Graphics Media
Pada sesi ini kita akan bahas tensorflow dalam lingkup Graphics Media. Kita batasi sampai cara menjalankan kodenya saja. Detil dari algoritmanya akan dibahas tersendiri di bagian lain.
- Image classification, apa itu ?
- Apa yang perlu disiapkan untuk membuat sebuah image classifier ?
- Mempersiapkan dataset
- Membuat Pipeline untuk input dataset
- Membangun Model Convolutional Neural Network,
- Menggunakan Arsitektur Model CNN yang sudah ada.
- Meng-Compile Model
- Model Training
- Model Save
- Model Evaluation
- Create Predict Function.

Kodenya bisa didownload di Github, bisa langsung klik gambar di bawah ini:

Jika belum punya akun GitHub bisa download fike zip di tombol yang warna hijau.
Jika sudah punya akun bisa kita fork, jadi kodenya masuk ke akun kita:

Setelah itu bisa didownload pakai GitHub Dekstop.

Cara downloadnya seperti yang ditunjukkan pada gambar di bawah ini:

Setelah didownload maka kita bebas mengedit dan upload balik ke akun kita tadi.

- Classify Flower Images Using Machine Learning & Python
- Flower Classification using Transfer Learning and CNN (Step-by-Step)
└── flowers
├── daisy
├── dandelion
├── flowers
│ ├── daisy
│ ├── dandelion
│ ├── rose
│ ├── sunflower
│ └── tulip
├── rose
├── sunflower
└── tulipDisini kita perlu download datanya di Kaggle (klik gambar di bawah):

Disini kita perlu daftar akun.

Setelah itu baru bisa kita download file zip.

Dalam proses yang pertama ini, kita ingin membagi datanya menjadi 3 bagian. yaitu train, test, dan validation. dengan proporsi (80,10,10).
├── dataset
│ ├── test
│ │ ├── daisy
│ │ ├── dandelion
│ │ ├── rose
│ │ ├── sunflower
│ │ └── tulip
│ ├── train
│ │ ├── daisy
│ │ ├── dandelion
│ │ ├── rose
│ │ ├── sunflower
│ │ └── tulip
│ └── validation
│ ├── daisy
│ ├── dandelion
│ ├── rose
│ ├── sunflower
│ └── tulipBerikut kode untuk babak awal dari sang penulis:

Di halaman ini sang penulis sarankan untuk pake Google Colab.

Jadi kira upload datanya ke Google Drive.

Sayangnya di Google Colab belum apa2 hasil outputnya sudah error.

Di halaman tertulis jika pakai lokal juga bisa.

Karena filenya notebook kita coba Jupyter Notebook bawaan instal dari Anaconda.

Karena itu kita coba opsi ini.
- Change Interpreter in Jupyter notebook
- Execute Python script within Jupyter notebook using a specific virtualenv
$ conda info --envs
$ conda.bat activate tf250
(tf250)$ conda install ipykernel
(tf250)$ python -m ipykernel install --user --name tf250 --display-name "Python 3.9 (tf250)"
(tf250)$ conda deactivate
$ exitBerikut tangkapan layarnya:

Tampilannya persis seperti kita masuk website karena dijalankan di localhost:

Ternyata di awal sudah error juga.

Di beberapa bagian lain juga error.

Kalau saya sudah lemas lihat error macam begini. Minimal mestinya awal² gak error. Apalagi bahasa Inggris juga ala kadarnya. Baca kalimatnya aja puyeng.

Untungnya di menunya kita bisa download halaman dengan kode python. Lumayan bisa kita pakai daripada ketik ulang atau copas baris perbaris.
Jadi kita balik lagi di pycharm sebagai pilihan terakhir.
Sebelum kita jalankan pycharm kita simak dahulu apa saja yang harus kita persiapkan.
Dari ulasan² sebelumnya pillow ini belum kita gunakan. Karena itu kita coba install.

Ternyata sudah terpasang. Jadi kita bisa langsung lanjut.
Setelah semua siap kita masukan kode paling awal.# extract melalui notebook jika diperlukan
# !unzip flowers-recognition.zip
import os
mypath= 'flowers/'
file_name = []
tag = []
full_path = []
for path, subdirs, files in os.walk(mypath):
for name in files:
full_path.append(os.path.join(path, name))
tag.append(path.split('/')[-1])
file_name.append(name)
import pandas as pd
# memasukan variabel yang sudah dikumpulkan pada looping di atas menjadi sebuah dataframe agar rapih
df = pd.DataFrame({"path":full_path,'file_name':file_name,"tag":tag})
df.groupby(['tag']).size()
tag
daisy 1538
dandelion 2110
rose 1568
sunflower 1468
tulip 1968
dtype: int64
#cek sample datanya
print(df.head())Kode ini diambil dari yang ada di paling awal (Lihat di bagian di bawah ini):

Walhasil bisa jalan tanpa error. Berarti bisa lanjut dengan pycharm. Mantap.

Berikutnya kita masukkan kode terusannya:
#load library untuk train test split
from sklearn.model_selection import train_test_split
#variabel yang digunakan pada pemisahan data ini
X= df['path']
y= df['tag']
# split dataset awal menjadi data train dan test
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.20, random_state=300)
# kemudian data test dibagi menjadi 2 sehingga menjadi data test dan data validation.
X_test, X_val, y_test, y_val = train_test_split(
X_test, y_test, test_size=0.5, random_state=100)
# menyatukan kedalam masing-masing dataframe
df_tr = pd.DataFrame({'path':X_train
,'tag':y_train
,'set':'train'})
df_te = pd.DataFrame({'path':X_test
,'tag':y_test
,'set':'test'})
df_val = pd.DataFrame({'path':X_val
,'tag':y_val
,'set':'validation'})
print('train size', len(df_tr))
print('val size', len(df_te))
print('test size', len(df_val))Kode ini diambil dari di halaman sang penulis (Lihat: Train test split):

Walhasil kode ini juga selamat, lolos tanpa error.

Lanjut kode berikutnya:
# melihat proporsi pada masing masing set apakah sudah ok atau masih ada yang ingin diubah
df_all = df_tr.append([df_te,df_val]).reset_index(drop=1)\
print('===================================================== \n')
print(df_all.groupby(['set','tag']).size(),'\n')
print('===================================================== \n')
#cek sample datanya
df_all.sample(3)Kode ini diambil dari halaman bagian ini:

Kode ini juga selamat tanpa error:

Nah di kode berikutnya baru masalah kita muncul.
Berikut kode yang saya maksud:# menghapus folder dataset jika diperlukan
#!rm -rf dataset/
import shutil
from tqdm.notebook import tqdm as tq
datasource_path = "flowers/"
dataset_path = "dataset/"
for index, row in tq(df_all.iterrows()):
#detect filepath
file_path = row['path']
if os.path.exists(file_path) == False:
file_path = os.path.join(datasource_path,row['tag'],row['image'].split('.')[0])
#make folder destination dirs
if os.path.exists(os.path.join(dataset_path,row['set'],row['tag'])) == False:
os.makedirs(os.path.join(dataset_path,row['set'],row['tag']))
#define file dest
destination_file_name = file_path.split('/')[-1]
file_dest = os.path.join(dataset_path,row['set'],row['tag'],destination_file_name)
#copy file from source to dest
if os.path.exists(file_dest) == False:
shutil.copy2(file_path,file_dest)
HBox(children=(FloatProgress(value=1.0, bar_style='info', max=1.0), HTML(value='')))Kode ini letaknya di bagian ini:

Berikut penampakan dari errornya:

Jadi ini masalahnya di tqdm salah satu modul dari python. Lucunya dia berasal dari bahasa Arab taqaddum yang artinya progress.
Dari pesan errornya ternyata modul tqdm ini belum ada terpasang.
Maka kita pasang di pycharm nya:

Packagenya bisa kita lihat di folder:

Selesai pasang kira² waktunya 15 menit:

Namun setelah dijalankan pesan errornya makin banyak:

Jadi masalahnya ternyata gak simpel. Kita akan bahas lebih detil. Berikut saya contohkan bagaimana cara saya cari solusi. Jadi ada gambaran sampai pemecahanya.
Cara termudah tentu kita cari di Google. kita bisa langsung klik kanan kalimat errornya terus pilih Search with Google:
Kita cari halaman yang ada kalimat paling mirip dengan kalimat errornya:

Di salah satu halaman ketemu jika kita harus istal Jupyter:

Setelah diinstal di pycharm ternyata masih juga error. Berikut saya salin kalimatnya:
Traceback (most recent call last):
File "C:\Users\Chetabahana\assets\_feeds\eksekusi\tensorflow\tensorflow\python\emulator\main.py", line 104, in <module>
shutil.copy2(file_path,file_dest)
File "C:\Users\Chetabahana\AppData\Local\Packages\anaconda3\envs\tf250\lib\shutil.py", line 435, in copy2
copyfile(src, dst, follow_symlinks=follow_symlinks)
File "C:\Users\Chetabahana\AppData\Local\Packages\anaconda3\envs\tf250\lib\shutil.py", line 264, in copyfile
with open(src, 'rb') as fsrc, open(dst, 'wb') as fdst:
FileNotFoundError: [Errno 2] No such file or directory: 'dataset/train\\daisy\\daisy\\2599662355_7782218c83.jpg'
0it [00:00, ?it/s]
Process finished with exit code 1Kelihatannya disini errornya lain lagi. Kali ini menyinggung si daisy.

Maka kita cek si daisy. Ternyata blank gk ada isinya:

Nah disini ketahuan salahnya dimana, ini sudah tinggal pengalaman yang membantu:

Setelah soal daisy muncul lagi error lain. Kali ini soal HBox.

Berikut saya salin kalimatnya:
Traceback (most recent call last):
File "C:\Users\Chetabahana\assets\_feeds\eksekusi\tensorflow\tensorflow\python\emulator\main.py", line 106, in <module>
HBox(children=(FloatProgress(value=1.0, bar_style='info', max=1.0), HTML(value='')))
NameError: name 'HBox' is not defined
Process finished with exit code 1HBox(children=(FloatProgress(value=1.0, bar_style='info', max=1.0), HTML(value='')))</code> Pantas saja jika dia ini samar karena sang penulisnya tidak menjadikannya masalah. Saya maklum karena dia yang penting dapat output dari program yang dia buat.

