CI & CD
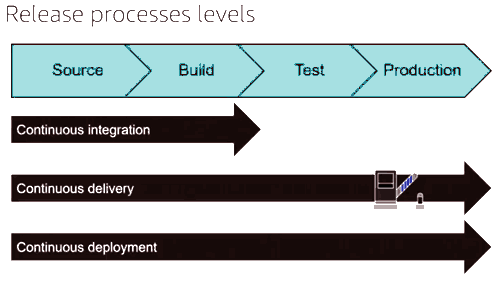
-
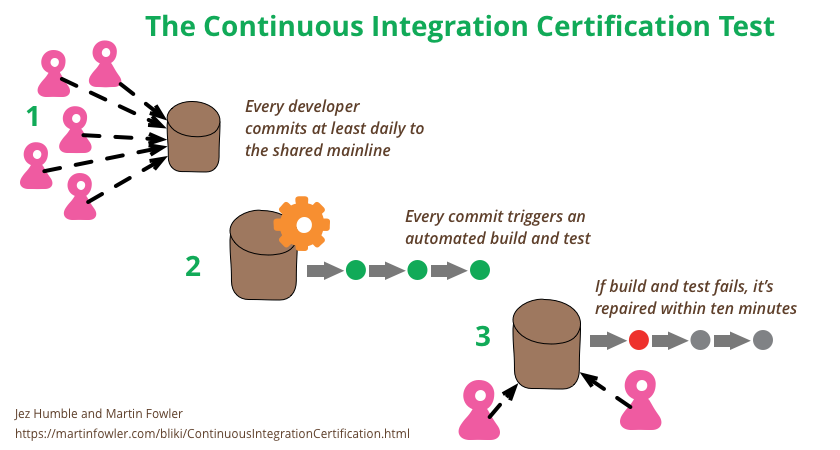
Always commit to trunk, and do it at least once a day.
-
The goal of CI is that the software is in a working state all the time.
-
CI mainly focuses on development teams.
-
CI is a practice, not a tool.
-
CI server should take no more than a few minutes. We think that ten minutes is about the limit, five minutes is better, and about ninety seconds is ideal.
-
Group your acceptance tests into functional areas.
-
Don’t check in on a broken build.
-
Always run all commit tests locally before committing.
-
Wait for commit tests to pass before moving on.
-
Never go home on a broken build.
-
Always be prepared to revert to the previous revision: If we can’t fix the problem quickly (10 minutes), for whatever reason, we should revert to the previous change-set.
-
Take responsibility for all breakages That result from your changes.
-
Trigger a new build whenever there is any change to upstream dependencies. This is the right thing to do, but it is not the norm in many teams—rather, they tend to only update their dependencies once their codebase is stable, perhaps at integration time, or when development has reached some other milestone. This behavior emphasizes stability, but at the cost of potential risk of spending a great deal of time integrating.
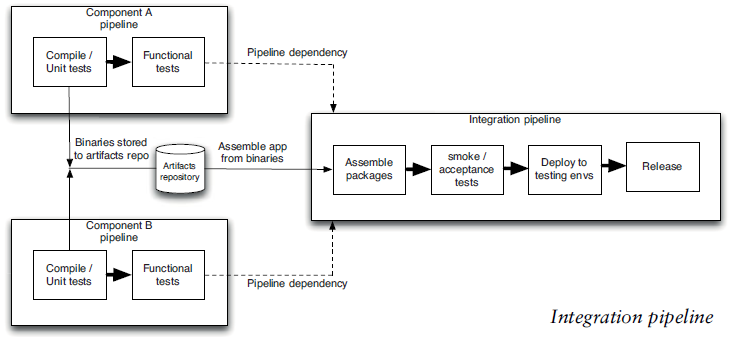
Deployment pipeline - automated implementation (manifestation) of the applications's build, deploy, test, and release process for getting software from version control into the hands of your users.
- Every change made to an application's configuration, source code, environment, or data, triggers the creation of a new instance of the pipeline (every change is a release candidate).
- If the release candidate passes all the tests, i can be released (on a button click).
- Deployment should tend towards being fully automated.
- If any part of the pipeline fails, stop the line.
- All aspects of each of your testing, staging, and production environments, specifically the configuration of any third-party elements of your system, should be applied from version control through an automated process.
- A working software application can be usefully decomposed into four components: executable code, configuration, host environment, and data.
