Batch API for BLS to execution changes #3798
Merged
Conversation
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
ashuralyk
pushed a commit
to synapseweb3/lighthouse
that referenced
this pull request
Apr 23, 2023
* blob production * cargo fix * Add more gossip verification conditions * Added Capella Data Structures to consensus/types (#3637) * Ran Cargo fmt * Added Capella Data Structures to consensus/types * Fixed some stuff in state processing (#3640) * Fixed a ton of state_processing stuff (#3642) FIXME's: * consensus/fork_choice/src/fork_choice.rs * consensus/state_processing/src/per_epoch_processing/capella.rs * consensus/types/src/execution_payload_header.rs TODO's: * consensus/state_processing/src/per_epoch_processing/capella/partial_withdrawals.rs * consensus/state_processing/src/per_epoch_processing/capella/full_withdrawals.rs * Capella eip 4844 cleanup (#3652) * add capella gossip boiler plate * get everything compiling Co-authored-by: realbigsean <[email protected] Co-authored-by: Mark Mackey <[email protected]> * small cleanup * small cleanup * cargo fix + some test cleanup * improve block production * add fixme for potential panic Co-authored-by: Mark Mackey <[email protected]> * Added Capella Epoch Processing Logic (#3666) * clean up types * 48 byte array serde * Couple blocks and blobs in gossip (#3670) * Revert "Add more gossip verification conditions" This reverts commit 1430b561c37adb44d5705005de6bf633deb8c16d. * Revert "Add todos" This reverts commit 91efb9d4c780b55025c3793a67bd9dacc1b2c924. * Revert "Reprocess blob sidecar messages" This reverts commit 21bf3d37cdce46632cfa4e3f5abb194f172c6851. * Add the coupled topic * Decode SignedBeaconBlockAndBlobsSidecar correctly * Process Block and Blobs in beacon processor * Remove extra blob publishing logic from vc * Remove blob signing in vc * Ugly hack to compile * Block processing eip4844 (#3673) * add eip4844 block processing * fix blob processing code * consensus logic fixes and cleanup * use safe arith * merge with unstable fixes * Cleanup payload types (#3675) * Add transparent support * Add `Config` struct * Deprecate `enum_behaviour` * Partially remove enum_behaviour from project * Revert "Partially remove enum_behaviour from project" This reverts commit 46ffb7fe77622cf420f7ba2fccf432c0050535d6. * Revert "Deprecate `enum_behaviour`" This reverts commit 89b64a6f53d0f68685be88d5b60d39799d9933b5. * Add `struct_behaviour` * Tidy * Move tests into `ssz_derive` * Bump ssz derive * Fix comment * newtype transaparent ssz * use ssz transparent and create macros for per fork implementations * use superstruct map macros Co-authored-by: Paul Hauner <[email protected]> * Feature gate withdrawals (#3684) * start feature gating * feature gate withdrawals * Fix compilation error (#3692) * fix topic name * Updated for queueless withdrawals spec * Fixed compiling with withdrawals enabled * Added stuff that NEEDS IMPLEMENTING * BeaconState field renamed * Forgot one feature guard * Added process_withdrawals * Fixes to make EF Capella tests pass (#3719) * Fixes to make EF Capella tests pass * Clippy for state_processing * Fix BlocksByRoot response types (#3743) * Massive Update to Engine API (#3740) * Massive Update to Engine API * Update beacon_node/execution_layer/src/engine_api/json_structures.rs Co-authored-by: Michael Sproul <[email protected]> * Update beacon_node/execution_layer/src/engine_api/json_structures.rs Co-authored-by: Michael Sproul <[email protected]> * Update beacon_node/beacon_chain/src/execution_payload.rs Co-authored-by: realbigsean <[email protected]> * Update beacon_node/execution_layer/src/engine_api.rs Co-authored-by: realbigsean <[email protected]> Co-authored-by: Michael Sproul <[email protected]> Co-authored-by: realbigsean <[email protected]> * - fix pre-merge block production (#3746) - return `None` on pre-4844 blob requests * Stuuupid camelCase (#3748) * Two Capella bugfixes (#3749) * Two Capella bugfixes * fix payload default check in fork choice * Revert "fix payload default check in fork choice" This reverts commit e56fefbd05811526af4499711045275db366aa09. Co-authored-by: realbigsean <[email protected]> * Rename excess blobs and update 4844 json RPC serialization/deserialization (#3745) * rename excess blobs and fix json serialization/deserialization * remove coments * Op pool and gossip for BLS to execution changes (#3726) * Fixed Payload Deserialization in DB (#3758) * Remove withdrawals guard for PayloadAttributesV2 * Fixed some BeaconChain Tests * Refactored Execution Layer & Fixed Some Tests * Fixed Compiler Warnings & Failing Tests (#3771) * Merge 'upstream/unstable' into capella (#3773) * Add API endpoint to count statuses of all validators (#3756) * Delete DB schema migrations for v11 and earlier (#3761) Co-authored-by: Mac L <[email protected]> Co-authored-by: Michael Sproul <[email protected]> * Fixed moar tests (#3774) * Fix some capella nits (#3782) * Fix `Withdrawal` serialisation and check address change fork (#3789) * Disallow address changes before Capella * Quote u64s in Withdrawal serialisation * Fixed Clippy Complaints & Some Failing Tests (#3791) * Fixed Clippy Complaints & Some Failing Tests * Update Dockerfile to Rust-1.65 * EF test file renamed * Touch up comments based on feedback * Fixed Payload Reconstruction Bug (#3796) * Use JsonPayload for payload reconstruction (#3797) * Batch API for address changes (#3798) * Fix Clippy * Publish capella images on push (#3803) * Enable withdrawals features in Capella docker images (#3805) * Bounded withdrawals and spec v1.3.0-alpha.2 (#3802) * Make engine_getPayloadV2 accept local block value * Removed `withdrawals` feature flag * Update consensus/state_processing/src/upgrade/eip4844.rs Co-authored-by: realbigsean <[email protected]> * Update consensus/state_processing/src/upgrade/eip4844.rs Co-authored-by: realbigsean <[email protected]> * Fixed spec serialization bug * Feature Guard V2 Engine API Methods * Fixed Some Tests * Fix clippy complaints * cleanup * Update beacon_node/execution_layer/src/engine_api/json_structures.rs * Update Execution Layer Tests for Capella * Fixed Operation Pool Tests * Fix EF Tests * Fixing Moar Failing Tests * Isolate withdrawals-processing Feature (#3854) * Added bls_to_execution_changes to PersistedOpPool (#3857) * Added bls_to_execution_changes to PersistedOpPool * Bump MSRV to 1.65 (#3860) * add historical summaries (#3865) * add historical summaries * fix tree hash caching, disable the sanity slots test with fake crypto * add ssz static HistoricalSummary * only store historical summaries after capella * Teach `UpdatePattern` about Capella * Tidy EF tests * Clippy Co-authored-by: Michael Sproul <[email protected]> * Remove `withdrawals-processing` feature (#3864) * Use spec to Determine Supported Engine APIs * Remove `withdrawals-processing` feature * Fixed Tests * Missed Some Spots * Fixed Another Test * Stupid Clippy * Fix Arbitrary implementations (#3867) * Fix Arbitrary implementations * Remove remaining vestiges of arbitrary-fuzz * Remove FIXME * Clippy * Fix some beacon_chain tests * Verify blockHash with withdrawals * Sign BlsToExecutionChange w/ GENESIS_FORK_VERSION * Don't Penalize Early `bls_to_execution_change` * Update gossip_methods.rs * bump ef-tests * intentionally skip `LightClientHeader` ssz static tests * CL-EL withdrawals harmonization using Gwei units (#3884) * Update checkpoint-sync.md (#3831) Remove infura checkpoint sync instructions. Co-authored-by: Adam Patacchiola <[email protected]> * Return HTTP 404 rather than 405 (#3836) ## Issue Addressed Issue #3112 ## Proposed Changes Add `Filter::recover` to the GET chain to handle rejections specifically as 404 NOT FOUND ## Additional Info Making a request to `http://localhost:5052/not_real` now returns the following: ``` { "code": 