Jika kode ini dihilangkan maka pesan errornya hilang namun hasilnya janggal..

Dan ternyata memang masalah ini sulit dipecahkan. Susahnya cari solusi progress bar ini karena memang orang lain juga seperti penulis ini. Membiarkannya seperti itu.
- Errno 2 using python shutil.py No such file or directory for file destination
- How to fix “FileNotFoundError: [Errno 2]” in Python 3 with shutil.copy
$ conda info --envs
$ conda.bat activate tf250
(tf250)$ python -m pip install --user --upgrade pip
(tf250)$ pip install ipywidgets
(tf250)$ jupyter nbextension enable --py widgetsnbextension
(tf250)$ conda update -n base -c defaults conda
(tf250)$ conda install -c conda-forge ipywidgets
(tf250)$ conda install -c conda-forge nodejs
(tf250)$ node --version
(tf250)$ jupyter labextension install @jupyter-widgets/jupyterlab-manager
(tf250)$ jupyter labextension install js
(tf250)$ conda deactivate
$ exitBerikut penampakan di layar

Kiata tunggu setiap perintah selesai diproses.

Waktunya cukup lama kira² lebih satu (1) jam semuanya bisa terinstal

Namun hasilnya masih juga error. Disini kita harus sabar.

from tqdm.notebook import tqdm as tq
for index, row in tq(df_all.iterrows()):ubah ke
from tqdm import tqdm as tq
for index, row in tq(df_all.iterrows(), total=df_all.shape[0]):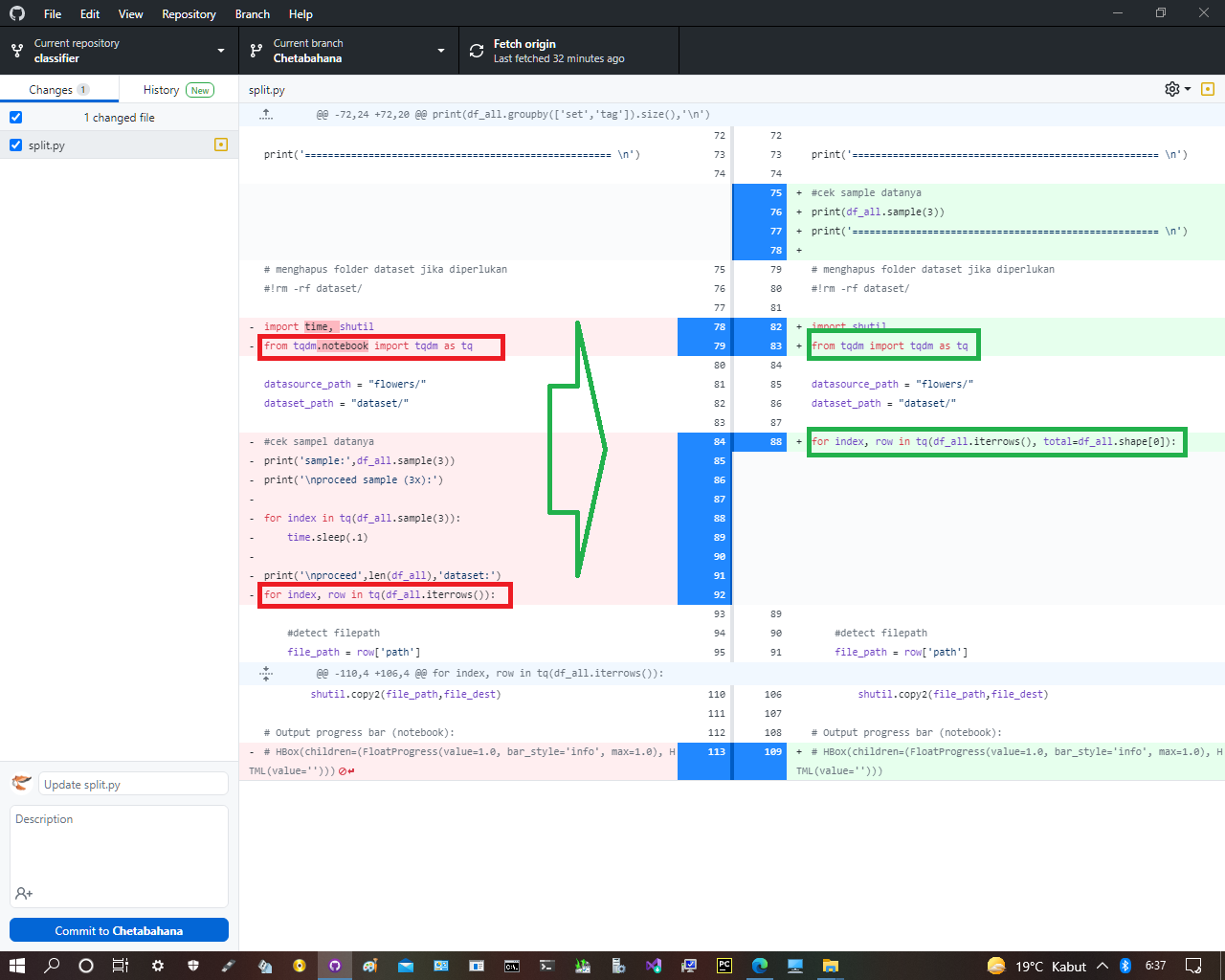
Berikut saya salin kode yang sudah benar secara keseluruhan sampai tahap ini
# extract melalui notebook jika diperlukan
# !unzip flowers-recognition.zip
import os
mypath= 'flowers/'
file_name = []
tag = []
full_path = []
for path, subdirs, files in os.walk(mypath):
for name in files:
full_path.append(os.path.join(path, name))
tag.append(path.split('/')[-1])
file_name.append(name)
import pandas as pd
# memasukan variabel yang sudah dikumpulkan pada looping di atas menjadi sebuah dataframe agar rapih
df = pd.DataFrame({"path":full_path,'file_name':file_name,"tag":tag})
df.groupby(['tag']).size()
#tag
#daisy 1538
#dandelion 2110
#rose 1568
#sunflower 1468
#tulip 1968
#dtype: int64
#cek sample datanya
print(df.head())
#load library untuk train test split
from sklearn.model_selection import train_test_split
#variabel yang digunakan pada pemisahan data ini
X= df['path']
y= df['tag']
# split dataset awal menjadi data train dan test
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.20, random_state=300)
# kemudian data test dibagi menjadi 2 sehingga menjadi data test dan data validation.
X_test, X_val, y_test, y_val = train_test_split(
X_test, y_test, test_size=0.5, random_state=100)
# menyatukan kedalam masing-masing dataframe
df_tr = pd.DataFrame({'path':X_train
,'tag':y_train
,'set':'train'})
df_te = pd.DataFrame({'path':X_test
,'tag':y_test
,'set':'test'})
df_val = pd.DataFrame({'path':X_val
,'tag':y_val
,'set':'validation'})
print('train size', len(df_tr))
print('val size', len(df_te))
print('test size', len(df_val))
# melihat proporsi pada masing masing set apakah sudah ok atau masih ada yang ingin diubah
df_all = df_tr.append([df_te,df_val]).reset_index(drop=1)\
print('===================================================== \n')
print(df_all.groupby(['set','tag']).size(),'\n')
print('===================================================== \n')
#cek sample datanya
print(df_all.sample(3))
print('===================================================== \n')
# menghapus folder dataset jika diperlukan
#!rm -rf dataset/
import shutil
from tqdm import tqdm as tq
datasource_path = "flowers/"
dataset_path = "dataset/"
for index, row in tq(df_all.iterrows(), total=df_all.shape[0]):
#detect filepath
file_path = row['path']
if os.path.exists(file_path) == False:
file_path = os.path.join(datasource_path,row['tag'],row['image'].split('.')[0])
#make folder destination dirs
if os.path.exists(os.path.join(dataset_path,row['set'],row['tag'])) == False:
os.makedirs(os.path.join(dataset_path,row['set'],row['tag']))
#define file dest
destination_file_name = file_path.split(os.sep)[-1]
file_dest = os.path.join(dataset_path,row['set'],row['tag'],destination_file_name)
#copy file from source to dest
if os.path.exists(file_dest) == False:
#print(file_path,'►',file_dest)
shutil.copy2(file_path,file_dest)
# Output progress bar (notebook):
# HBox(children=(FloatProgress(value=1.0, bar_style='info', max=1.0), HTML(value='')))Maka progress bar nya muncul..
Tentu ini lebih informatif daripada layar komputernya diam saja.

Jadi seperti itu kira² cara cari solusi. Jika beruntung kita bisa dapat solusi dalam sesaat. Namun tidak jarang bisa sampe berhari². Disini yang membantu tinggal kesabaran.
Kita lanjut ke babak selanjutnya.
Jadi sejauh ini kita baru melewati babak pertama. Untuk babak kedua saya sajikan terlebih dahulu halaman panjang yang memuat kode dari sang penulisnya.
Panjang juga kan halamannya. Nah kita mulai lagi jalankan kodenya..
Karena dataset kita sudah ready maka di babak kedua ini kita tidak perlu ulang kode python yang diuraikan di atas. Kita buka lembar baru dengan memasukan kode berikut ini:import tensorflow as tf
# Define Input Parameters
dim = (150, 150)
# dim = (456, 456)
channel = (3, )
input_shape = dim + channel
#batch size
batch_size = 16
#Epoch
epoch = 10
from tensorflow.keras.preprocessing.image import ImageDataGenerator
train_datagen = ImageDataGenerator(rescale=1. / 255,
shear_range=0.2,
zoom_range=0.2,
horizontal_flip=True)
val_datagen = ImageDataGenerator(rescale=1. / 255,
shear_range=0.2,
zoom_range=0.2,
horizontal_flip=True)
test_datagen = ImageDataGenerator(rescale=1. / 255,
shear_range=0.2,
zoom_range=0.2,
horizontal_flip=True)
# binary = [1,0,0,0,0] [0,1,0,0,0] [0,0,1,0,0] [0,0,0,1,0] [0,0,0,0,1]
# categorical = 1,2,3,4,5
train_generator = train_datagen.flow_from_directory('dataset/train/',
target_size=dim,
batch_size=batch_size,
class_mode='categorical',
shuffle=True)
val_generator = val_datagen.flow_from_directory('dataset/validation/',
target_size=dim,
batch_size=batch_size,
class_mode='categorical',
shuffle=True)
test_generator = test_datagen.flow_from_directory('dataset/test/',
target_size=dim,
batch_size=batch_size,
class_mode='categorical',
shuffle=True)
num_class = test_generator.num_classes
labels = train_generator.class_indices.keys()
print(labels)Jika ditemukan error tidak bisa import tensorflow maka kita pindahkan direktory project misalkan ke C:\ atau dekstop. Kemudian klik kanan foldernya dan pilih pycharm community.
Namun jika masih juga error maka lakukan instal ulang dengan perintah berkut:
$ conda.bat activate tf250
(tf250)$ pip install --upgrade --no-deps --force-reinstall tensorflow
(tf250)$ conda deactivate
$ exit
Jika tensorflow nya baik² saja mestinya kode ini lolos tanpa error:

Selajutnya kita jalankan lagi kode berikutnya:
# Membuat tf.data untuk kompabilitas yang lebih baik untuk tensorflow 2.1 (tf.keras)
def tf_data_generator(generator, input_shape):
num_class = generator.num_classes
tf_generator = tf.data.Dataset.from_generator(
lambda: generator,
output_types=(tf.float32, tf.float32),
output_shapes=([None
, input_shape[0]
, input_shape[1]
, input_shape[2]]
,[None, num_class])
)
return tf_generator
train_data = tf_data_generator(train_generator, input_shape)
test_data = tf_data_generator(test_generator, input_shape)
val_data = tf_data_generator(val_generator, input_shape)Kode ini juga lolos tanpa error.

Begitu juga kode terusannya:
# Membuat Struktur CNN
## Manualy define network
from tensorflow.keras import layers, Sequential
from tensorflow.keras.models import Model
from tensorflow.keras.layers import Conv2D, Activation, MaxPooling2D, Dropout, Flatten, Dense
model = Sequential()
model.add(Conv2D(128, (3, 3), padding='same', input_shape=input_shape))
model.add(Activation('relu'))
model.add(Conv2D(32, (3, 3)))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
model.add(Conv2D(64, (3, 3), padding='same'))
model.add(Activation('relu'))
model.add(Conv2D(64, (3, 3)))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
model.add(Flatten())
model.add(Dense(512))
model.add(Activation('relu'))
model.add(Dropout(0.5))
model.add(Dense(num_class))
model.add(Activation('softmax'))
# Compile the model
print('Compiling Model.......')
model.compile(optimizer='adam',
loss='categorical_crossentropy',
metrics=['accuracy'])
model.summary()Kode ini juda lolos tanpa masalah:

Nah di kode berikutnya masalah akan muncul lagi.
Berikut kode yang dimaksud:
# ## Using Pre-trained model / Transfer Learning
# ## Prebuild model
# ### Build Base Model
from tensorflow.keras.applications import MobileNetV2
# get base models
base_model = MobileNetV2(
input_shape=input_shape,
include_top=False,
weights='imagenet',
classes=num_class,
)
# ### Add top layer network
from tensorflow.keras import layers,Sequential
from tensorflow.keras.models import Model
#Adding custom layers
x = base_model.output
x = layers.GlobalAveragePooling2D()(x)
x = layers.Dropout(0.2)(x)
x = layers.Dense(1024, activation="relu")(x)
predictions = layers.Dense(num_class, activation="softmax")(x)
model = Model(inputs=base_model.input, outputs=predictions)
model.summary()
# Compile the model
print('Compiling Model.......')
model.compile(optimizer='adam',
loss='categorical_crossentropy',
metrics=['accuracy'])Penampakan layarnya seperti ini:
 Namun itu ternyata bukan masalah namum pemberitahuan saja
Namun itu ternyata bukan masalah namum pemberitahuan saja

Maka kita bisa lanjutkan.
Nah kali ini benar² muncul errornya di kode ini:
# ## Effinet
# !pip install -U --pre efficientnet
from efficientnet.tfkeras import EfficientNetB1
# ### Build Base model
# get base models
base_model = EfficientNetB1(
input_shape=input_shape,
include_top=False,
weights='noisy-student',
classes=num_class,
)
# ### Add top network layer to models
from tensorflow.keras import layers,Sequential
from tensorflow.keras.models import Model
#Adding custom layers
x = base_model.output
x = layers.GlobalAveragePooling2D()(x)
x = layers.Dropout(0.5)(x)
x = layers.Dense(1024, activation="relu")(x)
predictions = layers.Dense(num_class, activation="softmax")(x)
model = Model(inputs=base_model.input, outputs=predictions)
model.summary()
# Compile the model
print('Compiling Model.......')
model.compile(optimizer='adam',
loss='categorical_crossentropy',
metrics=['accuracy'])Penampakanya seperti ini:

Kita perlu instal yang namanya efficientnet. Ini adalah tool untuk grafik.
$ conda.bat activate tf250
(tf250)$ pip install -U --pre efficientnet
(tf250)$ conda deactivate
$ exitInsatalsinya berjalan lancar. Namun waktunya cukup panjang. Kira sejam.

Ketika dijalankan pesan yang sama akan tetap muncul. Jadi ini tidak biasa seperti modul yang lain karena dijalankannya harus via download oleh python.

Sejauh ini tak ada masalah yang signifikan, karena tidak ada pesan error lagi.

Masalahnya akan muncul di kode berikutnya:
# ## Visualize The final model
import tensorflow as tf
model_viz = tf.keras.utils.plot_model(model,
to_file='model.png',
show_shapes=True,
show_layer_names=True,
rankdir='TB',
expand_nested=True,
dpi=55)
model_viz
# # Train Model
# In[108]:
EPOCH = 2
history = model.fit(x=train_data,
steps_per_epoch=len(train_generator),
epochs=EPOCH,
validation_data=val_data,
validation_steps=len(val_generator),
shuffle=True,
verbose = 1)
history.history['loss']
history.history['accuracy']
# # Plot the training
from matplotlib import pyplot as plt
# Plot history: MAE
plt.plot(history.history['loss'], label='Training Loss')
plt.plot(history.history['val_loss'], label='Validation Loss')
plt.title('Training and Validation Loss')
plt.ylabel('value')
plt.xlabel('No. epoch')
plt.legend(loc="upper left")
plt.show()
# Plot history: MSE
plt.plot(history.history['accuracy'], label='Training Accuracy')
plt.plot(history.history['val_accuracy'], label='Validation Accuracy')
plt.title('Training and Validation Accuracy')
plt.ylabel('value')
plt.xlabel('No. epoch')
plt.legend(loc="upper left")
plt.show()
# # Save Model
import os
MODEL_BASE_PATH = "model"
PROJECT_NAME = "medium_project"
SAVE_MODEL_NAME = "model.h5"
save_model_path = os.path.join(MODEL_BASE_PATH, PROJECT_NAME, SAVE_MODEL_NAME)
if os.path.exists(os.path.join(MODEL_BASE_PATH, PROJECT_NAME)) == False:
os.makedirs(os.path.join(MODEL_BASE_PATH, PROJECT_NAME))
print('Saving Model At {}...'.format(save_model_path))
model.save(save_model_path,include_optimizer=False)
# # Evaluate Models
loss, acc = model.evaluate(test_data,steps=len(test_generator),verbose=0)
print('Accuracy on training data: {:.4f} \nLoss on training data: {:.4f}'.format(acc,loss),'\n')
loss, acc = model.evaluate(test_data,steps=len(test_generator),verbose=0)
print('Accuracy on test data: {:.4f} \nLoss on test data: {:.4f}'.format(acc,loss),'\n') Berikut penampakannya:

Selain itu juga muncul pesan otomatis dari pycharmnya:

Infonya kita sebaiknya beralih ke pycharm profesional karena lebih sesuai untuk kode yang kita jalankan.

Namun ternyata ada warning oleh Windows.

Jadi kita tetap di pycharm community saja. Apalagi sejauh ini masalah python nya bisa kita atasi satu persatu.
Ini persis seperti babak pertama maka di babak kedua pun masalahnya ada di ujung. Kali ini kasusnya adalah kita harus instal Visualisasi Grafik dari Graphviz.
$ conda.bat activate tf250
(tf250)$ pip install pydot
(tf250)$ pip install graphviz
(tf250)$ conda deactivate
$ exitSetelah itu kita cek di pycharm modulnya sudah masuk.

Untuk kedua modul sudah terinstalasi di pycharm.

Namun ketika dijalankan muncul error yang sama seperti sebelumnya.


Instalasi nya di Windows ternyata tidak mudah diikuti.

Jadi kita cari cara instal yang lebih simpel dan tepatnya.
- Image classification via fine-tuning with EfficientNet
- None of the MLIR optimization passes are enabled
$ conda.bat activate tf250
(tf250)$ pip uninstall -y pydot pydotplus graphviz
(tf250)$ conda install -y pydot pydotplus
(tf250)$ conda deactivate
$ exitBerdasarkan pencaharian online maka dua (baris) cmd ini bisa jadi solusi:

Berikutnya kita lanjut ke pycharm lagi.
Nah keluar epochnya. Jadi walaupun ada warning soal Graphic MLIR Optimization tapi minimal kita tahu setelan python nya sudah benar.

Tidak seperti Trend Analysis disini epoch nya berlangsung cukup lama, ini karena yang diiterasi adalah kalkulasi grafik atau gambar jadi akan bergantung ke kecepatan VGA nya.

Komputer saya Compute Capabilitynya 1.1, dia selesai dalam waktu kurang lebih satu (1) jam per epoch. Bila ingin akurasi yang lebih tinggi maka bisa sampai dua (2) jam lebih.

Bila kita gunakan spek yang tinggi tentu akan lebih cepat lagi seperti yang ditunjukkan di halaman sumber dengan menggunakan Google Colab:

Disini epoch akan berlangsung dua (2) kali. Begitu selesai yang kedua muncul grafik.

Grafik ini kita skrinshot jika perlu, kemudian kita tutup. Maka akan muncul grafik berikutnya.

Setelah grafiknya kita tutup maka python akan menyimpan model.h5. Model h5 ini adalah kuncinya. Dia ini yang jadi penentu hasil di babak selanjutnya.

Model h5 itu alur algoritmanya sangat panjang. kita dapat lihat dengan klik file model.png

Model pertama merupakan model.h5 yang tanpa optimizer dan model2.h5 adalah model dengan optimizer didalamnya.

Saving Model At model\medium_project\model.h5...
C:\Users\Chetabahana\AppData\Local\Packages\anaconda3\envs\tf250\lib\site-packages\tensorflow\python\keras\utils\generic_utils.py:494:
CustomMaskWarning: Custom mask layers require a config and must override get_config.
When loading, the custom mask layer must be passed to the custom_objects argument.
warnings.warn('Custom mask layers require a config and must override get_config')Namun ini ternyata berupa bug saja, jadi bisa kita abaikan.

import tensorflow as tf
# Define Input Parameters
dim = (150, 150)
# dim = (456, 456)
channel = (3, )
input_shape = dim + channel
#batch size
batch_size = 16
#Epoch
epoch = 10
from tensorflow.keras.preprocessing.image import ImageDataGenerator
train_datagen = ImageDataGenerator(rescale=1. / 255,
shear_range=0.2,
zoom_range=0.2,
horizontal_flip=True)
val_datagen = ImageDataGenerator(rescale=1. / 255,
shear_range=0.2,
zoom_range=0.2,
horizontal_flip=True)
test_datagen = ImageDataGenerator(rescale=1. / 255,
shear_range=0.2,
zoom_range=0.2,
horizontal_flip=True)
# binary = [1,0,0,0,0] [0,1,0,0,0] [0,0,1,0,0] [0,0,0,1,0] [0,0,0,0,1]
# categorical = 1,2,3,4,5
train_generator = train_datagen.flow_from_directory('dataset/train/',
target_size=dim,
batch_size=batch_size,
class_mode='categorical',
shuffle=True)
val_generator = val_datagen.flow_from_directory('dataset/validation/',
target_size=dim,
batch_size=batch_size,
class_mode='categorical',
shuffle=True)
test_generator = test_datagen.flow_from_directory('dataset/test/',
target_size=dim,
batch_size=batch_size,
class_mode='categorical',
shuffle=True)
num_class = test_generator.num_classes
labels = train_generator.class_indices.keys()
print(labels)
# Membuat tf.data untuk kompabilitas yang lebih baik untuk tensorflow 2.1 (tf.keras)
def tf_data_generator(generator, input_shape):
num_class = generator.num_classes
tf_generator = tf.data.Dataset.from_generator(
lambda: generator,
output_types=(tf.float32, tf.float32),
output_shapes=([None
, input_shape[0]
, input_shape[1]
, input_shape[2]]
,[None, num_class])
)
return tf_generator
train_data = tf_data_generator(train_generator, input_shape)
test_data = tf_data_generator(test_generator, input_shape)
val_data = tf_data_generator(val_generator, input_shape)
# Membuat Struktur CNN
## Manualy define network
from tensorflow.keras import layers, Sequential
from tensorflow.keras.models import Model
from tensorflow.keras.layers import Conv2D, Activation, MaxPooling2D, Dropout, Flatten, Dense
model = Sequential()
model.add(Conv2D(128, (3, 3), padding='same', input_shape=input_shape))
model.add(Activation('relu'))
model.add(Conv2D(32, (3, 3)))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
model.add(Conv2D(64, (3, 3), padding='same'))
model.add(Activation('relu'))
model.add(Conv2D(64, (3, 3)))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
model.add(Flatten())
model.add(Dense(512))
model.add(Activation('relu'))
model.add(Dropout(0.5))
model.add(Dense(num_class))
model.add(Activation('softmax'))
# Compile the model
print('Compiling Model.......')
model.compile(optimizer='adam',
loss='categorical_crossentropy',
metrics=['accuracy'])
model.summary()
# ## Using Pre-trained model / Transfer Learning
# ## Prebuild model
# ### Build Base Model
from tensorflow.keras.applications import MobileNetV2
# get base models
base_model = MobileNetV2(
input_shape=input_shape,
include_top=False,
weights='imagenet',
classes=num_class,
)
# ### Add top layer network
from tensorflow.keras import layers,Sequential
from tensorflow.keras.models import Model
#Adding custom layers
x = base_model.output
x = layers.GlobalAveragePooling2D()(x)
x = layers.Dropout(0.2)(x)
x = layers.Dense(1024, activation="relu")(x)
predictions = layers.Dense(num_class, activation="softmax")(x)
model = Model(inputs=base_model.input, outputs=predictions)
model.summary()
# Compile the model
print('Compiling Model.......')
model.compile(optimizer='adam',
loss='categorical_crossentropy',
metrics=['accuracy'])
# ## Effinet
# !pip install -U --pre efficientnet
from efficientnet.tfkeras import EfficientNetB1
# ### Build Base model
# get base models
base_model = EfficientNetB1(
input_shape=input_shape,
include_top=False,
weights='noisy-student',
classes=num_class,
)
# ### Add top network layer to models
from tensorflow.keras import layers,Sequential
from tensorflow.keras.models import Model
#Adding custom layers
x = base_model.output
x = layers.GlobalAveragePooling2D()(x)
x = layers.Dropout(0.5)(x)
x = layers.Dense(1024, activation="relu")(x)
predictions = layers.Dense(num_class, activation="softmax")(x)
model = Model(inputs=base_model.input, outputs=predictions)
model.summary()
# Compile the model
print('Compiling Model.......')
model.compile(optimizer='adam',
loss='categorical_crossentropy',
metrics=['accuracy'])
# ## Visualize The final model
#import tensorflow as tf
model_viz = tf.keras.utils.plot_model(model,
to_file='model.png',
show_shapes=True,
show_layer_names=True,
rankdir='TB',
expand_nested=True,
dpi=55)
model_viz
# # Train Model
EPOCH = 2
history = model.fit(x=train_data,
steps_per_epoch=len(train_generator),
epochs=EPOCH,
validation_data=val_data,
validation_steps=len(val_generator),
shuffle=True,
verbose = 1)
history.history['loss']
history.history['accuracy']
# # Plot the training
from matplotlib import pyplot as plt
# Plot history: MAE
plt.plot(history.history['loss'], label='Training Loss')
plt.plot(history.history['val_loss'], label='Validation Loss')
plt.title('Training and Validation Loss')
plt.ylabel('value')
plt.xlabel('No. epoch')
plt.legend(loc="upper left")
plt.show()
# Plot history: MSE
plt.plot(history.history['accuracy'], label='Training Accuracy')
plt.plot(history.history['val_accuracy'], label='Validation Accuracy')
plt.title('Training and Validation Accuracy')
plt.ylabel('value')
plt.xlabel('No. epoch')
plt.legend(loc="upper left")
plt.show()
# # Save Model
import os
MODEL_BASE_PATH = "model"
PROJECT_NAME = "medium_project"
SAVE_MODEL_NAME = "model.h5"
save_model_path = os.path.join(MODEL_BASE_PATH, PROJECT_NAME, SAVE_MODEL_NAME)
if os.path.exists(os.path.join(MODEL_BASE_PATH, PROJECT_NAME)) == False:
os.makedirs(os.path.join(MODEL_BASE_PATH, PROJECT_NAME))
print('Saving Model At {}...'.format(save_model_path))
model.save(save_model_path,include_optimizer=False)
# # Evaluate Models
loss, acc = model.evaluate(test_data,steps=len(test_generator),verbose=0)
print('Accuracy on training data: {:.4f} \nLoss on training data: {:.4f}'.format(acc,loss),'\n')
loss, acc = model.evaluate(test_data,steps=len(test_generator),verbose=0)
print('Accuracy on test data: {:.4f} \nLoss on test data: {:.4f}'.format(acc,loss),'\n') Berikutbya kita bahas babak ketiga atau terakhir.
Selanjutnya adalah melakukan test prediksi berdasarkan pada model yang kita simpan yaitu model.h5. Untuk kode lengkapnya saya salin seperti berikut ini:
# Define params and lib
import requests
from io import BytesIO
from PIL import Image
import numpy as np
# Parameters
input_size = (150,150)
#define input shape
channel = (3,)
input_shape = input_size + channel
#define labels
labels = ['daisy', 'dandelion', 'rose', 'sunflower', 'tulip']
# # Define preprocess function
def preprocess(img,input_size):
nimg = img.convert('RGB').resize(input_size, resample= 0)
img_arr = (np.array(nimg))/255
return img_arr
def reshape(imgs_arr):
return np.stack(imgs_arr, axis=0)
## Load models
from tensorflow.keras.models import load_model
# ada 2 cara load model, jika cara pertama berhasil maka bisa langsung di lanjutkan ke fungsi prediksi
MODEL_PATH = 'model/medium_project/model.h5'
model = load_model(MODEL_PATH,compile=False)
# # Predict the image
# read image
im = Image.open('contoh_prediksi.jpg')
X = preprocess(im,input_size)
X = reshape([X])
y = model.predict(X)
print( labels[np.argmax(y)], np.max(y) )
print( labels[np.argmax(y)], np.max(y) )
# read image
im = Image.open('dataset/train/dandelion/2522454811_f87af57d8b.jpg')
X = preprocess(im,input_size)
X = reshape([X])
y = model.predict(X)
print( labels[np.argmax(y)], np.max(y) )Letak persis kodenya ada di bagian halaman ini:

Kode ini tidak ada masalah sepanjang model.h5 yang disimpan sudah benar.
Berikut ini cara untuk menjalankannya.
- ValueError: Unknown layer: FixedDropout
- [KERAS] Error Valueerror: unknown activity function:Unknown layer:FixedDropout

Gambar ini kita masukkan kedalam foldernya dan diber nama: contoh_prediksi.jpg

Hasilnya ada dua (2) kemungkinan.
Jika model.h5 nya bermasalah maka outputnya juga berantakan seperti ini:
Jika Ok maka hasilnya adalah seperti gambar di bawah. Variabel y merupakan nilai dari hasil prediksi yang menghasilkan banyak nilai. Di mana nilai-nilai tersebut adalah nilai dari masing-masing kategori.

Namun kesimpulannya program secepat dan secanggih apapun semua itu hanya membantu. Yang jauh lebih penting adalah justru setelannya benar apa belum.
Dan tentunya juga apa yang mau kita buat dengannya.
Sekian.

{kind=link}