DDD
Design is how it works. (Steve Jobs)
The real value of DDD: collaboration, communication, and context.
- Domain
- Building Blocks
- CQRS (Command Query Responsibility Segregation)
- Domain Specific Language (DSL)
- References
DDD should be fuzzy. By having fuzziness in DDD, we can explore, model and solve new and novel problems because the existing patterns and principles don’t over-constrain our thinking.
A (sub)domain is a non-mutually-exclusive, arbitrary subset of concepts in the universe.
Domains are subjective and they are not mutually exclusive. The same concepts can exist in many different domains.
Problem domain refers to the subject area for which you are building software.
- Software projects fail when you don’t understand the business domain you are working within well enough.
- A lack of focus on a shared language and knowledge of the problem domain results in a codebase that works but does not reveal the intent of the business.
- Complexities of the problem domain are often mixed with the accidental complexities of the technical solution -> Big Ball of Mud.
- Simple problems require simple solutions. Trivial domains or subdomains that do not hold a strategic advantage for businesses will not benefit from all the principles of DDD.
- Entire experience can be frustrating for the business that saw a great return on investment (ROI) in terms of features and speed of delivery at the beginning but over time, even with additional investment in resources.
- To avoid accidental technical complexity the model is kept isolated from infrastructure code.
- Don’t model real life: the relationship may exist in the problem domain, but it may not provide a benefit by existing in your code.
- Satisfy business use cases — not real life.
- Some domains are only relevant to the solution and not the problem.
- Whenever using the terms problem space and solution space, you need to clarify from which perspective you are speaking. Your problem space is someone else’s solution space. It’s your view of the domain.
- Problem space is everything we can't touch, solution space is everything we can make choices in.
DDD stresses the importance of collaboration between the development teams and business experts to produce useful models to solve problems.
- Knowledge crunching is an ongoing process.
- Problems are solved not only in code but through collaboration, communication, and exploration with domain experts.
- Developers should not be judged on how quickly they can churn out code; they must be judged on how they solve problems.
- It’s important to ensure that communication between teams always occurs for knowledge and skill-sharing benefits.
You are the enabler. Don’t blindly follow the user’s requirements. Business users may not be able to write effective features or effectively express goals. You must share and understand the underlying vision and be aware of what the business is trying to achieve so you can offer real business value.
Expression language of the shared understanding.
- UL must be made explicit and be used when describing the domain model and problem domain.
- UL should be used in the code implementation of the model, with the same terms and concepts used as class names, properties, and method names.
- Each Bounded Context should have its own UL.
- Invest in your problem by giving yourself time to think.
The team members must communicate with each other using the UL. The development team must use it in code, and the domain experts must use it when talking to the team.
- Talk only in business terms; don’t get technical.
Wraps the communication with legacy or third-party code to protect the integrity of a bounded context.
A domain model is not a model of real life; it is a system of abstractions on reality, an interpretation that only includes aspects of the problem domain that are prevalent to solving specific business use cases.
- Any changes from a business perspective need to be reflected in the code model.
- The code is the model; the code is the truth.
A useful model is not a copy of the real world. Instead, a model is intended to solve a problem, and it should provide just enough information for that purpose. [a]
The purpose of abstracting is not to be vague but to create a new semantic level in which one can be absolutely precise. [a]
A bounded context is the boundary of a model that represents domain concepts, their relationships, and their rules.
- The same subdomain could be represented by an infinite number of modeling choices.
Bounded contexts are the consistency boundaries of ubiquitous languages. A language's terminology, principles, and business rules are only consistent inside its bounded context. [a]
A ubiquitous language is ubiquitous only in the boundaries of its bounded context. [a]
Subdomains are identified by analyzing the business domain, bounded contexts, on the other hand, are designed. We decide how to divide the business domain into smaller, manageable problem domains. [a]
- Subdomains are discovered and bounded contexts are designed.
- Division of the domain into bounded contexts is a strategic design decision.
- Each bounded context can contain multiple subdomains.
Models are defined based on team structure, ambiguity in language, business process alignment, or physical deployment.
- Provides conceptual consistency.
- Bounded contexts don’t have to be consistent with each other.
- Names can have different meanings in different contexts.
- Based on their responsibilities and behavior.
- Ideally, there would be a one-to-one mapping between models and subdomains, but this is not always the case.
- Subdomain could contain more than a single model and a model could span more than a single subdomain.
- Bounded context could include concepts from multiple subdomains. Or a single subdomain could be modeled as multiple bounded contexts.
Bounded contexts combine at run time to carry out full use cases, so teams need a big-picture understanding of how their bounded context(s) fit into the wider system.
- Retain some communication between teams.
The bounded context pattern is the domain-driven design tool for defining physical and ownership boundaries. [a]
- A Bounded Context defines the boundaries of the biggest services possible.
