Incorrect memory view after running self-modifying code #820
Comments
While working on proper interpretation of shellcode payloads from [1] we found some shikata ga nai-encoded payloads. Using Unicorn Engine we attempt to unpack this first layer to reach the actual shellcode. For now this only works partially due to one or more suspected bugs in Unicorn Engine's support for self-modifying code [2]. [1]: http://researchcenter.paloaltonetworks.com/2017/03/unit42-pulling-back-the-curtains-on-encodedcommand-powershell-attacks/ [2]: unicorn-engine/unicorn#820
|
Yep. Ran into that repeatedly with several self-modifying stack-based code. The problem is basically that QEMU translation cache has a tolerance of 16-byte shallow. That is, if the code modifies within 16-byte reach from its own EIP/PC then QEMU isn't going to 'taint' the cache. And I've spent about 23 hours on it only to find that this is a design issue. |
|
Are you sure it's within 16-bytes, not within the same TB? Maybe something with the logic to abort the currently executing TB on memory writes to itself is broken? |
|
Yes, as you described exactly. When the code-being-modified is beyond the reach of the TB cache, then it's flushed in current logic. The TB cache taint algorithm has been peppered throughout the QEMU source code and it has hard to work the state diagram of what it should be, so it's pretty wonky there. |
|
Ideally you should land in tb_invalidate_phys_page_range() which then would detect you're in the same TB and exit the cpu loop forcefully. We did change the way most cpu loop exiting works a while ago from an agressive longjmp to a softer "check a flag at the beginning of each TB" method. Maybe it broke there. |
|
Thanks for chiming in @agraf. I wanted to add one additional piece of information here which would suggest that Unicorn is at fault here. As mentioned above the xor decoding doesn't work correctly for the first X bytes, but does do its thing correctly for most of the remaining data (hence you will see URLs or hostnames used by the shellcode at the end of it). I also noted earlier that 1 out of every 4 bytes (namely, the first byte - in little endian speak) seemed to be correct. Furthermore, when adding a |
|
I do know that nearby code memory were modified by an XOR being emulated TWICE, hence the appearance that nothing got done and that no invalidation of TB cache were being done but (I think) is needed. Yeah, emulated TWICE, that is the flaw. |
|
Are all XORs pointing into their own TB emulated twice? Can someone come up with a minimal test case for this? |
|
Yes. I wrote a test case exactly for that. And it has been accepted and pushed here. Look for the word XOR as part of its source file name |
|
More specifically. I remember that the operand2 of XOR got emulated twice |
While working on proper interpretation of shellcode payloads from [1] we found some shikata ga nai-encoded payloads. Using Unicorn Engine we attempt to unpack this first layer to reach the actual shellcode. For now this only works partially due to one or more suspected bugs in Unicorn Engine's support for self-modifying code [2]. [1]: http://researchcenter.paloaltonetworks.com/2017/03/unit42-pulling-back-the-curtains-on-encodedcommand-powershell-attacks/ [2]: unicorn-engine/unicorn#820
|
is this solved if not is there any work done on it ? i see here that it's already fixed here i don't know if it's the same issue , but i'll try to test it . |
|
The greater than 14 patch basically forces an invalid instruction and which is NOT the behavior of the hardware CPU. In other word, the patch strengthens QEMU better than hardware which is not what we want for emulation of malicious code on pseudo-real hardware. |
|
According to Google Bug Report given earlier, it only impact when running QEMU in TCB mode, and not in KVM mode This means that ARM-based QEMU cannot emulate ix86 accurately because only TCB mode is supported. Whereas,Intel-based in KVM mode will properly emulate this. |
|
Unicorn doesn't use KVM mode.
|
|
Right... I mean to say QEMU... re-edited that. |
|
is there any fix yet for this ?! |
|
Nope. |
|
can anyone help at least showing me where to look in the code and @egberts can you please explain why "KVM" mode can emulate this but Unicorn can't thanks |
|
KVM runs just fine (that Unicorn doesn’t support) but not in QEMU emulation mode (that only Unicorn supports). The Bug is in emulation mode, specifically on XOR operator modifying within 16-byte region of its own XOR operator (in my supplied test case in this repo under test directory, the IMUL operator) and within the same TLB block. One can run this same IMUL/XOR code in KVM-emulation mode which I have not done. So the answer, to your question, is I don’t know. |
This mode forces EOB generation after each instruction. This is work-around to emulate self-modifying shell-code, maybe also unicorn-engine#820
This mode forces EOB generation after each instruction. This is work-around to emulate self-modifying shell-code, maybe also unicorn-engine#820
|
Confirmed that it is fixed in UC2. Link to #1217. |
Hi!
We're in the process of integrating Unicorn Engine in Cuckoo Sandbox. Its first purpose is unpacking
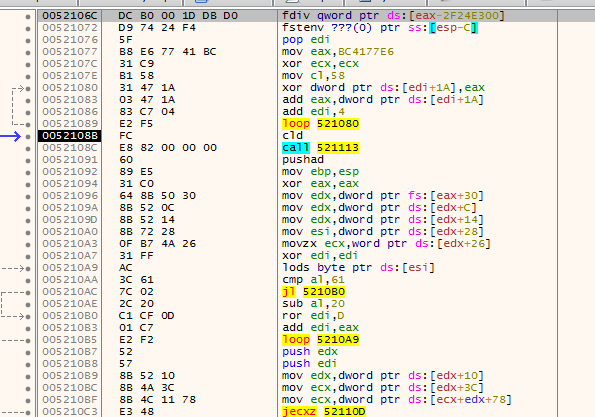
shikata ga nai-encoded (a metasploit encoder) payloads. While working on this we encountered an interesting shellcode sample that behaves incorrectly in Unicorn. Following some additional information.First of all, find the decoding stub as follows. What's notable (and I'm quite sure also related to the bug) is that the
shikata ga naistub decodes not only the payload, but also parts of the decoder stub.In this particular sample you'll find that the immediate operand of the
loopinstruction is decoded during the firstxoroperation and I suspect that this causes some out-of-sync issues with thetcg.Expected output after running the shellcode may be found as follows.
The actual output may be demonstrated by the following script (running
unicorn==1.0.0).On one hand you'll see that the remainder of the shellcode is decoded correctly, as you'll be able to find the
www3.chrome-up.datestring somewhere at the end of it. On the other hand, however, you'll find that the bytes just after theloopinstruction aren't decoded properly. The output of the script is as follows.At this point I don't know much about the Unicorn internals, but I sure do hope that somebody can pick up this issue! Thanks in advance! :-)
The text was updated successfully, but these errors were encountered: