{% include list.liquid all=true %}
Proofreading removes the mismatched nucleotide and extension continues. If a mismatch is accidentally incorporated, the polymerase is inhibited from further extension _([Wikipedia](https://en.wikipedia.org/wiki/DNA_polymerase#Function))_.

A current model of meiotic recombination, initiated by ***a double-strand break or gap***, followed by pairing with an homologous chromosome and strand invasion to initiate the recombinational repair process _([Wikipedia](https://en.wikipedia.org/wiki/Genetic_recombination))_.

π(96) = 96/4 = 24

$True Prime Pairs:
(5,7), (11,13), (17,19)
| 168 | 618 |
-----+-----+-----+-----+-----+ ---
19¨ | 3¨ | 4¨ | 6¨ | 6¨ | 4¤ -----> assigned to "id:30" 19¨
-----+-----+-----+-----+-----+ ---
17¨ | 5¨ | 3¨ | ❓ | ❓ | 4¤ ✔️ ---> assigned to "id:31" |
+-----+-----+-----+-----+ |
{12¨}| .. | .. | 2¤ (M & F) -----> assigned to "id:32" |
+-----+-----+-----+ |
11¨ | .. | .. | .. | 3¤ ----> Np(33) assigned to "id:33" -----> 👉 77¨
-----+-----+-----+-----+-----+ |
19¨ | .. | .. | .. | .. | 4¤ -----> assigned to "id:34" |
+-----+-----+-----+-----+ |
{18¨}| .. | .. | .. | 3¤ -----> assigned to "id:35" |
+-----+-----+-----+-----+-----+-----+-----+-----+-----+ ---
43¨ | .. | .. | .. | .. | .. | .. | .. | .. | .. | 9¤ (C1 & C2) 43¨
-----+-----+-----+-----+-----+-----+-----+-----+-----+-----+ ---
139¨ | 1 2 3 | 4 5 6 | 7 8 9 |
Δ Δ Δ 
Fidelity is very important in DNA replication. Mismatches in DNA base pairing can potentially result in dysfunctional proteins and could lead to cancer. Hydrogen bonds play a key role in base pair binding and interaction.
The function of DNA polymerase is not quite perfect, with the enzyme making ***about one mistake for every billion base pairs copied***. Error correction is a property of some, but not all DNA polymerases. This process corrects mistakes in newly synthesized DNA _([Wikipedia](https://en.wikipedia.org/wiki/DNA_polymerase#Function))_.