- Feedback must be received as soon as possible.
- When something needs doing, it is the responsibility of the whole team to stop what they are doing and decide on a course of action.
- The earlier you catch defects, the cheaper they are to fix.
- If testing is left to the end, it will be too late.
- A new instance of your deployment pipeline is created upon every check-in and, if the first stage passes, results in the creation of a release candidate.
- Everybody on the delivery team is responsible for the quality of the application all the time.
- Feature is only done when it is delivering value to users.
- Prevented from releasing into production builds that are not thoroughly tested and found to be fit for their intended purpose.
- Releases are automated, they are rapid, repeatable, and reliable.
- Only build your binaries once, during the commit stage of the build. Every time you compile the code, you run the risk of introducing some difference.
- The binaries that get deployed into production should be exactly the same as those that went through the acceptance test process.
- Deploy the same way to every environment to ensure that the build and deployment process is tested effectively.
- Keep the settings that are unique for each environment separate.
- It should be possible to consult one single source (a version control repository, a directory service, or a database) to find configuration settings for all your applications in all of your environments.
- Always roll back either by keeping an old version of the application deployed or by completely redeploying a previous known-good version.
- It may make sense to have a minipipeline for each component, and then a pipeline that assembles all the components and puts the entire application through acceptance tests, nonfunctional tests, and then deployment to testing, staging, and production environments.
- The whole pipeline does not need to be implemented at once. It should be implemented incrementally.
- Deployment pipeline is a living system. As you work continuously to improve your delivery process, you should continue to take care of your deployment pipeline.
- Ensure the deployment process is idempotent.
- Use a build master for very large teams. The build master should never be a permanent role.
- Focusing too early and too heavily on optimizing the capacity of the application is inefficient, expensive, and rarely delivers a high-performance system.
- Be able to roll back a deployment in case it goes wrong. Practice your rollback plan.
- Ensure that the state of your production system, including databases and state held on the filesystem, is backed up before doing a release.
- Emergency Fixes: Do not, under any circumstances, subvert your process.
- If the upgrade process fails, the application should automatically revert to the previous version and report the failure to the development team.
- The application should be able to upgrade from any version to any other version.
- Test the upgrade process as part of your deployment pipeline.
Zero-Downtime Releases (hot deployments) - Decoupling the various parts of the release process so they can happen independently as far as possible.
Blue-Green Deployments - Two identical versions of your production environment.
Canary Releasing - rolling out a new version of an application to a subset of the production servers to get fast feedback.
Configuration Management (synonym for version control) - process by which all artifacts relevant to your project, and the relationships between them, are stored, retrieved, uniquely identified, and modified.
- If different members of the team are working on separate branches or streams, then by definition they’re not continuously integrating.
Branch by Abstraction (no branching, still working on mainline) - an alternative to branching when you need to make a large-scale change to an application. Instead of branching, an abstraction layer is created over the piece to be changed. A new implementation is then created in parallel with the existing implementation, and then when it is complete, the original implementation and (optionally) the abstraction layer are removed.
-
Shipping semicompleted functionality along with the rest of your application is a good practice because it means you’re always integrating and testing the entire system as it exists at any time.
-
If other teams are working in the meantime, the merge at the end can be hard—and the bigger the change, the harder it will be. The bigger the apparent reason to branch, the more you shouldn’t branch.
-
Three good reasons to branch your code: 1. for releasing a new version, 2. spike out, 3. short-lived branch to make a large change (if not possible with other methods).
-
The desire to achieve flexibility may lead to the common antipattern of “ultimate configurability” which is, all too frequently, stated as a requirement for software projects. It is at best unhelpful, and at worst, this one requirement can kill a project. It frequently leads to analysis paralysis, in which the problem seems so big and so intractable that the team spends all of their time thinking about how to solve it and none of their time actually solving anything. The system becomes so complex to configure that many of the benefits of its flexibility are lost.
-
Configurable software is not always the cheaper solution it appears to be. It’s almost always better to focus on delivering the high-value functionality with little configuration and then add configuration options later when necessary.
-
Passwords and other sensitive information should not be checked in to version control at all.
-
It should always be cheaper to create a new environment than to repair an old one.
-
Production environment should be completely locked down.
-
Manage your own artifact repository (Artifactory and Nexus) - this helps ensure that builds are repeatable and prevents dependency hell by controlling which versions of each library are available to projects within your organization.