Apache spark pull latest #11
Merged
Conversation
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
## What changes were proposed in this pull request? unpersist unused datasets ## How was this patch tested? existing tests and local check in Spark-Shell Author: Zheng RuiFeng <[email protected]> Closes #20017 from zhengruifeng/bkm_unpersist.
## What changes were proposed in this pull request? In the previous PR #5755 (comment), we dropped `(-[classifier])` from the retrieval pattern. We should add it back; otherwise, > If this pattern for instance doesn't has the [type] or [classifier] token, Ivy will download the source/javadoc artifacts to the same file as the regular jar. ## How was this patch tested? The existing tests Author: gatorsmile <[email protected]> Closes #20037 from gatorsmile/addClassifier.
## What changes were proposed in this pull request? * Under Spark Scala Examples: Some of the syntax were written like Java way, It has been re-written as per scala style guide. * Most of all changes are followed to println() statement. ## How was this patch tested? Since, All changes proposed are re-writing println statements in scala way, manual run used to test println. Author: chetkhatri <[email protected]> Closes #20016 from chetkhatri/scala-style-spark-examples.
…assigning schedulingPool for stage
## What changes were proposed in this pull request?
In AppStatusListener's onStageSubmitted(event: SparkListenerStageSubmitted) method, there are duplicate code:
```
// schedulingPool was assigned twice with the same code
stage.schedulingPool = Option(event.properties).flatMap { p =>
Option(p.getProperty("spark.scheduler.pool"))
}.getOrElse(SparkUI.DEFAULT_POOL_NAME)
...
...
...
stage.schedulingPool = Option(event.properties).flatMap { p =>
Option(p.getProperty("spark.scheduler.pool"))
}.getOrElse(SparkUI.DEFAULT_POOL_NAME)
```
But, it does not make any sense to do this and there are no comment to explain for this.
## How was this patch tested?
N/A
Author: wuyi <[email protected]>
Closes #20033 from Ngone51/dev-spark-22847.
…ay to take time instead of int ## What changes were proposed in this pull request? Fixing configuration that was taking an int which should take time. Discussion in #19946 (comment) Made the granularity milliseconds as opposed to seconds since there's a use-case for sub-second reactions to scale-up rapidly especially with dynamic allocation. ## How was this patch tested? TODO: manual run of integration tests against this PR. PTAL cc/ mccheah liyinan926 kimoonkim vanzin mridulm jiangxb1987 ueshin Author: foxish <[email protected]> Closes #20032 from foxish/fix-time-conf.
…h huber loss. ## What changes were proposed in this pull request? Expose Python API for _LinearRegression_ with _huber_ loss. ## How was this patch tested? Unit test. Author: Yanbo Liang <[email protected]> Closes #19994 from yanboliang/spark-22810.
…e options ## What changes were proposed in this pull request? Introduce a new interface `SessionConfigSupport` for `DataSourceV2`, it can help to propagate session configs with the specified key-prefix to all data source operations in this session. ## How was this patch tested? Add new test suite `DataSourceV2UtilsSuite`. Author: Xingbo Jiang <[email protected]> Closes #19861 from jiangxb1987/datasource-configs.
…orized summarizer ## What changes were proposed in this pull request? Make several improvements in dataframe vectorized summarizer. 1. Make the summarizer return `Vector` type for all metrics (except "count"). It will return "WrappedArray" type before which won't be very convenient. 2. Make `MetricsAggregate` inherit `ImplicitCastInputTypes` trait. So it can check and implicitly cast input values. 3. Add "weight" parameter for all single metric method. 4. Update doc and improve the example code in doc. 5. Simplified test cases. ## How was this patch tested? Test added and simplified. Author: WeichenXu <[email protected]> Closes #19156 from WeichenXu123/improve_vec_summarizer.
## What changes were proposed in this pull request? This PR eliminates mutable states from the generated code for `Stack`. ## How was this patch tested? Existing test suites Author: Kazuaki Ishizaki <[email protected]> Closes #20035 from kiszk/SPARK-22848.
## What changes were proposed in this pull request? Upgrade Spark to Arrow 0.8.0 for Java and Python. Also includes an upgrade of Netty to 4.1.17 to resolve dependency requirements. The highlights that pertain to Spark for the update from Arrow versoin 0.4.1 to 0.8.0 include: * Java refactoring for more simple API * Java reduced heap usage and streamlined hot code paths * Type support for DecimalType, ArrayType * Improved type casting support in Python * Simplified type checking in Python ## How was this patch tested? Existing tests Author: Bryan Cutler <[email protected]> Author: Shixiong Zhu <[email protected]> Closes #19884 from BryanCutler/arrow-upgrade-080-SPARK-22324.