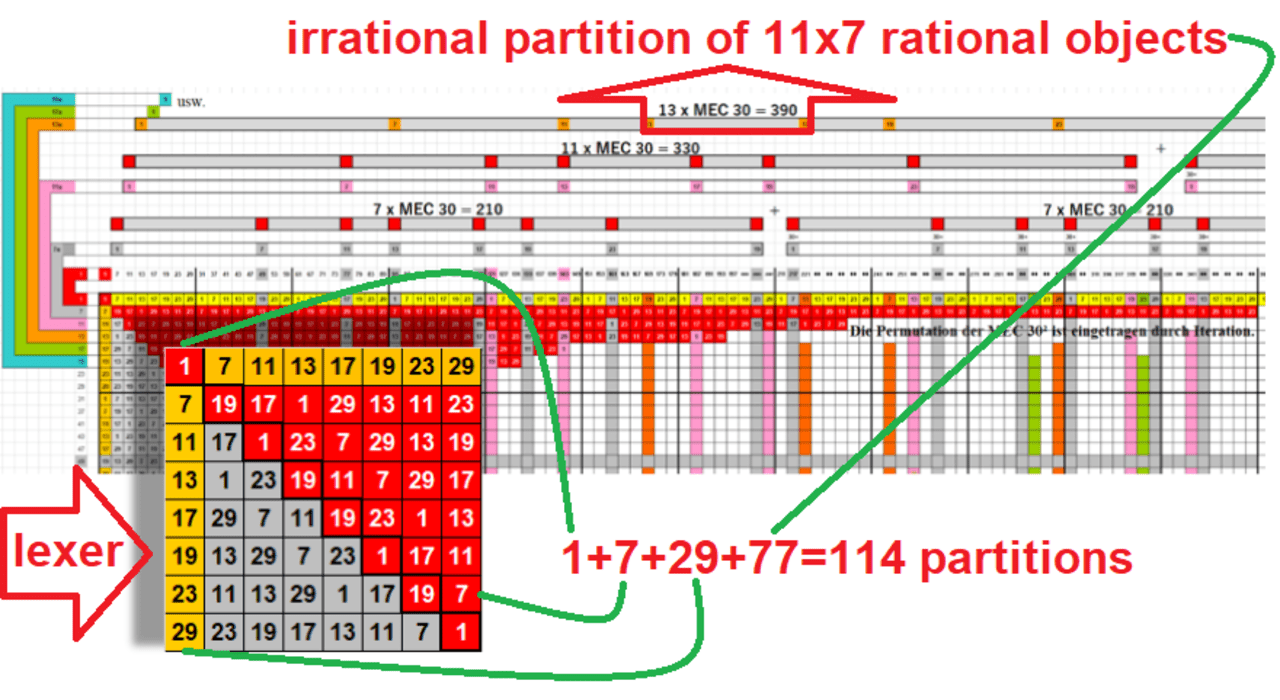
1 instance + 7 blocks + 29 flats + 77 rooms = 114 objects
Prime Loops:
π(10) = 4 (node)
π(100) = 25 (partition)
π(1000) - 29 = 139 (section)
π(10000) - 29th - 29 = 1091 (segment)
π(100000) - 109th - 109 = 8884 (texture)
Sum: 4 + 25 + 139 + 1091 + 8884 = 10143 (object)
Sequence Layers:
- By the next layer the 89² will become 89 and 5 become 5² or 25.
- This 89 and 25 are in the same layer with total of 114 or prime 619
- So sequence from the first prime is 1,4,7,10,29,68,89,114,139,168,329,618.
-----+-----+-----+-----+-----+ -----------------------------------------------
{786}| 1,2 | 2 | 2,3 | 3,4 | {19} |
-----+-----+-----+-----+-----+ |
{86}| 4 | 4,5 | 5,6 |{6,7}| 17 Base Zone
+-----+-----+-----+-----+ |
{78}|{7,8}| 8,9 | 12 (M dan F) ----> Δ |
+-----+-----+-----+ -----------
{67}| 9,11|11,12|12,14| 11 <----------- Mid Zone |
----+-----+-----+-----+-----+ |
{6}|15,16|17,18|18,20|21,22| 19 Mirror Zone
+-----+-----+-----+-----+ |
{8}|23,25|25,27|27,29| 18 |
+-----+-----+-----+-----+-----+-----+-----+-----+-------+ -----------
{7}|29,33|33,36|36,39|39,41|41,45|46,51|51,57|58,66|{67,77}| 43 (C1 dan C2)<---Δ
-----+-----+-----+-----+-----+-----+-----+-----+-----+-------+ -----------
| 1 2 3 | 4 5 6 | 7 8 9 |
|------ 29' ------|--------------- 139' ----------------|
|------ 102¨ -----|--------------- 66¨ ----------------|If you are using Docker-for-Windows, you can run now both Windows and Linux containers simultaneously: Running Docker Windows and Linux Containers Simultaneously, not only the Linux container itself, but also an orchestrator like Kubernetes: Kubernetes is Now Available In Docker Desktop Stable Channel

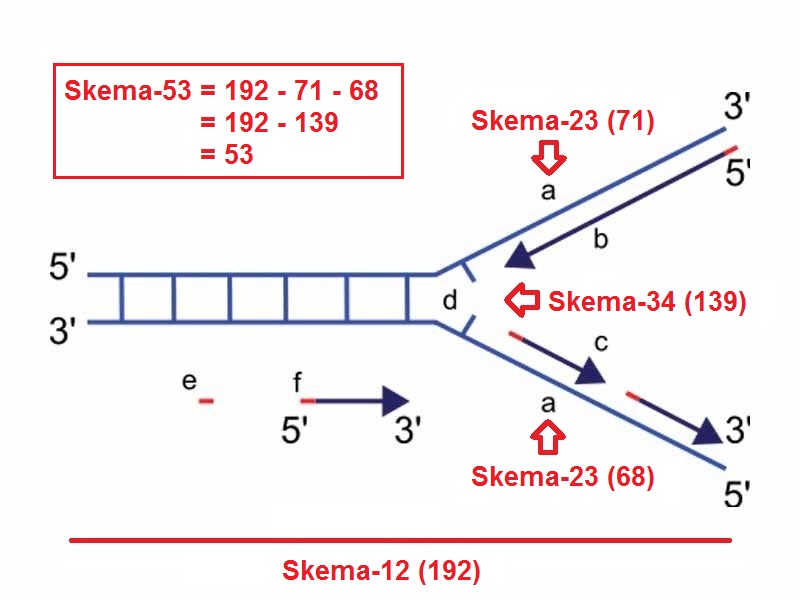
On the lagging strand template, a primase "reads" the template DNA and initiates synthesis of a short complementary RNA primer. This is assigned to Windows container.