404, "message": "NOT_FOUND", "stacktraces": [] } ``` Co-authored-by: Paul Hauner <[email protected]> * Add CLI flag to specify the format of logs written to the logfile (#3839) ## Proposed Changes Decouple the stdout and logfile formats by adding the `--logfile-format` CLI flag. This behaves identically to the existing `--log-format` flag, but instead will only affect the logs written to the logfile. The `--log-format` flag will no longer have any effect on the contents of the logfile. ## Additional Info This avoids being a breaking change by causing `logfile-format` to default to the value of `--log-format` if it is not provided. This means that users who were previously relying on being able to use a JSON formatted logfile will be able to continue to use `--log-format JSON`. Users who want to use JSON on stdout and default logs in the logfile, will need to pass the following flags: `--log-format JSON --logfile-format DEFAULT` * add better err reporting UnableToOpenVotingKeystore (#3781) ## Issue Addressed #3780 ## Proposed Changes Add error reporting that notifies the node operator that the `voting_keystore_path` in their `validator_definitions.yml` file may be incorrect. ## Additional Info There is more info in issue #3780 Co-authored-by: Paul Hauner <[email protected]> * add logging for starting request and receiving block (#3858) ## Issue Addressed #3853 ## Proposed Changes Added `INFO` level logs for requesting and receiving the unsigned block. ## Additional Info Logging for successfully publishing the signed block is already there. And seemingly there is a log for when "We realize we are going to produce a block" in the `start_update_service`: `info!(log, "Block production service started"); `. Is there anywhere else you'd like to see logging around this event? Co-authored-by: GeemoCandama <[email protected]> * Fix some dead links in markdown files (#3885) ## Issue Addressed No issue has been raised for these broken links. ## Proposed Changes Update links with the new URLs for the same document. ## Additional Info ~The link for the [Lighthouse Development Updates](https://eepurl.com/dh9Lvb/) mailing list is also broken, but I can't find the correct link.~ Co-authored-by: Paul Hauner <[email protected]> * Update engine_api to Latest spec (#3893) * Update engine_api to Latest spec * Small Test Fix * Fix Test Deserialization Issue * update antithesis dockerfile (#3883) Resolves https://github.com/sigp/lighthouse/issues/3879 Co-authored-by: realbigsean <[email protected]> * Improve block delay metrics (#3894) We recently ran a large-block experiment on the testnet and plan to do a further experiment on mainnet. Although the metrics recovered from lighthouse nodes were quite useful, I think we could do with greater resolution in the block delay metrics and get some specific values for each block (currently these can be lost to large exponential histogram buckets). This PR increases the resolution of the block delay histogram buckets, but also introduces a new metric which records the last block delay. Depending on the polling resolution of the metric server, we can lose some block delay information, however it will always give us a specific value and we will not lose exact data based on poor resolution histogram buckets. * Switch allocator to jemalloc (#3697) ## Proposed Changes Another `tree-states` motivated PR, this adds `jemalloc` as the default allocator, with an option to use the system allocator by compiling with `FEATURES="" make`. - [x] Metrics - [x] Test on Windows - [x] Test on macOS - [x] Test with `musl` - [x] Metrics dashboard on `lighthouse-metrics` (https://github.com/sigp/lighthouse-metrics/pull/37) Co-authored-by: Michael Sproul <[email protected]> * fix multiarch docker builds (#3904) ## Issue Addressed #3902 Tested and confirmed working [here](https://github.com/antondlr/lighthouse/actions/runs/3970418322) ## Additional Info buildx v0.10.0 added provenance attestations to images but they are packed in a way that's incompatible with `docker manifest` https://github.com/docker/buildx/releases * Import BLS to execution changes before Capella (#3892) * Import BLS to execution changes before Capella * Test for BLS to execution change HTTP API * Pack BLS to execution changes in LIFO order * Remove unused var * Clippy * Implement sync_committee_rewards API (per-validator reward) (#3903) ## Issue Addressed [#3661](https://github.com/sigp/lighthouse/issues/3661) ## Proposed Changes `/eth/v1/beacon/rewards/sync_committee/{block_id}` ``` { "execution_optimistic": false, "finalized": false, "data": [ { "validator_index": "0", "reward": "2000" } ] } ``` The issue contains the implementation of three per-validator reward APIs: * `sync_committee_rewards` * [`attestation_rewards`](https://github.com/sigp/lighthouse/pull/3822) * `block_rewards` This PR only implements the `sync_committe_rewards `. The endpoints can be viewed in the Ethereum Beacon nodes API browser: [https://ethereum.github.io/beacon-APIs/?urls.primaryName=dev#/Rewards](https://ethereum.github.io/beacon-APIs/?urls.primaryName=dev#/Rewards) ## Additional Info The implementation of [consensus client reward APIs](https://github.com/eth-protocol-fellows/cohort-three/blob/master/projects/project-ideas.md#consensus-client-reward-apis) is part of the [EPF](https://github.com/eth-protocol-fellows/cohort-three). Co-authored-by: navie <[email protected]> Co-authored-by: kevinbogner <[email protected]> * Use eth1_withdrawal_credentials in Test States (#3898) * Use eth1_withdrawal_credential in Some Test States * Update beacon_node/genesis/src/interop.rs Co-authored-by: Michael Sproul <[email protected]> * Update beacon_node/genesis/src/interop.rs Co-authored-by: Michael Sproul <[email protected]> * Increase validator sizes * Pick next sync committee message Co-authored-by: Michael Sproul <[email protected]> Co-authored-by: Paul Hauner <[email protected]> * light client optimistic update reprocessing (#3799) ## Issue Addressed Currently there is a race between receiving blocks and receiving light client optimistic updates (in unstable), which results in processing errors. This is a continuation of PR #3693 and seeks to progress on issue #3651 ## Proposed Changes Add the parent_root to ReprocessQueueMessage::BlockImported so we can remove blocks from queue when a block arrives that has the same parent root. We use the parent root as opposed to the block_root because the LightClientOptimisticUpdate does not contain the block_root. If light_client_optimistic_update.attested_header.canonical_root() != head_block.message().parent_root() then we queue the update. Otherwise we process immediately. ## Additional Info michaelsproul came up with this idea. The code was heavily based off of the attestation reprocessing. I have not properly tested this to see if it works as intended. * Fix docs for `oldest_block_slot` (#3911) ## Proposed Changes Update the docs to correct the description of `oldest_block_slot`. Credit to `laern` on Discord for noticing this. * Update sync rewards API for abstract exec payload * Fix the new BLS to execution change test * Update another test broken by the shuffling change * Clippy 1.67 (#3916) ## Proposed Changes Clippy 1.67.0 put us on blast for the size of some of our errors, most of them written by me ( :eyes: ). This PR shrinks the size of `BeaconChainError` by dropping some extraneous info and boxing an inner error which should only occur infrequently anyway. For the `AttestationSlashInfo` and `BlockSlashInfo` I opted to ignore the lint as they are always used in a `Result<A, Info>` where `A` is a similar size. This means they don't bloat the size of the `Result`, so it's a bit annoying for Clippy to report this as an issue. I also chose to ignore `clippy::uninlined-format-args` because I think the benefit-to-churn ratio is too low. E.g. sometimes we have long identifiers in `format!