上一篇文章已经尝试利用gplearn对波士顿房价数据进行了实验性的测试,这次继续深入尝试一下。当然最终目标还是服务于自己最近尝试的Kaggle竞赛项目。
进行实际操作前还是想理清一下特征组合的基本原理,以便用特征组合这种工具更好的提升模型效果,这里以二分类问题来梳理一下。


单个特征视角 0 和 1 两个label在单一特征上有不同的分布,最理想的分布当然是两个分布完全分离没有交集,这样但从一个特征就能做好分类工作,但实际情况大多是两个分布有重合,如果人工建模,当然我会选择用黑线位置的这个特征的值来区分两种标签,因为不是准确的区分,利用这种特征进行预测还会有一个准确率。
当用多个特征对目标进行预测的时候,就好像是有很多的评委在一个演员进行打分,而且他的打分还有一定权重。为了简化问题,就不加入权重的分析。
举个例子
label 00000 11111
feature1 10000 11110
feature2 01000 11101
feature3 00100 11011
上边这个简单的用三个特征预测的例子,每个特征的在整个数据集上都预测错了2个,准确率都是80%,当用三个特征预测是可以达到100%的准确率。
label 00000 11111
feature1 11000 11100
feature2 01100 11001
feature3 00011 00111
predict 01000 11101
甚至即使单个特征预测准确率很低,也能够构建出一个相对准确率较高的模型。例如这个例子的三个特征各自的准确率都只有60%,但是综合的准确率可以提升到80%
label 00000 11111
feature1 11000 11100
feature2 01100 11001
feature3 00110 10011
predict 01100 11001
这种情况下,综合三个特征进行的预测是没有提升的,每个特征和最后的预测都只停留在了60%。
道理其实很简单,特征预测错误的样本相对集中,导致单个特征预测的错误也集中反映在了特征集合预测的结果上。可以设想如果各个特征预测的错误都很集中,即使再多的特征,也不能提升预测效果,过多的特征还会成为计算负担,浪费模型的宝贵计算时间。
综合上面的几个例子,我想想总结一下好的特征的特点:
- 单个特征预测的准确性高
- 预测错误的样本和和其他特征预测的不一样
用学术点的语言,我们希望找到的特征之间是相互独立的,这样的误差也才能够是相互独立的,这样综合所有特征才能有效减小模型的偏差。 但实际项目中很少有特征真的能够相互独立,特征之间的相关性有时候还很高,举个泰坦尼克生存预测的例子。

例如票价和船舱等级就是有很高的相关性,这也是我们研究特征相关性的目的。
以上思想指导特征组合的思路,其实就是 组合和目标相关性高的特征, 但是和其他特征相关性要低。
在上一篇文章中通过波士顿房价数据实验了gplearn的基本使用,这次尝试在特征比较多的项目中实验使用一下Home Credit Default Risk这个项目中。数据直接使用[Home Credit Manual Engineered Features] (https://www.kaggle.com/willkoehrsen/home-credit-manual-engineered-features)已经做好多表连接的数据。感觉真的和作者Will Koehrsen 学习了太多,内心真的再次感激一下。
上一篇文章 利用 gplearn 进行特征工程主要测试了几个常规控制参数,
- generations 遗传算法的代数
- population_size 每代程式的数量
- n_components 我们想要得到的程式数量
- function_set 用于构成程式的函数集合
因为这次应用的数据集特征数量在 1000 这个量级上,所以也就需要调试更多的参数,以满足我们找到和目标相关性高的特征, 但是和其他特征相关性要低的目标。
tournament_size 参与遗传算法计算下一代程式的数量
