DetailsInRunningOnHeroku2017
彼がgitコマンドを起動するのはドイツに居る開発者が遅れてやってきた眠気に従い始める頃だ。「毎日この時間になるといくつかmerge commitが届いてるものなんですよ」職人はほほえみつつ、upstream/masterからfetchしたcommitたちをmasterに迎え入れる。「ええ、スムースなもんですよね」職人はおもむろに本番用のブランチを取り出しmasterをmergeする。「うちのブランチはできるだけupstreamから離れないようにしてますので」 conflictもなくmergeされていく更新内容。
「中身の確認?そんなものは壊れてからやればいいんだよ」Master職人はそういいながら実行環境にmergeした内容をpushしていく。「ほら、だいたい動くんだよ。これでてきとーにtootを」
Master職人の手が止まる。
というわけで、ぼっちインスタンス https://mastodon.zunda.ninja/ をHerokuで運用して気づいたあれこれを記しておきます。Herokuでの、より一般的なインスタンスの運用については https://github.com/zunda/mastodon/wiki にまとめてありますので参照してみてください。
この記事はMastodon Advent Calendar 2017の12月12日分です。11日分はabcangさんの『Mastodonのエラー情報をErrbitで収集してみる』でした。13日分はぜま✅クラゲ丼鯖缶さんの『マストドンで学術インスタンスみたいなものをやろうとしたらわりと異端だった』です。
Mastodonはweb (Puma)、worker (Sidekiq)それぞれ1 dynoを割り当てるようにコードが書かれていますが、Herokuでは、CPU負荷よりもメモリが主な制限になっているようです。Pumaのプロセスあたりのスレッド数を減らして、PumaとSidekiqをメモリ512MBのdyno 1台に詰め込んで運用しています。
アプリケーションのコードを変更した場合には、Herokuへのコードのプッシュ (git push heroku masterやGitHub Integrationなど)によってアプリケーションのビルド(依存パッケージのインストールやアセットのプリコンパイル)やデータベースのマイグレーションが実行されます。プロセス数やスレッド数の調整の時には待ってられない!というわけで、Dynoの再起動で変更できるconfig varに設定しておきます。
Stream API用のDynoはタイムラインを眺めている時のみ必要なので、Free dynoでオートスケールもどきしてみます。同じコードをデプロイして、RUN_STREAMING config varで動作を分けます。
というわけでProcfile:
web: if [ "$RUN_STREAMING" != "true" ]; then BIND=0.0.0.0 puma -C config/puma.rb & fi; if [ "$RUN_WORKER" == "true" ]; then sidekiq -c ${SIDEKIQ_THREADS:-5} & fi; if [ "$RUN_STREAMING" == "true" ]; then BIND=0.0.0.0 node ./streaming & fi; wait -n; kill -SIGTERM -$$; wait
worker: sidekiq -c ${SIDEKIQ_THREADS:-5}
release: if [ "$RUN_STREAMING" != "true" ]; then rake db:migrate; else echo Not migrating on this app; fi
web dynoでどのプロセスを走らせるか、下記のconfig varで決められるようにしてあります。Herokuではリクエストはポート80か443でしか受けられないので、ストリーミングサーバ(npm start)は別のアプリケーションのweb dynoで走らせます。
-
RUN_STREAMING:trueのときはこのアプリケーションではnpm startします。そうではない場合にはpumaを走らせます -
RUN_WORKER:trueのときはweb dynoでsidekiqも起動します
pumaやsidekiqをバックグラウンドで起動しておき、いずれかのプロセスが停止してしまった場合にはwait -nからkillに制御が進みすべてのプロセスにSIGTERMを送ることでdynoを再起動します。
worker dynoではいつでもsidekiqを走らせます。必要な時だけスケールアップします。
release dynoではデプロイのときにrake db:migrateを走らせます。RUN_STREAMINGがtrueになっているアプリでは何もしません。
.profileとして下記を書いておき、シェルがdynoのメインプロセスになった場合、SIGTERMによってdynoが即座に停止してしまわないようにします。
プロセス数とスレッド数の設定は、Procfileでコマンドラインオプションとして伝えているものと、アプリケーションのコードで受けているものがあります。STREAMING_CLUSTER_NUMはストリーミング用のアプリケーションに設定してあります。
| 項目 | 設定ファイル | config var | 内容 |
|---|---|---|---|
| Puma worker(プロセス)数 | config/puma.rb |
WEB_CONCURRENCY |
1 |
| Puma スレッド数 | config/puma.rb |
MAX_THREADS |
3 |
| Pumaからのデータベース接続数 | config/database.yml |
DB_POOL |
6 |
| Sidekiq スレッド数 |
Procfileでsidekiq -c ${SIDEKIQ_THREADS:-5}
|
SIDEKIQ_THREADS |
1 |
| npm worker数 | streaming/index.js |
STREAMING_CLUSTER_NUM |
3 |
DB_POOLは、MAX_THREADSの2倍にしてあります。rack-timeoutがタイムアウトを検出した時に、コネクションプールを行方不明にしちゃうことがあるので、予備を用意してあります。rack-timeoutのタイムアウトも長めにしてコネクションプールが行方不明になりにくくしてます。
config/initializers/timeout.rb:
Rack::Timeout::Logger.disable
Rack::Timeout.service_timeout = false
if Rails.env.production?
