
Doing fast searching of nearest neighbors in high dimensional spaces is an increasingly important problem, but so far there has not been a lot of empirical attempts at comparing approaches in an objective way.
This project contains some tools to benchmark various implementations of approximate nearest neighbor (ANN) search for different metrics. We have pregenerated datasets (in HDF5) formats and we also have Docker containers for each algorithm. There's a test suite that makes sure every algorithm works.
- Annoy
- FLANN
- scikit-learn: LSHForest, KDTree, BallTree
- PANNS
- NearPy
- KGraph
- NMSLIB (Non-Metric Space Library): SWGraph, HNSW, BallTree, MPLSH
- hnswlib (a part of nmslib project)
- RPForest
- FAISS
- DolphinnPy
- Datasketch
- PyNNDescent
- MRPT
- NGT: ONNG, PANNG
- SPTAG
- PUFFINN
We have a number of precomputed data sets for this. All data sets are pre-split into train/test and come with ground truth data in the form of the top 100 neighbors. We store them in a HDF5 format:
| Dataset | Dimensions | Train size | Test size | Neighbors | Distance | Download |
|---|---|---|---|---|---|---|
| DEEP1B | 96 | 9,990,000 | 10,000 | 100 | Angular | HDF5 (3.6GB) |
| Fashion-MNIST | 784 | 60,000 | 10,000 | 100 | Euclidean | HDF5 (217MB) |
| GIST | 960 | 1,000,000 | 1,000 | 100 | Euclidean | HDF5 (3.6GB) |
| GloVe | 25 | 1,183,514 | 10,000 | 100 | Angular | HDF5 (121MB) |
| GloVe | 50 | 1,183,514 | 10,000 | 100 | Angular | HDF5 (235MB) |
| GloVe | 100 | 1,183,514 | 10,000 | 100 | Angular | HDF5 (463MB) |
| GloVe | 200 | 1,183,514 | 10,000 | 100 | Angular | HDF5 (918MB) |
| Kosarak | 27983 | 74,962 | 500 | 100 | Jaccard | HDF5 (2.0GB) |
| MNIST | 784 | 60,000 | 10,000 | 100 | Euclidean | HDF5 (217MB) |
| NYTimes | 256 | 290,000 | 10,000 | 100 | Angular | HDF5 (301MB) |
| SIFT | 128 | 1,000,000 | 10,000 | 100 | Euclidean | HDF5 (501MB) |
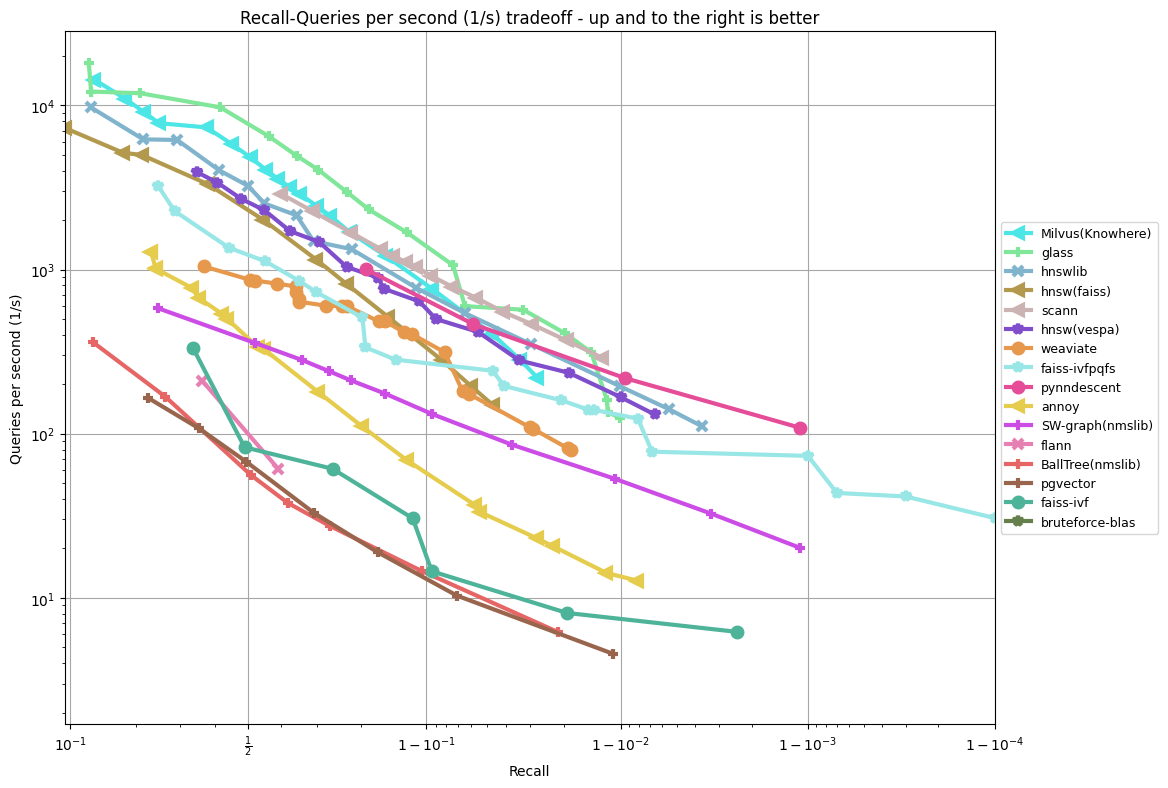
These are all as of 2019-06-10, running all benchmarks on a c5.4xlarge machine on AWS:





The only prerequisite is Python (tested with 3.6) and Docker.
- Clone the repo.
- Run
pip install -r requirements.txt. - Run
python install.pyto build all the libraries inside Docker containers (this can take a while, like 10-30 minutes).
- Run
python run.py(this can take an extremely long time, potentially days) - Run
python plot.pyorpython create_website.pyto plot results.
You can customize the algorithms and datasets if you want to:
- Check that
algos.yamlcontains the parameter settings that you want to test - To run experiments on SIFT, invoke
python run.py --dataset glove-100-angular. Seepython run.py --helpfor more information on possible settings. Note that experiments can take a long time. - To process the results, either use
python plot.py --dataset glove-100-angularorpython create_website.py. An example call:python create_website.py --plottype recall/time --latex --scatter --outputdir website/.
- Add your algorithm into
ann_benchmarks/algorithmsby providing a small Python wrapper. - Add a Dockerfile in
install/for it - Add it to
algos.yaml - Add it to
.travis.yml
- Everyone is welcome to submit pull requests with tweaks and changes to how each library is being used.
- In particular: if you are the author of any of these libraries, and you think the benchmark can be improved, consider making the improvement and submitting a pull request.
- This is meant to be an ongoing project and represent the current state.
- Make everything easy to replicate, including installing and preparing the datasets.
- Try many different values of parameters for each library and ignore the points that are not on the precision-performance frontier.
- High-dimensional datasets with approximately 100-1000 dimensions. This is challenging but also realistic. Not more than 1000 dimensions because those problems should probably be solved by doing dimensionality reduction separately.
- Single queries are used by default. ANN-Benchmarks enforces that only one CPU is saturated during experimentation, i.e., no multi-threading. A batch mode is available that provides all queries to the implementations at once. Add the flag
--batchtorun.pyandplot.pyto enable batch mode. - Avoid extremely costly index building (more than several hours).
- Focus on datasets that fit in RAM. Out of core ANN could be the topic of a later comparison.
- We mainly support CPU-based ANN algorithms. GPU support exists for FAISS, but it has to be compiled with GPU support locally and experiments must be run using the flags
--local --batch. - Do proper train/test set of index data and query points.
- Note that set similarity was supported in the past. This might hopefully be added back soon.
Built by Erik Bernhardsson with significant contributions from Martin Aumüller and Alexander Faithfull.
The following publication details design principles behind the benchmarking framework:
- M. Aumüller, E. Bernhardsson, A. Faithfull: ANN-Benchmarks: A Benchmarking Tool for Approximate Nearest Neighbor Algorithms. Information Systems 2019. DOI: 10.1016/j.is.2019.02.006