Site Reliability
Software is released, not when it is known to be correct, but when the rate of discovering errors slow down to one that management considers acceptable.
Good marketing can kill you at any time. -- Paul Lord
- Pre-autoscale by upping the configuration before the marketing event goes out.
Scalability has no theoretical limit. We may be restricted by our implementation, but in a perfectly scalable system, we could scale forever.
Scalability is the number of requests we can handle at a time (i.e. the load). The number of requests we can handle at a time (i.e. the load). That's the reason reactive microservices focus on improving Scalability.
Performance and Scalability can be measured by requests/second.
It's unlikely you can build a test farm the same size as your production environment. Scaling cannot be tested out - it must be designed out.
Patterns that work fine in small environments or one-to-one environments might slow down or fall completely when moved to the production sizes.
- Shared resources can be a bottleneck, a capacity constraint, and a threat ti stability. Stress them heavily.
- Be sure the clients keep working if the shared resource gets slow or locks up.
The most scalable architecture is the shared-nothing architecture. The trouble is that is can scale better at the cost of failover.
- Avoid self-denial by building a "shared-nothing" architecture.
- Make the shared resource itself horizontally scalable through redundancy.
- Design a fallback mode for the system to use when the shared resource is not available or not responding.
Point-to-point communication scales badly.
Steady-state load on a system might be sifnificantly different than the startup or periodic load.
- Stress both sides of the interface.
- Backend stressing: what happend by ten times the highest-ever demand?
- Frontend stressig: what happend if calls to the backend stop responsing or get very slow?
You need production-sized data sets to see what happends when the query returns a milion rows that you turn into objects.
- Don't rely on the data producers to create a limited amount of data.
- Paginate at the frontend.
Generating a slow response is worse than refusing a connection or returning an error.
A quick failure allows the calling system to finish processing the transaction rapidly. A slow response ties up resources in the calling and the called system.
For webserves, slow responsonses cause more traffic to already overloaded system (clicking the Reload button).
To an outside observer, there's no difference between "really slow" and "down".
Integration points are the number-one killer of systems. Every single one of those feeds presents a stability risk. Every socket, process, pipe, or remote procedure call can and will hang. Even database calls can hang, in ways obvious and subtle. Every feed into the system can hang it, crash it, or generate toher impulses at the worst possible time.
Every integration point will eventuallt fail in some way, and you need to be prepared for that failure.
Not every problem can be solved at the leverl of abstraction where it manifests. Sometimes the causes reverberate up and down the layers. You need to know how to drill through at least two layers of abstraction to find the "reality" at that level in order to understand the problem.
We can't tell what the execution context will be just by looking at the code.
If observations report that 80 percent of the system is unavailable, it's more likely to be a problem with the observer that the system.
Systems that consume resources should be statefull enough to detect if they're trying to spin up infinity instances.
Log files on production systems have a terrible signal-to-noise ration. It's best to get them off the individual hosts as quickly as possible.
- Ship the log files to a centralized logging server (Logstash), where they can be indexed, searched, and monitored.
Sessions are the Achilles' heel of every application server. Each session consumes resources, mainly RAM.
- Use sessions only for caching, so you can purge its contents if memory gets tight.
Weak references are a useful way to respond to changing memory conditions, but they do add complexity. When you can, it's best to just keep things out of the session.
An effective way to deal with per-user memory is to farm it out to a different process. Instead of keeping it inside the heap - it means inside the address space of your server's process - move it out to some other process (Redis).
Every application mst grapple with the fundamental nature of networks: networks are fallible.
- Expect failures!
- Develop a recovery-oriented mind set.
Well-placed timeouts provide fault isolation.
- Always use the method with the timeout argument.
Postel's robustness principe: Be conservative in what you do, be liberal in what you accept from others.
As soon as the service went live, its implementation comes the de facto specification.
You are not free to change the behaviour, even if it was something you never intended to support. Once the service is public, a new version cannot reject requests that would've been accepted before. Anything else is a breaking change.
- Learn many architectural styles, and select the best for the problem at hand.
You learn how to fix the things that often break. You don't learn how to fix the things that rarely break. But that means when they do break, the situation is likely to be more dire.
Wrapping dangerous operations with a component that can curcumvernt calls when the system is not healthy.
Circuit breakers are a way to automatically degrade functionality when the system is under stress.
In the normal "closed" state, the circuit breaker executes operations as usual. In the "open" state, calls to the circuit breaker fail immediately without any attempt to execute the real operation. After a suitable amount of time goes into the "half-open" state, the next call is allowed to execute the operation; when fails CI goes into "open" otherwise into "close".
Changes in a circuit breaker's state should always be logged, and the current state should be exposed for quering and monitoring.