Rack::Timeout.service_timeout = ENV.fetch('SERVICE_TIMEOUT') { 90 }.to_i
Rack::Timeout.wait_timeout = ENV.fetch('WAIT_TIMEOUT') { 30 }.to_i
Rack::Timeout.wait_overtime = ENV.fetch('WAIT_OVERTIME') { 60 }.to_i
end
現在は、下記で、1日に1度の再起動までコネクションプールを使い切ることもなく、そこそこ安定して動いてくれてます。データベース安くて遅いし、長めに。
| config var | 内容 |
|---|---|
SERVICE_TIMEOUT |
180 |
WAIT_TIMEOUT |
150 |
メトリクスを眺めていると時々dynoのメモリの使用量にスパイクが乗ります。ログを眺めてるとPaperclipがImageMagickのコマンドを実行している時に対応しているもよう。レスポンス時間やCPU負荷には影響は少ないようです。放っておこう。
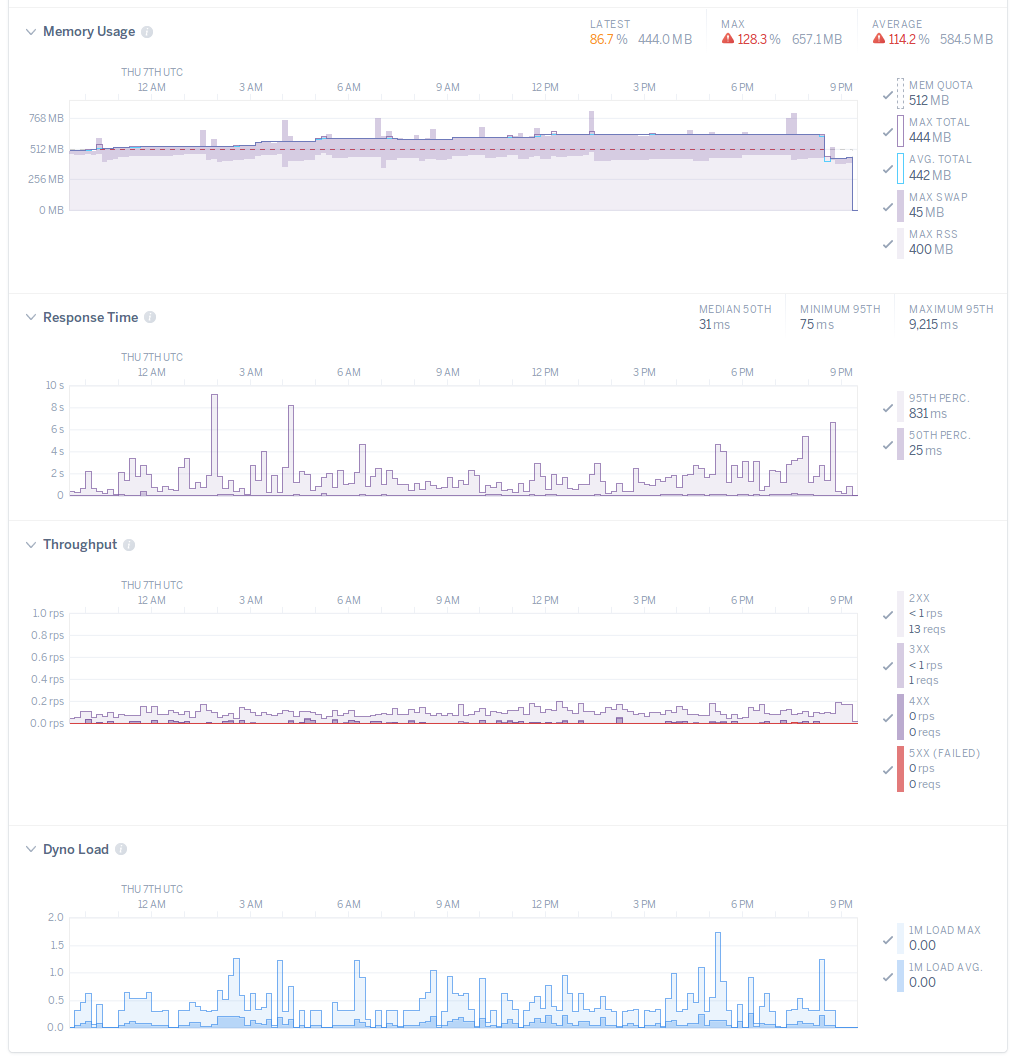
しかーし。HerokuのCommon Runtimeではメモリをあまり多く使いすぎるとR15 - Memory quota vastly exceededエラーが記録されてdynoが停止されます。Matodonだと受け取るメディアファイルの大きさによって時折このエラーが記録されてしまいます。valgrindで試してみたところだいたいMAGICK_MEMORY_LIMIT (バイト)で指定したメモリ量まで使うようになるようす。
512MBのメモリと同じくらいはスワップにつっこめるように見えるので、2枚同時に大きいメディアファイルが来ても生きていけるように、256MBくらいに制限してみます。
heroku config:set MAGICK_MEMORY_LIMIT=268435456
それでもR15が出る時は出る。
コードの更新にはHeroku Pipelinesを使うと楽です。Staging段に試験用のアプリケーションを置いておき、GitHubのレポジトリをPipelineに連携しておいて、インスタンス用のブランチにpushがあった場合にビルドが走るように設定しておきます。
更新されたコードのマージは手元でおこないます。bundle install等は手元ではおこなわないので、gitだけ動くようにしておきます。
originリモートが自分のレポジトリ、upstreamリモートがtootsuite/mastodonのワーキングコピーを用意します。
git clone [email protected]:ユーザー名/mastodon.git
cd mastodon
git remote add upstream https://github.com/tootsuite/mastodon.git