The leading strand is the strand of new DNA which is synthesized in the same direction as the growing replication fork. This sort of DNA replication is continuous. This workflow is assigned to Linux container (Ubuntu).
DNA polymerase extends primed segments, forming Okazaki fragments. The RNA primers are then removed and replaced with DNA, and the fragments of DNA are joined by DNA ligase and are bound to the helicase heximer _([Wikipedia](https://en.wikipedia.org/wiki/DNA_replication#Replication_fork))_.

In eukaryotes the helicase wraps around the leading strand, and in prokaryotes it wraps around the lagging strand. As helicase unwinds DNA at the replication fork, the DNA ahead is forced to rotate resulting a build-up of twists in the DNA ahead.
Because of its orientation, replication of the lagging strand is more complicated as compared to that of the leading strand. As a consequence, the DNA polymerase on this strand is seen to "lag behind".

layer | node | sub | i | f
------+------+-----+----------+-----+-----+-----+ ---
| | | 1,2:1 | 1 | 30 | 40 | 71 (2,3) ‹------------------- |
| | 1 +----------+-----+-----+-----+ | |
| 1 | | 2 | | 5¨ encapsulation
| |-----+----------+ ----------------------------- | |
| | | 3 | | | | |
1 +------+ 2 +----------+---- | LAGGING SCHEME | | ---
| | | 4 | | (Exponentiation Zone) | | |
| +-----+----------+ | | | |
| 2 | | 5 | ------------------------------ | 7¨ abstraction
289 | | 3 +----------+ | |
| | | | 6 | ‹---------------------------- Φ | {6®} |
------+------+-----+----------+-----+----- | ---
| | | 11:7 | 5 | 9 | 14 (20) --------› ¤ | |
| | 4 +----------+-----+-----+-----+ | |
| 3 | | 12:8 | 9 | 60 | 40 | 109 (26) «------------ | 11¨ polymorphism
| +-----+----------+-----+-----+-----+ | | |
| | | 13:9 | 9 | 60 | 69 (27) «-- Δ19 (Rep Fork) | {2®} | |
2 +------| 5 +----------+-----+-----+-----+ | | ---
| | | 14:19 | 9 | 60 | 40 | 109 (28) ------------- | |
| |-----+----------+-----+-----+-----+ | |
| 4 | | 15,18:11 | 1 | 30 | 40 | 71 (29,30,31,32) ------------ 13¨ inheritance
329 | | 6 +----------+-----+-----+-----+ |
| | | | 19:12 | 10 | 60 | {70} (36) -------› Φ |
------+------+-----+----------+-----+-----+ ---
| | | 20:13 | 90 | 90 (38) ‹-------------- ¤ |
| | 7 +----------+-----+ |
| 5 | | 14 | ----------------------------- 17¨ class
| |-----+----------+ | | |
| | | 15 | | LEADING SCHEME | |
3 +------+ 8 +----------+----- | (Multiplication Zone) | ---
| | | 16 | | | |
| |-----+----------+-----+ ----------------------------- |
| 6 | | 28:17 | 100 | 19¨ object
168 | | 9 +----------+-----+ |
| | | | 29:18 | 50 | 50(68) ---------> Δ18 |
------|------|-----+----------+-----+ ---This distribution of fermion parameters are shown by [13,17], [11,19] in the coupling of MEC30. So we shall find the rest of [7,23], [1,29] in the boson field.
In [physics](https://en.wikipedia.org/wiki/Physics), a ***coupling constant or gauge coupling*** parameter (or, more simply, a coupling), is a number that determines the strength of the [force](https://en.wikipedia.org/wiki/Force) exerted in an [interaction](https://en.wikipedia.org/wiki/Fundamental_interaction).
- Originally, the coupling constant related the force acting between two static bodies to the "[charges](https://en.wikipedia.org/wiki/Charge_(physics))" of the bodies (i.e. the electric charge for [electrostatic](https://en.wikipedia.org/wiki/Electrostatics) and the mass for [Newtonian gravity](https://en.wikipedia.org/wiki/Newton%27s_law_of_universal_gravitation)) divided by the distance squared, r².
- The choice of free parameters is somewhat arbitrary. In the table above, gauge couplings are listed as free parameters, therefore with this choice the Weinberg angle is not a free parameter
- The solution to both these problems comes from the Higgs mechanism, which involves scalar fields (the number of which depend on the exact form of Higgs mechanism) which (to give the briefest possible description) are "absorbed" by the massive bosons as degrees of freedom, and which couple to the fermions via ***Yukawa coupling*** to create what looks like mass terms.
The next step is to ***couple the gauge fields to the fermions***, allowing for interactions. _([Wikipedia](https://en.wikipedia.org/wiki/Coupling_constant))_
By The GitHub Runner you can connect to the Google COS Instance. For self-hosted runners defined at the organization level, configure runs-on.group in your workflow file to target a runner groups or combine groups and labels.
The runner is the application that runs a job from a GitHub Actions workflow. It is used by GitHub Actions in the hosted virtual environments, or you can self-host the runner in your own environment. We use both of them to create group as a four-vector.