## What changes were proposed in this pull request? Moves the -Xlint:unchecked flag in the sbt build configuration from Compile to (Compile, compile) scope, allowing publish and publishLocal commands to work. ## How was this patch tested? Successfully published the spark-launcher subproject from within sbt successfully, where it fails without this patch. Author: Erik LaBianca <[email protected]> Closes #20040 from easel/javadoc-xlint.
Prevents Scala 2.12 scaladoc from blowing up attempting to parse java comments. ## What changes were proposed in this pull request? Adds -no-java-comments to docs/scalacOptions under Scala 2.12. Also moves scaladoc configs out of the TestSettings and into the standard sharedSettings section in SparkBuild.scala. ## How was this patch tested? SBT_OPTS=-Dscala-2.12 sbt ++2.12.4 tags/publishLocal Author: Erik LaBianca <[email protected]> Closes #20042 from easel/scaladoc-212.
…split by CodegenContext.splitExpressions() ## What changes were proposed in this pull request? Passing global variables to the split method is dangerous, as any mutating to it is ignored and may lead to unexpected behavior. To prevent this, one approach is to make sure no expression would output global variables: Localizing lifetime of mutable states in expressions. Another approach is, when calling `ctx.splitExpression`, make sure we don't use children's output as parameter names. Approach 1 is actually hard to do, as we need to check all expressions and operators that support whole-stage codegen. Approach 2 is easier as the callers of `ctx.splitExpressions` are not too many. Besides, approach 2 is more flexible, as children's output may be other stuff that can't be parameter name: literal, inlined statement(a + 1), etc. close #19865 close #19938 ## How was this patch tested? existing tests Author: Wenchen Fan <[email protected]> Closes #20021 from cloud-fan/codegen.
## What changes were proposed in this pull request? In #19681 we introduced a new interface called `AppStatusPlugin`, to register listeners and set up the UI for both live and history UI. However I think it's an overkill for live UI. For example, we should not register `SQLListener` if users are not using SQL functions. Previously we register the `SQLListener` and set up SQL tab when `SparkSession` is firstly created, which indicates users are going to use SQL functions. But in #19681 , we register the SQL functions during `SparkContext` creation. The same thing should apply to streaming too. I think we should keep the previous behavior, and only use this new interface for history server. To reflect this change, I also rename the new interface to `SparkHistoryUIPlugin` This PR also refines the tests for sql listener. ## How was this patch tested? existing tests Author: Wenchen Fan <[email protected]> Closes #19981 from cloud-fan/listener.
…ecision ## What changes were proposed in this pull request? Test Coverage for `WindowFrameCoercion` and `DecimalPrecision`, this is a Sub-tasks for [SPARK-22722](https://issues.apache.org/jira/browse/SPARK-22722). ## How was this patch tested? N/A Author: Yuming Wang <[email protected]> Closes #20008 from wangyum/SPARK-22822.
…ild's partitioning is not decided ## What changes were proposed in this pull request? This is a followup PR of #19257 where gatorsmile had left couple comments wrt code style. ## How was this patch tested? Doesn't change any functionality. Will depend on build to see if no checkstyle rules are violated. Author: Tejas Patil <[email protected]> Closes #20041 from tejasapatil/followup_19257.
When one execution has multiple jobs, we need to append to the set of stages, not replace them on every job. Added unit test and ran existing tests on jenkins Author: Imran Rashid <[email protected]> Closes #20047 from squito/SPARK-22861.
What changes were proposed in this pull request? This PR contains documentation on the usage of Kubernetes scheduler in Spark 2.3, and a shell script to make it easier to build docker images required to use the integration. The changes detailed here are covered by #19717 and #19468 which have merged already. How was this patch tested? The script has been in use for releases on our fork. Rest is documentation. cc rxin mateiz (shepherd) k8s-big-data SIG members & contributors: foxish ash211 mccheah liyinan926 erikerlandson ssuchter varunkatta kimoonkim tnachen ifilonenko reviewers: vanzin felixcheung jiangxb1987 mridulm TODO: - [x] Add dockerfiles directory to built distribution. (#20007) - [x] Change references to docker to instead say "container" (#19995) - [x] Update configuration table. - [x] Modify spark.kubernetes.allocation.batch.delay to take time instead of int (#20032) Author: foxish <[email protected]> Closes #19946 from foxish/update-k8s-docs.
The code was ignoring SparkListenerLogStart, which was added somewhat recently to record the Spark version used to generate an event log. Author: Marcelo Vanzin <[email protected]> Closes #20049 from vanzin/SPARK-22854.
## What changes were proposed in this pull request? The PR introduces a new method `addImmutableStateIfNotExists ` to `CodeGenerator` to allow reusing and sharing the same global variable between different Expressions. This helps reducing the number of global variables needed, which is important to limit the impact on the constant pool. ## How was this patch tested? added UTs Author: Marco Gaido <[email protected]> Author: Marco Gaido <[email protected]> Closes #19940 from mgaido91/SPARK-22750.
…- LabeledPoint/VectorWithNorm/TreePoint ## What changes were proposed in this pull request? register following classes in Kryo: `org.apache.spark.mllib.regression.LabeledPoint` `org.apache.spark.mllib.clustering.VectorWithNorm` `org.apache.spark.ml.feature.LabeledPoint` `org.apache.spark.ml.tree.impl.TreePoint` `org.apache.spark.ml.tree.impl.BaggedPoint` seems also need to be registered, but I don't know how to do it in this safe way. WeichenXu123 cloud-fan ## How was this patch tested? added tests Author: Zheng RuiFeng <[email protected]> Closes #19950 from zhengruifeng/labeled_kryo.
## What changes were proposed in this pull request? The path was recently changed in #19946, but the dockerfile was not updated. This is a trivial 1 line fix. ## How was this patch tested? `./sbin/build-push-docker-images.sh -r spark-repo -t latest build` cc/ vanzin mridulm rxin jiangxb1987 liyinan926 Author: Anirudh Ramanathan <[email protected]> Author: foxish <[email protected]> Closes #20051 from foxish/patch-1.
…oder This behavior has confused some users, so lets clarify it. Author: Michael Armbrust <[email protected]> Closes #20048 from marmbrus/datasetAsDocs.
…seVersion. ## What changes were proposed in this pull request? Currently we check pandas version by capturing if `ImportError` for the specific imports is raised or not but we can compare `LooseVersion` of the version strings as the same as we're checking pyarrow version. ## How was this patch tested? Existing tests. Author: Takuya UESHIN <[email protected]> Closes #20054 from ueshin/issues/SPARK-22874.
…r in StructuredSteaming ## What changes were proposed in this pull request? A new VectorSizeHint transformer was added. This transformer is meant to be used as a pipeline stage ahead of VectorAssembler, on vector columns, so that VectorAssembler can join vectors in a streaming context where the size of the input vectors is otherwise not known. ## How was this patch tested? Unit tests. Please review http://spark.apache.org/contributing.html before opening a pull request. Author: Bago Amirbekian <[email protected]> Closes #19746 from MrBago/vector-size-hint.
## What changes were proposed in this pull request? Basic continuous execution, supporting map/flatMap/filter, with commits and advancement through RPC. ## How was this patch tested? new unit-ish tests (exercising execution end to end) Author: Jose Torres <[email protected]> Closes #19984 from jose-torres/continuous-impl.
## What changes were proposed in this pull request? SparkHive Scala Examples Improvement made: * Writing DataFrame / DataSet to Hive Managed , Hive External table using different storage format. * Implementation of Partition, Reparition, Coalesce with appropriate example. ## How was this patch tested? * Patch has been tested manually and by running ./dev/run-tests. Author: chetkhatri <[email protected]> Closes #20018 from chetkhatri/scala-sparkhive-examples.
## What changes were proposed in this pull request? Create table using the right DataFrame. peopleDF->usersDF peopleDF: +----+-------+ | age| name| +----+-------+ usersDF: +------+--------------+----------------+ | name|favorite_color|favorite_numbers| +------+--------------+----------------+ ## How was this patch tested? Manually tested. Author: CNRui <[email protected]> Closes #20052 from CNRui/patch-2.
## What changes were proposed in this pull request? This PR fixes a style that broke the build. ## How was this patch tested? Manually tested. Author: hyukjinkwon <[email protected]> Closes #20065 from HyukjinKwon/minor-style.
## What changes were proposed in this pull request?
This PR adds `date_trunc` in R API as below:
```r
> df <- createDataFrame(list(list(a = as.POSIXlt("2012-12-13 12:34:00"))))
> head(select(df, date_trunc("hour", df$a)))
date_trunc(hour, a)
1 2012-12-13 12:00:00
```
## How was this patch tested?
Unit tests added in `R/pkg/tests/fulltests/test_sparkSQL.R`.
Author: hyukjinkwon <[email protected]>
Closes #20031 from HyukjinKwon/r-datetrunc.
…ften returns NULL ## What changes were proposed in this pull request? When there is an operation between Decimals and the result is a number which is not representable exactly with the result's precision and scale, Spark is returning `NULL`. This was done to reflect Hive's behavior, but it is against SQL ANSI 2011, which states that "If the result cannot be represented exactly in the result type, then whether it is rounded or truncated is implementation-defined". Moreover, Hive now changed its behavior in order to respect the standard, thanks to HIVE-15331. Therefore, the PR propose to: - update the rules to determine the result precision and scale according to the new Hive's ones introduces in HIVE-15331; - round the result of the operations, when it is not representable exactly with the result's precision and scale, instead of returning `NULL` - introduce a new config `spark.sql.decimalOperations.allowPrecisionLoss` which default to `true` (ie. the new behavior) in order to allow users to switch back to the previous one. Hive behavior reflects SQLServer's one. The only difference is that the precision and scale are adjusted for all the arithmetic operations in Hive, while SQL Server is said to do so only for multiplications and divisions in the documentation. This PR follows Hive's behavior. A more detailed explanation is available here: https://mail-archives.apache.org/mod_mbox/spark-dev/201712.mbox/%3CCAEorWNAJ4TxJR9NBcgSFMD_VxTg8qVxusjP%2BAJP-x%2BJV9zH-yA%40mail.gmail.com%3E. ## How was this patch tested? modified and added UTs. Comparisons with results of Hive and SQLServer. Author: Marco Gaido <[email protected]> Closes #20023 from mgaido91/SPARK-22036.
…for registerJavaFunction. ## What changes were proposed in this pull request? Currently `UDFRegistration.registerJavaFunction` doesn't support data type string as a `returnType` whereas `UDFRegistration.register`, `udf`, or `pandas_udf` does. We can support it for `UDFRegistration.registerJavaFunction` as well. ## How was this patch tested? Added a doctest and existing tests. Author: Takuya UESHIN <[email protected]> Closes #20307 from ueshin/issues/SPARK-23141.
## What changes were proposed in this pull request?
Stage's task page table will throw an exception when there's no complete tasks. Furthermore, because the `dataSize` doesn't take running tasks into account, so sometimes UI cannot show the running tasks. Besides table will only be displayed when first task is finished according to the default sortColumn("index").
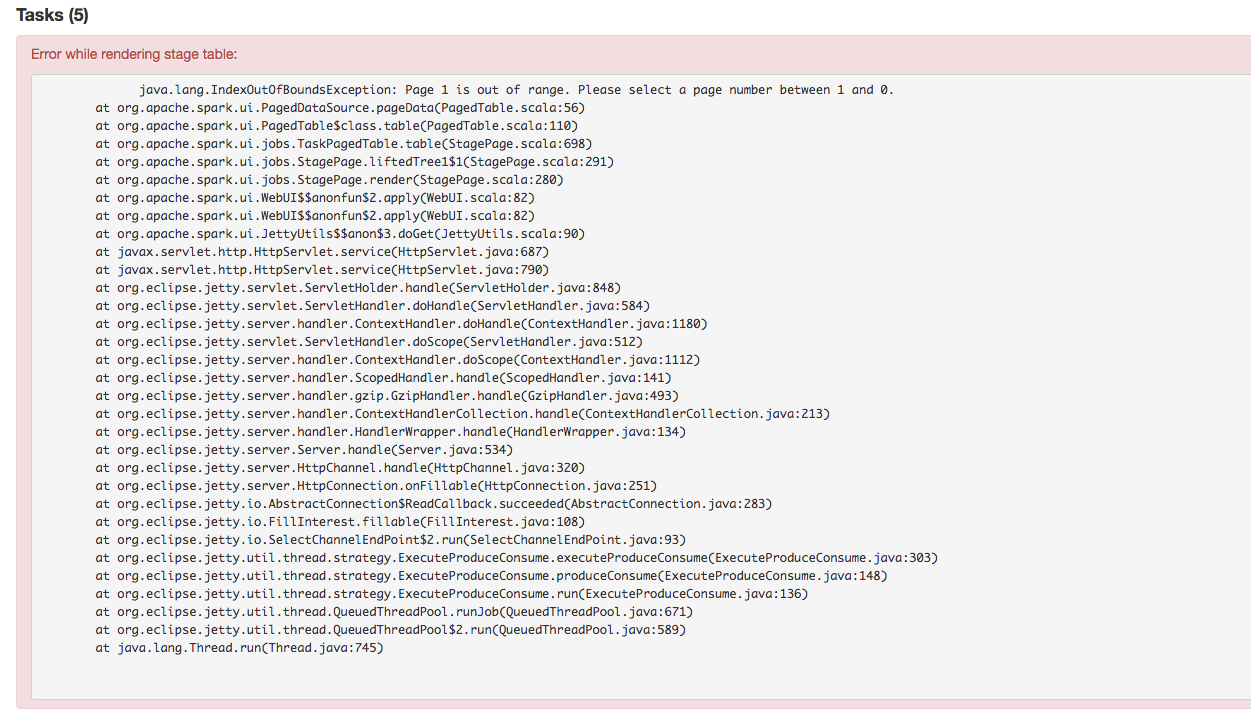
To reproduce this issue, user could try `sc.parallelize(1 to 20, 20).map { i => Thread.sleep(10000); i }.collect()` or `sc.parallelize(1 to 20, 20).map { i => Thread.sleep((20 - i) * 1000); i }.collect` to reproduce the above issue.
Here propose a solution to fix it. Not sure if it is a right fix, please help to review.
## How was this patch tested?
Manual test.
Author: jerryshao <[email protected]>
Closes #20315 from jerryshao/SPARK-23147.
{kind=link}
## What changes were proposed in this pull request? This PR completes the docs, specifying the default units assumed in configuration entries of type size. This is crucial since unit-less values are accepted and the user might assume the base unit is bytes, which in most cases it is not, leading to hard-to-debug problems. ## How was this patch tested? This patch updates only documentation only. Author: Fernando Pereira <[email protected]> Closes #20269 from ferdonline/docs_units.
…gger ## What changes were proposed in this pull request? Self-explanatory. ## How was this patch tested? New python tests. Author: Tathagata Das <[email protected]> Closes #20309 from tdas/SPARK-23143.
## What changes were proposed in this pull request? Refactored ConsoleWriter into ConsoleMicrobatchWriter and ConsoleContinuousWriter. ## How was this patch tested? new unit test Author: Tathagata Das <[email protected]> Closes #20311 from tdas/SPARK-23144.
Pass through spark java options to the executor in context of docker image. Closes #20296 andrusha: Deployed two version of containers to local k8s, checked that java options were present in the updated image on the running executor. Manual test Author: Andrew Korzhuev <[email protected]> Closes #20322 from foxish/patch-1.
## What changes were proposed in this pull request? There were two related fixes regarding `from_json`, `get_json_object` and `json_tuple` ([Fix #1](c8803c0), [Fix #2](86174ea)), but they weren't comprehensive it seems. I wanted to extend those fixes to all the parsers, and add tests for each case. ## How was this patch tested? Regression tests Author: Burak Yavuz <[email protected]> Closes #20302 from brkyvz/json-invfix.
## What changes were proposed in this pull request? In the Kubernetes mode, fails fast in the submission process if any submission client local dependencies are used as the use case is not supported yet. ## How was this patch tested? Unit tests, integration tests, and manual tests. vanzin foxish Author: Yinan Li <[email protected]> Closes #20320 from liyinan926/master.
## What changes were proposed in this pull request? Added documentation for continuous processing. Modified two locations. - Modified the overview to have a mention of Continuous Processing. - Added a new section on Continuous Processing at the end.   ## How was this patch tested? N/A Author: Tathagata Das <[email protected]> Closes #20308 from tdas/SPARK-23142.
{kind=link}
{kind=link}
…integration document ## What changes were proposed in this pull request? In latest structured-streaming-kafka-integration document, Java code example for Kafka integration is using `DataFrame<Row>`, shouldn't it be changed to `DataSet<Row>`? ## How was this patch tested? manual test has been performed to test the updated example Java code in Spark 2.2.1 with Kafka 1.0 Author: brandonJY <[email protected]> Closes #20312 from brandonJY/patch-2.
…g PythonUserDefinedType to String. ## What changes were proposed in this pull request? This is a follow-up of #20246. If a UDT in Python doesn't have its corresponding Scala UDT, cast to string will be the raw string of the internal value, e.g. `"org.apache.spark.sql.catalyst.expressions.UnsafeArrayDataxxxxxxxx"` if the internal type is `ArrayType`. This pr fixes it by using its `sqlType` casting. ## How was this patch tested? Added a test and existing tests. Author: Takuya UESHIN <[email protected]> Closes #20306 from ueshin/issues/SPARK-23054/fup1.
## What changes were proposed in this pull request? This patch fixes a few recently introduced java style check errors in master and release branch. As an aside, given that [java linting currently fails](#10763 ) on machines with a clean maven cache, it'd be great to find another workaround to [re-enable the java style checks](https://github.com/apache/spark/blob/3a07eff5af601511e97a05e6fea0e3d48f74c4f0/dev/run-tests.py#L577) as part of Spark PRB. /cc zsxwing JoshRosen srowen for any suggestions ## How was this patch tested? Manual Check Author: Sameer Agarwal <[email protected]> Closes #20323 from sameeragarwal/java.
…ameter Update user guide entry for `FeatureHasher` to match the Scala / Python doc, to describe the `categoricalCols` parameter. ## How was this patch tested? Doc only Author: Nick Pentreath <[email protected]> Closes #20293 from MLnick/SPARK-23127-catCol-userguide.