git checkout -b インスタンス用のブランチ
git push -u origin インスタンス用のブランチ
インスタンス用のブランチに変更点をコミットします。動作試験のためにはbundle installできる環境が必要ですね。
git checkout インスタンス用のブランチ
vi いじるファイル
git add いじるファイル -m 'いじった理由'
git commit
Release Phaseでデータベースのマイグレーションが走るようにしておくと便利です。Procfileに下記のような行を加えておきます。
release: rake db:migrate
ストリーミング用のアプリも作る場合は例えば上に書いたようにストリーミング用のアプリではマイグレーションが走らないようにしておきます。
まじマージ。更新内容をざっと確認してから、自分のレポジトリのmasterブランチはupstreamリモートに合わせておきます。
git fetch upstream
git log upstream/master...master
git checkout master
git rebase upstream/master
git push
git checkout インスタンス用のブランチ
git merge master
コンフリクトがあった場合にはがんばって解消します。git add ファイル名してgit commit。
マージできたら自分のレポジトリにプッシュします。Heroku Pipelinesがビルドを始めてくれます。
git push
ビルドとマイグレーションを眺める。
heroku builds:output -a ステージングのアプリ名; heroku logs -t -a ステージングのアプリ名
ステージングのアプリをちょっと使ってみる。うまくいったら、本番のアプリケーションにslugをプロモートして、マイグレーションと再起動を眺める。
heroku pipelines:promote -a ステージングのアプリ名; heroku logs -t -a 本番のアプリ名
Herokuにデプロイすると、アプリケーションをビルドする環境でソースコードのcommit hashをSOURCE_VERSION環境変数から参照できます。これを利用して、assetのプリコンパイルの一環としてソースコードのURLを生成します。rake assets:precompileするとconfig/initializers/version.rbが生成されます。
lib/tasks/version.rake:
namespace :source do
desc 'Record source version'
task :version do
hash = ENV['SOURCE_VERSION'] # available on Heroku while build
if hash.blank?
