulting `Aggregate` operator when the input plan contains zero output columns. In this way, `spark.emptyDataFrame.dropDuplicates()` is now translated into a grouping aggregation, roughly depicted as: ```scala spark.emptyDataFrame.dropDuplicates() => spark.emptyDataFrame.groupBy(lit(1)).agg(Map.empty[String, String]) ``` Which is now properly treated as a grouping aggregation and returns the correct answer. ## How was this patch tested? New unit tests added Author: Feng Liu <[email protected]> Closes #20174 from liufengdb/fix-duplicate.
Commits on Jan 11, 2018
-
[SPARK-22587] Spark job fails if fs.defaultFS and application jar are…
… different url ## What changes were proposed in this pull request? Two filesystems comparing does not consider the authority of URI. This is specific for WASB file storage system, where userInfo is honored to differentiate filesystems. For example: wasbs://user1xyz.net, wasbs://user2xyz.net would consider as two filesystem. Therefore, we have to add the authority to compare two filesystem, and two filesystem with different authority can not be the same FS. Please review http://spark.apache.org/contributing.html before opening a pull request. Author: Mingjie Tang <[email protected]> Closes #19885 from merlintang/EAR-7377.
-
[SPARK-23001][SQL] Fix NullPointerException when DESC a database with…
… NULL description ## What changes were proposed in this pull request? When users' DB description is NULL, users might hit `NullPointerException`. This PR is to fix the issue. ## How was this patch tested? Added test cases Author: gatorsmile <[email protected]> Closes #20215 from gatorsmile/SPARK-23001.
-
[SPARK-20657][CORE] Speed up rendering of the stages page.
There are two main changes to speed up rendering of the tasks list when rendering the stage page. The first one makes the code only load the tasks being shown in the current page of the tasks table, and information related to only those tasks. One side-effect of this change is that the graph that shows task-related events now only shows events for the tasks in the current page, instead of the previously hardcoded limit of "events for the first 1000 tasks". That ends up helping with readability, though. To make sorting efficient when using a disk store, the task wrapper was extended to include many new indices, one for each of the sortable columns in the UI, and metrics for which quantiles are calculated. The second changes the way metric quantiles are calculated for stages. Instead of using the "Distribution" class to process data for all task metrics, which requires scanning all tasks of a stage, the code now uses the KVStore "skip()" functionality to only read tasks that contain interesting information for the quantiles that are desired. This is still not cheap; because there are many metrics that the UI and API track, the code needs to scan the index for each metric to gather the information. Savings come mainly from skipping deserialization when using the disk store, but the in-memory code also seems to be faster than before (most probably because of other changes in this patch). To make subsequent calls faster, some quantiles are cached in the status store. This makes UIs much faster after the first time a stage has been loaded. With the above changes, a lot of code in the UI layer could be simplified. Author: Marcelo Vanzin <[email protected]> Closes #20013 from vanzin/SPARK-20657.
-
[SPARK-22967][TESTS] Fix VersionSuite's unit tests by change Windows …
…path into URI path ## What changes were proposed in this pull request? Two unit test will fail due to Windows format path: 1.test(s"$version: read avro file containing decimal") ``` org.apache.hadoop.hive.ql.metadata.HiveException: MetaException(message:java.lang.IllegalArgumentException: Can not create a Path from an empty string); ``` 2.test(s"$version: SPARK-17920: Insert into/overwrite avro table") ``` Unable to infer the schema. The schema specification is required to create the table `default`.`tab2`.; org.apache.spark.sql.AnalysisException: Unable to infer the schema. The schema specification is required to create the table `default`.`tab2`.; ``` This pr fix these two unit test by change Windows path into URI path. ## How was this patch tested? Existed. Please review http://spark.apache.org/contributing.html before opening a pull request. Author: wuyi5 <[email protected]> Closes #20199 from Ngone51/SPARK-22967.
-
[SPARK-23000][TEST-HADOOP2.6] Fix Flaky test suite DataSourceWithHive…
…MetastoreCatalogSuite ## What changes were proposed in this pull request? The Spark 2.3 branch still failed due to the flaky test suite `DataSourceWithHiveMetastoreCatalogSuite `. https://amplab.cs.berkeley.edu/jenkins/job/spark-branch-2.3-test-sbt-hadoop-2.6/ Although #20207 is unable to reproduce it in Spark 2.3, it sounds like the current DB of Spark's Catalog is changed based on the following stacktrace. Thus, we just need to reset it. ``` [info] DataSourceWithHiveMetastoreCatalogSuite: 02:40:39.486 ERROR org.apache.hadoop.hive.ql.parse.CalcitePlanner: org.apache.hadoop.hive.ql.parse.SemanticException: Line 1:14 Table not found 't' at org.apache.hadoop.hive.ql.parse.SemanticAnalyzer.getMetaData(SemanticAnalyzer.java:1594) at org.apache.hadoop.hive.ql.parse.SemanticAnalyzer.getMetaData(SemanticAnalyzer.java:1545) at org.apache.hadoop.hive.ql.parse.SemanticAnalyzer.genResolvedParseTree(SemanticAnalyzer.java:10077) at org.apache.hadoop.hive.ql.parse.SemanticAnalyzer.analyzeInternal(SemanticAnalyzer.java:10128) at org.apache.hadoop.hive.ql.parse.CalcitePlanner.analyzeInternal(CalcitePlanner.java:209) at org.apache.hadoop.hive.ql.parse.BaseSemanticAnalyzer.analyze(BaseSemanticAnalyzer.java:227) at org.apache.hadoop.hive.ql.Driver.compile(Driver.java:424) at org.apache.hadoop.hive.ql.Driver.compile(Driver.java:308) at org.apache.hadoop.hive.ql.Driver.compileInternal(Driver.java:1122) at org.apache.hadoop.hive.ql.Driver.runInternal(Driver.java:1170) at org.apache.hadoop.hive.ql.Driver.run(Driver.java:1059) at org.apache.hadoop.hive.ql.Driver.run(Driver.java:1049) at org.apache.spark.sql.hive.client.HiveClientImpl$$anonfun$runHive$1.apply(HiveClientImpl.scala:694) at org.apache.spark.sql.hive.client.HiveClientImpl$$anonfun$runHive$1.apply(HiveClientImpl.scala:683) at org.apache.spark.sql.hive.client.HiveClientImpl$$anonfun$withHiveState$1.apply(HiveClientImpl.scala:272) at org.apache.spark.sql.hive.client.HiveClientImpl.liftedTree1$1(HiveClientImpl.scala:210) at org.apache.spark.sql.hive.client.HiveClientImpl.retryLocked(HiveClientImpl.scala:209) at org.apache.spark.sql.hive.client.HiveClientImpl.withHiveState(HiveClientImpl.scala:255) at org.apache.spark.sql.hive.client.HiveClientImpl.runHive(HiveClientImpl.scala:683) at org.apache.spark.sql.hive.client.HiveClientImpl.runSqlHive(HiveClientImpl.scala:673) at org.apache.spark.sql.hive.DataSourceWithHiveMetastoreCatalogSuite$$anonfun$9$$anonfun$apply$1$$anonfun$apply$mcV$sp$3.apply$mcV$sp(HiveMetastoreCatalogSuite.scala:185) at org.apache.spark.sql.test.SQLTestUtilsBase$class.withTable(SQLTestUtils.scala:273) at org.apache.spark.sql.hive.DataSourceWithHiveMetastoreCatalogSuite.withTable(HiveMetastoreCatalogSuite.scala:139) at org.apache.spark.sql.hive.DataSourceWithHiveMetastoreCatalogSuite$$anonfun$9$$anonfun$apply$1.apply$mcV$sp(HiveMetastoreCatalogSuite.scala:163) at org.apache.spark.sql.hive.DataSourceWithHiveMetastoreCatalogSuite$$anonfun$9$$anonfun$apply$1.apply(HiveMetastoreCatalogSuite.scala:163) at org.apache.spark.sql.hive.DataSourceWithHiveMetastoreCatalogSuite$$anonfun$9$$anonfun$apply$1.apply(HiveMetastoreCatalogSuite.scala:163) at org.scalatest.OutcomeOf$class.outcomeOf(OutcomeOf.scala:85) at org.scalatest.OutcomeOf$.outcomeOf(OutcomeOf.scala:104) at org.scalatest.Transformer.apply(Transformer.scala:22) at org.scalatest.Transformer.apply(Transformer.scala:20) at org.scalatest.FunSuiteLike$$anon$1.apply(FunSuiteLike.scala:186) at org.apache.spark.SparkFunSuite.withFixture(SparkFunSuite.scala:68) at org.scalatest.FunSuiteLike$class.invokeWithFixture$1(FunSuiteLike.scala:183) at org.scalatest.FunSuiteLike$$anonfun$runTest$1.apply(FunSuiteLike.scala:196) at org.scalatest.FunSuiteLike$$anonfun$runTest$1.apply(FunSuiteLike.scala:196) at org.scalatest.SuperEngine.runTestImpl(Engine.scala:289) at org.scalatest.FunSuiteLike$class.runTest(FunSuiteLike.scala:196) at org.scalatest.FunSuite.runTest(FunSuite.scala:1560) at org.scalatest.FunSuiteLike$$anonfun$runTests$1.apply(FunSuiteLike.scala:229) at org.scalatest.FunSuiteLike$$anonfun$runTests$1.apply(FunSuiteLike.scala:229) at org.scalatest.SuperEngine$$anonfun$traverseSubNodes$1$1.apply(Engine.scala:396) at org.scalatest.SuperEngine$$anonfun$traverseSubNodes$1$1.apply(Engine.scala:384) at scala.collection.immutable.List.foreach(List.scala:381) at org.scalatest.SuperEngine.traverseSubNodes$1(Engine.scala:384) at org.scalatest.SuperEngine.org$scalatest$SuperEngine$$runTestsInBranch(Engine.scala:379) at org.scalatest.SuperEngine.runTestsImpl(Engine.scala:461) at org.scalatest.FunSuiteLike$class.runTests(FunSuiteLike.scala:229) at org.scalatest.FunSuite.runTests(FunSuite.scala:1560) at org.scalatest.Suite$class.run(Suite.scala:1147) at org.scalatest.FunSuite.org$scalatest$FunSuiteLike$$super$run(FunSuite.scala:1560) at org.scalatest.FunSuiteLike$$anonfun$run$1.apply(FunSuiteLike.scala:233) at org.scalatest.FunSuiteLike$$anonfun$run$1.apply(FunSuiteLike.scala:233) at org.scalatest.SuperEngine.runImpl(Engine.scala:521) at org.scalatest.FunSuiteLike$class.run(FunSuiteLike.scala:233) at org.apache.spark.SparkFunSuite.org$scalatest$BeforeAndAfterAll$$super$run(SparkFunSuite.scala:31) at org.scalatest.BeforeAndAfterAll$class.liftedTree1$1(BeforeAndAfterAll.scala:213) at org.scalatest.BeforeAndAfterAll$class.run(BeforeAndAfterAll.scala:210) at org.apache.spark.SparkFunSuite.run(SparkFunSuite.scala:31) at org.scalatest.tools.Framework.org$scalatest$tools$Framework$$runSuite(Framework.scala:314) at org.scalatest.tools.Framework$ScalaTestTask.execute(Framework.scala:480) at sbt.ForkMain$Run$2.call(ForkMain.java:296) at sbt.ForkMain$Run$2.call(ForkMain.java:286) at java.util.concurrent.FutureTask.run(FutureTask.java:266) at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1142) at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:617) at java.lang.Thread.run(Thread.java:745) ``` ## How was this patch tested? N/A Author: gatorsmile <[email protected]> Closes #20218 from gatorsmile/testFixAgain.
-
[SPARK-19732][FOLLOW-UP] Document behavior changes made in na.fill an…
…d fillna ## What changes were proposed in this pull request? #18164 introduces the behavior changes. We need to document it. ## How was this patch tested? N/A Author: gatorsmile <[email protected]> Closes #20234 from gatorsmile/docBehaviorChange.
-
## What changes were proposed in this pull request? Hi, acording to code below, "if (id == src) (0.0, Double.NegativeInfinity) else (0.0, 0.0)" I think the comment can be wrong ## How was this patch tested? Please review http://spark.apache.org/contributing.html before opening a pull request. Author: FanDonglai <[email protected]> Closes #20220 from ddna1021/master.
-
[SPARK-22908] Add kafka source and sink for continuous processing.
## What changes were proposed in this pull request? Add kafka source and sink for continuous processing. This involves two small changes to the execution engine: * Bring data reader close() into the normal data reader thread to avoid thread safety issues. * Fix up the semantics of the RECONFIGURING StreamExecution state. State updates are now atomic, and we don't have to deal with swallowing an exception. ## How was this patch tested? new unit tests Author: Jose Torres <[email protected]> Closes #20096 from jose-torres/continuous-kafka.
-
[SPARK-23046][ML][SPARKR] Have RFormula include VectorSizeHint in pip…
…eline ## What changes were proposed in this pull request? Including VectorSizeHint in RFormula piplelines will allow them to be applied to streaming dataframes. ## How was this patch tested? Unit tests. Author: Bago Amirbekian <[email protected]> Closes #20238 from MrBago/rFormulaVectorSize.
Commits on Jan 12, 2018
-
[SPARK-23008][ML] OnehotEncoderEstimator python API
## What changes were proposed in this pull request? OnehotEncoderEstimator python API. ## How was this patch tested? doctest Author: WeichenXu <[email protected]> Closes #20209 from WeichenXu123/ohe_py.
-
[SPARK-22986][CORE] Use a cache to avoid instantiating multiple insta…
…nces of broadcast variable values When resources happen to be constrained on an executor the first time a broadcast variable is instantiated it is persisted to disk by the BlockManager. Consequently, every subsequent call to TorrentBroadcast::readBroadcastBlock from other instances of that broadcast variable spawns another instance of the underlying value. That is, broadcast variables are spawned once per executor **unless** memory is constrained, in which case every instance of a broadcast variable is provided with a unique copy of the underlying value. This patch fixes the above by explicitly caching the underlying values using weak references in a ReferenceMap. Author: ho3rexqj <[email protected]> Closes #20183 from ho3rexqj/fix/cache-broadcast-values.
-
[SPARK-23008][ML][FOLLOW-UP] mark OneHotEncoder python API deprecated
## What changes were proposed in this pull request? mark OneHotEncoder python API deprecated ## How was this patch tested? N/A Author: WeichenXu <[email protected]> Closes #20241 from WeichenXu123/mark_ohe_deprecated.
-
[SPARK-23025][SQL] Support Null type in scala reflection
## What changes were proposed in this pull request? Add support for `Null` type in the `schemaFor` method for Scala reflection. ## How was this patch tested? Added UT Author: Marco Gaido <[email protected]> Closes #20219 from mgaido91/SPARK-23025.
-
Update rdd-programming-guide.md
## What changes were proposed in this pull request? Small typing correction - double word ## How was this patch tested? Please review http://spark.apache.org/contributing.html before opening a pull request. Author: Matthias Beaupère <[email protected]> Closes #20212 from matthiasbe/patch-1.
-
[SPARK-23028] Bump master branch version to 2.4.0-SNAPSHOT
## What changes were proposed in this pull request? This patch bumps the master branch version to `2.4.0-SNAPSHOT`. ## How was this patch tested? N/A Author: gatorsmile <[email protected]> Closes #20222 from gatorsmile/bump24.
-
[MINOR][BUILD] Fix Java linter errors
## What changes were proposed in this pull request? This PR cleans up the java-lint errors (for v2.3.0-rc1 tag). Hopefully, this will be the final one. ``` $ dev/lint-java Using `mvn` from path: /usr/local/bin/mvn Checkstyle checks failed at following occurrences: [ERROR] src/main/java/org/apache/spark/unsafe/memory/HeapMemoryAllocator.java:[85] (sizes) LineLength: Line is longer than 100 characters (found 101). [ERROR] src/main/java/org/apache/spark/launcher/InProcessAppHandle.java:[20,8] (imports) UnusedImports: Unused import - java.io.IOException. [ERROR] src/main/java/org/apache/spark/sql/execution/datasources/orc/OrcColumnVector.java:[41,9] (modifier) ModifierOrder: 'private' modifier out of order with the JLS suggestions. [ERROR] src/test/java/test/org/apache/spark/sql/JavaDataFrameSuite.java:[464] (sizes) LineLength: Line is longer than 100 characters (found 102). ``` ## How was this patch tested? Manual. ``` $ dev/lint-java Using `mvn` from path: /usr/local/bin/mvn Checkstyle checks passed. ``` Author: Dongjoon Hyun <[email protected]> Closes #20242 from dongjoon-hyun/fix_lint_java_2.3_rc1.