## What changes were proposed in this pull request? We have `OneHotEncoderEstimator` now and `OneHotEncoder` will be deprecated since 2.3.0. We should add `OneHotEncoderEstimator` into mllib document. We also need to provide corresponding examples for `OneHotEncoderEstimator` which are used in the document too. ## How was this patch tested? Existing tests. Author: Liang-Chi Hsieh <[email protected]> Closes #20257 from viirya/SPARK-23048.
## What changes were proposed in this pull request? When creating a session directory, Thrift should create the parent directory (i.e. /tmp/base_session_log_dir) if it is not present. It is common that many tools delete empty directories, so the directory may be deleted. This can cause the session log to be disabled. This was fixed in HIVE-12262: this PR brings it in Spark too. ## How was this patch tested? manual tests Author: Marco Gaido <[email protected]> Closes #20281 from mgaido91/SPARK-23089.
… have hidden and show features, when the table records very much. ## What changes were proposed in this pull request? Spark ui about the contents of the form need to have hidden and show features, when the table records very much. Because sometimes you do not care about the record of the table, you just want to see the contents of the next table, but you have to scroll the scroll bar for a long time to see the contents of the next table. Currently we have about 500 workers, but I just wanted to see the logs for the running applications table. I had to scroll through the scroll bars for a long time to see the logs for the running applications table. In order to ensure functional consistency, I modified the Master Page, Worker Page, Job Page, Stage Page, Task Page, Configuration Page, Storage Page, Pool Page. fix before: 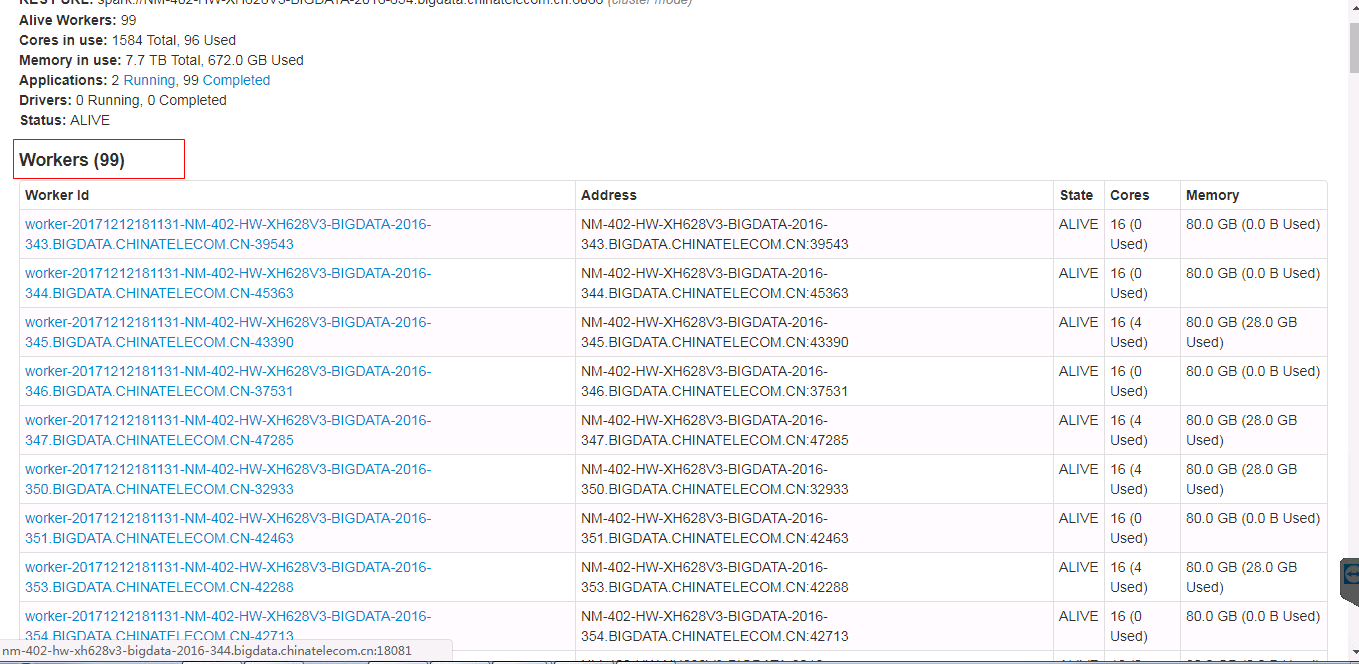 fix after: 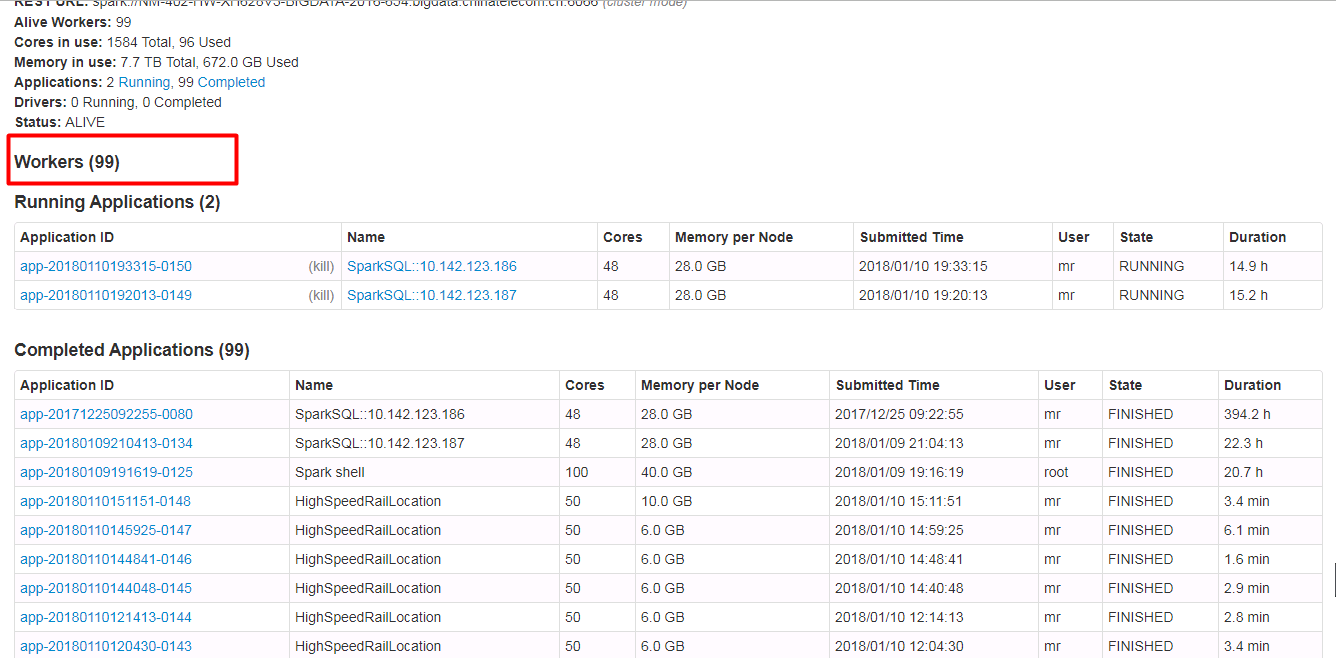 ## How was this patch tested? manual tests Please review http://spark.apache.org/contributing.html before opening a pull request. Author: guoxiaolong <[email protected]> Closes #20216 from guoxiaolongzte/SPARK-23024.