- A Bounded Context can be decomposed into multiple service boundaries.
- A service's boundaries are based on service responsibilities and behavior.
- A Product in service A must have the same meaning as a Product in service B when both services are in the same BC (same sub-domain).
- A service is defined by its logical boundaries, not a physical deployment unit.
A bounded context should be implemented, evolved, and maintained by one team only. [a]
- However, a single team can own multiple bounded contexts.
"Make illegal states unrepresentable." ~ Yaron Minsky
Domain primitives are similar to value objects in Domain-Driven Design. Key differences are that we require invariants to exist and they must be enforced at the point of creation.
- Prohibit the use of simple language primitives, or generic types (including null), as representations of concepts in the domain model.
- Reduce the risk of bugs caused by lack of detailed domain knowledge of the concepts involved in the operation.
- Nothing in a domain model should be represented by a language primitive or a generic type.
- Each concept should be modeled as a domain primitive to carry meaning when passed around, and to uphold its invariants.
Let’s say you have the concept of quantity in your domain model. The quantity is the amount a customer wants to buy of a certain item in the webshop you’re building. The quantity is a number, but instead of representing it as an integer you create a domain primitive called Quantity.
An entity represents a concept in your domain that is defined by its identity rather than its attributes.
- Identity remains fixed throughout its lifecycle, its attributes may change.
- Example: a product.
Entities should be behavior oriented.
- Expose expressive methods that communicate domain behaviors instead of exposing state (“Tell Don’t Ask”).
- Be wary of exposing getters and extremely sensitive to exposing setters (making them public).
Value objects represent the elements or concepts of your domain that are known only by their characteristics - their attributes determine their identity.
- Always associated with another object.
- Can never alter their state.
- If instances can be completely replaced, it points to the use of a value object rather than an entity.
- Example: money.
- identity-less
- attribute-based equality
- behavior-rich
- immutable
- cohesive
- combinable
- self-validating
- testable
Aggregate = Entity + Repository
Aggregate is an explicit grouping of domain objects designed to support the behaviors and invariants of a domain model while acting as a consistency and transactional boundary.
- Domain entities should always be valid entities.
Aggregate defines the boundary of the cluster of domain objects and separates it in terms of consistency and transactional mechanism from all other domain objects outside it.
Domain objects are not retrieved or persisted individually. The aggregate as a conceptual whole is pulled from and committed to the datastore via a repository.
Aggregate root is an entity that has been chosen as the gateway into the aggregate.
- Any changes to objects in the aggregate need to come through its root.
- All communication with an aggregate should then occur only via its root.
- The root encapsulates the data of the aggregate and only exposes behaviors to change it.
- By grouping related domain objects, you can refer to them collectively as a single concept.
Invariant is a business rule then must always be consistent.
- A properly designed aggregate is one that can be modified in any way required by the business with its invariants completely consistent within a single transaction.
- A properly designed bounded context modifies only one aggregate instance per transaction.
- User interface should concentrate each request to execute a single command on just one aggregate instance.
- Aggregates are chiefly about consistency boundaries and not driven by a desire to design object graphs.
- Large cluster aggregate will never perform or scale well.
- A bidirectional relationship should be converted into a unidirectional relationship.
- Avoid lazy loading (it can further complicate the model) - if you keep your aggregates small, you are unlikely to need lazy loading.
- Aggregate roots should keep a reference to the ID of another aggregate root and not a reference to the object itself:
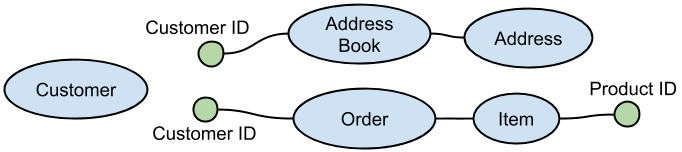
- Nothing outside an aggregate’s boundary may hold a reference to anything inside (nothing outside an aggregate should hold a reference to its inner members).
- Inner aggregate's objects can hold a reference to another aggregate (root).
- An outside aggregate can hold a transient copy of an inner object of another aggregate.
One aggregate per transaction is the default approach. But you should collaborate with the business, assess the technical complexity of each use case, and consciously ignore the guideline if there is a worthwhile advantage, such as a better user experience.
- Smaller aggregates make a system faster and more reliable.
Each aggregate has a matching repository that abstracts the underlying database and that will only allow aggregates to be persisted and hydrated (tip: ActiveJDBC in Java).
- Aggregate is never stored in an inconsistent state.
- Reporting or querying can be performed directly at the database level without the need to hydrate domain objects.
Aggregates should not be influenced by your data model. Associations between domain objects are not the same as database table relationships.
- Aggregate represents a concept in your domain and is not a container for items (eg. Why would you need to load all the items to add another?).