begin
hash = `git show --pretty=%H 2>/dev/null`.strip
# ignore the error: fatal: Not a git repository
rescue Errno::ENOENT # git command is not available
end
end
unless hash.blank?
hash_abb = hash[0..7]
mastodon_version_to_s = Mastodon::Version.to_s
File.open('config/initializers/version.rb', 'w') do |f|
f.write <<~_TEMPLATE
# frozen_string_literal: true
module Mastodon
module Version
module_function
def to_s
"#{mastodon_version_to_s} at #{hash_abb}"
end
def source_base_url
'https://github.com/zunda/mastodon'
end
def source_tag
"#{hash}"
end
end
end
_TEMPLATE
end
end
end
end
task 'assets:precompile' => ['source:version']
いろいろ入ってる。
$ heroku addons
Add-on Plan Price State
──────────────────────────────────────────────── ─────────── ──────── ───────
deployhooks (deployhooks-infinite-93817) http free created
└─ as DEPLOYHOOKS
heroku-postgresql (postgresql-aerodynamic-17416) hobby-basic $9/month created
├─ as DATABASE
├─ as PG_HOBBY_BASIC
└─ as DATABASE on ストリーミング用 app
heroku-redis (redis-round-39057) hobby-dev free created
├─ as REDIS
└─ as REDIS on ストリーミング用 app
librato (librato-colorful-53637) development free created
└─ as LIBRATO
logentries (logentries-shallow-65441) le_tryit free created
└─ as LOGENTRIES
mailgun (mailgun-graceful-35097) starter free created
└─ as MAILGUN
rollbar (rollbar-asymmetrical-52355) free free created
└─ as ROLLBAR
scout (scout-spherical-94295) chair free created
└─ as SCOUT
The table above shows add-ons and the attachments to the current app (zundan-mastodon) or other apps.
Mastodonに必要なデータサービス。
プロダクション用のHeroku Postgresは$50/月から。値段に見合う性能と信頼性はあると思うけど趣味にはちょっと高い。格納できる行数の十分なHobby Basicプラン($9/月)をつかってます。キャッシュメモリが無いので遅いよ。
Heroku Redisも趣味用のはインスタンスが落ちた場合に記憶が消えます。このインスタンスでは夏に一度消えましたが、一時的にタイムラインが消える以外の大きな問題はなかった、はず。アプリのダッシュボードから遡れる記録も記憶が消えたあとものものになります。
Rollbarにリリースがあったことを教えてあげます。
メトリクスを可視化してくれます。無料版なので最近60分のみだけど、デプロイ後にながめるのが楽しい。
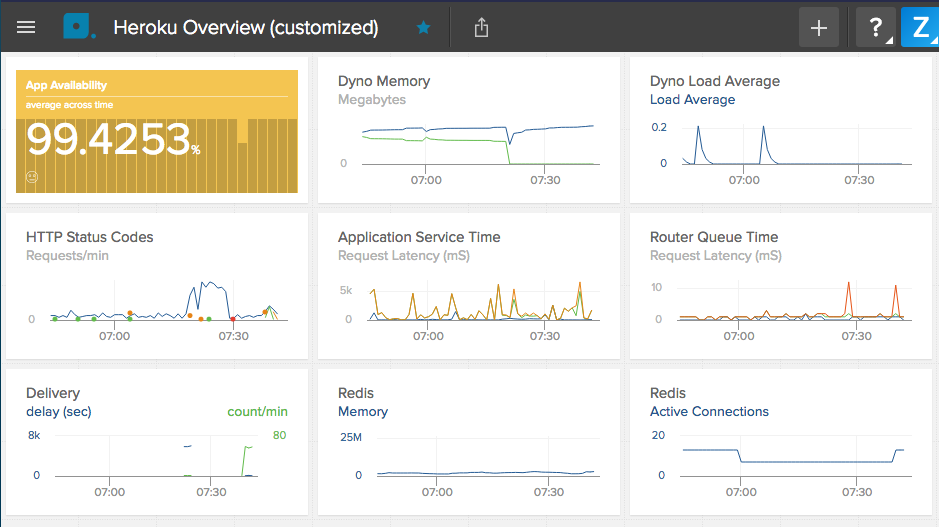
最近24時間のメトリクスはHerokuのダッシュボードから見られます。
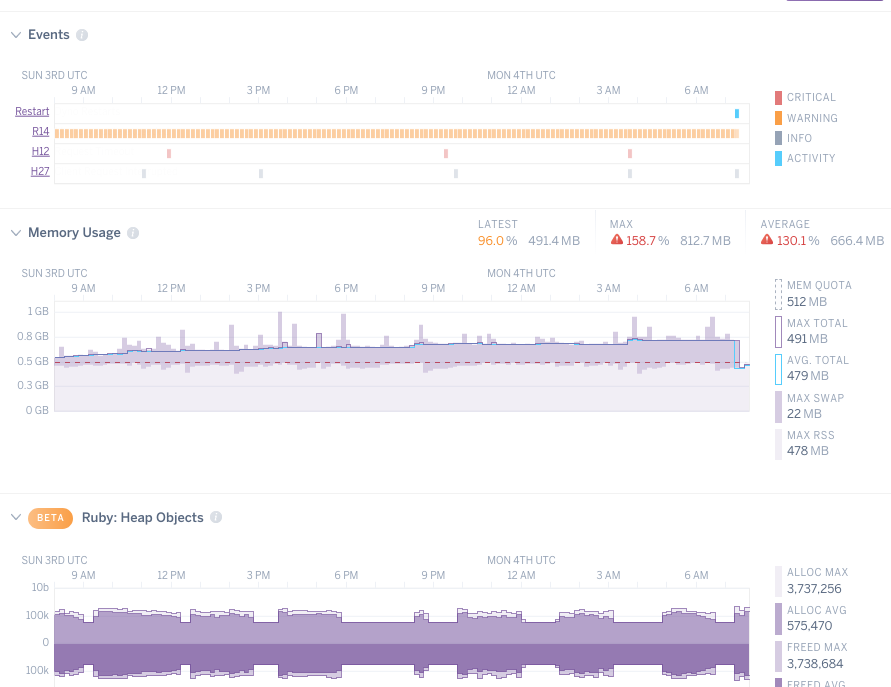
Rubyのメモリアロケーションとガベージコレクションを眺めるには、Gemfileに下記を追加し、heroku/metrics buildpackを加えます。
gem 'barnes'
$ heroku buildpacks -a ステージングのアプリ
=== Buildpack URLs
1. heroku/metrics
:
アプリログを取っておいてくれます。個人的にはPapertrailの方が使いやすいんだけど、無料版だと1日の行数があふれちゃうのだ。
メールの送信。当初はメールを送らずにアカウントの登録をする手段が入っていなかったので使ってます。トゥートの通報をした時に、リモートに行くと思ってた通知はローカルに来て、adminとしてメールを受け取りました。
例外を記録してくれます。リモートへの配送で起きる例外も拾ってくれて、無料版の件数は溢れてしまう。もうしわけない…
コード内からレポートを送信するよう、Gemfileに下記を追加します。
gem 'rollbar'
New Relic APMと同様、アプリケーション内のメトリクスを記録してくれます。Rubyに特化されていて、エンドポイントごとに消費時間や消費メモリの増加量、データベースへのクエリの時間などをわかりやすく教えてくれる。1日ごとのイベント数がときどき溢れてしまいます。もうしわけないもうしわけない。
コード内からレポートを送信するよう、Gemfileに下記を追加します。
gem 'scout_apm', '>= 2.3.0.pre2', '< 3.0.pre'
Add-onではないけれど。
バルス祭りでpumaからのレスポンスだけではなくsidekiqの稼働状況も監視したいと気づいたので、プルリクエストを出してみたのですが、「それstatsdでできるで」って。
DataDogに無料枠があるようなので、アカウントを作ってMastodonからメトリクスを送るようにしてみました。
アプリのビルドが起きるステージングのアプリには、DataDogのbuildpackを追加しておきます。他にもいろいろ入ってる。
$ heroku buildpacks -a ステージングのアプリ
=== Buildpack URLs
:
2. https://github.com/DataDog/heroku-buildpack-datadog.git
:
本番のアプリにはconfig varでDatadogとstatsdの設定を伝えます。
$ heroku config
:
DD_API_KEY: ********************************
:
STATSD_ADDR: localhost:8125
:
これでRailsやSidekiqが記録してくれるようになる多くのメトリクスをDatadog上で確認できるようになります。例えば大手インスタンスが落ちていた時のリトライキューの増加。
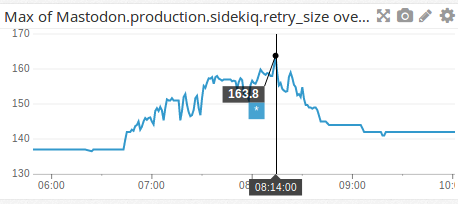
楽しい。
ここで、雪餅さんはPrometheusで収集したメトリクスをGrafanaで可視化しておられます。Mastodon Advent Calendar 2017 6日目のMastodon の Sidekiq 統計情報を収集・閲覧する。をご覧ください!
(2017-12-13追記)
HobbyプランのHeroku Postgresはキャッシュが無くてテーブル掃いたりするとちょっと遅い。https://mastodon.zunda.ninja/about/more に表示されるユーザー数、トゥート数、連合先の数はそれほど最新じゃなくても問題ない(よね?)ので、app/presenters/instance_presenter.rbを編集して、一度数えたら長めにキャッシュするようにしてあります。Rails.cacheはRedisを使ってくれるみたいで、Dynoを再起動してもキャッシュは消えません。