{kind=link}
{kind=link}
…oning ## What changes were proposed in this pull request? After session cloning in `TestHive`, the conf of the singleton SparkContext for derby DB location is changed to a new directory. The new directory is created in `HiveUtils.newTemporaryConfiguration(useInMemoryDerby = false)`. This PR is to keep the conf value of `ConfVars.METASTORECONNECTURLKEY.varname` unchanged during the session clone. ## How was this patch tested? The issue can be reproduced by the command: > build/sbt -Phive "hive/test-only org.apache.spark.sql.hive.HiveSessionStateSuite org.apache.spark.sql.hive.DataSourceWithHiveMetastoreCatalogSuite" Also added a test case. Author: gatorsmile <[email protected]> Closes #20328 from gatorsmile/fixTestFailure.
## What changes were proposed in this pull request? `ML.Vectors#sparse(size: Int, elements: Seq[(Int, Double)])` support zero-length ## How was this patch tested? existing tests Author: Zheng RuiFeng <[email protected]> Closes #20275 from zhengruifeng/SparseVector_size.
## What changes were proposed in this pull request? Several cleanups in `ColumnarBatch` * remove `schema`. The `ColumnVector`s inside `ColumnarBatch` already have the data type information, we don't need this `schema`. * remove `capacity`. `ColumnarBatch` is just a wrapper of `ColumnVector`s, not builders, it doesn't need a capacity property. * remove `DEFAULT_BATCH_SIZE`. As a wrapper, `ColumnarBatch` can't decide the batch size, it should be decided by the reader, e.g. parquet reader, orc reader, cached table reader. The default batch size should also be defined by the reader. ## How was this patch tested? existing tests. Author: Wenchen Fan <[email protected]> Closes #20316 from cloud-fan/columnar-batch.