On the other hand, with larger systems we are able to transfer the behavior of the energy from the subatomic space into the haptic space with the scale described here (thought experiment Schröninger's cat). Thus, we are still able to apply the Schröninger wave equation in the haptic space, and replace the Hamiltonian with our measurements.

The problems would arise when the Windows Container in Github deliver the RNA Primer to Google instance as Windows Image because it shall read the image while the COS is run under Linux. So it will need to proof and solve without actually having to try.
If it is easy to check that a solution to a problem is correct, is it also easy to solve the problem? This is the essence of the P vs NP question. Typical of the NP problems is that of the ***Hamiltonian Path Problem*** given N cities to visit, how can one do this without visiting a city twice? _([Clay Institute](https://www.claymath.org/millennium-problems))_.

Getting the proofreading ability of DNA polymerase to quickly solve problem for about one mistake for every billion base pairs copied is somehow that required by one of a major unsolved problem in theoretical computer science called P vs NP.
P vs. NP deals with the gap between computers being able to quickly solve problems vs. just being able to test proposed solutions for correctness. As such, the [P vs. NP problem](https://en.wikipedia.org/wiki/P_versus_NP_problem) is the search for a way to solve problems that ***require the trying of millions, billions, or trillions of combinations without actually having to try each one*** _([P vs. NP Explained](https://danielmiessler.com/study/pvsnp/#:~:text=P%20vs.%20NP%20deals%20with%20the%20gap%20between,combinations%20without%20actually%20having%20to%20try%20each%20one.))_.
It is stated that Np for a curve E with rank r obeys an asymptotic law and is still remain unsolved. Thus it would mean that using Euler's identity to get a definite pattern of prime distribution is still a long way to go.
Scheme 13:9
===========
(1){1}-7: 7'
(1){8}-13: 6‘
(1)14-{19}: 6‘
------------- 6+6 -------
(2)20-24: 5' |
(2)25-{29}: 5' |
------------ 5+5 -------
(3)30-36: 7:{70,30,10²}|
------------ |
(4)37-48: 12• --- |
(5)49-59: 11° | |
--}30° 30• |
(6)60-78: 19° | |
(7)79-96: 18• --- |
-------------- |
(8)97-109: 13 |
(9)110-139:{30}=5x6 <--x-
--
{43}
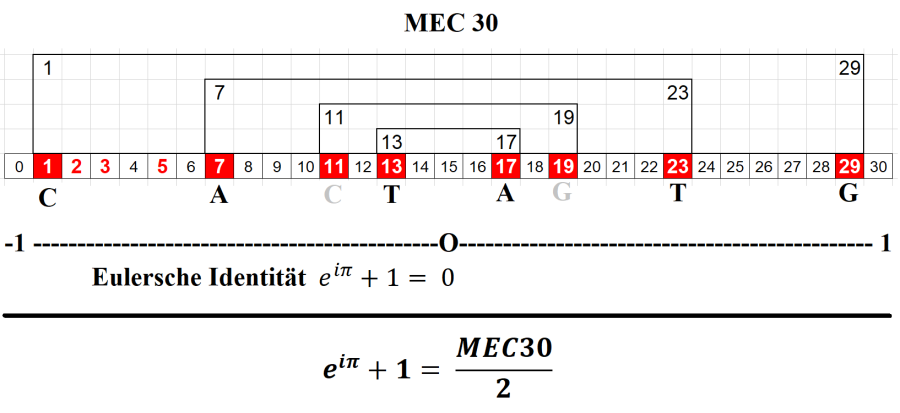
The True Prime Pairs:
(5,7), (11,13), (17,19)
|-------------------------------- 2x96 -------------------------------|
|--------------- 7¤ ---------------|------------ 7¤ ------------------|
|-------------- {89} --------------|{12}|-- {30} -|-- {36} -|-- {25} -|
+----+----+----+----+----+----+----+----+----+----+----+----+----+----+
| 5 | 7 | 11 |{13}| 17 | 19 | 17 |{12}| 11 | 19 | 18 | 18 | 12 | 13 |
+----+----+----+----+----+----+----+----+----+----+----+----+----+----+
|--------- {53} ---------|---- {48} ----|---- {48} ----|---- {43} ----|
|---------- 5¤ ----------|------------ {96} -----------|----- 3¤ -----|
|-------- Bosons --------|---------- Fermions ---------|-- Gravitons--|
13 variations 48 variations 11 variations 
The Prime Recycling ζ(s):
(2,3), (29,89), (36,68), (72,42), (100,50), (2,3), (29,89), ...**infinity**
----------------------+-----+-----+-----+ ---
7 --------- 1,2:1| 1 | 30 | 40 | 71 (2,3) ‹-------------@---- |
| +-----+-----+-----+-----+ | |
| 8 ‹------ 3:2| 1 | 30 | 40 | 90 | 161 (7) ‹--- | 5¨ encapsulation
| | +-----+-----+-----+-----+ | | |
| | 6 ‹-- 4,6:3| 1 | 30 | 200 | 231 (10,11,12) ‹--|--- | |
| | | +-----+-----+-----+-----+ | | | ---
--|--|-----» 7:4| 1 | 30 | 40 | 200 | 271 (13) --› | {5®} | |
| | +-----+-----+-----+-----+ | | |
--|---› 8,9:5| 1 | 30 | 200 | 231 (14,15) ---------› | 7¨ abstraction
289 | +-----+-----+-----+-----+-----+ | |
| ----› 10:6| 20 | 5 | 10 | 70 | 90 | 195 (19) --› Φ | {6®} |
--------------------+-----+-----+-----+-----+-----+ | ---
67 --------› 11:7| 5 | 9 | 14 (20) --------› ¤ | |
| +-----+-----+-----+ | |
| 78 ‹----- 12:8| 9 | 60 | 40 | 109 (26) «------------ | 11¨ polymorphism
| | +-----+-----+-----+ | | |
| | 86‹--- 13:9| 9 | 60 | 69 (27) «-- 3xΔ9 (2xMEC30) | {2®} | |
| | | +-----+-----+-----+ | | ---
| | ---› 14:10| 9 | 60 | 40 | 109 (28) ------------- | |
| | +-----+-----+-----+ | |
| ---› 15,18:11| 1 | 30 | 40 | 71 (29,30,31,32) ---------- 13¨ inheritance
329 | +-----+-----+-----+ |
| ‹--------- 19:12| 10 | 60 | {70} (36) ‹--------------------- Φ |
-------------------+-----+-----+ ---
786 ‹------- 20:13| 90 | 90 (38) ‹-------------- ¤ |
| +-----+-----+ |
| 618 ‹- 21,22:14| 8 | 40 | 48 (40,41) ‹---------------------- 17¨ class
| | +-----+-----+-----+-----+-----+ | |
| | 594 ‹- 23:15| 8 | 40 | 70 | 60 | 100 | 278 (42) «-- |{6'®} |
| | | +-----+-----+-----+-----+-----+ | | ---
--|--|-»24,27:16| 8 | 40 | 48 (43,44,45,46) ------------|---- |
| | +-----+-----+ | |
--|---› 28:17| 100 | {100} (50) ------------------------» 19¨ object
168 | +-----+ |
| 102 -› 29:18| 50 | 50(68) ---------> ∆27-∆9=Δ18 |
----------------------+-----+ ---