Extend vec::FromIterator specialization to collect in-place for some iterator pipelines #66383
Conversation
|
Thanks for the pull request, and welcome! The Rust team is excited to review your changes, and you should hear from @sfackler (or someone else) soon. If any changes to this PR are deemed necessary, please add them as extra commits. This ensures that the reviewer can see what has changed since they last reviewed the code. Due to the way GitHub handles out-of-date commits, this should also make it reasonably obvious what issues have or haven't been addressed. Large or tricky changes may require several passes of review and changes. Please see the contribution instructions for more information. |
80efbe9
to
1de6d0f
Compare
|
Replacing the How do I run individual benches under |
|
The job Click to expand the log.I'm a bot! I can only do what humans tell me to, so if this was not helpful or you have suggestions for improvements, please ping or otherwise contact |
1de6d0f
to
84e8a94
Compare
|
The job Click to expand the log.I'm a bot! I can only do what humans tell me to, so if this was not helpful or you have suggestions for improvements, please ping or otherwise contact |
84e8a94
to
7b9a3b1
Compare
|
I have addressed all review issues, extended the benchmarks and restored vectorization performance. |
|
@bors try @rust-timer queue |
|
Awaiting bors try build completion |
|
⌛ Trying commit 92dc2b06c8168f6b7e8effcc1b2406e6cfef3bdb with merge 32277c67f9127581d9db3d08b2604f4e8265ac15... |
|
The job Click to expand the log.I'm a bot! I can only do what humans tell me to, so if this was not helpful or you have suggestions for improvements, please ping or otherwise contact |
| @@ -53,15 +53,15 @@ | |||
| //! [`Index`]: ../../std/ops/trait.Index.html | |||
| //! [`IndexMut`]: ../../std/ops/trait.IndexMut.html | |||
| //! [`vec!`]: ../../std/macro.vec.html | |||
|
|
|||
| // ignore-tidy-filelength | |||
There was a problem hiding this comment.
It means that the file went over 3000 LOC which tidy doesn't like. Ideally the file should be refactored into smaller pieces.
There was a problem hiding this comment.
Any recommendations what should be split out?
There was a problem hiding this comment.
As a start, the iterators (e.g. Drain) could probably be moved out to a module:
src/liballoc/vec/
- mod.rs
- iter.rs
but it's probably best to do the split in a different PR to keep the diff limited.
|
@bors try @rust-timer queue |
|
Awaiting bors try build completion |
|
⌛ Trying commit 54797671acec9dedc22af578665dc291abfdb8bf with merge cfe2d15711e1469278c75c80cdb6508be16e8beb... |
|
☀️ Try build successful - checks-azure |
|
Queued cfe2d15711e1469278c75c80cdb6508be16e8beb with parent 5c5b8af, future comparison URL. |
|
Finished benchmarking try commit cfe2d15711e1469278c75c80cdb6508be16e8beb, comparison URL. |
b9fba82
to
89a616a
Compare
|
I don't see how those latest build errors are related to my changes? Any hints how to fix this? |
8be8db3
to
a724f9a
Compare
|
The job Click to expand the log.I'm a bot! I can only do what humans tell me to, so if this was not helpful or you have suggestions for improvements, please ping or otherwise contact |
|
@Dylan-DPC done |
|
@bors try @rust-timer queue |
|
Awaiting bors try build completion |
Extend vec::FromIterator specialization to collect in-place for some iterator pipelines This extends the existing `vec.into_iter().collect::<Vec>()` specialization to cover more cases, including iterator pipelines that flow from `IntoIter` through `Map`, `Filter`, `Zip` and `Enumerate` and several others. [Benchmark results](https://gist.github.com/the8472/6d999b2d08a2bedf3b93f12112f96e2f) with defaults and opt-level = 3, codegen-units=1. The specialization should be conservative, it is only applied when we know the iterator will fit into the source allocation. Additionally some existing specializations now applied in a few more code-paths.