` args and IMO the non-inlined form is easier to read: ```rust // I prefer this... format!( "{} did {} to {}", REALLY_LONG_CONSTANT_NAME, ANOTHER_REALLY_LONG_CONSTANT_NAME, regular_long_identifier_name ); // To this format!("{REALLY_LONG_CONSTANT_NAME} did {ANOTHER_REALLY_LONG_CONSTANT_NAME} to {regular_long_identifier_name}"); ``` I tried generating an automatic diff with `cargo clippy --fix` but it came out at: ``` 250 files changed, 1209 insertions(+), 1469 deletions(-) ``` Which seems like a bad idea when we'd have to back-merge it to `capella` and `eip4844` :scream: * exchangeCapabilities & Capella Readiness Logging (#3918) * Undo Passing Spec to Engine API * Utilize engine_exchangeCapabilities * Add Logging to Indicate Capella Readiness * Add exchangeCapabilities to mock_execution_layer * Send Nested Array for engine_exchangeCapabilities * Use Mutex Instead of RwLock for EngineCapabilities * Improve Locking to Avoid Deadlock * Prettier logic for get_engine_capabilities * Improve Comments * Update beacon_node/beacon_chain/src/capella_readiness.rs Co-authored-by: Michael Sproul <[email protected]> * Update beacon_node/beacon_chain/src/capella_readiness.rs Co-authored-by: Michael Sproul <[email protected]> * Update beacon_node/beacon_chain/src/capella_readiness.rs Co-authored-by: Michael Sproul <[email protected]> * Update beacon_node/beacon_chain/src/capella_readiness.rs Co-authored-by: Michael Sproul <[email protected]> * Update beacon_node/beacon_chain/src/capella_readiness.rs Co-authored-by: Michael Sproul <[email protected]> * Update beacon_node/client/src/notifier.rs Co-authored-by: Michael Sproul <[email protected]> * Update beacon_node/execution_layer/src/engine_api/http.rs Co-authored-by: Michael Sproul <[email protected]> * Addressed Michael's Comments --------- Co-authored-by: Michael Sproul <[email protected]> * Use Local Payload if More Profitable than Builder (#3934) * Use Local Payload if More Profitable than Builder * Rename clone -> clone_from_ref * Minimize Clones of GetPayloadResponse * Cleanup & Fix Tests * Added Tests for Payload Choice by Profit * Fix Outdated Comments * Don't Reject all Builder Bids After Capella (#3940) * Fix bug in Builder API Post-Capella * Fix Clippy Complaints * Unpin fixed-hash (#3917) ## Proposed Changes Remove the `[patch]` for `fixed-hash`. We pinned it years ago in #2710 to fix `arbitrary` support. Nowadays the 0.7 version of `fixed-hash` is only used by the `web3` crate and doesn't need `arbitrary`. ~~Blocked on #3916 but could be merged in the same Bors batch.~~ * Implement `attestation_rewards` API (per-validator reward) (#3822) ## Issue Addressed #3661 ## Proposed Changes `/eth/v1/beacon/rewards/attestations/{epoch}` ```json { "execution_optimistic": false, "finalized": false, "data": [ { "ideal_rewards": [ { "effective_balance": "1000000000", "head": "2500", "target": "5000", "source": "5000" } ], "total_rewards": [ { "validator_index": "0", "head": "2000", "target": "2000", "source": "4000", "inclusion_delay": "2000" } ] } ] } ``` The issue contains the implementation of three per-validator reward APIs: - [`sync_committee_rewards`](https://github.com/sigp/lighthouse/pull/3790) - `attestation_rewards` - `block_rewards`. This PR *only* implements the `attestation_rewards`. The endpoints can be viewed in the Ethereum Beacon nodes API browser: https://ethereum.github.io/beacon-APIs/?urls.primaryName=dev#/Rewards ## Additional Info The implementation of [consensus client reward APIs](https://github.com/eth-protocol-fellows/cohort-three/blob/master/projects/project-ideas.md#consensus-client-reward-apis) is part of the [EPF](https://github.com/eth-protocol-fellows/cohort-three). --- - [x] `get_state` - [x] Calculate *ideal rewards* with some logic from `get_flag_index_deltas` - [x] Calculate *actual rewards* with some logic from `get_flag_index_deltas` - [x] Code cleanup - [x] Testing * Remove unused `u256_hex_be_opt` (#3942) * Broadcast address changes at Capella (#3919) * Add first efforts at broadcast * Tidy * Move broadcast code to client * Progress with broadcast impl * Rename to address change * Fix compile errors * Use `while` loop * Tidy * Flip broadcast condition * Switch to forgetting individual indices * Always broadcast when the node starts * Refactor into two functions * Add testing * Add another test * Tidy, add more testing * Tidy * Add test, rename enum * Rename enum again * Tidy * Break loop early * Add V15 schema migration * Bump schema version * Progress with migration * Update beacon_node/client/src/address_change_broadcast.rs Co-authored-by: Michael Sproul <[email protected]> * Fix typo in function name --------- Co-authored-by: Michael Sproul <[email protected]> * Implement block_rewards API (per-validator reward) (#3907) ## Issue Addressed [#3661](https://github.com/sigp/lighthouse/issues/3661) ## Proposed Changes `/eth/v1/beacon/rewards/blocks/{block_id}` ``` { "execution_optimistic": false, "finalized": false, "data": { "proposer_index": "123", "total": "123", "attestations": "123", "sync_aggregate": "123", "proposer_slashings": "123", "attester_slashings": "123" } } ``` The issue contains the implementation of three per-validator reward APIs: * `sync_committee_rewards` * [`attestation_rewards`](https://github.com/sigp/lighthouse/pull/3822) * `block_rewards` This PR only implements the `block_rewards`. The endpoints can be viewed in the Ethereum Beacon nodes API browser: [https://ethereum.github.io/beacon-APIs/?urls.primaryName=dev#/Rewards](https://ethereum.github.io/beacon-APIs/?urls.primaryName=dev#/Rewards) ## Additional Info The implementation of [consensus client reward APIs](https://github.com/eth-protocol-fellows/cohort-three/blob/master/projects/project-ideas.md#consensus-client-reward-apis) is part of the [EPF](https://github.com/eth-protocol-fellows/cohort-three). Co-authored-by: kevinbogner <[email protected]> Co-authored-by: navie <[email protected]> * Update the docker build to include features based images (#3875) ## Proposed Changes There are some features that are enabled/disabled with the `FEATURES` env variable. This PR would introduce a pattern to introduce docker images based on those features. This can be useful later on to have specific images for some experimental features in the future. ## Additional Info We at Lodesart need to have `minimal` spec support for some cross-client network testing. To make it efficient on the CI, we tend to use minimal preset. * Self rate limiting dev flag (#3928) ## Issue Addressed Adds self rate limiting options, mainly with the idea to comply with peer's rate limits in small testnets ## Proposed Changes Add a hidden flag `self-limiter` this can take no value, or customs values to configure quotas per protocol ## Additional Info ### How to use `--self-limiter` will turn on the self rate limiter applying the same params we apply to inbound requests (requests from other peers) `--self-limiter "beacon_blocks_by_range:64/1"` will turn on the self rate limiter for ALL protocols, but change the quota for bbrange to 64 requested blocks per 1 second. `--self-limiter "beacon_blocks_by_range:64/1;ping:1/10"` same as previous one, changing the quota for ping as well. ### Caveats - The rate limiter is either on or off for all protocols. I added the custom values to be able to change the quotas per protocol so that some protocols can be given extremely loose or tight quotas. I think this should satisfy every need even if we can't technically turn off rate limits per protocol. - This reuses the rate limiter struct for the inbound requests so there is this ugly part of the code in which we need to deal with the inbound only protocols (light client stuff) if this becomes too ugly as we add lc protocols, we might want to split the rate limiters. I've checked this and looks doable with const generics to avoid so much code duplication ### Knowing if this is on ``` Feb 06 21:12:05.493 DEBG Using self rate limiting params config: OutboundRateLimiterConfig { ping: 2/10s, metadata: 1/15s, status: 5/15s, goodbye: 1/10s, blocks_by_range: 1024/10s, blocks_by_root: 128/10s }, service: libp2p_rpc, service: libp2p ``` * Update dependencies (#3946) ## Issue Addressed Resolves the cargo-audit failure caused by https://rustsec.org/advisories/RUSTSEC-2023-0010. I also removed the ignore for `RUSTSEC-2020-0159` as we are no longer using a vulnerable version of `chrono`. We still need the other ignore for `time 0.1` because we depend on it via `sloggers -> chrono -> time 0.1`. * Fix the whitespace in docker workflow (#3952) ## Issue Addressed Fix a whitespace issue that was causing failure in the docker build. ## Additional Info https://github.com/sigp/lighthouse/pull/3948 * Remove participation rate from API docs (#3955) ## Issue Addressed NA ## Proposed Changes Removes the "Participation Rate" since it references an undefined variable: `previous_epoch_attesting_gwei`. I didn't replace it with anything since I think "Justification/Finalization Rate" already expresses what it was trying to express. ## Additional Info NA * Add attestation duty slot metric (#2704) ## Issue Addressed Resolves #2521 ## Proposed Changes Add a metric that indicates the next attestation duty slot for all managed validators in the validator client. * Fix edge-case when finding the finalized descendant (#3924) ## Issue Addressed NA ## Description We were missing an edge case when checking to see if a block is a descendant of the finalized checkpoint. This edge case is described for one of the tests in this PR: https://github.com/sigp/lighthouse/blob/a119edc739e9dcefe1cb800a2ce9eb4baab55f20/consensus/proto_array/src/proto_array_fork_choice.rs#L1018-L1047 This bug presented itself in the following mainnet log: ``` Jan 26 15:12:42.841 ERRO Unable to validate attestation error: MissingBeaconState(0x7c30cb80ec3d4ec624133abfa70e4c6cfecfca456bfbbbff3393e14e5b20bf25), peer_id: 16Uiu2HAm8RPRciXJYtYc5c3qtCRdrZwkHn2BXN3XP1nSi1gxHYit, type: "unaggregated", slot: Slot(5660161), beacon_block_root: 0x4a45e59da7cb9487f4836c83bdd1b741b4f31c67010c7ae343fa6771b3330489 ``` Here the BN is rejecting an attestation because of a "missing beacon state". Whilst it was correct to reject the attestation, it should have rejected it because it attests to a block that conflicts with finality rather than claiming that the database is inconsistent. The block that this attestation points to (`0x4a45`) is block `C` in the above diagram. It is a non-canonical block in the first slot of an epoch that conflicts with the finalized checkpoint. Due to our lazy pruning of proto array, `0x4a45` was still present in proto-array. Our missed edge-case in [`ForkChoice::is_descendant_of_finalized`](https://github.com/sigp/lighthouse/blob/38514c07f222ff7783834c48cf5c0a6ee7f346d0/consensus/fork_choice/src/fork_choice.rs#L1375-L1379) would have indicated to us that the block is a descendant of the finalized block. Therefore, we would have accepted the attestation thinking that it attests to a descendant of the finalized *checkpoint*. Since we didn't have the shuffling for this erroneously processed block, we attempted to read its state from the database. This failed because we prune states from the database by keeping track of the tips of the chain and iterating back until we find a finalized block. This would have deleted `C` from the database, hence the `MissingBeaconState` error. * Tweaks to reward APIs (#3957) ## Proposed Changes * Return the effective balance in gwei to align with the spec ([ideal attestation rewards](https://ethereum.github.io/beacon-APIs/?urls.primaryName=dev#/Rewards/getAttestationsRewards)). * Use quoted `i64`s for attestation and sync committee rewards. * Properly Deserialize ForkVersionedResponses (#3944) * Move ForkVersionedResponse to consensus/types * Properly Deserialize ForkVersionedResponses * Elide Types in from_value Calls * Added Tests for ForkVersionedResponse Deserialize * Address Sean's Comments & Make Less Restrictive * Utilize `map_fork_name!` * Update Mock Builder for Post-Capella Tests (#3958) * Update Mock Builder for Post-Capella Tests * Add _mut Suffix to BidStuff Functions * Fix Setting Gas Limit * Use release profile for Windows binaries (#3965) ## Proposed Changes Disable `maxperf` profile on Windows due to #3964. This is required for the v3.5.0 release CI to succeed without crashing. * Reduce some EE and builder related ERRO logs to WARN (#3966) ## Issue Addressed NA ## Proposed Changes Our `ERRO` stream has been rather noisy since the merge due to some unexpected behaviours of builders and EEs. Now that we've been running post-merge for a while, I think we can drop some of these `ERRO` to `WARN` so we're not "crying wolf". The modified logs are: #### `ERRO Execution engine call failed` I'm seeing this quite frequently on Geth nodes. They seem to timeout when they're busy and it rarely indicates a serious issue. We also have logging across block import, fork choice updating and payload production that raise `ERRO` or `CRIT` when the EE times out, so I think we're not at risk of silencing actual issues. #### `ERRO "Builder failed to reveal payload"` In #3775 we reduced this log from `CRIT` to `ERRO` since it's common for builders to fail to reveal the block to the producer directly whilst still broadcasting it to the networ. I think it's worth dropping this to `WARN` since it's rarely interesting. I elected to stay with `WARN` since I really do wish builders would fulfill their API promises by returning the block to us. Perhaps I'm just being pedantic here, I could be convinced otherwise. #### `ERRO "Relay error when registering validator(s)"` It seems like builders and/or mev-boost struggle to handle heavy loads of validator registrations. I haven't observed issues with validators not actually being registered, but I see timeouts on these endpoints many times a day. It doesn't seem like this `ERRO` is worth it. #### `ERRO Error fetching block for peer ExecutionLayerErrorPayloadReconstruction` This means we failed to respond to a peer on the P2P network with a block they requested because of an error in the `execution_layer`. It's very common to see timeouts or incomplete responses on this endpoint whilst the EE is busy and I don't think it's important enough for an `ERRO`. As long as the peer count stays high, I don't think the user needs to be actively concerned about how we're responding to peers. ## Additional Info NA * Fix regression in DB write atomicity (#3931) ## Issue Addressed Fix a bug introduced by #3696. The bug is not expected to occur frequently, so releasing this PR is non-urgent. ## Proposed Changes * Add a variant to `StoreOp` that allows a raw KV operation to be passed around. * Return to using `self.store.do_atomically` rather than `self.store.hot_db.do_atomically`. This streamlines the write back into a single call and makes our auto-revert work again. * Prevent `import_block_update_shuffling_cache` from failing block import. This is an outstanding bug from before v3.4.0 which may have contributed to some random unexplained database corruption. ## Additional Info In #3696 I split the database write into two calls, one to convert the `StoreOp`s to `KeyValueStoreOp`s and one to write them. This had the unfortunate side-effect of damaging our atomicity guarantees in case of a write error. If the first call failed, we would be left with the block in fork choice but not on-disk (or the snapshot cache), which would prevent us from processing any descendant blocks. On `unstable` the first call is very unlikely to fail unless the disk is full, but on `tree-states` the conversion is more involved and a user reported database corruption after