## What changes were proposed in this pull request? Docs changes: - Adding a warning that the backend is experimental. - Removing a defunct internal-only option from documentation - Clarifying that node selectors can be used right away, and other minor cosmetic changes ## How was this patch tested? Docs only change Author: foxish <[email protected]> Closes #20314 from foxish/ambiguous-docs.
Closes #20185.
Detect the deletion of event log files from storage, and remove data about the related application attempt in the SHS. Also contains code to fix SPARK-21571 based on code by ericvandenbergfb. Author: Marcelo Vanzin <[email protected]> Closes #20138 from vanzin/SPARK-20664.
…LevelDB. The code was sorting "0" as "less than" negative values, which is a little wrong. Fix is simple, most of the changes are the added test and related cleanup. Author: Marcelo Vanzin <[email protected]> Closes #20284 from vanzin/SPARK-23103.
This follows the behavior of 2.2: only named accumulators with a value are rendered. Screenshot:  Author: Marcelo Vanzin <[email protected]> Closes #20299 from vanzin/SPARK-23135.
{kind=link}
## What changes were proposed in this pull request? Once a meta hive client is created, it generates its SessionState which creates a lot of session related directories, some deleteOnExit, some does not. if a hive client is useless we may not create it at the very start. ## How was this patch tested? N/A cc hvanhovell cloud-fan Author: Kent Yao <[email protected]> Closes #18983 from yaooqinn/patch-1.
## What changes were proposed in this pull request? Narrow bound on approx quantile test to epsilon from 2*epsilon to match paper ## How was this patch tested? Existing tests. Author: Sean Owen <[email protected]> Closes #20324 from srowen/SPARK-23091.
## What changes were proposed in this pull request? Fix spelling in quick-start doc. ## How was this patch tested? Doc only. Author: Shashwat Anand <[email protected]> Closes #20336 from ashashwat/SPARK-23165.
…rk.sql.orc.compression.codec' configuration doesn't take effect on hive table writing [SPARK-21786][SQL] The 'spark.sql.parquet.compression.codec' and 'spark.sql.orc.compression.codec' configuration doesn't take effect on hive table writing What changes were proposed in this pull request? Pass ‘spark.sql.parquet.compression.codec’ value to ‘parquet.compression’. Pass ‘spark.sql.orc.compression.codec’ value to ‘orc.compress’. How was this patch tested? Add test. Note: This is the same issue mentioned in #19218 . That branch was deleted mistakenly, so make a new pr instead. gatorsmile maropu dongjoon-hyun discipleforteen Author: fjh100456 <[email protected]> Author: Takeshi Yamamuro <[email protected]> Author: Wenchen Fan <[email protected]> Author: gatorsmile <[email protected]> Author: Yinan Li <[email protected]> Author: Marcelo Vanzin <[email protected]> Author: Juliusz Sompolski <[email protected]> Author: Felix Cheung <[email protected]> Author: jerryshao <[email protected]> Author: Li Jin <[email protected]> Author: Gera Shegalov <[email protected]> Author: chetkhatri <[email protected]> Author: Joseph K. Bradley <[email protected]> Author: Bago Amirbekian <[email protected]> Author: Xianjin YE <[email protected]> Author: Bruce Robbins <[email protected]> Author: zuotingbing <[email protected]> Author: Kent Yao <[email protected]> Author: hyukjinkwon <[email protected]> Author: Adrian Ionescu <[email protected]> Closes #20087 from fjh100456/HiveTableWriting.
Sign up for free
to join this conversation on GitHub.
Already have an account?
Sign in to comment
Add this suggestion to a batch that can be applied as a single commit.
This suggestion is invalid because no changes were made to the code.
Suggestions cannot be applied while the pull request is closed.
Suggestions cannot be applied while viewing a subset of changes.
Only one suggestion per line can be applied in a batch.
Add this suggestion to a batch that can be applied as a single commit.
Applying suggestions on deleted lines is not supported.
You must change the existing code in this line in order to create a valid suggestion.
Outdated suggestions cannot be applied.
This suggestion has been applied or marked resolved.
Suggestions cannot be applied from pending reviews.
Suggestions cannot be applied on multi-line comments.
Suggestions cannot be applied while the pull request is queued to merge.
Suggestion cannot be applied right now. Please check back later.
What changes were proposed in this pull request?
(Please fill in changes proposed in this fix)
How was this patch tested?
(Please explain how this patch was tested. E.g. unit tests, integration tests, manual tests)
(If this patch involves UI changes, please attach a screenshot; otherwise, remove this)
Please review http://spark.apache.org/contributing.html before opening a pull request.