-
[SPARK-22975][SS] MetricsReporter should not throw exception when the…
…re was no progress reported ## What changes were proposed in this pull request? `MetricsReporter ` assumes that there has been some progress for the query, ie. `lastProgress` is not null. If this is not true, as it might happen in particular conditions, a `NullPointerException` can be thrown. The PR checks whether there is a `lastProgress` and if this is not true, it returns a default value for the metrics. ## How was this patch tested? added UT Author: Marco Gaido <[email protected]> Closes #20189 from mgaido91/SPARK-22975.
-
Revert "[SPARK-22908] Add kafka source and sink for continuous proces…
…sing." This reverts commit 6f7aaed.
Commits on Jan 13, 2018
-
[SPARK-22980][PYTHON][SQL] Clarify the length of each series is of ea…
…ch batch within scalar Pandas UDF ## What changes were proposed in this pull request? This PR proposes to add a note that saying the length of a scalar Pandas UDF's `Series` is not of the whole input column but of the batch. We are fine for a group map UDF because the usage is different from our typical UDF but scalar UDFs might cause confusion with the normal UDF. For example, please consider this example: ```python from pyspark.sql.functions import pandas_udf, col, lit df = spark.range(1) f = pandas_udf(lambda x, y: len(x) + y, LongType()) df.select(f(lit('text'), col('id'))).show() ``` ``` +------------------+ |<lambda>(text, id)| +------------------+ | 1| +------------------+ ``` ```python from pyspark.sql.functions import udf, col, lit df = spark.range(1) f = udf(lambda x, y: len(x) + y, "long") df.select(f(lit('text'), col('id'))).show() ``` ``` +------------------+ |<lambda>(text, id)| +------------------+ | 4| +------------------+ ``` ## How was this patch tested? Manually built the doc and checked the output. Author: hyukjinkwon <[email protected]> Closes #20237 from HyukjinKwon/SPARK-22980. -
[SPARK-23043][BUILD] Upgrade json4s to 3.5.3
## What changes were proposed in this pull request? Spark still use a few years old version 3.2.11. This change is to upgrade json4s to 3.5.3. Note that this change does not include the Jackson update because the Jackson version referenced in json4s 3.5.3 is 2.8.4, which has a security vulnerability ([see](https://issues.apache.org/jira/browse/SPARK-20433)). ## How was this patch tested? Existing unit tests and build. Author: shimamoto <[email protected]> Closes #20233 from shimamoto/upgrade-json4s.
-
[SPARK-22870][CORE] Dynamic allocation should allow 0 idle time
## What changes were proposed in this pull request? This pr to make `0` as a valid value for `spark.dynamicAllocation.executorIdleTimeout`. For details, see the jira description: https://issues.apache.org/jira/browse/SPARK-22870. ## How was this patch tested? N/A Author: Yuming Wang <[email protected]> Author: Yuming Wang <[email protected]> Closes #20080 from wangyum/SPARK-22870.
-
[SPARK-23036][SQL][TEST] Add withGlobalTempView for testing
## What changes were proposed in this pull request? Add withGlobalTempView when create global temp view, like withTempView and withView. And correct some improper usage. Please see jira. There are other similar place like that. I will fix it if community need. Please confirm it. ## How was this patch tested? no new test. Author: xubo245 <[email protected]> Closes #20228 from xubo245/DropTempView.
-
[SPARK-22790][SQL] add a configurable factor to describe HadoopFsRela…
…tion's size ## What changes were proposed in this pull request? as per discussion in #19864 (comment) the current HadoopFsRelation is purely based on the underlying file size which is not accurate and makes the execution vulnerable to errors like OOM Users can enable CBO with the functionalities in #19864 to avoid this issue This JIRA proposes to add a configurable factor to sizeInBytes method in HadoopFsRelation class so that users can mitigate this problem without CBO ## How was this patch tested? Existing tests Author: CodingCat <[email protected]> Author: Nan Zhu <[email protected]> Closes #20072 from CodingCat/SPARK-22790.
-
[SPARK-21213][SQL][FOLLOWUP] Use compatible types for comparisons in …
…compareAndGetNewStats ## What changes were proposed in this pull request? This pr fixed code to compare values in `compareAndGetNewStats`. The test below fails in the current master; ``` val oldStats2 = CatalogStatistics(sizeInBytes = BigInt(Long.MaxValue) * 2) val newStats5 = CommandUtils.compareAndGetNewStats( Some(oldStats2), newTotalSize = BigInt(Long.MaxValue) * 2, None) assert(newStats5.isEmpty) ``` ## How was this patch tested? Added some tests in `CommandUtilsSuite`. Author: Takeshi Yamamuro <[email protected]> Closes #20245 from maropu/SPARK-21213-FOLLOWUP.
Commits on Jan 14, 2018
-
[SPARK-22959][PYTHON] Configuration to select the modules for daemon …
…and worker in PySpark ## What changes were proposed in this pull request? We are now forced to use `pyspark/daemon.py` and `pyspark/worker.py` in PySpark. This doesn't allow a custom modification for it (well, maybe we can still do this in a super hacky way though, for example, setting Python executable that has the custom modification). Because of this, for example, it's sometimes hard to debug what happens inside Python worker processes. This is actually related with [SPARK-7721](https://issues.apache.org/jira/browse/SPARK-7721) too as somehow Coverage is unable to detect the coverage from `os.fork`. If we have some custom fixes to force the coverage, it works fine. This is also related with [SPARK-20368](https://issues.apache.org/jira/browse/SPARK-20368). This JIRA describes Sentry support which (roughly) needs some changes within worker side. With this configuration advanced users will be able to do a lot of pluggable workarounds and we can meet such potential needs in the future. As an example, let's say if I configure the module `coverage_daemon` and had `coverage_daemon.py` in the python path: ```python import os from pyspark import daemon if "COVERAGE_PROCESS_START" in os.environ: from pyspark.worker import main def _cov_wrapped(*args, **kwargs): import coverage cov = coverage.coverage( config_file=os.environ["COVERAGE_PROCESS_START"]) cov.start() try: main(*args, **kwargs) finally: cov.stop() cov.save() daemon.worker_main = _cov_wrapped if __name__ == '__main__': daemon.manager() ``` I can track the coverages in worker side too. More importantly, we can leave the main code intact but allow some workarounds. ## How was this patch tested? Manually tested. Author: hyukjinkwon <[email protected]> Closes #20151 from HyukjinKwon/configuration-daemon-worker.
-
[SPARK-23063][K8S] K8s changes for publishing scripts (and a couple o…
…f other misses) ## What changes were proposed in this pull request? Including the `-Pkubernetes` flag in a few places it was missed. ## How was this patch tested? checkstyle, mima through manual tests. Author: foxish <[email protected]> Closes #20256 from foxish/SPARK-23063.
-
[SPARK-23038][TEST] Update docker/spark-test (JDK/OS)
## What changes were proposed in this pull request? This PR aims to update the followings in `docker/spark-test`. - JDK7 -> JDK8 Spark 2.2+ supports JDK8 only. - Ubuntu 12.04.5 LTS(precise) -> Ubuntu 16.04.3 LTS(xeniel) The end of life of `precise` was April 28, 2017. ## How was this patch tested? Manual. * Master ``` $ cd external/docker $ ./build $ export SPARK_HOME=... $ docker run -v $SPARK_HOME:/opt/spark spark-test-master CONTAINER_IP=172.17.0.3 ... 18/01/11 06:50:25 INFO MasterWebUI: Bound MasterWebUI to 172.17.0.3, and started at http://172.17.0.3:8080 18/01/11 06:50:25 INFO Utils: Successfully started service on port 6066. 18/01/11 06:50:25 INFO StandaloneRestServer: Started REST server for submitting applications on port 6066 18/01/11 06:50:25 INFO Master: I have been elected leader! New state: ALIVE ``` * Slave ``` $ docker run -v $SPARK_HOME:/opt/spark spark-test-worker spark://172.17.0.3:7077 CONTAINER_IP=172.17.0.4 ... 18/01/11 06:51:54 INFO Worker: Successfully registered with master spark://172.17.0.3:7077 ``` After slave starts, master will show ``` 18/01/11 06:51:54 INFO Master: Registering worker 172.17.0.4:8888 with 4 cores, 1024.0 MB RAM ``` Author: Dongjoon Hyun <[email protected]> Closes #20230 from dongjoon-hyun/SPARK-23038.
-
[SPARK-23069][DOCS][SPARKR] fix R doc for describe missing text
## What changes were proposed in this pull request? fix doc truncated ## How was this patch tested? manually Author: Felix Cheung <[email protected]> Closes #20263 from felixcheung/r23docfix.
