Fix org.scala-lang: * inconsistent versions #234
Conversation
|
Can one of the admins verify this patch? |
| </dependency> | ||
| <dependency> | ||
| <groupId>org.scala-lang</groupId> | ||
| <artifactId>scala-actors</artifactId> |
There was a problem hiding this comment.
Why is this dependency needed?
There was a problem hiding this comment.
scalatest_2.10 1.9.1 depends on scala-actors 2.10.0
It should be like this?
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-actors</artifactId>
<version>${scala.version}</version>
<scope>test</scope>
</dependency>
There was a problem hiding this comment.
If it's just necessary from the scalatest, then why doesn't it get pulled in when we depenend on scalatest in the core pom?
There was a problem hiding this comment.
I don't think that it is necessary to declare this explicit dependency. And if scalatest 1.9.1 is making this necessary, then an arguably better fix is to bump scalatest to 1.9.2, which has cleaned up transitive dependencies that do not include scala-actors. At some point we should also make the shift to scalatest 2.x.
There was a problem hiding this comment.
@witgo what happens if we just remove it? Does it get pulled in correctly or are there errors?
There was a problem hiding this comment.
@witgo I'm also confused because we didn't change anything related to scalatest in the earlier patch for binary compatbility...
There was a problem hiding this comment.
If you remove it, will cause such a result: mvn dependency:tree
[INFO] +- org.scalatest:scalatest_2.10:jar:1.9.1:test
[INFO] | +- org.scala-lang:scala-actors:jar:2.10.0:test
[INFO] | \- org.scala-lang:scala-reflect:jar:2.10.3:test
org.scala-lang:scala-actors and other org.scala-lang: * inconsistent versions
|
I am seeing this too and investigating. I don't believe this is related to tests, right? There are no tests in I think the simple issue is that Let me dig in and see if I can suggest a change along those lines. |
|
@srowen I agree with your assessment. note that this fix does add the relevant deps to the tools project. I'm just confused why it also touches scala test stuff. |
This is just a slight variation on #234 and alternative suggestion for SPARK-1325. `scala-actors` is not necessary. `SparkBuild.scala` should be updated to reflect the direct dependency on `scala-reflect` and `scala-compiler`. And the `repl` build, which has the same dependencies, should also be consistent between Maven / SBT. Author: Sean Owen <[email protected]> Author: witgo <[email protected]> Closes #240 from srowen/SPARK-1325 and squashes the following commits: 25bd7db [Sean Owen] Add necessary dependencies scala-reflect and scala-compiler to tools. Update repl dependencies, which are similar, to be consistent between Maven / SBT in this regard too.
|
@pwendell , @srowen @markhamstra <dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-actors</artifactId>
<version>${scala.version}</version>
<scope>test</scope>
</dependency> |
|
Can one of the admins verify this patch? |
|
Can one of the admins verify this patch? |
1. Better error messages when required arguments are missing. 2. Support for unit testing cases where presented arguments are invalid. 3. Bug fix: Only use environment varaibles when they are set (otherwise will cause NPE). 4. A verbose mode to aid debugging. 5. Visibility of several variables is set to private. 6. Deprecation warning for existing scripts. Author: Patrick Wendell <[email protected]> Closes apache#271 from pwendell/spark-submit and squashes the following commits: 9146def [Patrick Wendell] SPARK-1352: Improve robustness of spark-submit script
Before we were materializing everything in memory. This also uses the projection interface so will be easier to plug in code gen (its ported from that branch). @rxin @liancheng Author: Michael Armbrust <[email protected]> Closes apache#250 from marmbrus/hashJoin and squashes the following commits: 1ad873e [Michael Armbrust] Change hasNext logic back to the correct version. 8e6f2a2 [Michael Armbrust] Review comments. 1e9fb63 [Michael Armbrust] style bc0cb84 [Michael Armbrust] Rewrite join implementation to allow streaming of one relation.
This test needs to be fixed. It currently depends on Thread.sleep() having exact-timing semantics, which is not a valid assumption. Author: Patrick Wendell <[email protected]> Closes apache#277 from pwendell/rate-limited-stream and squashes the following commits: 6c0ff81 [Patrick Wendell] SPARK-1365: Fix RateLimitedOutputStream test
Author: Sandy Ryza <[email protected]> Closes apache#279 from sryza/sandy-spark-1376 and squashes the following commits: d8aebfa [Sandy Ryza] SPARK-1376. In the yarn-cluster submitter, rename "args" option to "arg"
Previous version was 7.6.8v20121106. The only difference between Jetty 7 and Jetty 8 is that the former uses Servlet API 2.5, while the latter uses Servlet API 3.0. Author: Andrew Or <[email protected]> Closes apache#280 from andrewor14/jetty-upgrade and squashes the following commits: dd57104 [Andrew Or] Merge github.com:apache/spark into jetty-upgrade e75fa85 [Andrew Or] Upgrade Jetty to 8.1.14v20131031
If a previously persisted RDD is re-used, its information disappears from the Storage page. This is because the tasks associated with re-using the RDD do not report the RDD's blocks as updated (which is correct). On stage submit, however, we overwrite any existing information regarding that RDD with a fresh one, whether or not the information for the RDD already exists. Author: Andrew Or <[email protected]> Closes apache#281 from andrewor14/ui-storage-fix and squashes the following commits: 408585a [Andrew Or] Fix storage UI bug
…text. This doesn't yet support different databases in Hive (though you can probably workaround this by calling `USE <dbname>`). However, given the time constraints for 1.0 I think its probably worth including this now and extending the functionality in the next release. Author: Michael Armbrust <[email protected]> Closes apache#282 from marmbrus/cacheTables and squashes the following commits: 83785db [Michael Armbrust] Support for caching and uncaching tables in a SQLContext.
Just a Scala version increment Author: Mark Hamstra <[email protected]> Closes apache#259 from markhamstra/scala-2.10.4 and squashes the following commits: fbec547 [Mark Hamstra] [SPARK-1342] Bumped Scala version to 2.10.4
…HONOPTS from call see comments on Pull Request apache#38 (i couldn't figure out how to modify an existing pull request, so I'm hoping I can withdraw that one and replace it with this one.) Author: Diana Carroll <[email protected]> Closes apache#227 from dianacarroll/spark-1134 and squashes the following commits: ffe47f2 [Diana Carroll] [spark-1134] remove ipythonopts from ipython command b673bf7 [Diana Carroll] Merge branch 'master' of github.com:apache/spark 0309cf9 [Diana Carroll] SPARK-1134 bug with ipython prevents non-interactive use with spark; only call ipython if no command line arguments were supplied
…ove IPYTHONOPTS from call" This reverts commit afb5ea6.
Joint work with @hirakendu, @etrain, @atalwalkar and @harsha2010. Key features: + Supports binary classification and regression + Supports gini, entropy and variance for information gain calculation + Supports both continuous and categorical features The algorithm has gone through several development iterations over the last few months leading to a highly optimized implementation. Optimizations include: 1. Level-wise training to reduce passes over the entire dataset. 2. Bin-wise split calculation to reduce computation overhead. 3. Aggregation over partitions before combining to reduce communication overhead. Author: Manish Amde <[email protected]> Author: manishamde <[email protected]> Author: Xiangrui Meng <[email protected]> Closes apache#79 from manishamde/tree and squashes the following commits: 1e8c704 [Manish Amde] remove numBins field in the Strategy class 7d54b4f [manishamde] Merge pull request apache#4 from mengxr/dtree f536ae9 [Xiangrui Meng] another pass on code style e1dd86f [Manish Amde] implementing code style suggestions 62dc723 [Manish Amde] updating javadoc and converting helper methods to package private to allow unit testing 201702f [Manish Amde] making some more methods private f963ef5 [Manish Amde] making methods private c487e6a [manishamde] Merge pull request #1 from mengxr/dtree 24500c5 [Xiangrui Meng] minor style updates 4576b64 [Manish Amde] documentation and for to while loop conversion ff363a7 [Manish Amde] binary search for bins and while loop for categorical feature bins 632818f [Manish Amde] removing threshold for classification predict method 2116360 [Manish Amde] removing dummy bin calculation for categorical variables 6068356 [Manish Amde] ensuring num bins is always greater than max number of categories 62c2562 [Manish Amde] fixing comment indentation ad1fc21 [Manish Amde] incorporated mengxr's code style suggestions d1ef4f6 [Manish Amde] more documentation 794ff4d [Manish Amde] minor improvements to docs and style eb8fcbe [Manish Amde] minor code style updates cd2c2b4 [Manish Amde] fixing code style based on feedback 63e786b [Manish Amde] added multiple train methods for java compatability d3023b3 [Manish Amde] adding more docs for nested methods 84f85d6 [Manish Amde] code documentation 9372779 [Manish Amde] code style: max line lenght <= 100 dd0c0d7 [Manish Amde] minor: some docs 0dd7659 [manishamde] basic doc 5841c28 [Manish Amde] unit tests for categorical features f067d68 [Manish Amde] minor cleanup c0e522b [Manish Amde] updated predict and split threshold logic b09dc98 [Manish Amde] minor refactoring 6b7de78 [Manish Amde] minor refactoring and tests d504eb1 [Manish Amde] more tests for categorical features dbb7ac1 [Manish Amde] categorical feature support 6df35b9 [Manish Amde] regression predict logic 53108ed [Manish Amde] fixing index for highest bin e23c2e5 [Manish Amde] added regression support c8f6d60 [Manish Amde] adding enum for feature type b0e3e76 [Manish Amde] adding enum for feature type 154aa77 [Manish Amde] enums for configurations 733d6dd [Manish Amde] fixed tests 02c595c [Manish Amde] added command line parsing 98ec8d5 [Manish Amde] tree building and prediction logic b0eb866 [Manish Amde] added logic to handle leaf nodes 80e8c66 [Manish Amde] working version of multi-level split calculation 4798aae [Manish Amde] added gain stats class dad0afc [Manish Amde] decison stump functionality working 03f534c [Manish Amde] some more tests 0012a77 [Manish Amde] basic stump working 8bca1e2 [Manish Amde] additional code for creating intermediate RDD 92cedce [Manish Amde] basic building blocks for intermediate RDD calculation. untested. cd53eae [Manish Amde] skeletal framework
@rxin mentioned this might cause issues on windows machines. Author: Michael Armbrust <[email protected]> Closes apache#297 from marmbrus/noStars and squashes the following commits: 263122a [Michael Armbrust] Remove * from test case golden filename.
This data structure was misused and, as a result, later renamed to an incorrect name. This data structure seems to have gotten into this tangled state as a result of @henrydavidge using the stageID instead of the job Id to index into it and later @andrewor14 renaming the data structure to reflect this misunderstanding. This patch renames it and removes an incorrect indexing into it. The incorrect indexing into it meant that the code added by @henrydavidge to warn when a task size is too large (added here apache@5757993) was not always executed; this commit fixes that. Author: Kay Ousterhout <[email protected]> Closes apache#301 from kayousterhout/fixCancellation and squashes the following commits: bd3d3a4 [Kay Ousterhout] Renamed stageIdToActiveJob to jobIdToActiveJob.
`BlockId.scala` offers a way to reconstruct a BlockId from a string through regex matching. `util/JsonProtocol.scala` duplicates this functionality by explicitly matching on the BlockId type. With this PR, the de/serialization of BlockIds will go through the first (older) code path. (Most of the line changes in this PR involve changing `==` to `===` in `JsonProtocolSuite.scala`) Author: Andrew Or <[email protected]> Closes apache#289 from andrewor14/blockid-json and squashes the following commits: 409d226 [Andrew Or] Simplify JSON de/serialization for BlockId
This avoids a silent data corruption issue (https://spark-project.atlassian.net/browse/SPARK-1188) and has no performance impact by my measurements. It also simplifies the code. As far as I can tell the object re-use was nothing but premature optimization. I did actual benchmarks for all the included changes, and there is no performance difference. I am not sure where to put the benchmarks. Does Spark not have a benchmark suite? This is an example benchmark I did: test("benchmark") { val builder = new EdgePartitionBuilder[Int] for (i <- (1 to 10000000)) { builder.add(i.toLong, i.toLong, i) } val p = builder.toEdgePartition p.map(_.attr + 1).iterator.toList } It ran for 10 seconds both before and after this change. Author: Daniel Darabos <[email protected]> Closes apache#276 from darabos/spark-1188 and squashes the following commits: 574302b [Daniel Darabos] Restore "manual" copying in EdgePartition.map(Iterator). Add comment to discourage novices like myself from trying to simplify the code. 4117a64 [Daniel Darabos] Revert EdgePartitionSuite. 4955697 [Daniel Darabos] Create a copy of the Edge objects in EdgeRDD.compute(). This avoids exposing the object re-use, while still enables the more efficient behavior for internal code. 4ec77f8 [Daniel Darabos] Add comments about object re-use to the affected functions. 2da5e87 [Daniel Darabos] Restore object re-use in EdgePartition. 0182f2b [Daniel Darabos] Do not re-use objects in the EdgePartition/EdgeTriplet iterators. This avoids a silent data corruption issue (SPARK-1188) and has no performance impact in my measurements. It also simplifies the code. c55f52f [Daniel Darabos] Tests that reproduce the problems from SPARK-1188.
…r storage JIRA issue: [SPARK-1373](https://issues.apache.org/jira/browse/SPARK-1373) (Although tagged as WIP, this PR is structurally complete. The only things left unimplemented are 3 more compression algorithms: `BooleanBitSet`, `IntDelta` and `LongDelta`, which are trivial to add later in this or another separate PR.) This PR contains compression support for Spark SQL in-memory columnar storage. Main interfaces include: * `CompressionScheme` Each `CompressionScheme` represents a concrete compression algorithm, which basically consists of an `Encoder` for compression and a `Decoder` for decompression. Algorithms implemented include: * `RunLengthEncoding` * `DictionaryEncoding` Algorithms to be implemented include: * `BooleanBitSet` * `IntDelta` * `LongDelta` * `CompressibleColumnBuilder` A stackable `ColumnBuilder` trait used to build byte buffers for compressible columns. A best `CompressionScheme` that exhibits lowest compression ratio is chosen for each column according to statistical information gathered while elements are appended into the `ColumnBuilder`. However, if no `CompressionScheme` can achieve a compression ratio better than 80%, no compression will be done for this column to save CPU time. Memory layout of the final byte buffer is showed below: ``` .--------------------------- Column type ID (4 bytes) | .----------------------- Null count N (4 bytes) | | .------------------- Null positions (4 x N bytes, empty if null count is zero) | | | .------------- Compression scheme ID (4 bytes) | | | | .--------- Compressed non-null elements V V V V V +---+---+-----+---+---------+ | | | ... | | ... ... | +---+---+-----+---+---------+ \-----------/ \-----------/ header body ``` * `CompressibleColumnAccessor` A stackable `ColumnAccessor` trait used to iterate (possibly) compressed data column. * `ColumnStats` Used to collect statistical information while loading data into in-memory columnar table. Optimizations like partition pruning rely on this information. Strictly speaking, `ColumnStats` related code is not part of the compression support. It's contained in this PR to ensure and validate the row-based API design (which is used to avoid boxing/unboxing cost whenever possible). A major refactoring change since PR apache#205 is: * Refactored all getter/setter methods for primitive types in various places into `ColumnType` classes to remove duplicated code. Author: Cheng Lian <[email protected]> Closes apache#285 from liancheng/memColumnarCompression and squashes the following commits: ed71bbd [Cheng Lian] Addressed all PR comments by @marmbrus d3a4fa9 [Cheng Lian] Removed Ordering[T] in ColumnStats for better performance 5034453 [Cheng Lian] Bug fix, more tests, and more refactoring c298b76 [Cheng Lian] Test suites refactored 2780d6a [Cheng Lian] [WIP] in-memory columnar compression support 211331c [Cheng Lian] WIP: in-memory columnar compression support 85cc59b [Cheng Lian] Refactored ColumnAccessors & ColumnBuilders to remove duplicate code
Updated documentation about the YARN v2.2 build process (cherry picked from commit 241336a) Signed-off-by: Patrick Wendell <[email protected]>
This is just a slight variation on apache#234 and alternative suggestion for SPARK-1325. `scala-actors` is not necessary. `SparkBuild.scala` should be updated to reflect the direct dependency on `scala-reflect` and `scala-compiler`. And the `repl` build, which has the same dependencies, should also be consistent between Maven / SBT. Author: Sean Owen <[email protected]> Author: witgo <[email protected]> Closes apache#240 from srowen/SPARK-1325 and squashes the following commits: 25bd7db [Sean Owen] Add necessary dependencies scala-reflect and scala-compiler to tools. Update repl dependencies, which are similar, to be consistent between Maven / SBT in this regard too.
[SPARKR-163] Support sampleByKey() Conflicts: pkg/R/pairRDD.R
This PR pulls in recent changes in SparkR-pkg, including cartesian, intersection, sampleByKey, subtract, subtractByKey, except, and some API for StructType and StructField. Author: cafreeman <[email protected]> Author: Davies Liu <[email protected]> Author: Zongheng Yang <[email protected]> Author: Shivaram Venkataraman <[email protected]> Author: Shivaram Venkataraman <[email protected]> Author: Sun Rui <[email protected]> Closes #5436 from davies/R3 and squashes the following commits: c2b09be [Davies Liu] SQLTypes -> schema a5a02f2 [Davies Liu] Merge branch 'master' of github.com:apache/spark into R3 168b7fe [Davies Liu] sort generics b1fe460 [Davies Liu] fix conflict in README.md e74c04e [Davies Liu] fix schema.R 4f5ac09 [Davies Liu] Merge branch 'master' of github.com:apache/spark into R5 41f8184 [Davies Liu] rm man ae78312 [Davies Liu] Merge pull request #237 from sun-rui/SPARKR-154_3 1bdcb63 [Zongheng Yang] Updates to README.md. 5a553e7 [cafreeman] Use object attribute instead of argument 71372d9 [cafreeman] Update docs and examples 8526d2e [cafreeman] Remove `tojson` functions 6ef5f2d [cafreeman] Fix spacing 7741d66 [cafreeman] Rename the SQL DataType function 141efd8 [Shivaram Venkataraman] Merge pull request #245 from hqzizania/upstream 9387402 [Davies Liu] fix style 40199eb [Shivaram Venkataraman] Move except into sorted position 07d0dbc [Sun Rui] [SPARKR-244] Fix test failure after integration of subtract() and subtractByKey() for RDD. 7e8caa3 [Shivaram Venkataraman] Merge pull request #246 from hlin09/fixCombineByKey ed66c81 [cafreeman] Update `subtract` to work with `generics.R` f3ba785 [cafreeman] Fixed duplicate export 275deb4 [cafreeman] Update `NAMESPACE` and tests 1a3b63d [cafreeman] new version of `CreateDF` 836c4bf [cafreeman] Update `createDataFrame` and `toDF` be5d5c1 [cafreeman] refactor schema functions 40338a4 [Zongheng Yang] Merge pull request #244 from sun-rui/SPARKR-154_5 20b97a6 [Zongheng Yang] Merge pull request #234 from hqzizania/assist ba54e34 [Shivaram Venkataraman] Merge pull request #238 from sun-rui/SPARKR-154_4 c9497a3 [Shivaram Venkataraman] Merge pull request #208 from lythesia/master b317aa7 [Zongheng Yang] Merge pull request #243 from hqzizania/master 136a07e [Zongheng Yang] Merge pull request #242 from hqzizania/stats cd66603 [cafreeman] new line at EOF 8b76e81 [Shivaram Venkataraman] Merge pull request #233 from redbaron/fail-early-on-missing-dep 7dd81b7 [cafreeman] Documentation 0e2a94f [cafreeman] Define functions for schema and fields
…ecutionId ## What changes were proposed in this pull request? This is a backport of apache@59dc26e apache#16940 adds a test case which does not stop the spark job. It causes many failures of other test cases. - https://amplab.cs.berkeley.edu/jenkins/view/Spark%20QA%20Test%20(Dashboard)/job/spark-master-test-sbt-hadoop-2.7/2403/consoleFull - https://amplab.cs.berkeley.edu/jenkins/view/Spark%20QA%20Test%20(Dashboard)/job/spark-master-test-maven-hadoop-2.7/2600/consoleFull ``` [info] org.apache.spark.SparkException: Only one SparkContext may be running in this JVM (see SPARK-2243). To ignore this error, set spark.driver.allowMultipleContexts = true. The currently running SparkContext was created at: ``` ## How was this patch tested? Pass the Jenkins test. Author: Dongjoon Hyun <[email protected]> Closes apache#234 from ala/execution-id-fix.