--- a/app/presenters/instance_presenter.rb
+++ b/app/presenters/instance_presenter.rb
@@ -17,15 +17,15 @@ class InstancePresenter
end
def user_count
- Rails.cache.fetch('user_count') { User.confirmed.count }
+ @user_count ||= Rails.cache.fetch('user_count', expires_in: 37.hours) { User.confirmed.count }
end
def status_count
- Rails.cache.fetch('local_status_count') { Account.local.sum(:statuses_count) }
+ @status_count ||= Rails.cache.fetch('local_status_count', expires_in: 11.hours) { Account.local.sum(:statuses_count) }
end
def domain_count
- Rails.cache.fetch('distinct_domain_count') { Account.distinct.count(:domain) }
+ @domain_count ||= Rails.cache.fetch('distinct_domain_count', expires_in: 17.hours) { Account.distinct.count(:domain) }
end
def version_number(2017-12-25追記)
ぼっちインスタンスでは、ローカルタイムラインを生成する下記のようなクエリが遅いことがあるようです。
SELECT "statuses"."id", "statuses"."updated_at" FROM "statuses" LEFT OUTER JOIN "accounts" ON "accounts"."id" = "statuses"."account_id" WHERE ("statuses"."local" = ? OR "statuses"."uri" IS NULL) AND "statuses"."visibility" = ? AND (statuses.reblog_of_id IS NULL) AND (statuses.reply = FALSE OR statuses.in_reply_to_account_id = statuses.account_id) AND "accounts"."silenced" = ? ORDER BY "statuses"."id" DESC LIMIT ?
statusテーブルの最近のデータがリモート多め未収載多めだったりしてLTLに出せるトゥートが少ないと遅くなるらしく、部分インデックスの作成で改善できるとのこと。
> CREATE INDEX accounts_not_silenced ON accounts using btree (id)
WHERE not silenced;
Time: 5044.809 ms
> CREATE INDEX statuses_public_local ON statuses using btree (id)
WHERE "statuses"."visibility" = 0
AND (statuses.reblog_of_id IS NULL)
AND (statuses.reply = FALSE OR statuses.in_reply_to_account_id = statuses.account_id)
AND ("statuses"."local" = TRUE OR "statuses"."uri" IS NULL);
Time: 69976.339 ms