Instead of creating large aggregates to satisfy UIs, it’s common practice to map from multiple aggregates onto a single view model that contains all the data a page needs. This will usually be in the form of an application service making multiple repository calls to load aggregates, and then mapping information from the aggregates onto the view model.
- Aggregates should not be designed around UIs.
The repository is the mechanism that you should use to retrieve and persist aggregates.
- Because an aggregate is treated as an atomic unit, you should not be able to persist changes to an aggregate without persisting the entire aggregate.
- Transactions and other technical details should be handled in the application service layer.
- Repository is not an object. It is a procedural boundary and an explicit contract.
- You should create your domain objects without thinking about persistence requirements; that is the job of the repository.
The repository is the contract between the domain model and the persistence store. It should be written only in terms of the domain and without a thought to the underlying persistence framework. Define intent and make it explicit; do not treat the repository contract like object-oriented (OO) code.
In CRUD (create-read-update-delete), a factory represents the "C" and a repository the "RUD". Because Factories and Repositories are related, they are often combined containing all the create, read, update and delete functionality for a specific object.
DAO is the contract between relational database and the application. It encapsulates the details of database CRUD operations from the web application. On the other hand, a Repository is a separate abstraction that interacts with the DAOs and provides business interfaces to the domain model.
Repositories speak the Ubiquitous Language of the domain, work with all necessary DAOs and provide data access services to the domain model in a language the domain understands.
DAO methods are fine-grained and closer to the database while the Repository methods are more coarse-grained and closer to the domain. Also one Repository class may have multiple DAO's injected.
- Aim for lower cardinality by adding constraints to collections:
class ContractRepo {
public Contract getBy(int id, Date fromDate) { // ...
} }
ORMs map to the data model and make using it easier. They have little to do with domain models. The role of the repository is to keep the two models separate and not to let them blur into one. An ORM is not a repository, but a repository can use it to persist the state of domain objects.
- With document stores the domain model can be serialized without compromise.
Trying to apply a generalizing strategy to all repositories is a bad idea.
- Define your repositories based on their individual needs, and be explicit when naming query methods.
- When it comes to implementation, there is a place for the generic repository:
package infrastructure.persistence;
public class CustomerRepositoryImpl implements CustomerRepository {
private Repository<Customer, Long> repository; // general repo used here
public List<Customer> findAllActive() {
return repository.findByActive(true);
}
}
- Don’t support ad-hoc queries.
- Lazy loading is design smell.
- Don’t use repositories for reporting needs (It is better to use a framework to directly query a read store).
If the creation of an entity or a value object is sufficiently complex, you should delegate the construction to a factory.
Static factory method - for wrapping the complexities of object construction behind a simpler, more expressive interface.
Use factories to reconstitute a domain object from a persistence model, or you can use them to create new domain objects, encapsulating complex creation logic.
Domain services encapsulate domain logic and concepts that are not naturally modeled as value objects or entities.
- No identity or state.
- Orchestrate business logic using entities and value objects.
Domain services represent concepts that exist within the problem domain, their interface lives in the domain model.
Application services, in opposite, do not represent domain concepts, and they don’t contain business rules.
- Rather than cluttering domain logic with these technical details, you can perform this type of validation in application services.
- An application service’s job is to handle errors and translate them into suitable representations for external parties.
Business validation is going to happen in the domain model, after the anticorruption layer validates the inputs.
- A use-case should care about the domain logic and we shouldn't pollute it with input validation.
- Not a pure function, needs additional data.
Input validation is a syntantical validation, while a business rule is a semantical validation in the context of a use-case.
- We can transform the input model of the web adapter into the input model of the use-cases. Anything that prevents us from doing this transformation is a validation error.
- A pure function.
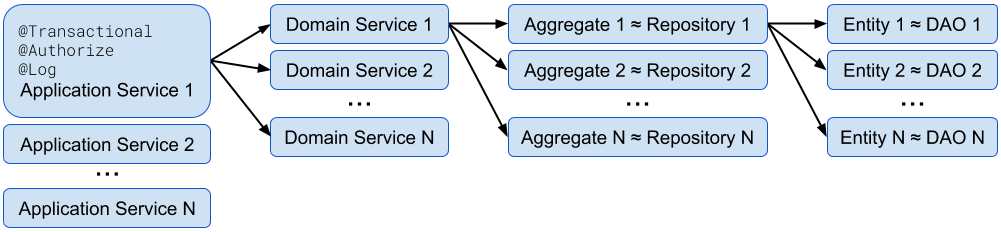
Application services live in the service layer and deal will pulling together infrastructural concerns, like transactions, to carry out full business use cases.
Application services coordinate with the domain to carry out full business use cases.
Application services deal with infrastructural concerns: managing transactions, sending e-mails, and similar technical tasks.
- Validations
- Transactions
- Error handling
- Logging, metrics, monitoring
- Security
- Communication
- Frameworks integration
// application service
public class InsurancePremium {
private PolicyRepository policyRepository;
// domain service
private PremiumCalculator calculator;
public InsurancePremium(PolicyRepository policyRepo, PremiumCalculator calculator) {
this.calculator = calculator;
this.policyRepository = policyRepo; }
public Quote getQuote(int policyId) {
Policy policy = policyRepository.get(policyId);
return calculator.calculateQuote(policy); /* pass entity into domain service */ }
}
Suport logging is intended for support staff and system administrators; it's part of the application's observable behavior. Diagnostic logging helps developers understand what's going on inside the application: it's an implementation detail.
- Don't test diagnostic logging. Unlike support logging, you can do diagnostic logging directly in the domain model.
- Use diagnostic logging sporadically. Excessive diagnostic logging clutters the code and damages the logs' signal-to-noise ratio. Ideally, you should only use diagnostic logging for unhandled exceptions.
Support logging is a business requirement and should be reflected explicitly in the code base.
- Introduce a special
DomainLoggerclass for all support logging needed for the business. - Treat support logging as any other functionality that works with an out-of-process dependency.
- Use domain events to track changes in the domain model; convert those domain events into calls to
DomainLoggerin controllers.
Domain events signify something that has happened in the problem domain that the business cares about.
You can use events to record changes to a model or as a form of communication across aggregates.
The data included in domain events is not intended to describe the aggregates' state. Instead, it describes a business event that happened during its lifecycle. [a]
Internal events are internal to a domain model–they are not shared between bounded contexts.
- Because internal events are limited in scope to a single bounded context, it is okay to put domain objects on them.
External events tend to be flat in structure, exposing just a few properties.
- External events need to be versioned to avoid breaking changes.

Before implementing eventual consistency, you should have a business agreement.
Sending commands from a service to another service violates autonomy of a service business capability.
- Decouple the publishing and handling of events, so that side effects are isolated.
- Implemented by storing a collection of events on the aggregate root and publishing them once the aggregate root has completed its task.
class OrderForDelivery
private List<Event> recordedEvents; // accessible via a getter
public void confirmReceipt(int receiptId) {
// ... some business logic
recordedEvents.add(new ReceiptConfirmed(receiptId));
} }
The majority of web applications see a disparity between queries and commands. CQRS splits these two and enables the sides to be optimized without compromise.
- Not meant for the whole system, just for a service.
- It's about collaborative domains (lots of writers).
- The problem is hight contention on a single record.
- Almost behind every "if" statement on an entity property one can find some kind of collaboration.
- CQRS comes hand in hand with business changes (like negative inventory).
- CQRS is not a top-level architecture.
- CQRS is an implementation of the Single Responsibility Principle (SRP) applied at the domain model layer.
- CQRS is useful for solving the complexity that arises when a presentational model is not in alignment with a transactional model.
- CQRS states that the two contexts should be handled separately for better effectiveness.
- CQRS uses a different data store for querying.
- CQRS does not require you to be eventually consistent.
- Event Sourcing is an effective method to build both the read and the write models; however, no prerequisite.
A DSL is a programming language that is specific to the domain.
You can model anything and everything with a general-purpose programming language. With a DSL, you can model only one specific domain, but in a more expressive way.
The problem domain and the solution domain need to share a common vocabulary for ease of communication. With this vocabulary, you can trace an artifact of the problem domain to its appropriate representation in the solution domain.
- Eric Evans: Domain-Driven Design
- Scott Millett, Nick Tune: Patterns, Principles, and Practices of Domain-Driven Design
- Vaughn Vernon: Effective Aggregate Design
- Debasish Ghosh: DSLs in Action
- Vlad Khononov: Learning Domain-Driven Design [a]
- https://www.infoq.com/articles/ddd-in-practice/
- https://lostechies.com/jimmybogard/2014/05/13/a-better-domain-events-pattern
- https://blog.jayway.com/2013/03/08/aggregates-event-sourcing-distilled
- https://blog.jayway.com/2013/06/20/dont-publish-domain-events-return-them
- http://debasishg.blogspot.de/2014/04/functional-patterns-in-domain-modeling.html
- Spring repositories made OOP
- Domain services vs Application services
- Always-Valid Domain Model
- Enterprise DDD with JPA
- The Entity Service Antipattern
- Evolving Away From Entities
- Domain Primitives
- Value chain analysis
- Layered service models are bad
- From CRUD to domain-driven fluency
- What are Aggregates in DDD
- How To Define Bounded Contexts
- Bounded Contexts are NOT Microservices
- Splitting a Domain Across Multiple Bounded Contexts
- Domain, Subdomain, Bounded Context, Problem/Solution Space in DDD
- Core Domain Patterns
- https://github.com/ddd-crew