[SPARK-601] Test RPC authentication, allow users to generate a secret client-side
### What changes were proposed in this pull request? snappy-java have release v1.1.7.5, upgrade to latest version. Fixed in v1.1.7.4 - Caching internal buffers for SnappyFramed streams #234 - Fixed the native lib for ppc64le to work with glibc 2.17 (Previously it depended on 2.22) Fixed in v1.1.7.5 - Fixes java.lang.NoClassDefFoundError: org/xerial/snappy/pool/DefaultPoolFactory in 1.1.7.4 xerial/snappy-java@1.1.7.3...1.1.7.5 v 1.1.7.5 release note: xerial/snappy-java@edc4ec2 ### Why are the changes needed? Fix bug ### Does this PR introduce _any_ user-facing change? No ### How was this patch tested? No need Closes #28472 from AngersZhuuuu/spark-31655. Authored-by: angerszhu <[email protected]> Signed-off-by: Dongjoon Hyun <[email protected]>
### What changes were proposed in this pull request? snappy-java have release v1.1.7.5, upgrade to latest version. Fixed in v1.1.7.4 - Caching internal buffers for SnappyFramed streams #234 - Fixed the native lib for ppc64le to work with glibc 2.17 (Previously it depended on 2.22) Fixed in v1.1.7.5 - Fixes java.lang.NoClassDefFoundError: org/xerial/snappy/pool/DefaultPoolFactory in 1.1.7.4 xerial/snappy-java@1.1.7.3...1.1.7.5 v 1.1.7.5 release note: xerial/snappy-java@edc4ec2 ### Why are the changes needed? Fix bug ### Does this PR introduce _any_ user-facing change? No ### How was this patch tested? No need Closes #28509 from AngersZhuuuu/SPARK-31655-3.0. Authored-by: angerszhu <[email protected]> Signed-off-by: Dongjoon Hyun <[email protected]>
### What changes were proposed in this pull request? snappy-java have release v1.1.7.5, upgrade to latest version. Fixed in v1.1.7.4 - Caching internal buffers for SnappyFramed streams #234 - Fixed the native lib for ppc64le to work with glibc 2.17 (Previously it depended on 2.22) Fixed in v1.1.7.5 - Fixes java.lang.NoClassDefFoundError: org/xerial/snappy/pool/DefaultPoolFactory in 1.1.7.4 xerial/snappy-java@1.1.7.3...1.1.7.5 v 1.1.7.5 release note: xerial/snappy-java@edc4ec2 ### Why are the changes needed? Fix bug ### Does this PR introduce _any_ user-facing change? No ### How was this patch tested? No need Closes #28506 from AngersZhuuuu/spark-31655-2.4. Authored-by: angerszhu <[email protected]> Signed-off-by: Dongjoon Hyun <[email protected]>
…gate expressions without aggregate function ### What changes were proposed in this pull request? This PR: - Adds a new expression `GroupingExprRef` that can be used in aggregate expressions of `Aggregate` nodes to refer grouping expressions by index. These expressions capture the data type and nullability of the referred grouping expression. - Adds a new rule `EnforceGroupingReferencesInAggregates` that inserts the references in the beginning of the optimization phase. - Adds a new rule `UpdateGroupingExprRefNullability` to update nullability of `GroupingExprRef` expressions as nullability of referred grouping expression can change during optimization. ### Why are the changes needed? If aggregate expressions (without aggregate functions) in an `Aggregate` node are complex then the `Optimizer` can optimize out grouping expressions from them and so making aggregate expressions invalid. Here is a simple example: ``` SELECT not(t.id IS NULL) , count(*) FROM t GROUP BY t.id IS NULL ``` In this case the `BooleanSimplification` rule does this: ``` === Applying Rule org.apache.spark.sql.catalyst.optimizer.BooleanSimplification === !Aggregate [isnull(id#222)], [NOT isnull(id#222) AS (NOT (id IS NULL))#226, count(1) AS c#224L] Aggregate [isnull(id#222)], [isnotnull(id#222) AS (NOT (id IS NULL))#226, count(1) AS c#224L] +- Project [value#219 AS id#222] +- Project [value#219 AS id#222] +- LocalRelation [value#219] +- LocalRelation [value#219] ``` where `NOT isnull(id#222)` is optimized to `isnotnull(id#222)` and so it no longer refers to any grouping expression. Before this PR: ``` == Optimized Logical Plan == Aggregate [isnull(id#222)], [isnotnull(id#222) AS (NOT (id IS NULL))#234, count(1) AS c#232L] +- Project [value#219 AS id#222] +- LocalRelation [value#219] ``` and running the query throws an error: ``` Couldn't find id#222 in [isnull(id#222)#230,count(1)#226L] java.lang.IllegalStateException: Couldn't find id#222 in [isnull(id#222)#230,count(1)#226L] ``` After this PR: ``` == Optimized Logical Plan == Aggregate [isnull(id#222)], [NOT groupingexprref(0) AS (NOT (id IS NULL))#234, count(1) AS c#232L] +- Project [value#219 AS id#222] +- LocalRelation [value#219] ``` and the query works. ### Does this PR introduce _any_ user-facing change? Yes, the query works. ### How was this patch tested? Added new UT. Closes #31913 from peter-toth/SPARK-34581-keep-grouping-expressions. Authored-by: Peter Toth <[email protected]> Signed-off-by: Wenchen Fan <[email protected]>
…gate expressions without aggregate function ### What changes were proposed in this pull request? This PR adds a new rule `PullOutGroupingExpressions` to pull out complex grouping expressions to a `Project` node under an `Aggregate`. These expressions are then referenced in both grouping expressions and aggregate expressions without aggregate functions to ensure that optimization rules don't change the aggregate expressions to invalid ones that no longer refer to any grouping expressions. ### Why are the changes needed? If aggregate expressions (without aggregate functions) in an `Aggregate` node are complex then the `Optimizer` can optimize out grouping expressions from them and so making aggregate expressions invalid. Here is a simple example: ``` SELECT not(t.id IS NULL) , count(*) FROM t GROUP BY t.id IS NULL ``` In this case the `BooleanSimplification` rule does this: ``` === Applying Rule org.apache.spark.sql.catalyst.optimizer.BooleanSimplification === !Aggregate [isnull(id#222)], [NOT isnull(id#222) AS (NOT (id IS NULL))#226, count(1) AS c#224L] Aggregate [isnull(id#222)], [isnotnull(id#222) AS (NOT (id IS NULL))#226, count(1) AS c#224L] +- Project [value#219 AS id#222] +- Project [value#219 AS id#222] +- LocalRelation [value#219] +- LocalRelation [value#219] ``` where `NOT isnull(id#222)` is optimized to `isnotnull(id#222)` and so it no longer refers to any grouping expression. Before this PR: ``` == Optimized Logical Plan == Aggregate [isnull(id#222)], [isnotnull(id#222) AS (NOT (id IS NULL))#234, count(1) AS c#232L] +- Project [value#219 AS id#222] +- LocalRelation [value#219] ``` and running the query throws an error: ``` Couldn't find id#222 in [isnull(id#222)#230,count(1)#226L] java.lang.IllegalStateException: Couldn't find id#222 in [isnull(id#222)#230,count(1)#226L] ``` After this PR: ``` == Optimized Logical Plan == Aggregate [_groupingexpression#233], [NOT _groupingexpression#233 AS (NOT (id IS NULL))#230, count(1) AS c#228L] +- Project [isnull(value#219) AS _groupingexpression#233] +- LocalRelation [value#219] ``` and the query works. ### Does this PR introduce _any_ user-facing change? Yes, the query works. ### How was this patch tested? Added new UT. Closes #32396 from peter-toth/SPARK-34581-keep-grouping-expressions-2. Authored-by: Peter Toth <[email protected]> Signed-off-by: Wenchen Fan <[email protected]>
* [SPARK-34225][CORE][FOLLOWUP] Replace Hadoop's Path with Utils.resolveURI to make the way to get URI simple ### What changes were proposed in this pull request? This PR proposes to replace Hadoop's `Path` with `Utils.resolveURI` to make the way to get URI simple in `SparkContext`. ### Why are the changes needed? Keep the code simple. ### Does this PR introduce _any_ user-facing change? No. ### How was this patch tested? Existing tests. Closes #32164 from sarutak/followup-SPARK-34225. Authored-by: Kousuke Saruta <[email protected]> Signed-off-by: Dongjoon Hyun <[email protected]> * [SPARK-35070][SQL] TRANSFORM not support alias in inputs ### What changes were proposed in this pull request? Normal function parameters should not support alias, hive not support too 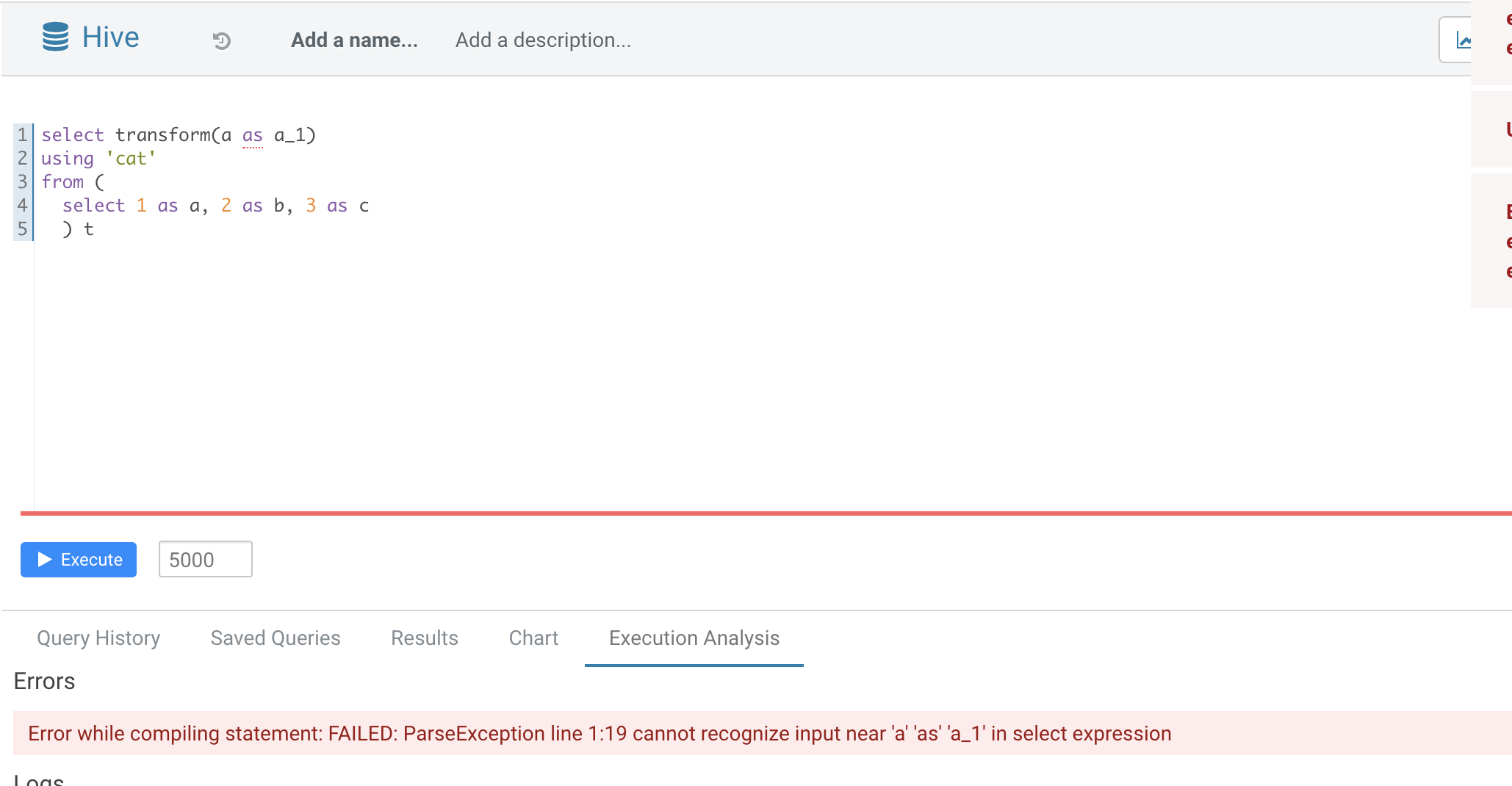 In this pr we forbid use alias in `TRANSFORM`'s inputs ### Why are the changes needed? Fix bug ### Does this PR introduce _any_ user-facing change? No ### How was this patch tested? Added UT Closes #32165 from AngersZhuuuu/SPARK-35070. Authored-by: Angerszhuuuu <[email protected]> Signed-off-by: Wenchen Fan <[email protected]> * [MINOR][CORE] Correct the number of started fetch requests in log ### What changes were proposed in this pull request? When counting the number of started fetch requests, we should exclude the deferred requests. ### Why are the changes needed? Fix the wrong number in the log. ### Does this PR introduce _any_ user-facing change? Yes, users see the correct number of started requests in logs. ### How was this patch tested? Manually tested. Closes #32180 from Ngone51/count-deferred-request. Lead-authored-by: yi.wu <[email protected]> Co-authored-by: wuyi <[email protected]> Signed-off-by: attilapiros <[email protected]> * [SPARK-34995] Port/integrate Koalas remaining codes into PySpark ### What changes were proposed in this pull request? There are some more changes in Koalas such as [databricks/koalas#2141](https://github.com/databricks/koalas/commit/c8f803d6becb3accd767afdb3774c8656d0d0b47), [databricks/koalas#2143](https://github.com/databricks/koalas/commit/913d68868d38ee7158c640aceb837484f417267e) after the main code porting, this PR is to synchronize those changes with the `pyspark.pandas`. ### Why are the changes needed? We should port the whole Koalas codes into PySpark and synchronize them. ### Does this PR introduce _any_ user-facing change? Fixed some incompatible behavior with pandas 1.2.0 and added more to the `to_markdown` docstring. ### How was this patch tested? Manually tested in local. Closes #32154 from itholic/SPARK-34995. Authored-by: itholic <[email protected]> Signed-off-by: HyukjinKwon <[email protected]> * Revert "[SPARK-34995] Port/integrate Koalas remaining codes into PySpark" This reverts commit 9689c44b602781c1d6b31a322162c488ed17a29b. * [SPARK-34843][SQL][FOLLOWUP] Fix a test failure in OracleIntegrationSuite ### What changes were proposed in this pull request? This PR fixes a test failure in `OracleIntegrationSuite`. After SPARK-34843 (#31965), the way to divide partitions is changed and `OracleIntegrationSuites` is affected. ``` [info] - SPARK-22814 support date/timestamp types in partitionColumn *** FAILED *** (230 milliseconds) [info] Set(""D" < '2018-07-11' or "D" is null", ""D" >= '2018-07-11' AND "D" < '2018-07-15'", ""D" >= '2018-07-15'") did not equal Set(""D" < '2018-07-10' or "D" is null", ""D" >= '2018-07-10' AND "D" < '2018-07-14'", ""D" >= '2018-07-14'") (OracleIntegrationSuite.scala:448) [info] Analysis: [info] Set(missingInLeft: ["D" < '2018-07-10' or "D" is null, "D" >= '2018-07-10' AND "D" < '2018-07-14', "D" >= '2018-07-14'], missingInRight: ["D" < '2018-07-11' or "D" is null, "D" >= '2018-07-11' AND "D" < '2018-07-15', "D" >= '2018-07-15']) ``` ### Why are the changes needed? To follow the previous change. ### Does this PR introduce _any_ user-facing change? No. ### How was this patch tested? The modified test. Closes #32186 from sarutak/fix-oracle-date-error. Authored-by: Kousuke Saruta <[email protected]> Signed-off-by: Dongjoon Hyun <[email protected]> * [SPARK-35032][PYTHON] Port Koalas Index unit tests into PySpark ### What changes were proposed in this pull request? Now that we merged the Koalas main code into the PySpark code base (#32036), we should port the Koalas Index unit tests to PySpark. ### Why are the changes needed? Currently, the pandas-on-Spark modules are not tested fully. We should enable the Index unit tests. ### Does this PR introduce _any_ user-facing change? No. ### How was this patch tested? Enable Index unit tests. Closes #32139 from xinrong-databricks/port.indexes_tests. Authored-by: Xinrong Meng <[email protected]> Signed-off-by: HyukjinKwon <[email protected]> * [SPARK-35099][SQL] Convert ANSI interval literals to SQL string in ANSI style ### What changes were proposed in this pull request? Handle `YearMonthIntervalType` and `DayTimeIntervalType` in the `sql()` and `toString()` method of `Literal`, and format the ANSI interval in the ANSI style. ### Why are the changes needed? To improve readability and UX with Spark SQL. For example, a test output before the changes: ``` -- !query select timestamp'2011-11-11 11:11:11' - interval '2' day -- !query schema struct<TIMESTAMP '2011-11-11 11:11:11' - 172800000000:timestamp> -- !query output 2011-11-09 11:11:11 ``` ### Does this PR introduce _any_ user-facing change? Should not since the new intervals haven't been released yet. ### How was this patch tested? By running new tests: ``` $ ./build/sbt "test:testOnly *LiteralExpressionSuite" ``` Closes #32196 from MaxGekk/literal-ansi-interval-sql. Authored-by: Max Gekk <[email protected]> Signed-off-by: Max Gekk <[email protected]> * [SPARK-35083][CORE] Support remote scheduler pool files ### What changes were proposed in this pull request? Use hadoop FileSystem instead of FileInputStream. ### Why are the changes needed? Make `spark.scheduler.allocation.file` suport remote file. When using Spark as a server (e.g. SparkThriftServer), it's hard for user to specify a local path as the scheduler pool. ### Does this PR introduce _any_ user-facing change? Yes, a minor feature. ### How was this patch tested? Pass `core/src/test/scala/org/apache/spark/scheduler/PoolSuite.scala` and manul test After add config `spark.scheduler.allocation.file=hdfs:///tmp/fairscheduler.xml`. We intrudoce the configed pool.  Closes #32184 from ulysses-you/SPARK-35083. Authored-by: ulysses-you <[email protected]> Signed-off-by: Dongjoon Hyun <[email protected]> * [SPARK-35104][SQL] Fix ugly indentation of multiple JSON records in a single split file generated by JacksonGenerator when pretty option is true ### What changes were proposed in this pull request? This issue fixes an issue that indentation of multiple output JSON records in a single split file are broken except for the first record in the split when `pretty` option is `true`. ``` // Run in the Spark Shell. // Set spark.sql.leafNodeDefaultParallelism to 1 for the current master. // Or set spark.default.parallelism for the previous releases. spark.conf.set("spark.sql.leafNodeDefaultParallelism", 1) val df = Seq("a", "b", "c").toDF df.write.option("pretty", "true").json("/path/to/output") # Run in a Shell $ cat /path/to/output/*.json { "value" : "a" } { "value" : "b" } { "value" : "c" } ``` ### Why are the changes needed? It's not pretty even though `pretty` option is true. ### Does this PR introduce _any_ user-facing change? I think "No". Indentation style is changed but JSON format is not changed. ### How was this patch tested? New test. Closes #32203 from sarutak/fix-ugly-indentation. Authored-by: Kousuke Saruta <[email protected]> Signed-off-by: Max Gekk <[email protected]> * [SPARK-34995] Port/integrate Koalas remaining codes into PySpark ### What changes were proposed in this pull request? There are some more changes in Koalas such as [databricks/koalas#2141](https://github.com/databricks/koalas/commit/c8f803d6becb3accd767afdb3774c8656d0d0b47), [databricks/koalas#2143](https://github.com/databricks/koalas/commit/913d68868d38ee7158c640aceb837484f417267e) after the main code porting, this PR is to synchronize those changes with the `pyspark.pandas`. ### Why are the changes needed? We should port the whole Koalas codes into PySpark and synchronize them. ### Does this PR introduce _any_ user-facing change? Fixed some incompatible behavior with pandas 1.2.0 and added more to the `to_markdown` docstring. ### How was this patch tested? Manually tested in local. Closes #32197 from itholic/SPARK-34995-fix. Authored-by: itholic <[email protected]> Signed-off-by: HyukjinKwon <[email protected]> * [MINOR][DOCS] Soften security warning and keep it in cluster management docs only ### What changes were proposed in this pull request? Soften security warning and keep it in cluster management docs only, not in the main doc page, where it's not necessarily relevant. ### Why are the changes needed? The statement is perhaps unnecessarily 'frightening' as the first section in the main docs page. It applies to clusters not local mode, anyhow. ### Does this PR introduce _any_ user-facing change? Just a docs change. ### How was this patch tested? N/A Closes #32206 from srowen/SecurityStatement. Authored-by: Sean Owen <[email protected]> Signed-off-by: Sean Owen <[email protected]> * [SPARK-34787][CORE] Option variable in Spark historyServer log should be displayed as actual value instead of Some(XX) ### What changes were proposed in this pull request? Make the attemptId in the log of historyServer to be more easily to read. ### Why are the changes needed? Option variable in Spark historyServer log should be displayed as actual value instead of Some(XX) ### Does this PR introduce any user-facing change? No ### How was this patch tested? manual test Closes #32189 from kyoty/history-server-print-option-variable. Authored-by: kyoty <[email protected]> Signed-off-by: Dongjoon Hyun <[email protected]> * [SPARK-35101][INFRA] Add GitHub status check in PR instead of a comment ### What changes were proposed in this pull request? TL;DR: now it shows green yellow read status of tests instead of relying on a comment in a PR, **see https://github.com/HyukjinKwon/spark/pull/41 for an example**. This PR proposes the GitHub status checks instead of a comment that link to the build (from forked repository) in PRs. This is how it works: 1. **forked repo**: "Build and test" workflow is triggered when you create a branch to create a PR which uses your resources in GitHub Actions. 1. **main repo**: "Notify test workflow" (previously created a comment) now creates a in-progress status (yellow status) as a GitHub Actions check to your current PR. 1. **main repo**: "Update build status workflow" regularly (every 15 mins) checks open PRs, and updates the status of GitHub Actions checks at PRs according to the status of workflows in the forked repositories (status sync). **NOTE** that creating/updating statuses in the PRs is only allowed from the main repo. That's why the flow is as above. ### Why are the changes needed? The GitHub status shows a green although the tests are running, which is confusing. ### Does this PR introduce _any_ user-facing change? No, dev-only. ### How was this patch tested? Manually tested at: - https://github.com/HyukjinKwon/spark/pull/41 - HyukjinKwon#42 - HyukjinKwon#43 - https://github.com/HyukjinKwon/spark/pull/37 **queued**: <img width="861" alt="Screen Shot 2021-04-16 at 10 56 03 AM" src="https://user-images.githubusercontent.com/6477701/114960831-c9a73080-9ea2-11eb-8442-ddf3f6008a45.png"> **in progress**: <img width="871" alt="Screen Shot 2021-04-16 at 12 14 39 PM" src="https://user-images.githubusercontent.com/6477701/114966359-59ea7300-9ead-11eb-98cb-1e63323980ad.png"> **passed**:  **failure**:  Closes #32193 from HyukjinKwon/update-checks-pr-poc. Lead-authored-by: HyukjinKwon <[email protected]> Co-authored-by: Hyukjin Kwon <[email protected]> Co-authored-by: Yikun Jiang <[email protected]> Signed-off-by: HyukjinKwon <[email protected]> * [MINOR][INFRA] Upgrade Jira client to 2.0.0 ### What changes were proposed in this pull request? SPARK-10498 added the initial Jira client requirement with 1.0.3 five year ago (2016 January). As of today, it causes `dev/merge_spark_pr.py` failure with `Python 3.9.4` due to this old dependency. This PR aims to upgrade it to the latest version, 2.0.0. The latest version is also a little old (2018 July). - https://pypi.org/project/jira/#history ### Why are the changes needed? `Jira==2.0.0` works well with both Python 3.8/3.9 while `Jira==1.0.3` fails with Python 3.9. **BEFORE** ``` $ pyenv global 3.9.4 $ pip freeze | grep jira jira==1.0.3 $ dev/merge_spark_pr.py Traceback (most recent call last): File "/Users/dongjoon/APACHE/spark-merge/dev/merge_spark_pr.py", line 39, in <module> import jira.client File "/Users/dongjoon/.pyenv/versions/3.9.4/lib/python3.9/site-packages/jira/__init__.py", line 5, in <module> from .config import get_jira File "/Users/dongjoon/.pyenv/versions/3.9.4/lib/python3.9/site-packages/jira/config.py", line 17, in <module> from .client import JIRA File "/Users/dongjoon/.pyenv/versions/3.9.4/lib/python3.9/site-packages/jira/client.py", line 165 validate=False, get_server_info=True, async=False, logging=True, max_retries=3): ^ SyntaxError: invalid syntax ``` **AFTER** ``` $ pip install jira==2.0.0 $ dev/merge_spark_pr.py git rev-parse --abbrev-ref HEAD Which pull request would you like to merge? (e.g. 34): ``` ### Does this PR introduce _any_ user-facing change? No. This is a committer-only script. ### How was this patch tested? Manually. Closes #32215 from dongjoon-hyun/jira. Authored-by: Dongjoon Hyun <[email protected]> Signed-off-by: HyukjinKwon <[email protected]> * [SPARK-35116][SQL][TESTS] The generated data fits the precision of DayTimeIntervalType in spark ### What changes were proposed in this pull request? The precision of `java.time.Duration` is nanosecond, but when it is used as `DayTimeIntervalType` in Spark, it is microsecond. At present, the `DayTimeIntervalType` data generated in the implementation of `RandomDataGenerator` is accurate to nanosecond, which will cause the `DayTimeIntervalType` to be converted to long, and then back to `DayTimeIntervalType` to lose the accuracy, which will cause the test to fail. For example: https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/137390/testReport/org.apache.spark.sql.hive.execution/HashAggregationQueryWithControlledFallbackSuite/udaf_with_all_data_types/ ### Why are the changes needed? Improve `RandomDataGenerator` so that the generated data fits the precision of DayTimeIntervalType in spark. ### Does this PR introduce _any_ user-facing change? 'No'. Just change the test class. ### How was this patch tested? Jenkins test. Closes #32212 from beliefer/SPARK-35116. Authored-by: beliefer <[email protected]> Signed-off-by: Max Gekk <[email protected]> * [SPARK-35114][SQL][TESTS] Add checks for ANSI intervals to `LiteralExpressionSuite` ### What changes were proposed in this pull request? In the PR, I propose to add additional checks for ANSI interval types `YearMonthIntervalType` and `DayTimeIntervalType` to `LiteralExpressionSuite`. Also, I replaced some long literal values by `CalendarInterval` to check `CalendarIntervalType` that the tests were supposed to check. ### Why are the changes needed? To improve test coverage and have the same checks for ANSI types as for `CalendarIntervalType`. ### Does this PR introduce _any_ user-facing change? No ### How was this patch tested? By running the modified test suite: ``` $ build/sbt "test:testOnly *LiteralExpressionSuite" ``` Closes #32213 from MaxGekk/interval-literal-tests. Authored-by: Max Gekk <[email protected]> Signed-off-by: Max Gekk <[email protected]> * [SPARK-34716][SQL] Support ANSI SQL intervals by the aggregate function `sum` ### What changes were proposed in this pull request? Extend the `Sum` expression to to support `DayTimeIntervalType` and `YearMonthIntervalType` added by #31614. Note: the expressions can throw the overflow exception independently from the SQL config `spark.sql.ansi.enabled`. In this way, the modified expressions always behave in the ANSI mode for the intervals. ### Why are the changes needed? Extend `org.apache.spark.sql.catalyst.expressions.aggregate.Sum` to support `DayTimeIntervalType` and `YearMonthIntervalType`. ### Does this PR introduce _any_ user-facing change? 'No'. Should not since new types have not been released yet. ### How was this patch tested? Jenkins test Closes #32107 from beliefer/SPARK-34716. Lead-authored-by: gengjiaan <[email protected]> Co-authored-by: beliefer <[email protected]> Co-authored-by: Hyukjin Kwon <[email protected]> Signed-off-by: Max Gekk <[email protected]> * [SPARK-35115][SQL][TESTS] Check ANSI intervals in `MutableProjectionSuite` ### What changes were proposed in this pull request? Add checks for `YearMonthIntervalType` and `DayTimeIntervalType` to `MutableProjectionSuite`. ### Why are the changes needed? To improve test coverage, and the same checks as for `CalendarIntervalType`. ### Does this PR introduce _any_ user-facing change? No ### How was this patch tested? By running the modified test suite: ``` $ build/sbt "test:testOnly *MutableProjectionSuite" ``` Closes #32225 from MaxGekk/test-ansi-intervals-in-MutableProjectionSuite. Authored-by: Max Gekk <[email protected]> Signed-off-by: Takeshi Yamamuro <[email protected]> * [SPARK-35092][UI] the auto-generated rdd's name in the storage tab should be truncated if it is too long ### What changes were proposed in this pull request? the auto-generated rdd's name in the storage tab should be truncated as a single line if it is too long. ### Why are the changes needed? to make the ui shows more friendly. ### Does this PR introduce _any_ user-facing change? No ### How was this patch tested? just a simple modifition in css, manual test works well like below: before modified:  after modified: Tht titile needs just one line:  Closes #32191 from kyoty/storage-rdd-titile-display-improve. Authored-by: kyoty <[email protected]> Signed-off-by: Kousuke Saruta <[email protected]> * [SPARK-35109][SQL] Fix minor exception messages of HashedRelation and HashJoin ### What changes were proposed in this pull request? It seems that we miss classifying one `SparkOutOfMemoryError` in `HashedRelation`. Add the error classification for it. In addition, clean up two errors definition of `HashJoin` as they are not used. ### Why are the changes needed? Better error classification. ### Does this PR introduce _any_ user-facing change? No. ### How was this patch tested? Existing tests. Closes #32211 from c21/error-message. Authored-by: Cheng Su <[email protected]> Signed-off-by: Takeshi Yamamuro <[email protected]> * [SPARK-34581][SQL] Don't optimize out grouping expressions from aggregate expressions without aggregate function ### What changes were proposed in this pull request? This PR: - Adds a new expression `GroupingExprRef` that can be used in aggregate expressions of `Aggregate` nodes to refer grouping expressions by index. These expressions capture the data type and nullability of the referred grouping expression. - Adds a new rule `EnforceGroupingReferencesInAggregates` that inserts the references in the beginning of the optimization phase. - Adds a new rule `UpdateGroupingExprRefNullability` to update nullability of `GroupingExprRef` expressions as nullability of referred grouping expression can change during optimization. ### Why are the changes needed? If aggregate expressions (without aggregate functions) in an `Aggregate` node are complex then the `Optimizer` can optimize out grouping expressions from them and so making aggregate expressions invalid. Here is a simple example: ``` SELECT not(t.id IS NULL) , count(*) FROM t GROUP BY t.id IS NULL ``` In this case the `BooleanSimplification` rule does this: ``` === Applying Rule org.apache.spark.sql.catalyst.optimizer.BooleanSimplification === !Aggregate [isnull(id#222)], [NOT isnull(id#222) AS (NOT (id IS NULL))#226, count(1) AS c#224L] Aggregate [isnull(id#222)], [isnotnull(id#222) AS (NOT (id IS NULL))#226, count(1) AS c#224L] +- Project [value#219 AS id#222] +- Project [value#219 AS id#222] +- LocalRelation [value#219] +- LocalRelation [value#219] ``` where `NOT isnull(id#222)` is optimized to `isnotnull(id#222)` and so it no longer refers to any grouping expression. Before this PR: ``` == Optimized Logical Plan == Aggregate [isnull(id#222)], [isnotnull(id#222) AS (NOT (id IS NULL))#234, count(1) AS c#232L] +- Project [value#219 AS id#222] +- LocalRelation [value#219] ``` and running the query throws an error: ``` Couldn't find id#222 in [isnull(id#222)#230,count(1)#226L] java.lang.IllegalStateException: Couldn't find id#222 in [isnull(id#222)#230,count(1)#226L] ``` After this PR: ``` == Optimized Logical Plan == Aggregate [isnull(id#222)], [NOT groupingexprref(0) AS (NOT (id IS NULL))#234, count(1) AS c#232L] +- Project [value#219 AS id#222] +- LocalRelation [value#219] ``` and the query works. ### Does this PR introduce _any_ user-facing change? Yes, the query works. ### How was this patch tested? Added new UT. Closes #31913 from peter-toth/SPARK-34581-keep-grouping-expressions. Authored-by: Peter Toth <[email protected]> Signed-off-by: Wenchen Fan <[email protected]> * [SPARK-35122][SQL] Migrate CACHE/UNCACHE TABLE to use AnalysisOnlyCommand ### What changes were proposed in this pull request? Now that `AnalysisOnlyCommand` in introduced in #32032, `CacheTable` and `UncacheTable` can extend `AnalysisOnlyCommand` to simplify the code base. For example, the logic to handle these commands such that the tables are only analyzed is scattered across different places. ### Why are the changes needed? To simplify the code base to handle these two commands. ### Does this PR introduce _any_ user-facing change? No, just internal refactoring. ### How was this patch tested? The existing tests (e.g., `CachedTableSuite`) cover the changes in this PR. For example, if I make `CacheTable`/`UncacheTable` extend `LeafCommand`, there are few failures in `CachedTableSuite`. Closes #32220 from imback82/cache_cmd_analysis_only. Authored-by: Terry Kim <[email protected]> Signed-off-by: Wenchen Fan <[email protected]> * [SPARK-31937][SQL] Support processing ArrayType/MapType/StructType data using no-serde mode script transform ### What changes were proposed in this pull request? Support no-serde mode script transform use ArrayType/MapType/StructStpe data. ### Why are the changes needed? Make user can process array/map/struct data ### Does this PR introduce _any_ user-facing change? Yes, user can process array/map/struct data in script transform `no-serde` mode ### How was this patch tested? Added UT Closes #30957 from AngersZhuuuu/SPARK-31937. Lead-authored-by: Angerszhuuuu <[email protected]> Co-authored-by: angerszhu <[email protected]> Co-authored-by: AngersZhuuuu <[email protected]> Signed-off-by: HyukjinKwon <[email protected]> * [SPARK-35045][SQL][FOLLOW-UP] Add a configuration for CSV input buffer size ### What changes were proposed in this pull request? This PR makes the input buffer configurable (as an internal configuration). This is mainly to work around the regression in uniVocity/univocity-parsers#449. This is particularly useful for SQL workloads that requires to rewrite the `CREATE TABLE` with options. ### Why are the changes needed? To work around uniVocity/univocity-parsers#449. ### Does this PR introduce _any_ user-facing change? No, it's only internal option. ### How was this patch tested? Manually tested by modifying the unittest added in https://github.com/apache/spark/pull/31858 as below: ```diff diff --git a/sql/core/src/test/scala/org/apache/spark/sql/execution/datasources/csv/CSVSuite.scala b/sql/core/src/test/scala/org/apache/spark/sql/execution/datasources/csv/CSVSuite.scala index fd25a79619d..705f38dbfbd 100644 --- a/sql/core/src/test/scala/org/apache/spark/sql/execution/datasources/csv/CSVSuite.scala +++ b/sql/core/src/test/scala/org/apache/spark/sql/execution/datasources/csv/CSVSuite.scala -2456,6 +2456,7 abstract class CSVSuite test("SPARK-34768: counting a long record with ignoreTrailingWhiteSpace set to true") { val bufSize = 128 val line = "X" * (bufSize - 1) + "| |" + spark.conf.set("spark.sql.csv.parser.inputBufferSize", 128) withTempPath { path => Seq(line).toDF.write.text(path.getAbsolutePath) assert(spark.read.format("csv") ``` Closes #32231 from HyukjinKwon/SPARK-35045-followup. Authored-by: HyukjinKwon <[email protected]> Signed-off-by: HyukjinKwon <[email protected]> * [SPARK-34837][SQL] Support ANSI SQL intervals by the aggregate function `avg` ### What changes were proposed in this pull request? Extend the `Average` expression to support `DayTimeIntervalType` and `YearMonthIntervalType` added by #31614. Note: the expressions can throw the overflow exception independently from the SQL config `spark.sql.ansi.enabled`. In this way, the modified expressions always behave in the ANSI mode for the intervals. ### Why are the changes needed? Extend `org.apache.spark.sql.catalyst.expressions.aggregate.Average` to support `DayTimeIntervalType` and `YearMonthIntervalType`. ### Does this PR introduce _any_ user-facing change? 'No'. Should not since new types have not been released yet. ### How was this patch tested? Jenkins test Closes #32229 from beliefer/SPARK-34837. Authored-by: gengjiaan <[email protected]> Signed-off-by: Max Gekk <[email protected]> * [SPARK-35107][SQL] Parse unit-to-unit interval literals to ANSI intervals ### What changes were proposed in this pull request? Parse the year-month interval literals like `INTERVAL '1-1' YEAR TO MONTH` to values of `YearMonthIntervalType`, and day-time interval literals to `DayTimeIntervalType` values. Currently, Spark SQL supports: - DAY TO HOUR - DAY TO MINUTE - DAY TO SECOND - HOUR TO MINUTE - HOUR TO SECOND - MINUTE TO SECOND All such interval literals are converted to `DayTimeIntervalType`, and `YEAR TO MONTH` to `YearMonthIntervalType` while loosing info about `from` and `to` units. **Note**: new behavior is under the SQL config `spark.sql.legacy.interval.enabled` which is `false` by default. When the config is set to `true`, the interval literals are parsed to `CaledarIntervalType` values. Closes #32176 ### Why are the changes needed? To conform the ANSI SQL standard which assumes conversions of interval literals to year-month or day-time interval but not to mixed interval type like Catalyst's `CalendarIntervalType`. ### Does this PR introduce _any_ user-facing change? Yes. Before: ```sql spark-sql> SELECT INTERVAL '1 01:02:03.123' DAY TO SECOND; 1 days 1 hours 2 minutes 3.123 seconds spark-sql> SELECT typeof(INTERVAL '1 01:02:03.123' DAY TO SECOND); interval ``` After: ```sql spark-sql> SELECT INTERVAL '1 01:02:03.123' DAY TO SECOND; 1 01:02:03.123000000 spark-sql> SELECT typeof(INTERVAL '1 01:02:03.123' DAY TO SECOND); day-time interval ``` ### How was this patch tested? 1. By running the affected test suites: ``` $ ./build/sbt "test:testOnly *.ExpressionParserSuite" $ SPARK_GENERATE_GOLDEN_FILES=1 build/sbt "sql/testOnly *SQLQueryTestSuite -- -z interval.sql" $ SPARK_GENERATE_GOLDEN_FILES=1 build/sbt "sql/testOnly *SQLQueryTestSuite -- -z create_view.sql" $ SPARK_GENERATE_GOLDEN_FILES=1 build/sbt "sql/testOnly *SQLQueryTestSuite -- -z date.sql" $ SPARK_GENERATE_GOLDEN_FILES=1 build/sbt "sql/testOnly *SQLQueryTestSuite -- -z timestamp.sql" ``` 2. PostgresSQL tests are executed with `spark.sql.legacy.interval.enabled` is set to `true` to keep compatibility with PostgreSQL output: ```sql > SELECT interval '999' second; 0 years 0 mons 0 days 0 hours 16 mins 39.00 secs ``` Closes #32209 from MaxGekk/parse-ansi-interval-literals. Authored-by: Max Gekk <[email protected]> Signed-off-by: Max Gekk <[email protected]> * [SPARK-34715][SQL][TESTS] Add round trip tests for period <-> month and duration <-> micros ### What changes were proposed in this pull request? Similarly to the test from the PR https://github.com/apache/spark/pull/31799, add tests: 1. Months -> Period -> Months 2. Period -> Months -> Period 3. Duration -> micros -> Duration ### Why are the changes needed? Add round trip tests for period <-> month and duration <-> micros ### Does this PR introduce _any_ user-facing change? 'No'. Just test cases. ### How was this patch tested? Jenkins test Closes #32234 from beliefer/SPARK-34715. Authored-by: gengjiaan <[email protected]> Signed-off-by: Max Gekk <[email protected]> * [SPARK-35125][K8S] Upgrade K8s client to 5.3.0 to support K8s 1.20 ### What changes were proposed in this pull request? Although AS-IS master branch already works with K8s 1.20, this PR aims to upgrade K8s client to 5.3.0 to support K8s 1.20 officially. - https://github.com/fabric8io/kubernetes-client#compatibility-matrix The following are the notable breaking API changes. 1. Remove Doneable (5.0+): - https://github.com/fabric8io/kubernetes-client/pull/2571 2. Change Watcher.onClose signature (5.0+): - https://github.com/fabric8io/kubernetes-client/pull/2616 3. Change Readiness (5.1+) - https://github.com/fabric8io/kubernetes-client/pull/2796 ### Why are the changes needed? According to the compatibility matrix, this makes Apache Spark and its external cluster manager extension support all K8s 1.20 features officially for Apache Spark 3.2.0. ### Does this PR introduce _any_ user-facing change? Yes, this is a dev dependency change which affects K8s cluster extension users. ### How was this patch tested? Pass the CIs. This is manually tested with K8s IT. ``` KubernetesSuite: - Run SparkPi with no resources - Run SparkPi with a very long application name. - Use SparkLauncher.NO_RESOURCE - Run SparkPi with a master URL without a scheme. - Run SparkPi with an argument. - Run SparkPi with custom labels, annotations, and environment variables. - All pods have the same service account by default - Run extraJVMOptions check on driver - Run SparkRemoteFileTest using a remote data file - Verify logging configuration is picked from the provided SPARK_CONF_DIR/log4j.properties - Run SparkPi with env and mount secrets. - Run PySpark on simple pi.py example - Run PySpark to test a pyfiles example - Run PySpark with memory customization - Run in client mode. - Start pod creation from template - PVs with local storage - Launcher client dependencies - SPARK-33615: Launcher client archives - SPARK-33748: Launcher python client respecting PYSPARK_PYTHON - SPARK-33748: Launcher python client respecting spark.pyspark.python and spark.pyspark.driver.python - Launcher python client dependencies using a zip file - Test basic decommissioning - Test basic decommissioning with shuffle cleanup - Test decommissioning with dynamic allocation & shuffle cleanups - Test decommissioning timeouts - Run SparkR on simple dataframe.R example Run completed in 17 minutes, 44 seconds. Total number of tests run: 27 Suites: completed 2, aborted 0 Tests: succeeded 27, failed 0, canceled 0, ignored 0, pending 0 All tests passed. ``` Closes #32221 from dongjoon-hyun/SPARK-K8S-530. Authored-by: Dongjoon Hyun <[email protected]> Signed-off-by: Dongjoon Hyun <[email protected]> * [SPARK-35102][SQL] Make spark.sql.hive.version read-only, not deprecated and meaningful ### What changes were proposed in this pull request? Firstly let's take a look at the definition and comment. ``` // A fake config which is only here for backward compatibility reasons. This config has no effect // to Spark, just for reporting the builtin Hive version of Spark to existing applications that // already rely on this config. val FAKE_HIVE_VERSION = buildConf("spark.sql.hive.version") .doc(s"deprecated, please use ${HIVE_METASTORE_VERSION.key} to get the Hive version in Spark.") .version("1.1.1") .fallbackConf(HIVE_METASTORE_VERSION) ``` It is used for reporting the built-in Hive version but the current status is unsatisfactory, as it is could be changed in many ways e.g. --conf/SET syntax. It is marked as deprecated but kept a long way until now. I guess it is hard for us to remove it and not even necessary. On second thought, it's actually good for us to keep it to work with the `spark.sql.hive.metastore.version`. As when `spark.sql.hive.metastore.version` is changed, it could be used to report the compiled hive version statically, it's useful when an error occurs in this case. So this parameter should be fixed to compiled hive version. ### Why are the changes needed? `spark.sql.hive.version` is useful in certain cases and should be read-only ### Does this PR introduce _any_ user-facing change? `spark.sql.hive.version` now is read-only ### How was this patch tested? new test cases Closes #32200 from yaooqinn/SPARK-35102. Authored-by: Kent Yao <[email protected]> Signed-off-by: Wenchen Fan <[email protected]> * [SPARK-35136] Remove initial null value of LiveStage.info ### What changes were proposed in this pull request? To prevent potential NullPointerExceptions, this PR changes the `LiveStage` constructor to take `info` as a constructor parameter and adds a nullcheck in `AppStatusListener.activeStages`. ### Why are the changes needed? The `AppStatusListener.getOrCreateStage` would create a LiveStage object with the `info` field set to null and right after that set it to a specific StageInfo object. This can lead to a race condition when the `livestages` are read in between those calls. This could then lead to a null pointer exception in, for instance: `AppStatusListener.activeStages`. ### Does this PR introduce _any_ user-facing change? No ### How was this patch tested? Regular CI/CD tests Closes #32233 from sander-goos/SPARK-35136-livestage. Authored-by: Sander Goos <[email protected]> Signed-off-by: Wenchen Fan <[email protected]> * [SPARK-35138][SQL] Remove Antlr4 workaround ### What changes were proposed in this pull request? Remove Antlr 4.7 workaround. ### Why are the changes needed? The https://github.com/antlr/antlr4/commit/ac9f7530 has been fixed in upstream, so remove the workaround to simplify code. ### Does this PR introduce _any_ user-facing change? No ### How was this patch tested? Existed UTs. Closes #32238 from pan3793/antlr-minor. Authored-by: Cheng Pan <[email protected]> Signed-off-by: Dongjoon Hyun <[email protected]> * [SPARK-35120][INFRA] Guide users to sync branch and enable GitHub Actions in their forked repository ### What changes were proposed in this pull request? This PR proposes to add messages when the workflow fails to find the workflow run in a forked repository, for example as below: **Before**   **After**   (typo `foce` in the image was fixed) See this example: https://github.com/HyukjinKwon/spark/runs/2380644793 ### Why are the changes needed? To guide users to enable Github Actions in their forked repositories (and sync their branch to the latest `master` in Apache Spark). ### Does this PR introduce _any_ user-facing change? No, dev-only. ### How was this patch tested? Manually tested in: - https://github.com/HyukjinKwon/spark/pull/47 - https://github.com/HyukjinKwon/spark/pull/46 Closes #32235 from HyukjinKwon/test-test-test. Authored-by: HyukjinKwon <[email protected]> Signed-off-by: Dongjoon Hyun <[email protected]> * [SPARK-35131][K8S] Support early driver service clean-up during app termination ### What changes were proposed in this pull request? This PR aims to support a new configuration, `spark.kubernetes.driver.service.deleteOnTermination`, to clean up `Driver Service` resource during app termination. ### Why are the changes needed? The K8s service is one of the important resources and sometimes it's controlled by quota. ``` $ k describe quota Name: service Namespace: default Resource Used Hard -------- ---- ---- services 1 3 ``` Apache Spark creates a service for driver whose lifecycle is the same with driver pod. It means a new Spark job submission fails if the number of completed Spark jobs equals the number of service quota. **BEFORE** ``` $ k get pod NAME READY STATUS RESTARTS AGE org-apache-spark-examples-sparkpi-a32c9278e7061b4d-driver 0/1 Completed 0 31m org-apache-spark-examples-sparkpi-a9f1f578e721ef62-driver 0/1 Completed 0 78s $ k get svc NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 80m org-apache-spark-examples-sparkpi-a32c9278e7061b4d-driver-svc ClusterIP None <none> 7078/TCP,7079/TCP,4040/TCP 31m org-apache-spark-examples-sparkpi-a9f1f578e721ef62-driver-svc ClusterIP None <none> 7078/TCP,7079/TCP,4040/TCP 80s $ k describe quota Name: service Namespace: default Resource Used Hard -------- ---- ---- services 3 3 $ bin/spark-submit... Exception in thread "main" io.fabric8.kubernetes.client.KubernetesClientException: Failure executing: POST at: https://192.168.64.50:8443/api/v1/namespaces/default/services. Message: Forbidden! User minikube doesn't have permission. services "org-apache-spark-examples-sparkpi-843f6978e722819c-driver-svc" is forbidden: exceeded quota: service, requested: services=1, used: services=3, limited: services=3. ``` **AFTER** ``` $ k get pod NAME READY STATUS RESTARTS AGE org-apache-spark-examples-sparkpi-23d5f278e77731a7-driver 0/1 Completed 0 26s org-apache-spark-examples-sparkpi-d1292278e7768ed4-driver 0/1 Completed 0 67s org-apache-spark-examples-sparkpi-e5bedf78e776ea9d-driver 0/1 Completed 0 44s $ k get svc NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 172m $ k describe quota Name: service Namespace: default Resource Used Hard -------- ---- ---- services 1 3 ``` ### Does this PR introduce _any_ user-facing change? Yes, this PR adds a new configuration, `spark.kubernetes.driver.service.deleteOnTermination`, and enables it by default. The change is documented at the migration guide. ### How was this patch tested? Pass the CIs. This is tested with K8s IT manually. ``` KubernetesSuite: - Run SparkPi with no resources - Run SparkPi with a very long application name. - Use SparkLauncher.NO_RESOURCE - Run SparkPi with a master URL without a scheme. - Run SparkPi with an argument. - Run SparkPi with custom labels, annotations, and environment variables. - All pods have the same service account by default - Run extraJVMOptions check on driver - Run SparkRemoteFileTest using a remote data file - Verify logging configuration is picked from the provided SPARK_CONF_DIR/log4j.properties - Run SparkPi with env and mount secrets. - Run PySpark on simple pi.py example - Run PySpark to test a pyfiles example - Run PySpark with memory customization - Run in client mode. - Start pod creation from template - PVs with local storage - Launcher client dependencies - SPARK-33615: Launcher client archives - SPARK-33748: Launcher python client respecting PYSPARK_PYTHON - SPARK-33748: Launcher python client respecting spark.pyspark.python and spark.pyspark.driver.python - Launcher python client dependencies using a zip file - Test basic decommissioning - Test basic decommissioning with shuffle cleanup - Test decommissioning with dynamic allocation & shuffle cleanups - Test decommissioning timeouts - Run SparkR on simple dataframe.R example Run completed in 19 minutes, 9 seconds. Total number of tests run: 27 Suites: completed 2, aborted 0 Tests: succeeded 27, failed 0, canceled 0, ignored 0, pending 0 All tests passed. ``` Closes #32226 from dongjoon-hyun/SPARK-35131. Authored-by: Dongjoon Hyun <[email protected]> Signed-off-by: Dongjoon Hyun <[email protected]> * [SPARK-35103][SQL] Make TypeCoercion rules more efficient ## What changes were proposed in this pull request? This PR fixes a couple of things in TypeCoercion rules: - Only run the propagate types step if the children of a node have output attributes with changed dataTypes and/or nullability. This is implemented as custom tree transformation. The TypeCoercion rules now only implement a partial function. - Combine multiple type coercion rules into a single rule. Multiple rules are applied in single tree traversal. - Reduce calls to conf.get in DecimalPrecision. This now happens once per tree traversal, instead of once per matched expression. - Reduce the use of withNewChildren. This brings down the number of CPU cycles spend in analysis by ~28% (benchmark: 10 iterations of all TPC-DS queries on SF10). ## How was this patch tested? Existing tests. Closes #32208 from sigmod/coercion. Authored-by: Yingyi Bu <[email protected]> Signed-off-by: herman <[email protected]> * [SPARK-35117][UI] Change progress bar back to highlight ratio of tasks in progress ### What changes were proposed in this pull request? Small UI update to add highlighting the number of tasks in progress in a stage/job instead of highlighting the whole in progress stage/job. This was the behavior pre Spark 3.1 and the bootstrap 4 upgrade. ### Why are the changes needed? To add back in functionality lost between 3.0 and 3.1. This provides a great visual queue of how much of a stage/job is currently being run. ### Does this PR introduce _any_ user-facing change? Small UI change. Before:  After (and pre Spark 3.1):  ### How was this patch tested? Updated existing UT. Closes #32214 from Kimahriman/progress-bar-started. Authored-by: Adam Binford <[email protected]> Signed-off-by: Kousuke Saruta <[email protected]> * [SPARK-35080][SQL] Only allow a subset of correlated equality predicates when a subquery is aggregated ### What changes were proposed in this pull request? This PR updated the `foundNonEqualCorrelatedPred` logic for correlated subqueries in `CheckAnalysis` to only allow correlated equality predicates that guarantee one-to-one mapping between inner and outer attributes, instead of all equality predicates. ### Why are the changes needed? To fix correctness bugs. Before this fix Spark can give wrong results for certain correlated subqueries that pass CheckAnalysis: Example 1: ```sql create or replace view t1(c) as values ('a'), ('b') create or replace view t2(c) as values ('ab'), ('abc'), ('bc') select c, (select count(*) from t2 where t1.c = substring(t2.c, 1, 1)) from t1 ``` Correct results: [(a, 2), (b, 1)] Spark results: ``` +---+-----------------+ |c |scalarsubquery(c)| +---+-----------------+ |a |1 | |a |1 | |b |1 | +---+-----------------+ ``` Example 2: ```sql create or replace view t1(a, b) as values (0, 6), (1, 5), (2, 4), (3, 3); create or replace view t2(c) as values (6); select c, (select count(*) from t1 where a + b = c) from t2; ``` Correct results: [(6, 4)] Spark results: ``` +---+-----------------+ |c |scalarsubquery(c)| +---+-----------------+ |6 |1 | |6 |1 | |6 |1 | |6 |1 | +---+-----------------+ ``` ### Does this PR introduce _any_ user-facing change? Yes. Users will not be able to run queries that contain unsupported correlated equality predicates. ### How was this patch tested? Added unit tests. Closes #32179 from allisonwang-db/spark-35080-subquery-bug. Lead-authored-by: allisonwang-db <[email protected]> Co-authored-by: Wenchen Fan <[email protected]> Signed-off-by: Wenchen Fan <[email protected]> * [SPARK-35052][SQL] Use static bits for AttributeReference and Literal ### What changes were proposed in this pull request? - Share a static ImmutableBitSet for `treePatternBits` in all object instances of AttributeReference. - Share three static ImmutableBitSets for `treePatternBits` in three kinds of Literals. - Add an ImmutableBitSet as a subclass of BitSet. ### Why are the changes needed? Reduce the additional memory usage caused by `treePatternBits`. ### Does this PR introduce _any_ user-facing change? No. ### How was this patch tested? Existing tests. Closes #32157 from sigmod/leaf. Authored-by: Yingyi Bu <[email protected]> Signed-off-by: Gengliang Wang <[email protected]> * [SPARK-35134][BUILD][TESTS] Manually exclude redundant netty jars in SparkBuild.scala to avoid version conflicts in test ### What changes were proposed in this pull request? The following logs will print when Jenkins execute [PySpark pip packaging tests](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/137500/console): ``` copying deps/jars/netty-all-4.1.51.Final.jar -> pyspark-3.2.0.dev0/deps/jars copying deps/jars/netty-buffer-4.1.50.Final.jar -> pyspark-3.2.0.dev0/deps/jars copying deps/jars/netty-codec-4.1.50.Final.jar -> pyspark-3.2.0.dev0/deps/jars copying deps/jars/netty-common-4.1.50.Final.jar -> pyspark-3.2.0.dev0/deps/jars copying deps/jars/netty-handler-4.1.50.Final.jar -> pyspark-3.2.0.dev0/deps/jars copying deps/jars/netty-resolver-4.1.50.Final.jar -> pyspark-3.2.0.dev0/deps/jars copying deps/jars/netty-transport-4.1.50.Final.jar -> pyspark-3.2.0.dev0/deps/jars copying deps/jars/netty-transport-native-epoll-4.1.50.Final.jar -> pyspark-3.2.0.dev0/deps/jars ``` There will be 2 different versions of netty4 jars copied to the jars directory, but the `netty-xxx-4.1.50.Final.jar` not in maven `dependency:tree `, but spark only needs to rely on `netty-all-xxx.jar`. So this pr try to add new `ExclusionRule`s to `SparkBuild.scala` to exclude unnecessary netty 4 dependencies. ### Why are the changes needed? Make sure that only `netty-all-xxx.jar` is used in the test to avoid possible jar conflicts. ### Does this PR introduce _any_ user-facing change? No. ### How was this patch tested? - Pass the Jenkins or GitHub Action - Check Jenkins log manually, there should be only `copying deps/jars/netty-all-4.1.51.Final.jar -> pyspark-3.2.0.dev0/deps/jars` and there should be no such logs as ``` copying deps/jars/netty-buffer-4.1.50.Final.jar -> pyspark-3.2.0.dev0/deps/jars copying deps/jars/netty-codec-4.1.50.Final.jar -> pyspark-3.2.0.dev0/deps/jars copying deps/jars/netty-common-4.1.50.Final.jar -> pyspark-3.2.0.dev0/deps/jars copying deps/jars/netty-handler-4.1.50.Final.jar -> pyspark-3.2.0.dev0/deps/jars copying deps/jars/netty-resolver-4.1.50.Final.jar -> pyspark-3.2.0.dev0/deps/jars copying deps/jars/netty-transport-4.1.50.Final.jar -> pyspark-3.2.0.dev0/deps/jars copying deps/jars/netty-transport-native-epoll-4.1.50.Final.jar -> pyspark-3.2.0.dev0/deps/jars ``` Closes #32230 from LuciferYang/SPARK-35134. Authored-by: yangjie01 <[email protected]> Signed-off-by: HyukjinKwon <[email protected]> * [SPARK-35018][SQL][TESTS] Check transferring of year-month intervals via Hive Thrift server ### What changes were proposed in this pull request? 1. Add a test to check that Thrift server is able to collect year-month intervals and transfer them via thrift protocol. 2. Improve similar test for day-time intervals. After the changes, the test doesn't depend on the result of date subtractions. In the future, the type of date subtract can be changed. So, current PR should make the test tolerant to the changes. ### Why are the changes needed? To improve test coverage. ### Does this PR introduce _any_ user-facing change? No ### How was this patch tested? By running the modified test suite: ``` $ ./build/sbt -Phive -Phive-thriftserver "test:testOnly *SparkThriftServerProtocolVersionsSuite" ``` Closes #32240 from MaxGekk/year-month-interval-thrift-protocol. Authored-by: Max Gekk <[email protected]> Signed-off-by: Max Gekk <[email protected]> * [SPARK-34974][SQL] Improve subquery decorrelation framework ### What changes were proposed in this pull request? This PR implements the decorrelation technique in the paper "Unnesting Arbitrary Queries" by T. Neumann; A. Kemper (http://www.btw-2015.de/res/proceedings/Hauptband/Wiss/Neumann-Unnesting_Arbitrary_Querie.pdf). It currently supports Filter, Project, Aggregate, Join, and UnaryNode that passes CheckAnalysis. This feature can be controlled by the config `spark.sql.optimizer.decorrelateInnerQuery.enabled` (default: true). A few notes: 1. This PR does not relax any constraints in CheckAnalysis for correlated subqueries, even though some cases can be supported by this new framework, such as aggregate with correlated non-equality predicates. This PR focuses on adding the new framework and making sure all existing cases can be supported. Constraints can be relaxed gradually in the future via separate PRs. 2. The new framework is only enabled for correlated scalar subqueries, as the first step. EXISTS/IN subqueries can be supported in the future. ### Why are the changes needed? Currently, Spark has limited support for correlated subqueries. It only allows `Filter` to reference outer query columns and does not support non-equality predicates when the subquery is aggregated. This new framework will allow more operators to host outer column references and support correlated non-equality predicates and more types of operators in correlated subqueries. ### Does this PR introduce _any_ user-facing change? No ### How was this patch tested? Existing unit and SQL query tests and new optimizer plan tests. Closes #32072 from allisonwang-db/spark-34974-decorrelation. Authored-by: allisonwang-db <[email protected]> Signed-off-by: Wenchen Fan <[email protected]> * [SPARK-35068][SQL] Add tests for ANSI intervals to HiveThriftBinaryServerSuite ### What changes were proposed in this pull request? After the PR https://github.com/apache/spark/pull/32209, this should be possible now. We can add test case for ANSI intervals to HiveThriftBinaryServerSuite ### Why are the changes needed? Add more test case ### Does this PR introduce _any_ user-facing change? No ### How was this patch tested? Added UT Closes #32250 from AngersZhuuuu/SPARK-35068. Authored-by: Angerszhuuuu <[email protected]> Signed-off-by: Max Gekk <[email protected]> * [SPARK-33976][SQL][DOCS] Add a SQL doc page for a TRANSFORM clause ### What changes were proposed in this pull request? Add doc about `TRANSFORM` and related function.  ### Why are the changes needed? ### Does this PR introduce _any_ user-facing change? No ### How was this patch tested? Not need Closes #31010 from AngersZhuuuu/SPARK-33976. Lead-authored-by: Angerszhuuuu <[email protected]> Co-authored-by: angerszhu <[email protected]> Signed-off-by: Wenchen Fan <[email protected]> * [SPARK-34877][CORE][YARN] Add the code change for adding the Spark AM log link in spark UI ### What changes were proposed in this pull request? On Running Spark job with yarn and deployment mode as client, Spark Driver and Spark Application master launch in two separate containers. In various scenarios there is need to see Spark Application master logs to see the resource allocation, Decommissioning status and other information shared between yarn RM and Spark Application master. In Cluster mode Spark driver and Spark AM is on same container, So Log link of the driver already there to see the logs in Spark UI This PR is for adding the spark AM log link for spark job running in the client mode for yarn. Instead of searching the container id and then find the logs. We can directly check in the Spark UI This change is only for showing the AM log links in the Client mode when resource manager is yarn. ### Why are the changes needed? Till now the only way to check this by finding the container id of the AM and check the logs either using Yarn utility or Yarn RM Application History server. This PR is for adding the spark AM log link for spark job running in the client mode for yarn. Instead of searching the container id and then find the logs. We can directly check in the Spark UI ### Does this PR introduce _any_ user-facing change? No ### How was this patch tested? Added the unit test also checked the Spark UI **In Yarn Client mode** Before Change  