-
[SPARK-23021][SQL] AnalysisBarrier should override innerChildren to p…
…rint correct explain output ## What changes were proposed in this pull request? `AnalysisBarrier` in the current master cuts off explain results for parsed logical plans; ``` scala> Seq((1, 1)).toDF("a", "b").groupBy("a").count().sample(0.1).explain(true) == Parsed Logical Plan == Sample 0.0, 0.1, false, -7661439431999668039 +- AnalysisBarrier Aggregate [a#5], [a#5, count(1) AS count#14L] ``` To fix this, `AnalysisBarrier` needs to override `innerChildren` and this pr changed the output to; ``` == Parsed Logical Plan == Sample 0.0, 0.1, false, -5086223488015741426 +- AnalysisBarrier +- Aggregate [a#5], [a#5, count(1) AS count#14L] +- Project [_1#2 AS a#5, _2#3 AS b#6] +- LocalRelation [_1#2, _2#3] ``` ## How was this patch tested? Added tests in `DataFrameSuite`. Author: Takeshi Yamamuro <[email protected]> Closes #20247 from maropu/SPARK-23021-2. -
[SPARK-23051][CORE] Fix for broken job description in Spark UI
## What changes were proposed in this pull request? In 2.2, Spark UI displayed the stage description if the job description was not set. This functionality was broken, the GUI has shown no description in this case. In addition, the code uses jobName and jobDescription instead of stageName and stageDescription when JobTableRowData is created. In this PR the logic producing values for the job rows was modified to find the latest stage attempt for the job and use that as a fallback if job description was missing. StageName and stageDescription are also set using values from stage and jobName/description is used only as a fallback. ## How was this patch tested? Manual testing of the UI, using the code in the bug report. Author: Sandor Murakozi <[email protected]> Closes #20251 from smurakozi/SPARK-23051.
-
[SPARK-22999][SQL] show databases like command' can remove the like k…
…eyword ## What changes were proposed in this pull request? SHOW DATABASES (LIKE pattern = STRING)? Can be like the back increase? When using this command, LIKE keyword can be removed. You can refer to the SHOW TABLES command, SHOW TABLES 'test *' and SHOW TABELS like 'test *' can be used. Similarly SHOW DATABASES 'test *' and SHOW DATABASES like 'test *' can be used. ## How was this patch tested? unit tests manual tests Please review http://spark.apache.org/contributing.html before opening a pull request. Author: guoxiaolong <[email protected]> Closes #20194 from guoxiaolongzte/SPARK-22999.
Commits on Jan 15, 2018
-
[SPARK-23054][SQL] Fix incorrect results of casting UserDefinedType t…
…o String ## What changes were proposed in this pull request? This pr fixed the issue when casting `UserDefinedType`s into strings; ``` >>> from pyspark.ml.classification import MultilayerPerceptronClassifier >>> from pyspark.ml.linalg import Vectors >>> df = spark.createDataFrame([(0.0, Vectors.dense([0.0, 0.0])), (1.0, Vectors.dense([0.0, 1.0]))], ["label", "features"]) >>> df.selectExpr("CAST(features AS STRING)").show(truncate = False) +-------------------------------------------+ |features | +-------------------------------------------+ |[6,1,0,0,2800000020,2,0,0,0] | |[6,1,0,0,2800000020,2,0,0,3ff0000000000000]| +-------------------------------------------+ ``` The root cause is that `Cast` handles input data as `UserDefinedType.sqlType`(this is underlying storage type), so we should pass data into `UserDefinedType.deserialize` then `toString`. This pr modified the result into; ``` +---------+ |features | +---------+ |[0.0,0.0]| |[0.0,1.0]| +---------+ ``` ## How was this patch tested? Added tests in `UserDefinedTypeSuite `. Author: Takeshi Yamamuro <[email protected]> Closes #20246 from maropu/SPARK-23054. -
[SPARK-23049][SQL]
spark.sql.files.ignoreCorruptFilesshould work f……or ORC files ## What changes were proposed in this pull request? When `spark.sql.files.ignoreCorruptFiles=true`, we should ignore corrupted ORC files. ## How was this patch tested? Pass the Jenkins with a newly added test case. Author: Dongjoon Hyun <[email protected]> Closes #20240 from dongjoon-hyun/SPARK-23049.
-
[SPARK-23023][SQL] Cast field data to strings in showString
## What changes were proposed in this pull request? The current `Datset.showString` prints rows thru `RowEncoder` deserializers like; ``` scala> Seq(Seq(Seq(1, 2), Seq(3), Seq(4, 5, 6))).toDF("a").show(false) +------------------------------------------------------------+ |a | +------------------------------------------------------------+ |[WrappedArray(1, 2), WrappedArray(3), WrappedArray(4, 5, 6)]| +------------------------------------------------------------+ ``` This result is incorrect because the correct one is; ``` scala> Seq(Seq(Seq(1, 2), Seq(3), Seq(4, 5, 6))).toDF("a").show(false) +------------------------+ |a | +------------------------+ |[[1, 2], [3], [4, 5, 6]]| +------------------------+ ``` So, this pr fixed code in `showString` to cast field data to strings before printing. ## How was this patch tested? Added tests in `DataFrameSuite`. Author: Takeshi Yamamuro <[email protected]> Closes #20214 from maropu/SPARK-23023. -
[SPARK-19550][BUILD][FOLLOW-UP] Remove MaxPermSize for sql module
## What changes were proposed in this pull request? Remove `MaxPermSize` for `sql` module ## How was this patch tested? Manually tested. Author: Yuming Wang <[email protected]> Closes #20268 from wangyum/SPARK-19550-MaxPermSize.
-
[SPARK-23070] Bump previousSparkVersion in MimaBuild.scala to be 2.2.0
## What changes were proposed in this pull request? Bump previousSparkVersion in MimaBuild.scala to be 2.2.0 and add the missing exclusions to `v23excludes` in `MimaExcludes`. No item can be un-excluded in `v23excludes`. ## How was this patch tested? The existing tests. Author: gatorsmile <[email protected]> Closes #20264 from gatorsmile/bump22.
-
[SPARK-23035][SQL] Fix improper information of TempTableAlreadyExists…
…Exception ## What changes were proposed in this pull request? Problem: it throw TempTableAlreadyExistsException and output "Temporary table '$table' already exists" when we create temp view by using org.apache.spark.sql.catalyst.catalog.GlobalTempViewManager#create, it's improper. So fix improper information about TempTableAlreadyExistsException when create temp view: change "Temporary table" to "Temporary view" ## How was this patch tested? test("rename temporary view - destination table already exists, with: CREATE TEMPORARY view") test("rename temporary view - destination table with database name,with:CREATE TEMPORARY view") Author: xubo245 <[email protected]> Closes #20227 from xubo245/fixDeprecated.
Commits on Jan 16, 2018
-
[SPARK-23080][SQL] Improve error message for built-in functions
## What changes were proposed in this pull request? When a user puts the wrong number of parameters in a function, an AnalysisException is thrown. If the function is a UDF, he user is told how many parameters the function expected and how many he/she put. If the function, instead, is a built-in one, no information about the number of parameters expected and the actual one is provided. This can help in some cases, to debug the errors (eg. bad quotes escaping may lead to a different number of parameters than expected, etc. etc.) The PR adds the information about the number of parameters passed and the expected one, analogously to what happens for UDF. ## How was this patch tested? modified existing UT + manual test Author: Marco Gaido <[email protected]> Closes #20271 from mgaido91/SPARK-23080.
-
[SPARK-23000] Use fully qualified table names in HiveMetastoreCatalog…
…Suite ## What changes were proposed in this pull request? In another attempt to fix DataSourceWithHiveMetastoreCatalogSuite, this patch uses qualified table names (`default.t`) in the individual tests. ## How was this patch tested? N/A (Test Only Change) Author: Sameer Agarwal <[email protected]> Closes #20273 from sameeragarwal/flaky-test.
-
[SPARK-22956][SS] Bug fix for 2 streams union failover scenario
## What changes were proposed in this pull request? This problem reported by yanlin-Lynn ivoson and LiangchangZ. Thanks! When we union 2 streams from kafka or other sources, while one of them have no continues data coming and in the same time task restart, this will cause an `IllegalStateException`. This mainly cause because the code in [MicroBatchExecution](https://github.com/apache/spark/blob/master/sql/core/src/main/scala/org/apache/spark/sql/execution/streaming/MicroBatchExecution.scala#L190) , while one stream has no continues data, its comittedOffset same with availableOffset during `populateStartOffsets`, and `currentPartitionOffsets` not properly handled in KafkaSource. Also, maybe we should also consider this scenario in other Source. ## How was this patch tested? Add a UT in KafkaSourceSuite.scala Author: Yuanjian Li <[email protected]> Closes #20150 from xuanyuanking/SPARK-22956.
-
[SPARK-23020][CORE] Fix races in launcher code, test.
The race in the code is because the handle might update its state to the wrong state if the connection handling thread is still processing incoming data; so the handle needs to wait for the connection to finish up before checking the final state. The race in the test is because when waiting for a handle to reach a final state, the waitFor() method needs to wait until all handle state is updated (which also includes waiting for the connection thread above to finish). Otherwise, waitFor() may return too early, which would cause a bunch of different races (like the listener not being yet notified of the state change, or being in the middle of being notified, or the handle not being properly disposed and causing postChecks() to assert). On top of that I found, by code inspection, a couple of potential races that could make a handle end up in the wrong state when being killed. Tested by running the existing unit tests a lot (and not seeing the errors I was seeing before). Author: Marcelo Vanzin <[email protected]> Closes #20223 from vanzin/SPARK-23020.
-
[SPARK-22978][PYSPARK] Register Vectorized UDFs for SQL Statement
## What changes were proposed in this pull request? Register Vectorized UDFs for SQL Statement. For example, ```Python >>> from pyspark.sql.functions import pandas_udf, PandasUDFType >>> pandas_udf("integer", PandasUDFType.SCALAR) ... def add_one(x): ... return x + 1 ... >>> _ = spark.udf.register("add_one", add_one) >>> spark.sql("SELECT add_one(id) FROM range(3)").collect() [Row(add_one(id)=1), Row(add_one(id)=2), Row(add_one(id)=3)] ``` ## How was this patch tested? Added test cases Author: gatorsmile <[email protected]> Closes #20171 from gatorsmile/supportVectorizedUDF. -
[SPARK-22392][SQL] data source v2 columnar batch reader
## What changes were proposed in this pull request? a new Data Source V2 interface to allow the data source to return `ColumnarBatch` during the scan. ## How was this patch tested? new tests Author: Wenchen Fan <[email protected]> Closes #20153 from cloud-fan/columnar-reader.
-
[SPARK-16139][TEST] Add logging functionality for leaked threads in t…
…ests ## What changes were proposed in this pull request? Lots of our tests don't properly shutdown everything they create, and end up leaking lots of threads. For example, `TaskSetManagerSuite` doesn't stop the extra `TaskScheduler` and `DAGScheduler` it creates. There are a couple more instances, eg. in `DAGSchedulerSuite`. This PR adds the possibility to print out the not properly stopped thread list after a test suite executed. The format is the following: ``` ===== FINISHED o.a.s.scheduler.DAGSchedulerSuite: 'task end event should have updated accumulators (SPARK-20342)' ===== ... ===== Global thread whitelist loaded with name /thread_whitelist from classpath: rpc-client.*, rpc-server.*, shuffle-client.*, shuffle-server.*' ===== ScalaTest-run: ===== THREADS NOT STOPPED PROPERLY ===== ScalaTest-run: dag-scheduler-event-loop ScalaTest-run: globalEventExecutor-2-5 ScalaTest-run: ===== END OF THREAD DUMP ===== ScalaTest-run: ===== EITHER PUT THREAD NAME INTO THE WHITELIST FILE OR SHUT IT DOWN PROPERLY ===== ``` With the help of this leaking threads has been identified in TaskSetManagerSuite. My intention is to hunt down and fix such bugs in later PRs. ## How was this patch tested? Manual: TaskSetManagerSuite test executed and found out where are the leaking threads. Automated: Pass the Jenkins. Author: Gabor Somogyi <[email protected]> Closes #19893 from gaborgsomogyi/SPARK-16139.
-
[SPARK-23045][ML][SPARKR] Update RFormula to use OneHotEncoderEstimator.
## What changes were proposed in this pull request? RFormula should use VectorSizeHint & OneHotEncoderEstimator in its pipeline to avoid using the deprecated OneHotEncoder & to ensure the model produced can be used in streaming. ## How was this patch tested? Unit tests. Please review http://spark.apache.org/contributing.html before opening a pull request. Author: Bago Amirbekian <[email protected]> Closes #20229 from MrBago/rFormula.
Commits on Jan 17, 2018
-
[SPARK-23044] Error handling for jira assignment
## What changes were proposed in this pull request? * If there is any error while trying to assign the jira, prompt again * Filter out the "Apache Spark" choice * allow arbitrary user ids to be entered ## How was this patch tested? Couldn't really test the error case, just some testing of similar-ish code in python shell. Haven't run a merge yet. Author: Imran Rashid <[email protected]> Closes #20236 from squito/SPARK-23044.
-
[SPARK-23095][SQL] Decorrelation of scalar subquery fails with java.u…
…til.NoSuchElementException ## What changes were proposed in this pull request? The following SQL involving scalar correlated query returns a map exception. ``` SQL SELECT t1a FROM t1 WHERE t1a = (SELECT count(*) FROM t2 WHERE t2c = t1c HAVING count(*) >= 1) ``` ``` SQL key not found: ExprId(278,786682bb-41f9-4bd5-a397-928272cc8e4e) java.util.NoSuchElementException: key not found: ExprId(278,786682bb-41f9-4bd5-a397-928272cc8e4e) at scala.collection.MapLike$class.default(MapLike.scala:228) at scala.collection.AbstractMap.default(Map.scala:59) at scala.collection.MapLike$class.apply(MapLike.scala:141) at scala.collection.AbstractMap.apply(Map.scala:59) at org.apache.spark.sql.catalyst.optimizer.RewriteCorrelatedScalarSubquery$.org$apache$spark$sql$catalyst$optimizer$RewriteCorrelatedScalarSubquery$$evalSubqueryOnZeroTups(subquery.scala:378) at org.apache.spark.sql.catalyst.optimizer.RewriteCorrelatedScalarSubquery$$anonfun$org$apache$spark$sql$catalyst$optimizer$RewriteCorrelatedScalarSubquery$$constructLeftJoins$1.apply(subquery.scala:430) at org.apache.spark.sql.catalyst.optimizer.RewriteCorrelatedScalarSubquery$$anonfun$org$apache$spark$sql$catalyst$optimizer$RewriteCorrelatedScalarSubquery$$constructLeftJoins$1.apply(subquery.scala:426) ``` In this case, after evaluating the HAVING clause "count(*) > 1" statically against the binding of aggregtation result on empty input, we determine that this query will not have a the count bug. We should simply return the evalSubqueryOnZeroTups with empty value. (Please fill in changes proposed in this fix) ## How was this patch tested? A new test was added in the Subquery bucket. Author: Dilip Biswal <[email protected]> Closes #20283 from dilipbiswal/scalar-count-defect. -
[SPARK-22361][SQL][TEST] Add unit test for Window Frames
## What changes were proposed in this pull request? There are already quite a few integration tests using window frames, but the unit tests coverage is not ideal. In this PR the already existing tests are reorganized, extended and where gaps found additional cases added. ## How was this patch tested? Automated: Pass the Jenkins. Author: Gabor Somogyi <[email protected]> Closes #20019 from gaborgsomogyi/SPARK-22361.
-
[SPARK-22908][SS] Roll forward continuous processing Kafka support wi…
…th fix to continuous Kafka data reader ## What changes were proposed in this pull request? The Kafka reader is now interruptible and can close itself. ## How was this patch tested? I locally ran one of the ContinuousKafkaSourceSuite tests in a tight loop. Before the fix, my machine ran out of open file descriptors a few iterations in; now it works fine. Author: Jose Torres <[email protected]> Closes #20253 from jose-torres/fix-data-reader.
-
Revert "[SPARK-23020][CORE] Fix races in launcher code, test."
This reverts commit 66217da.
-
Fix merge between 07ae39d and 1667057
## What changes were proposed in this pull request? The first commit added a new test, and the second refactored the class the test was in. The automatic merge put the test in the wrong place. ## How was this patch tested? - Author: Jose Torres <[email protected]> Closes #20289 from jose-torres/fix.
-
[SPARK-23072][SQL][TEST] Add a Unicode schema test for file-based dat…
…a sources ## What changes were proposed in this pull request? After [SPARK-20682](#19651), Apache Spark 2.3 is able to read ORC files with Unicode schema. Previously, it raises `org.apache.spark.sql.catalyst.parser.ParseException`. This PR adds a Unicode schema test for CSV/JSON/ORC/Parquet file-based data sources. Note that TEXT data source only has [a single column with a fixed name 'value'](https://github.com/apache/spark/blob/master/sql/core/src/main/scala/org/apache/spark/sql/execution/datasources/text/TextFileFormat.scala#L71). ## How was this patch tested? Pass the newly added test case. Author: Dongjoon Hyun <[email protected]> Closes #20266 from dongjoon-hyun/SPARK-23072.