it failed in a way that should have been recoverable. Additionally, as @emhane observed, #3696 also inadvertently removed the import of the new block into the block cache. Although this seems like it could have negatively impacted performance, there are several mitigating factors: - For regular block processing we should almost always load the parent block (and state) from the snapshot cache. - We often load blinded blocks, which bypass the block cache anyway. - Metrics show no noticeable increase in the block cache miss rate with v3.4.0. However, I expect the block cache _will_ be useful again in `tree-states`, so it is restored to use by this PR. * Invalid cross build feature flag (#3959) ## Issue Addressed The documentation referring to build from source mismatches with the what gitworkflow uses. https://github.com/sigp/lighthouse/blob/aa5b7ef7839e15d55c3a252230ecb11c4abc0a52/book/src/installation-source.md?plain=1#L118-L120 ## Proposed Changes Because the github workflow uses `cross` to build from source and for that build there is different env variable `CROSS_FEATURES` so need pass at the compile time. ## Additional Info Verified that existing `-dev` builds does not contains the `minimal` spec enabled. ```bash > docker run --rm --name node-5-cl-lighthouse sigp/lighthouse:latest-amd64-unstable-dev lighthouse --version Lighthouse v3.4.0-aa5b7ef BLS library: blst-portable SHA256 hardware acceleration: true Allocator: jemalloc Specs: mainnet (true), minimal (false), gnosis (true) ``` * Placeholder for BlobsByRange outbound rate limit * Update block rewards API for Capella * Enforce a timeout on peer disconnect (#3757) On heavily crowded networks, we are seeing many attempted connections to our node every second. Often these connections come from peers that have just been disconnected. This can be for a number of reasons including: - We have deemed them to be not as useful as other peers - They have performed poorly - They have dropped the connection with us - The connection was spontaneously lost - They were randomly removed because we have too many peers In all of these cases, if we have reached or exceeded our target peer limit, there is no desire to accept new connections immediately after the disconnect from these peers. In fact, it often costs us resources to handle the established connections and defeats some of the logic of dropping them in the first place. This PR adds a timeout, that prevents recently disconnected peers from reconnecting to us. Technically we implement a ban at the swarm layer to prevent immediate re connections for at least 10 minutes. I decided to keep this light, and use a time-based LRUCache which only gets updated during the peer manager heartbeat to prevent added stress of polling a delay map for what could be a large number of peers. This cache is bounded in time. An extra space bound could be added should people consider this a risk. Co-authored-by: Diva M <[email protected]> * Quote Capella BeaconState fields (#3967) * Simplify payload traits and reduce cloning (#3976) * Simplify payload traits and reduce cloning * Fix self limiter * Fix docker and deps (#3978) ## Proposed Changes - Fix this cargo-audit failure for `sqlite3-sys`: https://github.com/sigp/lighthouse/actions/runs/4179008889/jobs/7238473962 - Prevent the Docker builds from running out of RAM on CI by removing `gnosis` and LMDB support from the `-dev` images (see: https://github.com/sigp/lighthouse/pull/3959#issuecomment-1430531155, successful run on my fork: https://github.com/michaelsproul/lighthouse/actions/runs/4179162480/jobs/7239537947). * Execution engine suggestions from code review Co-authored-by: Paul Hauner <[email protected]> * blacklist tests in windows (#3961) ## Issue Addressed Windows tests for subscription and unsubscriptions fail in CI sporadically. We usually ignore this failures, so this PR aims to help reduce the failure noise. Associated issue is https://github.com/sigp/lighthouse/issues/3960 * Improve testing slot clock to allow manipulation of time in tests (#3974) ## Issue Addressed I discovered this issue while implementing [this test](https://github.com/jimmygchen/lighthouse/blob/test-example/beacon_node/network/src/beacon_processor/tests.rs#L895), where I tried to manipulate the slot clock with: `rig.chain.slot_clock.set_current_time(duration);` however the change doesn't get reflected in the `slot_clock` in `ReprocessQueue`, and I realised `slot_clock` was cloned a few times in the code, and therefore changing the time in `rig.chain.slot_clock` doesn't have any effect in `ReprocessQueue`. I've incorporated the suggestion from the @paulhauner and @michaelsproul - wrapping the `ManualSlotClock.current_time` (`RwLock<Duration>)` in an `Arc`, and the above test now passes. Let's see if this breaks any existing tests :) * Fix exec integration tests for Geth v1.11.0 (#3982) ## Proposed Changes * Bump Go from 1.17 to 1.20. The latest Geth release v1.11.0 requires 1.18 minimum. * Prevent a cache miss during payload building by using the right fee recipient. This prevents Geth v1.11.0 from building a block with 0 transactions. The payload building mechanism is overhauled in the new Geth to improve the payload every 2s, and the tests were failing because we were falling back on a `getPayload` call with no lookahead due to `get_payload_id` cache miss caused by the mismatched fee recipient. Alternatively we could hack the tests to send `proposer_preparation_data`, but I think the static fee recipient is simpler for now. * Add support for optionally enabling Lighthouse logs in the integration tests. Enable using `cargo run --release --features logging/test_logger`. This was very useful for debugging. * Suggestions for Capella `execution_layer` (#3983) * Restrict Engine::request to FnOnce * Use `Into::into` * Impl IntoIterator for VariableList * Use Instant rather than SystemTime * Add capella fork epoch (#3997) * Fix Capella schema downgrades (#4004) * Remove "eip4844" network (#4008) * Suggestions for Capella `beacon_chain` (#3999) * Remove CapellaReadiness::NotSynced Some EEs have a habit of flipping between synced/not-synced, which causes some spurious "Not read for the merge" messages back before the merge. For the merge, if the EE wasn't synced the CE simple wouldn't go through the transition (due to optimistic sync stuff). However, we don't have that hard requirement for Capella; the CE will go through the fork and just wait for the EE to catch up. I think that removing `NotSynced` here will avoid false-positives on the "Not ready logs..". We'll be creating other WARN/ERRO logs if the EE isn't synced, anyway. * Change some Capella readiness logging There's two changes here: 1. Shorten the log messages, for readability. 2. Change the hints. Connecting a Capella-ready LH to a non-Capella-ready EE gives this log: ``` WARN Not ready for Capella info: The execution endpoint does not appear to support the required engine api methods for Capella: Required Methods Unsupported: engine_getPayloadV2 engine_forkchoiceUpdatedV2 engine_newPayloadV2, service: slot_notifier ``` This variant of error doesn't get a "try updating" style hint, when it's the one that needs it. This is because we detect the method-not-found reponse from the EE and return default capabilities, rather than indicating that the request fails. I think it's fair to say that an EE upgrade is required whenever it doesn't provide the required methods. I changed the `ExchangeCapabilitiesFailed` message since that can only happen when the EE fails to respond with anything other than success or not-found. * Capella consensus review (#4012) * Add extra encoding/decoding tests * Remove TODO The method LGTM * Remove `FreeAttestation` This is an ancient relic, I'm surprised it still existed! * Add paranoid check for eip4844 code This is not technically necessary, but I think it's nice to be explicit about EIP4844 consensus code for the time being. * Reduce big-O complexity of address change pruning I'm not sure this is *actually* useful, but it might come in handy if we see a ton of address changes at the fork boundary. I know the devops team have been testing with ~100k changes, so maybe this will help in that case. * Revert "Reduce big-O complexity of address change pruning" This reverts commit e7d93e6cc7cf1b92dd5a9e1966ce47d4078121eb. * Revert Sepolia genesis change (#4013) * Allow for withdrawals in max block size (#4011) * Allow for withdrawals in max block size * Ensure payload size is counted * Fix post-Bellatrix checkpoint sync (#4014) * Recognise execution in post-merge blocks * Remove `.body()` * Fix typo * Use `is_default_with_empty_roots`. * Modify some Capella comments (#4015) * Modify comment to only include 4844 Capella only modifies per epoch processing by adding `process_historical_summaries_update`, which does not change the realization of justification or finality. Whilst 4844 does not currently modify realization, the spec is not yet final enough to say that it never will. * Clarify address change verification comment The verification of the address change doesn't really have anything to do with the current epoch. I think this was just a copy-paste from a function like `verify_exit`. * Cache validator balances and allow them to be served over the HTTP API (#3863) ## Issue Addressed #3804 ## Proposed Changes - Add `total_balance` to the validator monitor and adjust the number of historical epochs which are cached. - Allow certain values in the cache to be served out via the HTTP API without requiring a state read. ## Usage ``` curl -X POST "http://localhost:5052/lighthouse/ui/validator_info" -d '{"indices": [0]}' -H "Content-Type: application/json" | jq ``` ``` { "data": { "validators": { "0": { "info": [ { "epoch": 172981, "total_balance": 36566388519 }, ... { "epoch": 172990, "total_balance": 36566496513 } ] }, "1": { "info": [ { "epoch": 172981, "total_balance": 36355797968 }, ... { "epoch": 172990, "total_balance": 36355905962 } ] } } } } ``` ## Additional Info This requires no historical states to operate which mean it will still function on the freshly checkpoint synced node, however because of this, the values will populate each epoch (up to a maximum of 10 entries). Another benefit of this method, is that we can easily cache any other values which would normally require a state read and serve them via the same endpoint. However, we would need be cautious about not overly increasing block processing time by caching values from complex computations. This also caches some of the validator metrics directly, rather than pulling them from the Prometheus metrics when the API is called. This means when the validator count exceeds the individual monitor threshold, the cached values will still be available. Co-authored-by: Paul Hauner <[email protected]> * Disable debug info on CI (#4018) ## Issue Addressed Closes #4005 Alternative to #4017 ## Proposed Changes Disable debug info on CI to save RAM and disk space. * Remove BeaconBlockAndBlobsSidecar from core topics (#4016) * Fix metric (#4020) * Fix doppelganger script (#3988) ## Issue Addressed N/A ## Proposed Changes The doppelganger tests were failing silently since the `PROPOSER_BOOST` config was not set. Sets the config and script returns an error if any subprocess fails. * Register disconnected peers when temporarily banned (#4001) This is a correction to #3757. The correction registers a peer that is being disconnected in the local peer manager db to ensure we are tracking the correct state. * v3.5.0 (#3996) ## Issue Addressed NA ## Proposed Changes - Bump versions ## Sepolia Capella Upgrade This release will enable the Capella fork on Sepolia. We are planning to publish this release on the 23rd of Feb 2023. Users who can build from source and wish to do pre-release testing can use this branch. ## Additional Info - [ ] Requires further testing * Execution Integration Tests Correction (#4034) The execution integration tests are currently failing. This is a quick modification to pin the execution client version to correct the tests. * Allow compilation with no slasher backend (#3888) ## Proposed Changes Allowing compiling without MDBX by running: ```bash CARGO_INSTALL_EXTRA_FLAGS="--no-default-features" make ``` The reasons to do this are several: - Save compilation time if the slasher won't be used - Work around compilation errors in slasher backend dependencies (our pinned version of MDBX is currently not compiling on FreeBSD with certain compiler versions). ## Additional Info When I opened this PR we were using resolver v1 which [doesn't disable default features in dependencies](https://doc.rust-lang.org/cargo/reference/features.html#resolver-version-2-command-line-flags), and `mdbx` is default for the `slasher` crate. Even after the resolver got changed to v2 in #3697 compiling with `--no-default-features` _still_ wasn't turning off the slasher crate's default features, so I added `default-features = false` in all the places we depend on it. Co-authored-by: Michael Sproul <[email protected]> * Add content-type header to metrics server response (#3970) This fixes issues with certain metrics scrapers, which might error if the content-type is not correctly set. ## Issue Addressed Fixes https://github.com/sigp/lighthouse/issues/3437 ## Proposed Changes Simply set header: `Content-Type: text/plain` on metrics server response. Seems like the errored branch does this correctly already. ## Additional Info This is needed also to enable influx-db metric scraping which work very nicely with Geth. * Use consensus-spec-tests `v1.3.0-rc.3` (#4021) ## Issue Addressed NA ## Proposed Changes Updates our `ef_tests` to use: https://github.com/ethereum/consensus-specs/releases/tag/v1.3.0-rc.3 This required: - Skipping a `merkle_proof_validity` test (see #4022) - Account for the `eip4844` tests changing name to `deneb` - My IDE did some Python linting during this change. It seemed simple and nice so I left it there. ## Additional Info NA * Docs for Siren (#4023) This adds some documentation for the Siren app into the Lighthouse book. Co-authored-by: Mavrik <[email protected]> * Add more logs in the BN HTTP API during block production (#4025) ## Issue Addressed NA ## Proposed Changes Adds two new `DEBG` logs to the HTTP API: 1. As soon as we are requested to produce a block. 2. As soon as a signed block is received. In #3858 we added some very helpful logs to the VC so we could see when things are happening with block proposals in the VC. After doing some more debugging, I found that I can tell when the VC is sending a block but I *can't* tell the time that the BN receives it (I can only get the time after the BN has started doing some work with the block). Knowing when the VC published and as soon as the BN receives is useful for determining the delays introduced by network latency (and some other things like JSON decoding, etc). ## Additional Info NA * Clean capella (#4019) ## Issue Addressed Cleans up all the remnants of 4844 in capella. This makes sure when 4844 is reviewed there is nothing we are missing because it got included here ## Proposed Changes drop a bomb on every 4844 thing ## Additional Info Merge process I did (locally) is as follows: - squash merge to produce one commit - in new branch off unstable with the squashed commit create a `git revert HEAD` commit - merge that new branch onto 4844 with `--strategy ours` - compare local 4844 to remote 4844 and make sure the diff is empty - enjoy Co-authored-by: Paul Hauner <[email protected]> * Delete Kiln and Ropsten configs (#4038) ## Proposed Changes Remove built-in support for Ropsten and Kiln via the `--network` flag. Both testnets are long dead and deprecated. This shaves about 30MiB off the binary size, from 135MiB to 103MiB (maxperf), or 165MiB to 135MiB (release). * Cleaner logic for gossip subscriptions for new forks (#4030) ## Issue Addressed Cleaner resolution for #4006 ## Proposed Changes We are currently subscribing to core topics of new forks way before the actual fork since we had just a single `CORE_TOPICS` array. This PR separates the core topics for every fork and subscribes to only required topics based on the current fork. Also adds logic for subscribing to the core topics of a new fork only 2 slots before the fork happens. 2 slots is to give enough time for the gossip meshes to form. Currently doesn't add logic to remove topics from older forks in new forks. For e.g. in the coupled 4844 world, we had to remove the `BeaconBlock` topic in favour of `BeaconBlocksAndBlobsSidecar` at the 4844 fork. It should be easy enough to add though. Not adding it because I'm assuming that #4019 will get merged before this PR and we won't require any deletion logic. Happy to add it regardless though. * Log a debug message when a request fails for a beacon node candidate (#4036) ## Issue Addressed #3985 ## Proposed Changes Log a debug message when a BN candidate returns an error. `Mar 01 16:40:24.011 DEBG Request to beacon node failed error: ServerMessage(ErrorMessage { code: 503, message: "SERVICE_UNAVAILABLE: beacon node is syncing: head slot is 8416, current slot is 5098402", stacktraces: [] }), node: http://localhost:5052/` * Permit a `null` LVH from an `INVALID` response to `newPayload` (#4037) ## Issue Addressed NA ## Proposed Changes As discovered in #4034, Lighthouse is not accepting `latest_valid_hash == None` in an `INVALID` response to `newPayload`. The `null`/`None` response *was* illegal at one point, however it was added in https://github.com/ethereum/execution-apis/pull/254. This PR brings Lighthouse in line with the standard and should fix the root cause of what #4034 patched around. ## Additional Info NA * Add latency measurement service to VC (#4024) ## Issue Addressed NA ## Proposed Changes Adds a service which periodically polls (11s into each mainnet slot) the `node/version` endpoint on each BN and roughly measures the round-trip latency. The latency is exposed as a `DEBG` log and a Prometheus metric. The `--latency-measurement-service` has been added to the VC, with the following options: - `--latency-measurement-service true`: enable the service (default). - `--latency-measurement-service`: (without a value) has the same effect. - `--latency-measurement-service false`: disable the service. ## Additional Info Whilst looking at our staking setup, I think the BN+VC latency is contributing to late blocks. Now that we have to wait for the builders to respond it's nice to try and do everything we can to reduce that latency. Having visibility is the first step. * Optimise payload attributes calculation and add SSE (#4027) ## Issue Addressed Closes #3896 Closes #3998 Closes #3700 ## Proposed Changes - Optimise the calculation of withdrawals for payload attributes by avoiding state clones, avoiding unnecessary state advances and reading from the snapshot cache if possible. - Use the execution layer's payload attributes cache to avoid re-calculating payload attributes. I actually implemented a new LRU cache just for withdrawals but it had the exact same key and most of the same data as the existing payload attributes cache, so I deleted it. - Add a new SSE event that fires when payloadAttributes are calculated. This is useful for block builders, a la https://github.com/ethereum/beacon-APIs/issues/244. - Add a new CLI flag `--always-prepare-payload` which forces payload attributes to be sent with every fcU regardless of connected proposers. This is intended for use by builders/relays. For maximum effect, the flags I've been using to run Lighthouse in "payload builder mode" are: ``` --always-prepare-payload \ --prepare-payload-lookahead 12000 \ --suggested-fee-recipient 0x0000000000000000000000000000000000000000 ``` The fee recipient is required so Lighthouse has something to pack in the payload attributes (it can be ignored by the builder). The lookahead causes fcU to be sent at the start of every slot rather than at 8s. As usual, fcU will also be sent after each change of head block. I think this combination is sufficient for builders to build on all viable heads. Often there will be two fcU (and two payload attributes) sent for the same slot: one sent at the start of the slot with the head from `n - 1` as the parent, and one sent after the block arrives with `n` as the parent. Example usage of the new event stream: ```bash curl -N "http://localhost:5052/eth/v1/events?topics=payload_attributes" ``` ## Additional Info - [x] Tests added by updating the proposer re-org tests. This has the benefit of testing the proposer re-org code paths with withdrawals too, confirming that the new changes don't interact poorly. - [ ] Benchmarking with `blockdreamer` on devnet-7 showed promising results but I'm yet to do a comparison to `unstable`. Co-authored-by: Michael Sproul <[email protected]> * Optimise attestation selection proof signing (#4033) ## Issue Addressed Closes #3963 (hopefully) ## Proposed Changes Compute attestation selection proofs gradually each slot rather than in a single `join_all` at the start of each epoch. On a machine with 5k validators this replaces 5k tasks signing 5k proofs with 1 task that signs 5k/32 ~= 160 proofs each slot. Based on testing with Goerli validators this seems to reduce the average time to produce a signature by preventing Tokio and the OS from falling over each other trying to run hundreds of threads. My testing so far has been with local keystores, which run on a dynamic pool of up to 512 OS threads because they use [`spawn_blocking`](https://docs.rs/tokio/1.11.0/tokio/task/fn.spawn_blocking.html) (and we haven't changed the default). An earlier version of this PR hyper-optimised the time-per-signature metric to the detriment of the entire system's performance (see the reverted commits). The current PR is conservative in that it avoids touching the attestation service at all. I think there's more optimising to do here, but we can come back for that in a future PR rather than expanding the scope of this one. The new algorithm for attestation selection proofs is: - We sign a small batch of selection proofs each slot, for slots up to 8 slots in the future. On average we'll sign one slot's worth of proofs per slot, with an 8 slot lookahead. - The batch is signed halfway through the slot when there is unlikely to be contention for signature production (blocks are <4s, attestations are ~4-6 seconds, aggregates are 8s+). ## Performance Data _See first comment for updated graphs_. Graph of median signing times before this PR: 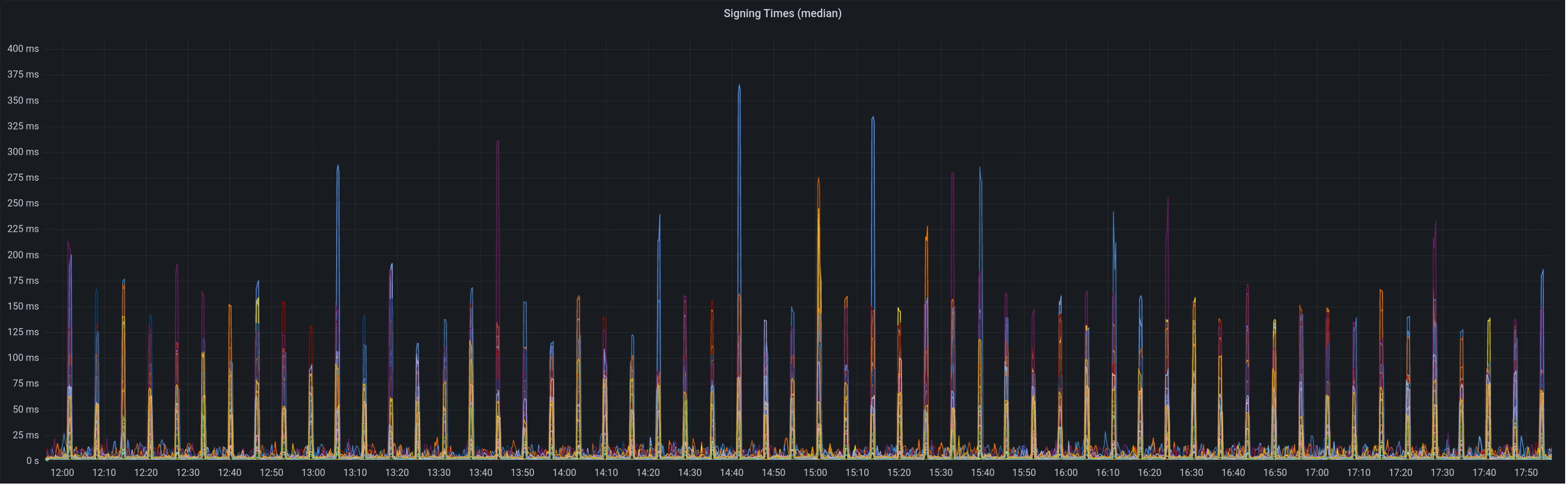 Graph of update attesters metric (includes selection proof signing) before this PR: 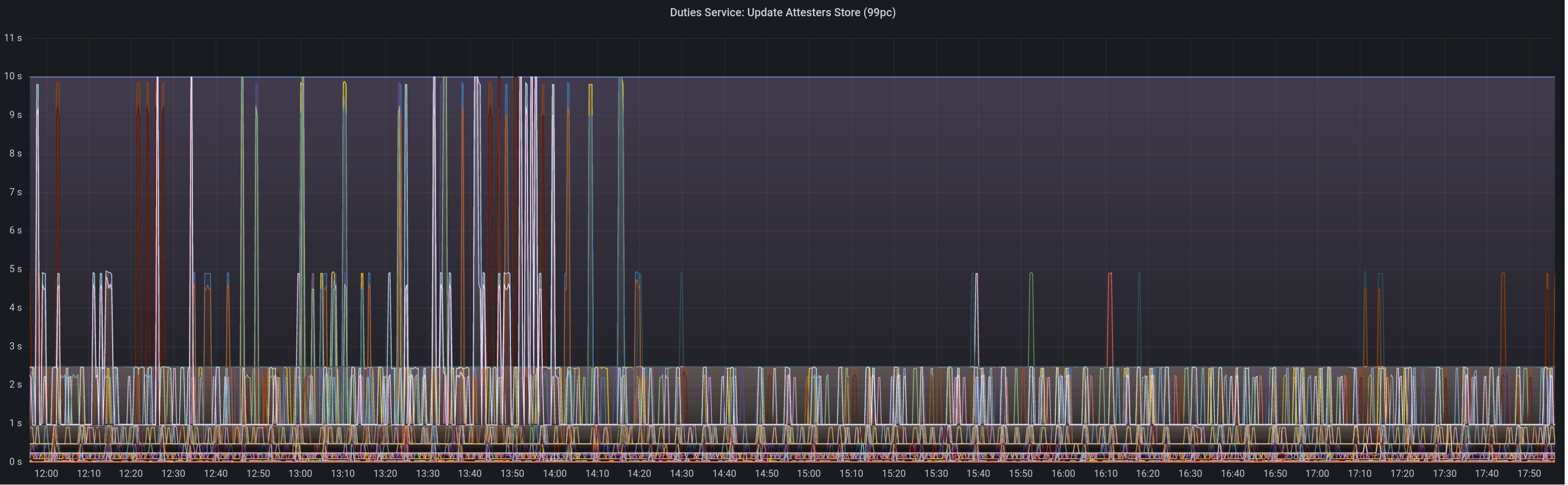 Median signing time after this PR (prototype from 12:00, updated version from 13:30): 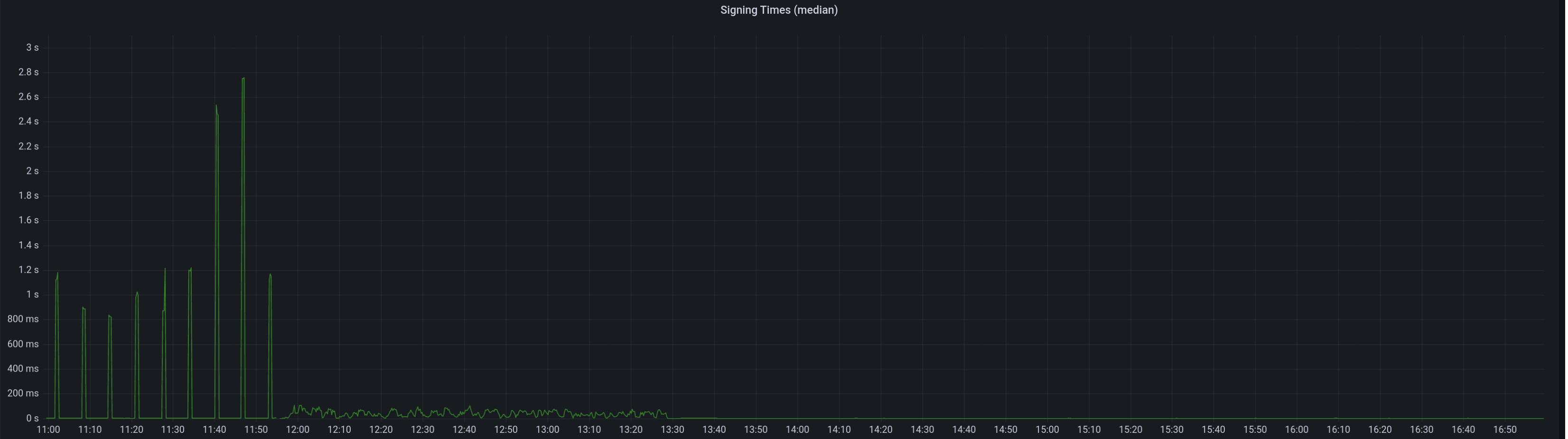 99th percentile on signing times (bounded attestation signing from 16:55, now removed): 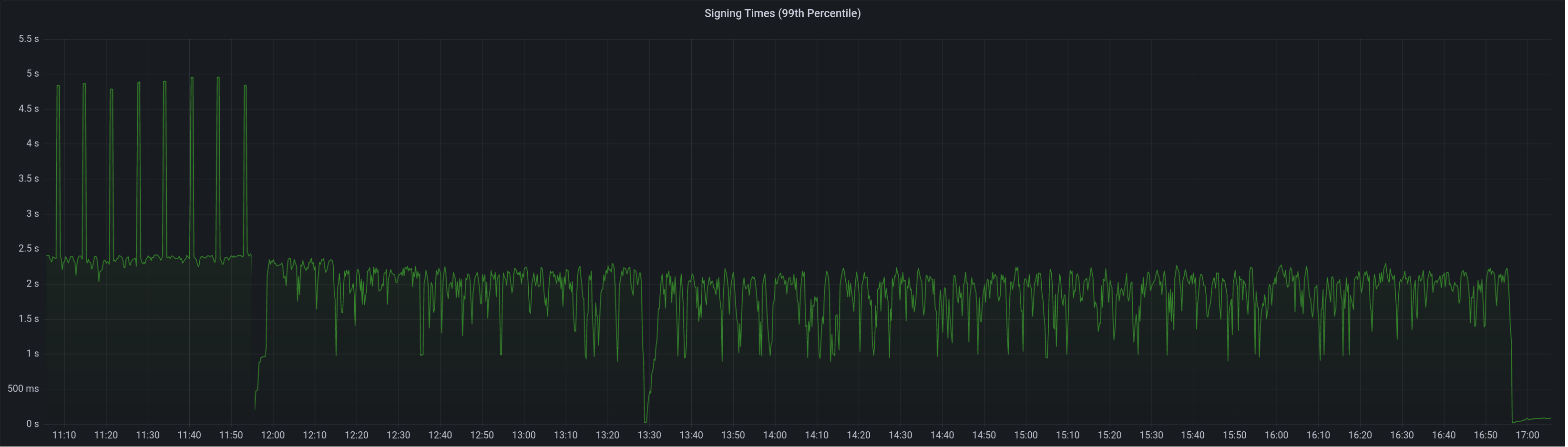 Attester map update timing after this PR:  Selection proof signings per second change: 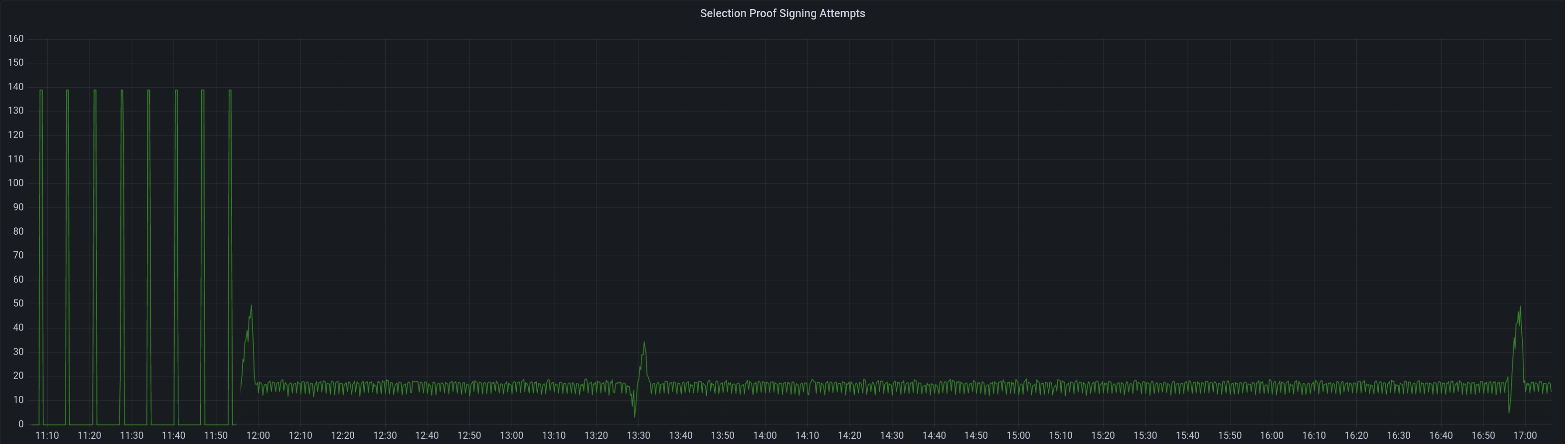 ## Link to late blocks I believe this is related to the slow block signings because logs from Stakely in #3963 show these two logs almost 5 seconds apart: > Feb 23 18:56:23.978 INFO Received unsigned block, slot: 5862880, service: block, module: validator_client::block_service:393 > Feb 23 18:56:28.552 INFO Publishing signed block, slot: 5862880, service: block, module: validator_client::block_service:416 The only thing that happens between those two logs is the signing of the block: https://github.com/sigp/lighthouse/blob/0fb58a680d6f0c9f0dc8beecf142186debff9a8d/validator_client/src/block_service.rs#L410-L414 Helpfully, Stakely noticed this issue without any Lighthouse BNs in the mix, which pointed to a clear issue in the VC. ## TODO - [x] Further testing on testnet infrastructure. - [x] Make the attestation signing parallelism configurable. * Update dependencies incl tempfile (#4048) ## Proposed Changes Fix the cargo audit failure caused by [RUSTSEC-2023-0018](https://rustsec.org/advisories/RUSTSEC-2023-0018) which we were exposed to via `tempfile`. ## Additional Info I've held back the libp2p crate for now because it seemed to introduce another duplicate dependency on libp2p-core, for a total of 3 copies. Maybe that's fine, but we can sort it out later. * Log a `WARN` in the VC for a mismatched Capella fork epoch (#4050) ## Issue Addressed NA ## Proposed Changes - Adds a `WARN` statement for Capella, just like the previous forks. - Adds a hint message to all those WARNs to suggest the user update the BN or VC. ## Additional Info NA * Add VC metric for primary BN latency (#4051) ## Issue Addressed NA ## Proposed Changes In #4024 we added metrics to expose the latency measurements from a VC to each BN. Whilst playing with these new metrics on our infra I realised it would be great to have a single metric to make sure that the primary BN for each VC has a reasonable latency. With the current "metrics for all BNs" it's hard to tell which is the primary. ## Additional Info NA * Set Capella fork epoch for Goerli (#4044) ## Issue Addressed NA ## Proposed Changes Sets the Capella fork epoch as per https://github.com/eth-clients/goerli/pull/160. The fork will occur at: - Epoch: 162304 - Slot: 5193728 - UTC: 14/03/2023, 10:25:36 pm ## Additional Info - [x] Blocked on https://github.com/eth-clients/goerli/pull/160 being merged * Add a flag to always use payloads from builders (#4052) ## Issue Addressed #4040 ## Proposed Changes - Add the `always_prefer_builder_payload` field to `Config` in `beacon_node/client/src/config.rs`. - Add that same field to `Inner` in `beacon_node/execution_layer/src/lib.rs` - Modify the logic for picking the payload in `beacon_node/execution_layer/src/lib.rs` - Add the `always-prefer-builder-payload` flag to the beacon node CLI - Test the new flags in `lighthouse/tests/beacon_node.rs` Co-authored-by: Paul Hauner <[email protected]> * Release v3.5.1 (#4049) ## Issue Addressed NA ## Proposed Changes Bumps versions to v3.5.1. ## Additional Info - [x] Requires further testing * Fix order of arguments to log_count (#4060) See: https://github.com/sigp/lighthouse/pull/4027 ## Proposed Changes The order of the arguments to `log_count` is swapped in `beacon_node/beacon_chain/src/events.rs`. * Appease Clippy 1.68 and refactor `http_api` (#4068) ## Proposed Changes Two tiny updates to satisfy Clippy 1.68 Plus refactoring of the `http_api` into less complex types so the compiler can chew and digest them more easily. Co-authored-by: Michael Sproul <[email protected]> * Added warning when new jwt is generated (#4000) ## Issue Addressed #3435 ## Proposed Changes Fire a warning with the path of JWT to be created when the path given by --execution-jwt is not found Currently, the same error is logged if the jwt is found but doesn't match the execution client's jwt, and if no jwt was found at the given path. This makes it very hard to tell if you accidentally typed the wrong path, as a new jwt is created silently that won't match the execution client's jwt. So instead, it will now fire a warning stating that a jwt is being generated at the given path. ## Additional Info In the future, it may be smarter to handle this case by adding an InvalidJWTPath member to the Error enum in lib.rs or auth.rs that can be handled during upcheck() This is my first PR and first project with rust. so thanks to anyone who looks at this for their patience and help! Co-authored-by: Sebastian Richel <[email protected]> * Correct /lighthouse/nat implementation (#4069) ## Proposed Changes The current `/lighthouse/nat` implementation checks for _zero_ address updated messages, when it should check for a _non-zero_ number. This was spotted while debugging an issue on Discord where a user's ports weren't forwarded but `/lighthouse/nat` was still returning `true`. * Support for Ipv6 (#4046) ## Issue Addressed Add support for ipv6 and dual stack in lighthouse. ## Proposed Changes From an user perspective, now setting an ipv6 address, optionally configuring the ports should feel exactly the same as using an ipv4 address. If listening over both ipv4 and ipv6 then the user needs to: - use the `--listen-address` two times (ipv4 and ipv6 addresses) - `--port6` becomes then required - `--discovery-port6` can now be used to additionally configure the ipv6 udp port ### Rough list of code changes - Discovery: - Table filter and ip mode set to match the listening config. - Ipv6 address, tcp port and udp port set in the ENR builder - Reported addresses now check which tcp port to give to libp2p - LH Network Service: - Can listen over Ipv6, Ipv4, or both. This uses two sockets. Using mapped addresses is disabled from libp2p and it's the most compatible option. - NetworkGlobals: - No longer stores udp port since was not used at all. Instead, stores the Ipv4 and Ipv6 TCP ports. - NetworkConfig: - Update names to make it clear that previous udp and tcp ports in ENR were Ipv4 - Add fields to configure Ipv6 udp and tcp ports in the ENR - Include advertised enr Ipv6 address. - Add type to model Listening address that's either Ipv4, Ipv6 or both. A listening address includes the ip, udp port and tcp port. - UPnP: - Kept only for ipv4 - Cli flags: - `--listen-addresses` now can take up to two values - `--port` will apply to ipv4 or ipv6 if only one listening address is given. If two listening addresses are given it will apply only to Ipv4. - `--port6` New flag required when listening over ipv4 and ipv6 that applies exclusively to Ipv6. - `--discovery-port` will now apply to ipv4 and ipv6 if only one listening address is given. - `--discovery-port6` New flag to configure the individual udp port of ipv6 if listening over both ipv4 and ipv6. - `--enr-udp-port` Updated docs to specify that it only applies to ipv4. This is an old behaviour. - `--enr-udp6-port` Added to configure the enr udp6 field. - `--enr-tcp-port` Updated docs to specify that it only applies to ipv4. This is an old behaviour. - `--enr-tcp6-port` Added to configure the enr tcp6 field. - `--enr-addresses` now can take two values. - `--enr-mat…
Woodpile37
pushed a commit
to Woodpile37/lighthouse
that referenced
this pull request
Jan 6, 2024
Sign up for free
to join this conversation on GitHub.
Already have an account?
Sign in to comment
Add this suggestion to a batch that can be applied as a single commit.
This suggestion is invalid because no changes were made to the code.
Suggestions cannot be applied while the pull request is closed.
Suggestions cannot be applied while viewing a subset of changes.
Only one suggestion per line can be applied in a batch.
Add this suggestion to a batch that can be applied as a single commit.
Applying suggestions on deleted lines is not supported.
You must change the existing code in this line in order to create a valid suggestion.
Outdated suggestions cannot be applied.
This suggestion has been applied or marked resolved.
Suggestions cannot be applied from pending reviews.
Suggestions cannot be applied on multi-line comments.
Suggestions cannot be applied while the pull request is queued to merge.
Suggestion cannot be applied right now. Please check back later.
Issue Addressed
Closes #3788
Proposed Changes
Change the BLS to execution HTTP API so that it takes a list of BLS to execution changes, matching the latest spec: ethereum/beacon-APIs#279