After the Change - The AM info is there  AM Log  **In Yarn Cluster Mode** - The AM log link will not be there  Closes #31974 from SaurabhChawla100/SPARK-34877. Authored-by: SaurabhChawla <[email protected]> Signed-off-by: Thomas Graves <[email protected]> * [SPARK-34035][SQL] Refactor ScriptTransformation to remove input parameter and replace it by child.output ### What changes were proposed in this pull request? Refactor ScriptTransformation to remove input parameter and replace it by child.output ### Why are the changes needed? refactor code ### Does this PR introduce _any_ user-facing change? No ### How was this patch tested? Existed UT Closes #32228 from AngersZhuuuu/SPARK-34035. Lead-authored-by: Angerszhuuuu <[email protected]> Co-authored-by: AngersZhuuuu <[email protected]> Signed-off-by: Wenchen Fan <[email protected]> * [SPARK-34338][SQL] Report metrics from Datasource v2 scan ### What changes were proposed in this pull request? This patch proposes to leverage `CustomMetric`, `CustomTaskMetric` API to report custom metrics from DS v2 scan to Spark. ### Why are the changes needed? This is related to #31398. In SPARK-34297, we want to add a couple of metrics when reading from Kafka in SS. We need some public API change in DS v2 to make it possible. This extracts only DS v2 change and make it general for DS v2 instead of micro-batch DS v2 API. ### Does this PR introduce _any_ user-facing change? No ### How was this patch tested? Unit test. Implement a simple test DS v2 class locally and run it: ```scala scala> import org.apache.spark.sql.execution.datasources.v2._ import org.apache.spark.sql.execution.datasources.v2._ scala> classOf[CustomMetricDataSourceV2].getName res0: String = org.apache.spark.sql.execution.datasources.v2.CustomMetricDataSourceV2 scala> val df = spark.read.format(res0).load() df: org.apache.spark.sql.DataFrame = [i: int, j: int] scala> df.collect ``` <img width="703" alt="Screen Shot 2021-03-30 at 11 07 13 PM" src="https://user-images.githubusercontent.com/68855/113098080-d8a49800-91ac-11eb-8681-be408a0f2e69.png"> Closes #31451 from viirya/dsv2-metrics. Authored-by: Liang-Chi Hsieh <[email protected]> Signed-off-by: Wenchen Fan <[email protected]> * [SPARK-35145][SQL] CurrentOrigin should support nested invoking ### What changes were proposed in this pull request? `CurrentOrigin` is a thread-local variable to track the original SQL line position in plan/expression. Usually, we set `CurrentOrigin`, create `TreeNode` instances, and reset `CurrentOrigin`. This PR updates the last step to set `CurrentOrigin` to its previous value, instead of resetting it. This is necessary when we invoke `CurrentOrigin` in a nested way, like with subqueries. ### Why are the changes needed? To keep the original SQL line position in the error message in more cases. ### Does this PR introduce _any_ user-facing change? No, only minor error message changes. ### How was this patch tested? existing tests Closes #32249 from cloud-fan/origin. Authored-by: Wenchen Fan <[email protected]> Signed-off-by: Wenchen Fan <[email protected]> * [SPARK-34472][YARN] Ship ivySettings file to driver in cluster mode ### What changes were proposed in this pull request? In YARN, ship the `spark.jars.ivySettings` file to the driver when using `cluster` deploy mode so that `addJar` is able to find it in order to resolve ivy paths. ### Why are the changes needed? SPARK-33084 introduced support for Ivy paths in `sc.addJar` or Spark SQL `ADD JAR`. If we use a custom ivySettings file using `spark.jars.ivySettings`, it is loaded at https://github.com/apache/spark/blob/b26e7b510bbaee63c4095ab47e75ff2a70e377d7/core/src/main/scala/org/apache/spark/deploy/SparkSubmit.scala#L1280. However, this file is only accessible on the client machine. In YARN cluster mode, this file is not available on the driver and so `addJar` fails to find it. ### Does this PR introduce _any_ user-facing change? No ### How was this patch tested? Added unit tests to verify that the `ivySettings` file is localized by the YARN client and that a YARN cluster mode application is able to find to load the `ivySettings` file. Closes #31591 from shardulm94/SPARK-34472. Authored-by: Shardul Mahadik <[email protected]> Signed-off-by: Thomas Graves <[email protected]> * [SPARK-35153][SQL] Make textual representation of ANSI interval operators more readable ### What changes were proposed in this pull request? In the PR, I propose to override the `sql` and `toString` methods of the expressions that implement operators over ANSI intervals (`YearMonthIntervalType`/`DayTimeIntervalType`), and replace internal expression class names by operators like `*`, `/` and `-`. ### Why are the changes needed? Proposed methods should make the textual representation of such operators more readable, and potentially parsable by Spark SQL parser. ### Does this PR introduce _any_ user-facing change? Yes. This can influence on column names. ### How was this patch tested? By running existing test suites for interval and datetime expressions, and re-generating the `*.sql` tests: ``` $ build/sbt "sql/testOnly *SQLQueryTestSuite -- -z interval.sql" $ build/sbt "sql/testOnly *SQLQueryTestSuite -- -z datetime.sql" ``` Closes #32262 from MaxGekk/interval-operator-sql. Authored-by: Max Gekk <[email protected]> Signed-off-by: Max Gekk <[email protected]> * [SPARK-35132][BUILD][CORE] Upgrade netty-all to 4.1.63.Final ### What changes were proposed in this pull request? There are 3 CVE problems were found after netty 4.1.51.Final as follows: - [CVE-2021-21409](https://cve.mitre.org/cgi-bin/cvename.cgi?name=CVE-2021-21409) - [CVE-2021-21295](https://cve.mitre.org/cgi-bin/cvename.cgi?name=CVE-2021-21295) - [CVE-2021-21290](https://cve.mitre.org/cgi-bin/cvename.cgi?name=CVE-2021-21290) So the main change of this pr is upgrade netty-all to 4.1.63.Final avoid these potential risks. Another change is to clean up deprecated api usage: [Tiny caches have been merged into small caches](https://github.com/netty/netty/blob/4.1/buffer/src/main/java/io/netty/buffer/PooledByteBufAllocator.java#L447-L455)(after [netty#10267](https://github.com/netty/netty/pull/10267)) and [should use PooledByteBufAllocator(boolean, int, int, int, int, int, int, boolean, int)](https://github.com/netty/netty/blob/4.1/buffer/src/main/java/io/netty/buffer/PooledByteBufAllocator.java#L227-L239) api to create `PooledByteBufAllocator`. ### Why are the changes needed? Upgrade netty-all to 4.1.63.Final avoid CVE problems. ### Does this PR introduce _any_ user-facing change? No ### How was this patch tested? Pass the Jenkins or GitHub Action Closes #32227 from LuciferYang/SPARK-35132. Authored-by: yangjie01 <[email protected]> Signed-off-by: Sean Owen <[email protected]> * [SPARK-35044][SQL][FOLLOWUP][TEST-HADOOP2.7] Fix hadoop 2.7 test due to diff between hadoop 2.7 and hadoop 3 ### What changes were proposed in this pull request? dfs.replication is inconsistent from hadoop 2.x to 3.x, so in this PR we use `dfs.hosts` to verify per https://github.com/apache/spark/pull/32144#discussion_r616833099 ``` == Results == !== Correct Answer - 1 == == Spark Answer - 1 == !struct<> struct<key:string,value:string> ![dfs.replication,<undefined>] [dfs.replication,3] ``` ### Why are the changes needed? fix Jenkins job with Hadoop 2.7 ### Does this PR introduce _any_ user-facing change? test only change ### How was this patch tested? test only change Closes #32263 from yaooqinn/SPARK-35044-F. Authored-by: Kent Yao <[email protected]> Signed-off-by: HyukjinKwon <[email protected]> * [SPARK-35113][SQL] Support ANSI intervals in the Hash expression ### What changes were proposed in this pull request? Support ANSI interval in HashExpression and add UT ### Why are the changes needed? Support ANSI interval in HashExpression ### Does this PR introduce _any_ user-facing change? User can pass ANSI interval in HashExpression function ### How was this patch tested? Added UT Closes #32259 from AngersZhuuuu/SPARK-35113. Authored-by: Angerszhuuuu <[email protected]> Signed-off-by: Max Gekk <[email protected]> * [SPARK-35120][INFRA][FOLLOW-UP] Try catch an error to show the correct guidance ### What changes were proposed in this pull request? This PR proposes to handle 404 not found, see https://github.com/apache/spark/pull/32255/checks?check_run_id=2390446579 as an example. If a fork does not have any previous workflow runs, it seems throwing 4…
… expressions from aggregate expressions without aggregate function (#941) * [SPARK-34581][SQL] Don't optimize out grouping expressions from aggregate expressions without aggregate function ### What changes were proposed in this pull request? This PR adds a new rule `PullOutGroupingExpressions` to pull out complex grouping expressions to a `Project` node under an `Aggregate`. These expressions are then referenced in both grouping expressions and aggregate expressions without aggregate functions to ensure that optimization rules don't change the aggregate expressions to invalid ones that no longer refer to any grouping expressions. ### Why are the changes needed? If aggregate expressions (without aggregate functions) in an `Aggregate` node are complex then the `Optimizer` can optimize out grouping expressions from them and so making aggregate expressions invalid. Here is a simple example: ``` SELECT not(t.id IS NULL) , count(*) FROM t GROUP BY t.id IS NULL ``` In this case the `BooleanSimplification` rule does this: ``` === Applying Rule org.apache.spark.sql.catalyst.optimizer.BooleanSimplification === !Aggregate [isnull(id#222)], [NOT isnull(id#222) AS (NOT (id IS NULL))#226, count(1) AS c#224L] Aggregate [isnull(id#222)], [isnotnull(id#222) AS (NOT (id IS NULL))#226, count(1) AS c#224L] +- Project [value#219 AS id#222] +- Project [value#219 AS id#222] +- LocalRelation [value#219] +- LocalRelation [value#219] ``` where `NOT isnull(id#222)` is optimized to `isnotnull(id#222)` and so it no longer refers to any grouping expression. Before this PR: ``` == Optimized Logical Plan == Aggregate [isnull(id#222)], [isnotnull(id#222) AS (NOT (id IS NULL))#234, count(1) AS c#232L] +- Project [value#219 AS id#222] +- LocalRelation [value#219] ``` and running the query throws an error: ``` Couldn't find id#222 in [isnull(id#222)#230,count(1)#226L] java.lang.IllegalStateException: Couldn't find id#222 in [isnull(id#222)#230,count(1)#226L] ``` After this PR: ``` == Optimized Logical Plan == Aggregate [_groupingexpression#233], [NOT _groupingexpression#233 AS (NOT (id IS NULL))#230, count(1) AS c#228L] +- Project [isnull(value#219) AS _groupingexpression#233] +- LocalRelation [value#219] ``` and the query works. ### Does this PR introduce _any_ user-facing change? Yes, the query works. ### How was this patch tested? Added new UT. Closes #32396 from peter-toth/SPARK-34581-keep-grouping-expressions-2. Authored-by: Peter Toth <[email protected]> Signed-off-by: Wenchen Fan <[email protected]> (cherry picked from commit cfc0495) * [SPARK-34037][SQL] Remove unnecessary upcasting for Avg & Sum which handle by themself internally ### What changes were proposed in this pull request? The type-coercion for numeric types of average and sum is not necessary at all, as the resultType and sumType can prevent the overflow. ### Why are the changes needed? rm unnecessary logic which may cause potential performance regressions ### Does this PR introduce _any_ user-facing change? no ### How was this patch tested? tpcds tests for plan Closes #31079 from yaooqinn/SPARK-34037. Authored-by: Kent Yao <[email protected]> Signed-off-by: Liang-Chi Hsieh <[email protected]> (cherry picked from commit a235c3b) Co-authored-by: Peter Toth <[email protected]>
No description provided.