程式(program) 文档中使用program来描述符号回归中的数学公式,我用‘程式’来作为翻译
这个参数可以参数可以控制进化过程中保留下来的程式数量,可以想象如果每代保留的程式都很少,特征之间的相关性会很快提升,这并不是我们想要的,所以我觉得这是一个关键参数。在实验中可以尝试不同设置来观察特征之间的相似度,以及后续带来的模型效果提升情况。
stopping_criteria 遗传算法停止条件
默认值是0,控制特征与label相关性的参数,在特征组合中,我觉得可以适当调高,防止特征与标签的相似性过高。
init_depth 初始化的树深度
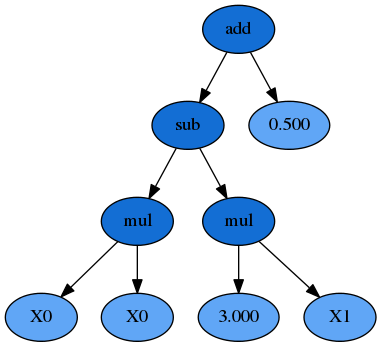
默认值是(2-6)
parsimony coefficient 简化系数
默认值是0.001
这个参数用来空值模型膨胀(bloat)。当进行了多代的进化,程式树深度会 变得越来越深,节点数会变得越来越多,但是适应度确没有显著提升,节俭系数就类似于线性回归中的正则项,给复杂的程式增加惩罚项,让我们的算法不去选择过于复杂的程式。
我们在进行特征组合的时候也不希望获得过于复杂的特征组合方式,所以可以通过这个参数来空值组合形式的复杂程度,简化系数越高,生成的程式越简化。
p_hoist_mutation 提升变异系数
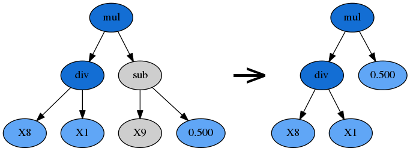
默认值为0.01
提升变异,是将子树的一部分直接替换整个子树,也就是所谓的提升,提升变异降低了程式的膨胀情况。
提升变异系数是对上一代保留程式进行提升变异的比例。
类似的,p_subtree_mutation,p_point_mutation分别代表子树变异系数,点变异系数,由于对特征相关性的影响不大,所以不重点介绍了。
max_samples 最大采样比例
默认值为 1.0。
这个参数的含义可以类比 提升算法Bagging中采样的概念。在进行适应度计算的时候,只选取整个数据的子集进行计算,一定程度上可以降低过拟合的情况,另一方面还能用没有参与计算的数据来评估新程式的适应度,类似于Bagging中的带外评估(out-of-bag estimate)。
简化系数 提升变异系数 最大采样比例 是三种不同的控制程式膨胀的方向,详细参考文档中的论述控制程式膨胀的方法。
- 以下几个特征感觉和特征组合的筛选不太有关,但是还是罗列一下。
hall_of_fame 备选数量
n_components < hall_of_fame < population_size 选定最后的n_components个程式前,提前筛选出的程式,具体为什么多这么一步,我也没想清除。
const_range 混入程式的常数范围
nit_method 初始化方法 ‘grow’生成不对称的树,‘full’ 生成丰满的树,最后默认值是‘half and half’ 是前两者个生成一半,感觉没必要调整。
metric 适应度标准,默认 皮尔逊相关系数,可选spearman相关系数,或者自定义,我在测试过程中,spearman的计算时间好像要明显长于皮尔逊相关系数,所以也就使用默认值,不不修改了。
联想到sklearn中对特征的筛选,其实可以尝试一下互信息等指标进行筛选,我暂时还没仔细研究,可行性,还有速度和效果等有待实验一下。
p_crossover 交叉变异系数
交叉变异是最主要的变异方式,系数默认值有0.9。
warm_start 热启动
如果修改为True,利用之前的计算结果,进行计算,速度回快点
n_jobs 并行计算使用的核心数量
verbose 显示信息控制
random_state 随机种子
后面几个参数,sklearn常用,不细说了。
数据来源Home Credit Manual Engineered Features
模型参数参考Fork_of_ForK_LightGBM_with_Simple_Features
评估特征还是从 1 与label的相关性,2 特征之间的相关性,3 模型中的重要程度,4 对模型效果提升 四个方面评估新生成的效果。
不新生成特征,记录四个方面的情况