|
☀️ Try build successful - checks-azure |
|
Queued efe77ba with parent a2e8030, future comparison URL. |
|
The top negative item of that perf run is syn-opt, I can't reproduce the result locally. I'm building rustc stage2 from
Then I run rustc-perf rev e8cd7a6
Anything I might be missing? |

|
@the8472 Probably don't want to focus on minor changes in syn-opt perf see #69060. The issue mentions a noop run that was faster. This comment references the issue in relation to a bench where it was slower. |
|
ping from triage: |
|
I'm still trying a few things, but running those benchmarks locally takes ages, which makes iterating slow. I'll have to rebase the branch anyway, maybe some of the recent MIR optimizations will reduce the overhead. |
|
Closing this due to inactivity. Thanks for taking the time to contribute to rustc. |
|
Sorry for the slow responses. I did rebase my branch and ran the webrender-wrench rustc-perf benchmarks locally and the differences vanished. Can I get another perf run? |
|
Should I make a new PR instead? |
|
@the8472 this can't be reöpened so yeah. |
specialize some collection and iterator operations to run in-place This is a rebase and update of rust-lang#66383 which was closed due inactivity. Recent rustc changes made the compile time regressions disappear, at least for webrender-wrench. Running a stage2 compile and the rustc-perf suite takes hours on the hardware I have at the moment, so I can't do much more than that. 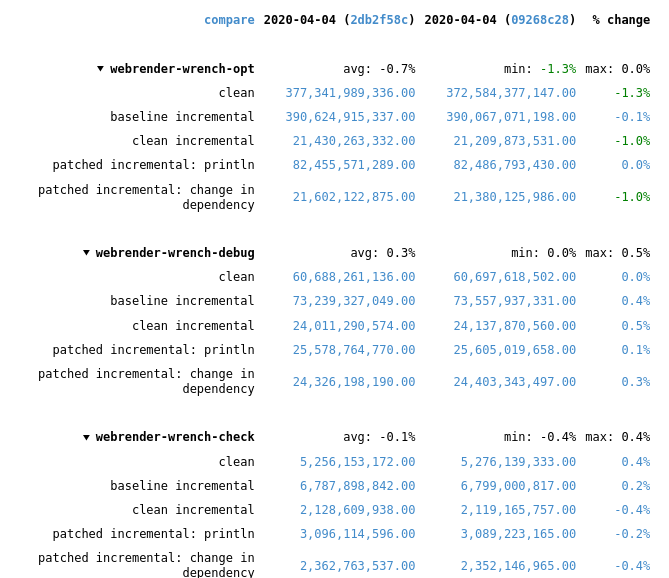 In the best case of the `vec::bench_in_place_recycle` synthetic microbenchmark these optimizations can provide a 15x speedup over the regular implementation which allocates a new vec for every benchmark iteration. [Benchmark results](https://gist.github.com/the8472/6d999b2d08a2bedf3b93f12112f96e2f). In real code the speedups are tiny, but it also depends on the allocator used, a system allocator that uses a process-wide mutex will benefit more than one with thread-local pools. ## What was changed * `SpecExtend` which covered `from_iter` and `extend` specializations was split into separate traits * `extend` and `from_iter` now reuse the `append_elements` if passed iterators are from slices. * A preexisting `vec.into_iter().collect::<Vec<_>>()` optimization that passed through the original vec has been generalized further to also cover cases where the original has been partially drained. * A chain of *Vec<T> / BinaryHeap<T> / Box<[T]>* `IntoIter`s through various iterator adapters collected into *Vec<U>* and *BinaryHeap<U>* will be performed in place as long as `T` and `U` have the same alignment and size and aren't ZSTs. * To enable above specialization the unsafe, unstable `SourceIter` and `InPlaceIterable` traits have been added. The first allows reaching through the iterator pipeline to grab a pointer to the source memory. The latter is a marker that promises that the read pointer will advance as fast or faster than the write pointer and thus in-place operation is possible in the first place. * `vec::IntoIter` implements `TrustedRandomAccess` for `T: Copy` to allow in-place collection when there is a `Zip` adapter in the iterator. TRA had to be made an unstable public trait to support this. ## In-place collectible adapters * `Map` * `MapWhile` * `Filter` * `FilterMap` * `Fuse` * `Skip` * `SkipWhile` * `Take` * `TakeWhile` * `Enumerate` * `Zip` (left hand side only, `Copy` types only) * `Peek` * `Scan` * `Inspect` ## Concerns `vec.into_iter().filter(|_| false).collect()` will no longer return a vec with 0 capacity, instead it will return its original allocation. This avoids the cost of doing any allocation or deallocation but could lead to large allocations living longer than expected. If that's not acceptable some resizing policy at the end of the attempted in-place collect would be necessary, which in the worst case could result in one more memcopy than the non-specialized case. ## Possible followup work * split liballoc/vec.rs to remove `ignore-tidy-filelength` * try to get trivial chains such as `vec.into_iter().skip(1).collect::<Vec<)>>()` to compile to a `memmove` (currently compiles to a pile of SIMD, see rust-lang#69187 ) * improve up the traits so they can be reused by other crates, e.g. itertools. I think currently they're only good enough for internal use * allow iterators sourced from a `HashSet` to be in-place collected into a `Vec`
{kind=link}
This extends the existing
vec.into_iter().collect::<Vec>()specialization to cover more cases, including iterator pipelines that flow fromIntoIterthroughMap,Filter,ZipandEnumerateand several others.Benchmark results with defaults and opt-level = 3, codegen-units=1.
The specialization should be conservative, it is only applied when we know the iterator will fit into the source allocation.
Additionally some existing specializations now applied in a few more code-paths.