Bulkheads keep a failure in one part of the system from destroying everything.
Most common from of bulheads is redundancy.
The "let it crash" approach says that error recovery is difficult and unrealiable, so our goal should be to get back to that clean startup as rapidly as possible.
If startup time is measured in minutes (as Java EE applications), then "let it crash" is not the right stategy.
Middleware is a graceless name for tools that inhabit a singularly messy space - integrating systems that were never meant to work together.
Tightly coupled (synchronous request/reply) middleware amplifies shocks to the system. The main advantage is its logical simplicity.
Less tightly coupled forms of middleware allow the calling and receiving systems to process messages in different places and at different times.
Message-oriented middleware decouples the endpoints in both space and time - this form of middleware cannot produce a cascading failure.
The move from synchronous to asynchronous communication neccessitates very different design.
Decoupling middleware is an architecture decision. It ripples into every part of the system. Should be make early rather than late.
When one component is struggling to keep-up, the system as a whole needs to respond in a sensible way.
Since the system can’t cope and it can’t fail it should communicate the fact that it is under stress to upstream components and so get them to reduce the load.
Back pressure creates safety by slowing down consumers.
Consumers will experience slowdowns - the only alternative is to let them crash the provider.
- Apply back pressure within a system boundary.
Broken access control allows attackers to access data they shouldn't.
- Log bad requests by source principal.
If a caller is not authorized to see the contents of a resource, it should be as if the resource doesn't even exist.
- Don't reveal any information by distingushing statuses as
403and404.
The API must ensure that malicious requests cannot access data the original user would not be able to see.
- Generate a unique but non-sequential identifiers to use in URLs.
A process should have the lowest level of privilege needed to accomplish its task.
Testing - even agile, pragmatic, atuomated testing - is not enough to prove that software is ready for the real world.
We can't simulate all aspects in a nonproduction environment because of the scale problem. We also can't gain confidence by testing components in solation. It turns out that like concurrency, safety is not a composable property. Two services may each be safe on their own, but the composition of them isn't neccessarily safe.
Any software, no matter how big, small, complex, or simple it is, inevitably contains an unlimited number of bugs. It is only a question of how many of them we can discover, fix, and how many deliver to end-users.
- We have to design our products so that they help us discover bugs.
- The cheapest and most effective way to discover bugs is to make software fragile. Software that breaks often does a big favor to the entire project, helping us to discover and document defects earlier and more easily.
- Throw as many exceptions as possible.
- Defects are there anyway, the question is how the product will behave when the issue occurs.
Fail save makes bugs more expensive. We need time and resources to find out exactly where the bugs are, and to determine when and why they appear.
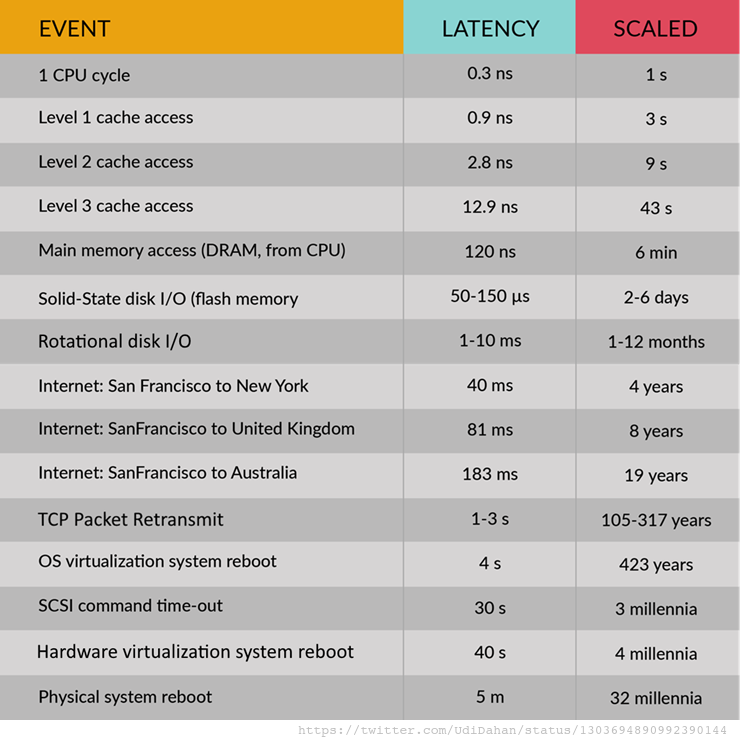
- Michael T. Nyguard - Release it! (2nd edition)
- Yegor Bugayenko: Elegant Objects
- https://www.reactivemanifesto.org
- CAP Theorem
- Sharding Effects
- High Scalability Blog
- Fit Rest API URLs with signing
- Avoiding fallback in distributed systems