-
[SPARK-23062][SQL] Improve EXCEPT documentation
## What changes were proposed in this pull request? Make the default behavior of EXCEPT (i.e. EXCEPT DISTINCT) more explicit in the documentation, and call out the change in behavior from 1.x. Author: Henry Robinson <[email protected]> Closes #20254 from henryr/spark-23062.
-
[SPARK-21783][SQL] Turn on ORC filter push-down by default
## What changes were proposed in this pull request? ORC filter push-down is disabled by default from the beginning, [SPARK-2883](aa31e43#diff-41ef65b9ef5b518f77e2a03559893f4dR149 ). Now, Apache Spark starts to depend on Apache ORC 1.4.1. For Apache Spark 2.3, this PR turns on ORC filter push-down by default like Parquet ([SPARK-9207](https://issues.apache.org/jira/browse/SPARK-21783)) as a part of [SPARK-20901](https://issues.apache.org/jira/browse/SPARK-20901), "Feature parity for ORC with Parquet". ## How was this patch tested? Pass the existing tests. Author: Dongjoon Hyun <[email protected]> Closes #20265 from dongjoon-hyun/SPARK-21783.
-
[SPARK-23079][SQL] Fix query constraints propagation with aliases
## What changes were proposed in this pull request? Previously, PR #19201 fix the problem of non-converging constraints. After that PR #19149 improve the loop and constraints is inferred only once. So the problem of non-converging constraints is gone. However, the case below will fail. ``` spark.range(5).write.saveAsTable("t") val t = spark.read.table("t") val left = t.withColumn("xid", $"id" + lit(1)).as("x") val right = t.withColumnRenamed("id", "xid").as("y") val df = left.join(right, "xid").filter("id = 3").toDF() checkAnswer(df, Row(4, 3)) ``` Because `aliasMap` replace all the aliased child. See the test case in PR for details. This PR is to fix this bug by removing useless code for preventing non-converging constraints. It can be also fixed with #20270, but this is much simpler and clean up the code. ## How was this patch tested? Unit test Author: Wang Gengliang <[email protected]> Closes #20278 from gengliangwang/FixConstraintSimple.
-
[SPARK-23020] Ignore Flaky Test: SparkLauncherSuite.testInProcessLaun…
…cher ## What changes were proposed in this pull request? Temporarily ignoring flaky test `SparkLauncherSuite.testInProcessLauncher` to de-flake the builds. This should be re-enabled when SPARK-23020 is merged. ## How was this patch tested? N/A (Test Only Change) Author: Sameer Agarwal <[email protected]> Closes #20291 from sameeragarwal/disable-test-2.
-
[SPARK-23033][SS] Don't use task level retry for continuous processing
## What changes were proposed in this pull request? Continuous processing tasks will fail on any attempt number greater than 0. ContinuousExecution will catch these failures and restart globally from the last recorded checkpoints. ## How was this patch tested? unit test Author: Jose Torres <[email protected]> Closes #20225 from jose-torres/no-retry.
-
[SPARK-23093][SS] Don't change run id when reconfiguring a continuous…
… processing query. ## What changes were proposed in this pull request? Keep the run ID static, using a different ID for the epoch coordinator to avoid cross-execution message contamination. ## How was this patch tested? new and existing unit tests Author: Jose Torres <[email protected]> Closes #20282 from jose-torres/fix-runid.
-
[SPARK-23047][PYTHON][SQL] Change MapVector to NullableMapVector in A…
…rrowColumnVector ## What changes were proposed in this pull request? This PR changes usage of `MapVector` in Spark codebase to use `NullableMapVector`. `MapVector` is an internal Arrow class that is not supposed to be used directly. We should use `NullableMapVector` instead. ## How was this patch tested? Existing test. Author: Li Jin <[email protected]> Closes #20239 from icexelloss/arrow-map-vector.
-
[SPARK-23132][PYTHON][ML] Run doctests in ml.image when testing
## What changes were proposed in this pull request? This PR proposes to actually run the doctests in `ml/image.py`. ## How was this patch tested? doctests in `python/pyspark/ml/image.py`. Author: hyukjinkwon <[email protected]> Closes #20294 from HyukjinKwon/trigger-image.
-
[MINOR] Fix typos in ML scaladocs
## What changes were proposed in this pull request? Fixed some typos found in ML scaladocs ## How was this patch tested? NA Author: Bryan Cutler <[email protected]> Closes #20300 from BryanCutler/ml-doc-typos-MINOR.
Commits on Jan 18, 2018
-
[SPARK-23119][SS] Minor fixes to V2 streaming APIs
## What changes were proposed in this pull request? - Added `InterfaceStability.Evolving` annotations - Improved docs. ## How was this patch tested? Existing tests. Author: Tathagata Das <[email protected]> Closes #20286 from tdas/SPARK-23119.
-
[SPARK-23064][DOCS][SS] Added documentation for stream-stream joins
## What changes were proposed in this pull request? Added documentation for stream-stream joins     ## How was this patch tested? N/a Author: Tathagata Das <[email protected]> Closes #20255 from tdas/join-docs.
-
[SPARK-21996][SQL] read files with space in name for streaming
## What changes were proposed in this pull request? Structured streaming is now able to read files with space in file name (previously it would skip the file and output a warning) ## How was this patch tested? Added new unit test. Author: Xiayun Sun <[email protected]> Closes #19247 from xysun/SPARK-21996.
-
[SPARK-23122][PYTHON][SQL] Deprecate register* for UDFs in SQLContext…
… and Catalog in PySpark ## What changes were proposed in this pull request? This PR proposes to deprecate `register*` for UDFs in `SQLContext` and `Catalog` in Spark 2.3.0. These are inconsistent with Scala / Java APIs and also these basically do the same things with `spark.udf.register*`. Also, this PR moves the logcis from `[sqlContext|spark.catalog].register*` to `spark.udf.register*` and reuse the docstring. This PR also handles minor doc corrections. It also includes #20158 ## How was this patch tested? Manually tested, manually checked the API documentation and tests added to check if deprecated APIs call the aliases correctly. Author: hyukjinkwon <[email protected]> Closes #20288 from HyukjinKwon/deprecate-udf.
-
[SPARK-23052][SS] Migrate ConsoleSink to data source V2 api.
## What changes were proposed in this pull request? Migrate ConsoleSink to data source V2 api. Note that this includes a missing piece in DataStreamWriter required to specify a data source V2 writer. Note also that I've removed the "Rerun batch" part of the sink, because as far as I can tell this would never have actually happened. A MicroBatchExecution object will only commit each batch once for its lifetime, and a new MicroBatchExecution object would have a new ConsoleSink object which doesn't know it's retrying a batch. So I think this represents an anti-feature rather than a weakness in the V2 API. ## How was this patch tested? new unit test Author: Jose Torres <[email protected]> Closes #20243 from jose-torres/console-sink.
-
[SPARK-23140][SQL] Add DataSourceV2Strategy to Hive Session state's p…
…lanner ## What changes were proposed in this pull request? `DataSourceV2Strategy` is missing in `HiveSessionStateBuilder`'s planner, which will throw exception as described in [SPARK-23140](https://issues.apache.org/jira/browse/SPARK-23140). ## How was this patch tested? Manual test. Author: jerryshao <[email protected]> Closes #20305 from jerryshao/SPARK-23140.
-
[SPARK-22036][SQL] Decimal multiplication with high precision/scale o…
…ften returns NULL ## What changes were proposed in this pull request? When there is an operation between Decimals and the result is a number which is not representable exactly with the result's precision and scale, Spark is returning `NULL`. This was done to reflect Hive's behavior, but it is against SQL ANSI 2011, which states that "If the result cannot be represented exactly in the result type, then whether it is rounded or truncated is implementation-defined". Moreover, Hive now changed its behavior in order to respect the standard, thanks to HIVE-15331. Therefore, the PR propose to: - update the rules to determine the result precision and scale according to the new Hive's ones introduces in HIVE-15331; - round the result of the operations, when it is not representable exactly with the result's precision and scale, instead of returning `NULL` - introduce a new config `spark.sql.decimalOperations.allowPrecisionLoss` which default to `true` (ie. the new behavior) in order to allow users to switch back to the previous one. Hive behavior reflects SQLServer's one. The only difference is that the precision and scale are adjusted for all the arithmetic operations in Hive, while SQL Server is said to do so only for multiplications and divisions in the documentation. This PR follows Hive's behavior. A more detailed explanation is available here: https://mail-archives.apache.org/mod_mbox/spark-dev/201712.mbox/%3CCAEorWNAJ4TxJR9NBcgSFMD_VxTg8qVxusjP%2BAJP-x%2BJV9zH-yA%40mail.gmail.com%3E. ## How was this patch tested? modified and added UTs. Comparisons with results of Hive and SQLServer. Author: Marco Gaido <[email protected]> Closes #20023 from mgaido91/SPARK-22036.
-
[SPARK-23141][SQL][PYSPARK] Support data type string as a returnType …
…for registerJavaFunction. ## What changes were proposed in this pull request? Currently `UDFRegistration.registerJavaFunction` doesn't support data type string as a `returnType` whereas `UDFRegistration.register`, `udf`, or `pandas_udf` does. We can support it for `UDFRegistration.registerJavaFunction` as well. ## How was this patch tested? Added a doctest and existing tests. Author: Takuya UESHIN <[email protected]> Closes #20307 from ueshin/issues/SPARK-23141.
-
[SPARK-23147][UI] Fix task page table IndexOutOfBound Exception
## What changes were proposed in this pull request? Stage's task page table will throw an exception when there's no complete tasks. Furthermore, because the `dataSize` doesn't take running tasks into account, so sometimes UI cannot show the running tasks. Besides table will only be displayed when first task is finished according to the default sortColumn("index"). 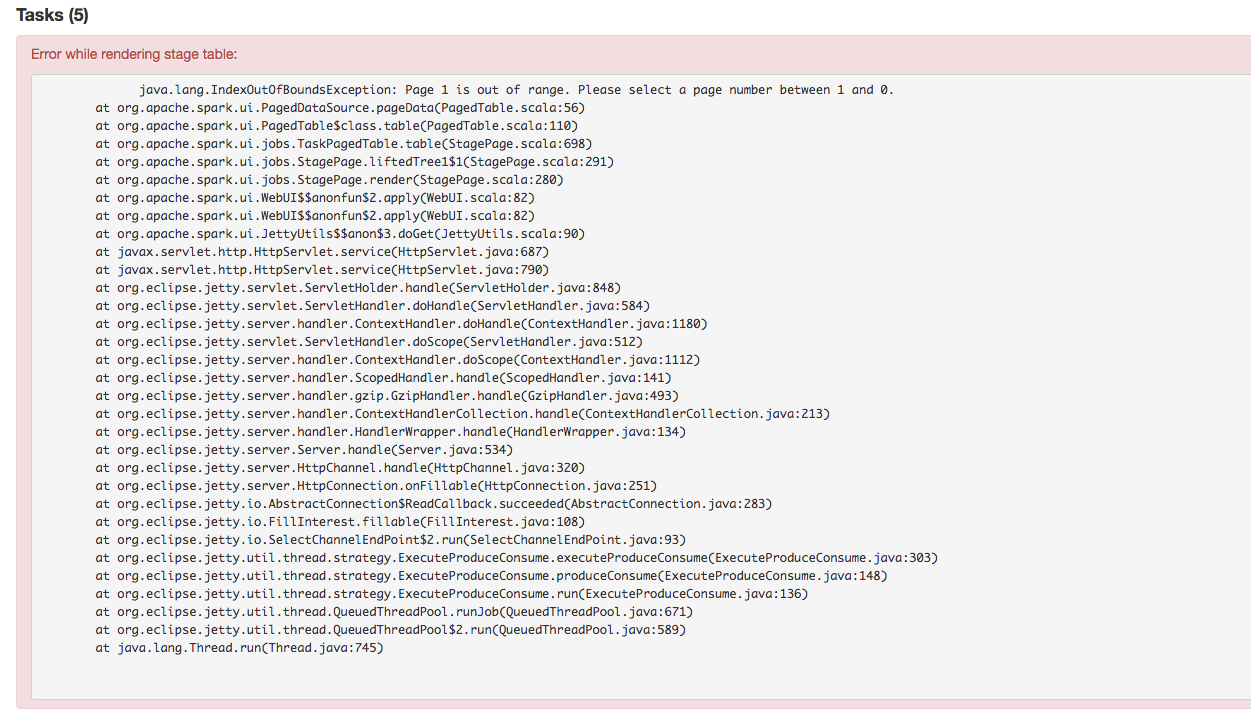 To reproduce this issue, user could try `sc.parallelize(1 to 20, 20).map { i => Thread.sleep(10000); i }.collect()` or `sc.parallelize(1 to 20, 20).map { i => Thread.sleep((20 - i) * 1000); i }.collect` to reproduce the above issue. Here propose a solution to fix it. Not sure if it is a right fix, please help to review. ## How was this patch tested? Manual test. Author: jerryshao <[email protected]> Closes #20315 from jerryshao/SPARK-23147. -
[SPARK-23029][DOCS] Specifying default units of configuration entries
## What changes were proposed in this pull request? This PR completes the docs, specifying the default units assumed in configuration entries of type size. This is crucial since unit-less values are accepted and the user might assume the base unit is bytes, which in most cases it is not, leading to hard-to-debug problems. ## How was this patch tested? This patch updates only documentation only. Author: Fernando Pereira <[email protected]> Closes #20269 from ferdonline/docs_units.
-
[SPARK-23143][SS][PYTHON] Added python API for setting continuous tri…
…gger ## What changes were proposed in this pull request? Self-explanatory. ## How was this patch tested? New python tests. Author: Tathagata Das <[email protected]> Closes #20309 from tdas/SPARK-23143.
-
[SPARK-23144][SS] Added console sink for continuous processing
## What changes were proposed in this pull request? Refactored ConsoleWriter into ConsoleMicrobatchWriter and ConsoleContinuousWriter. ## How was this patch tested? new unit test Author: Tathagata Das <[email protected]> Closes #20311 from tdas/SPARK-23144.
-
[SPARK-23133][K8S] Fix passing java options to Executor
Pass through spark java options to the executor in context of docker image. Closes #20296 andrusha: Deployed two version of containers to local k8s, checked that java options were present in the updated image on the running executor. Manual test Author: Andrew Korzhuev <[email protected]> Closes #20322 from foxish/patch-1.
-
[SPARK-23094] Fix invalid character handling in JsonDataSource
## What changes were proposed in this pull request? There were two related fixes regarding `from_json`, `get_json_object` and `json_tuple` ([Fix #1](c8803c0), [Fix #2](86174ea)), but they weren't comprehensive it seems. I wanted to extend those fixes to all the parsers, and add tests for each case. ## How was this patch tested? Regression tests Author: Burak Yavuz <[email protected]> Closes #20302 from brkyvz/json-invfix.
-
[SPARK-22962][K8S] Fail fast if submission client local files are used
## What changes were proposed in this pull request? In the Kubernetes mode, fails fast in the submission process if any submission client local dependencies are used as the use case is not supported yet. ## How was this patch tested? Unit tests, integration tests, and manual tests. vanzin foxish Author: Yinan Li <[email protected]> Closes #20320 from liyinan926/master.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Commits on Jan 19, 2018
-
[SPARK-23142][SS][DOCS] Added docs for continuous processing
## What changes were proposed in this pull request? Added documentation for continuous processing. Modified two locations. - Modified the overview to have a mention of Continuous Processing. - Added a new section on Continuous Processing at the end.   ## How was this patch tested? N/A Author: Tathagata Das <[email protected]> Closes #20308 from tdas/SPARK-23142.
-
[DOCS] change to dataset for java code in structured-streaming-kafka-…
…integration document ## What changes were proposed in this pull request? In latest structured-streaming-kafka-integration document, Java code example for Kafka integration is using `DataFrame<Row>`, shouldn't it be changed to `DataSet<Row>`? ## How was this patch tested? manual test has been performed to test the updated example Java code in Spark 2.2.1 with Kafka 1.0 Author: brandonJY <[email protected]> Closes #20312 from brandonJY/patch-2.
-
[SPARK-23054][SQL][PYSPARK][FOLLOWUP] Use sqlType casting when castin…
…g PythonUserDefinedType to String. ## What changes were proposed in this pull request? This is a follow-up of #20246. If a UDT in Python doesn't have its corresponding Scala UDT, cast to string will be the raw string of the internal value, e.g. `"org.apache.spark.sql.catalyst.expressions.UnsafeArrayDataxxxxxxxx"` if the internal type is `ArrayType`. This pr fixes it by using its `sqlType` casting. ## How was this patch tested? Added a test and existing tests. Author: Takuya UESHIN <[email protected]> Closes #20306 from ueshin/issues/SPARK-23054/fup1.
-
[BUILD][MINOR] Fix java style check issues
## What changes were proposed in this pull request? This patch fixes a few recently introduced java style check errors in master and release branch. As an aside, given that [java linting currently fails](#10763 ) on machines with a clean maven cache, it'd be great to find another workaround to [re-enable the java style checks](https://github.com/apache/spark/blob/3a07eff5af601511e97a05e6fea0e3d48f74c4f0/dev/run-tests.py#L577) as part of Spark PRB. /cc zsxwing JoshRosen srowen for any suggestions ## How was this patch tested? Manual Check Author: Sameer Agarwal <[email protected]> Closes #20323 from sameeragarwal/java.
-
[SPARK-23048][ML] Add OneHotEncoderEstimator document and examples
## What changes were proposed in this pull request? We have `OneHotEncoderEstimator` now and `OneHotEncoder` will be deprecated since 2.3.0. We should add `OneHotEncoderEstimator` into mllib document. We also need to provide corresponding examples for `OneHotEncoderEstimator` which are used in the document too. ## How was this patch tested? Existing tests. Author: Liang-Chi Hsieh <[email protected]> Closes #20257 from viirya/SPARK-23048.
-
[SPARK-23089][STS] Recreate session log directory if it doesn't exist
## What changes were proposed in this pull request? When creating a session directory, Thrift should create the parent directory (i.e. /tmp/base_session_log_dir) if it is not present. It is common that many tools delete empty directories, so the directory may be deleted. This can cause the session log to be disabled. This was fixed in HIVE-12262: this PR brings it in Spark too. ## How was this patch tested? manual tests Author: Marco Gaido <[email protected]> Closes #20281 from mgaido91/SPARK-23089.
-
[SPARK-23024][WEB-UI] Spark ui about the contents of the form need to…
… have hidden and show features, when the table records very much. ## What changes were proposed in this pull request? Spark ui about the contents of the form need to have hidden and show features, when the table records very much. Because sometimes you do not care about the record of the table, you just want to see the contents of the next table, but you have to scroll the scroll bar for a long time to see the contents of the next table. Currently we have about 500 workers, but I just wanted to see the logs for the running applications table. I had to scroll through the scroll bars for a long time to see the logs for the running applications table. In order to ensure functional consistency, I modified the Master Page, Worker Page, Job Page, Stage Page, Task Page, Configuration Page, Storage Page, Pool Page. fix before:  fix after:  ## How was this patch tested? manual tests Please review http://spark.apache.org/contributing.html before opening a pull request. Author: guoxiaolong <[email protected]> Closes #20216 from guoxiaolongzte/SPARK-23024.
-
[SPARK-23000][TEST] Keep Derby DB Location Unchanged After Session Cl…
…oning ## What changes were proposed in this pull request? After session cloning in `TestHive`, the conf of the singleton SparkContext for derby DB location is changed to a new directory. The new directory is created in `HiveUtils.newTemporaryConfiguration(useInMemoryDerby = false)`. This PR is to keep the conf value of `ConfVars.METASTORECONNECTURLKEY.varname` unchanged during the session clone. ## How was this patch tested? The issue can be reproduced by the command: > build/sbt -Phive "hive/test-only org.apache.spark.sql.hive.HiveSessionStateSuite org.apache.spark.sql.hive.DataSourceWithHiveMetastoreCatalogSuite" Also added a test case. Author: gatorsmile <[email protected]> Closes #20328 from gatorsmile/fixTestFailure.
-
[SPARK-23085][ML] API parity for mllib.linalg.Vectors.sparse
## What changes were proposed in this pull request? `ML.Vectors#sparse(size: Int, elements: Seq[(Int, Double)])` support zero-length ## How was this patch tested? existing tests Author: Zheng RuiFeng <[email protected]> Closes #20275 from zhengruifeng/SparseVector_size.
-
[SPARK-23149][SQL] polish ColumnarBatch
## What changes were proposed in this pull request? Several cleanups in `ColumnarBatch` * remove `schema`. The `ColumnVector`s inside `ColumnarBatch` already have the data type information, we don't need this `schema`. * remove `capacity`. `ColumnarBatch` is just a wrapper of `ColumnVector`s, not builders, it doesn't need a capacity property. * remove `DEFAULT_BATCH_SIZE`. As a wrapper, `ColumnarBatch` can't decide the batch size, it should be decided by the reader, e.g. parquet reader, orc reader, cached table reader. The default batch size should also be defined by the reader. ## How was this patch tested? existing tests. Author: Wenchen Fan <[email protected]> Closes #20316 from cloud-fan/columnar-batch.
-
[SPARK-23104][K8S][DOCS] Changes to Kubernetes scheduler documentation
## What changes were proposed in this pull request? Docs changes: - Adding a warning that the backend is experimental. - Removing a defunct internal-only option from documentation - Clarifying that node selectors can be used right away, and other minor cosmetic changes ## How was this patch tested? Docs only change Author: foxish <[email protected]> Closes #20314 from foxish/ambiguous-docs.
-
[SPARK-20664][CORE] Delete stale application data from SHS.
Detect the deletion of event log files from storage, and remove data about the related application attempt in the SHS. Also contains code to fix SPARK-21571 based on code by ericvandenbergfb. Author: Marcelo Vanzin <[email protected]> Closes #20138 from vanzin/SPARK-20664.
-
[SPARK-23103][CORE] Ensure correct sort order for negative values in …
…LevelDB. The code was sorting "0" as "less than" negative values, which is a little wrong. Fix is simple, most of the changes are the added test and related cleanup. Author: Marcelo Vanzin <[email protected]> Closes #20284 from vanzin/SPARK-23103.
-
[SPARK-23135][UI] Fix rendering of accumulators in the stage page.
This follows the behavior of 2.2: only named accumulators with a value are rendered. Screenshot:  Author: Marcelo Vanzin <[email protected]> Closes #20299 from vanzin/SPARK-23135.
-
[SPARK-21771][SQL] remove useless hive client in SparkSQLEnv
## What changes were proposed in this pull request? Once a meta hive client is created, it generates its SessionState which creates a lot of session related directories, some deleteOnExit, some does not. if a hive client is useless we may not create it at the very start. ## How was this patch tested? N/A cc hvanhovell cloud-fan Author: Kent Yao <[email protected]> Closes #18983 from yaooqinn/patch-1.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Commits on Jan 20, 2018
-
[SPARK-23091][ML] Incorrect unit test for approxQuantile
## What changes were proposed in this pull request? Narrow bound on approx quantile test to epsilon from 2*epsilon to match paper ## How was this patch tested? Existing tests. Author: Sean Owen <[email protected]> Closes #20324 from srowen/SPARK-23091.
-
[SPARK-23165][DOC] Spelling mistake fix in quick-start doc.
## What changes were proposed in this pull request? Fix spelling in quick-start doc. ## How was this patch tested? Doc only. Author: Shashwat Anand <[email protected]> Closes #20336 from ashashwat/SPARK-23165.
-
[SPARK-21786][SQL] The 'spark.sql.parquet.compression.codec' and 'spa…
…rk.sql.orc.compression.codec' configuration doesn't take effect on hive table writing [SPARK-21786][SQL] The 'spark.sql.parquet.compression.codec' and 'spark.sql.orc.compression.codec' configuration doesn't take effect on hive table writing What changes were proposed in this pull request? Pass ‘spark.sql.parquet.compression.codec’ value to ‘parquet.compression’. Pass ‘spark.sql.orc.compression.codec’ value to ‘orc.compress’. How was this patch tested? Add test. Note: This is the same issue mentioned in #19218 . That branch was deleted mistakenly, so make a new pr instead. gatorsmile maropu dongjoon-hyun discipleforteen Author: fjh100456 <[email protected]> Author: Takeshi Yamamuro <[email protected]> Author: Wenchen Fan <[email protected]> Author: gatorsmile <[email protected]> Author: Yinan Li <[email protected]> Author: Marcelo Vanzin <[email protected]> Author: Juliusz Sompolski <[email protected]> Author: Felix Cheung <[email protected]> Author: jerryshao <[email protected]> Author: Li Jin <[email protected]> Author: Gera Shegalov <[email protected]> Author: chetkhatri <[email protected]> Author: Joseph K. Bradley <[email protected]> Author: Bago Amirbekian <[email protected]> Author: Xianjin YE <[email protected]> Author: Bruce Robbins <[email protected]> Author: zuotingbing <[email protected]> Author: Kent Yao <[email protected]> Author: hyukjinkwon <[email protected]> Author: Adrian Ionescu <[email protected]> Closes #20087 from fjh100456/HiveTableWriting.