Missed optimization: repeated pointer increments don't compile to a memcpy #69187
Labels
A-LLVM
Area: Code generation parts specific to LLVM. Both correctness bugs and optimization-related issues.
C-enhancement
Category: An issue proposing an enhancement or a PR with one.
I-slow
Issue: Problems and improvements with respect to performance of generated code.
T-compiler
Relevant to the compiler team, which will review and decide on the PR/issue.
Comments
|
|
This does (https://godbolt.org/z/MdgeTL). |
|
@cynecx Indeed, that is exactly what |
|
@timvermeulen Fwiw LLVM isn't doing a great job at detecting this particular pattern: https://godbolt.org/z/TW2bJH (C++). |
bors
added a commit
to rust-lang-ci/rust
that referenced
this issue
Sep 3, 2020
specialize some collection and iterator operations to run in-place This is a rebase and update of rust-lang#66383 which was closed due inactivity. Recent rustc changes made the compile time regressions disappear, at least for webrender-wrench. Running a stage2 compile and the rustc-perf suite takes hours on the hardware I have at the moment, so I can't do much more than that. 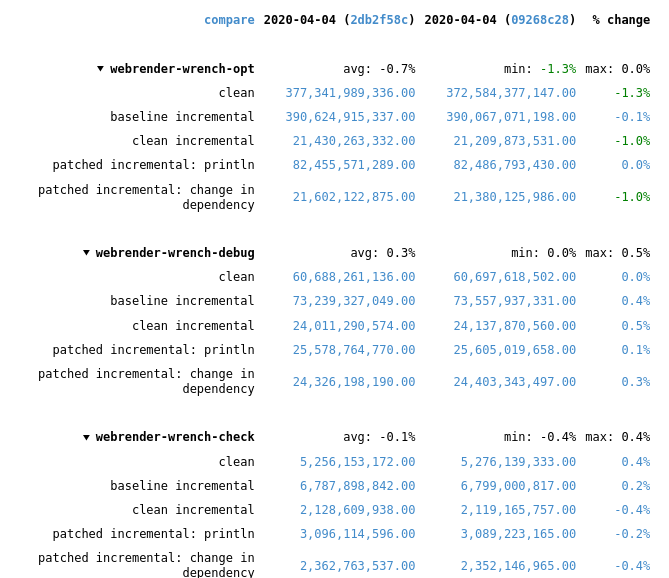 In the best case of the `vec::bench_in_place_recycle` synthetic microbenchmark these optimizations can provide a 15x speedup over the regular implementation which allocates a new vec for every benchmark iteration. [Benchmark results](https://gist.github.com/the8472/6d999b2d08a2bedf3b93f12112f96e2f). In real code the speedups are tiny, but it also depends on the allocator used, a system allocator that uses a process-wide mutex will benefit more than one with thread-local pools. ## What was changed * `SpecExtend` which covered `from_iter` and `extend` specializations was split into separate traits * `extend` and `from_iter` now reuse the `append_elements` if passed iterators are from slices. * A preexisting `vec.into_iter().collect::<Vec<_>>()` optimization that passed through the original vec has been generalized further to also cover cases where the original has been partially drained. * A chain of *Vec<T> / BinaryHeap<T> / Box<[T]>* `IntoIter`s through various iterator adapters collected into *Vec<U>* and *BinaryHeap<U>* will be performed in place as long as `T` and `U` have the same alignment and size and aren't ZSTs. * To enable above specialization the unsafe, unstable `SourceIter` and `InPlaceIterable` traits have been added. The first allows reaching through the iterator pipeline to grab a pointer to the source memory. The latter is a marker that promises that the read pointer will advance as fast or faster than the write pointer and thus in-place operation is possible in the first place. * `vec::IntoIter` implements `TrustedRandomAccess` for `T: Copy` to allow in-place collection when there is a `Zip` adapter in the iterator. TRA had to be made an unstable public trait to support this. ## In-place collectible adapters * `Map` * `MapWhile` * `Filter` * `FilterMap` * `Fuse` * `Skip` * `SkipWhile` * `Take` * `TakeWhile` * `Enumerate` * `Zip` (left hand side only, `Copy` types only) * `Peek` * `Scan` * `Inspect` ## Concerns `vec.into_iter().filter(|_| false).collect()` will no longer return a vec with 0 capacity, instead it will return its original allocation. This avoids the cost of doing any allocation or deallocation but could lead to large allocations living longer than expected. If that's not acceptable some resizing policy at the end of the attempted in-place collect would be necessary, which in the worst case could result in one more memcopy than the non-specialized case. ## Possible followup work * split liballoc/vec.rs to remove `ignore-tidy-filelength` * try to get trivial chains such as `vec.into_iter().skip(1).collect::<Vec<)>>()` to compile to a `memmove` (currently compiles to a pile of SIMD, see rust-lang#69187 ) * improve up the traits so they can be reused by other crates, e.g. itertools. I think currently they're only good enough for internal use * allow iterators sourced from a `HashSet` to be in-place collected into a `Vec`
{kind=link}
|
This is detected as a memcpy on nightly, presumably due to LLVM 12 upgrade. |
Sign up for free
to join this conversation on GitHub.
Already have an account?
Sign in to comment
This doesn't currently compile to a
memcpy(Godbolt).I figured this was worth filing because this seems to be the main reason that a naive
iter::Zipimplementation isn't optimal, which is why it's implemented the way it is.The text was updated successfully, but these errors were encountered: