Large Language Models

(Image credit: Google DeepMind. Unsplash)
Large Language Models (LLMs) are deep learning models that are trained to work on human languages. They are capable of understanding and generating text in a human-like fashion. LLMs are based on large transformer models that use a combination of artificial neural networks and natural language processing techniques to process and generate text.
Overall, LLMs represent a significant advance in the field of natural language processing and have the potential to revolutionize the way we interact with computers and other digital devices.
Large language models (LLMs) are trained on massive datasets of text and code. This is known as Generative AI, and allows the models to learn the patterns and relationships between words, which in turn allows them to perform a variety of tasks, including:
- Generating text: LLMs can be used to generate text that is similar to human-written text. This can be used for a variety of purposes, such as creating chatbots, writing articles, or generating creative content.
- Translating languages: LLMs can be used to translate text from one language to another. This can be useful for businesses that need to communicate with customers in multiple languages, or for individuals who want to read content in a language they don't speak.
- Answering questions - Chatbots: LLMs can be used to answer questions about the world. This can be useful for students who are doing research, or for people who want to learn more about a particular topic.
- Summarizing text: LLMs can be used to summarize text, extracting the key points and presenting them in a concise way. This can be useful for people who don't have time to read long articles, or for students who need to summarize their research findings.
LLMs are still under development, but they have the potential to revolutionize the way we interact with computers. In the future, LLMs could be used to create more natural and engaging user interfaces, or to provide us with personalized recommendations and advice.
Here are some of the current applications of LLMs:
- Chatbots: LLMs are being used to power chatbots that can have conversations with humans in a natural way. This is being used in a variety of industries, such as customer service, healthcare, and education.
- Virtual assistants: LLMs are also being used to power virtual assistants like Amazon Alexa and Google Assistant. These assistants can answer questions, set reminders, and control smart devices.
- Content generation: LLMs are being used to generate content, such as articles, blog posts, and even creative writing. This is being used by businesses to create marketing content, and by individuals to share their thoughts and ideas.
- Machine translation: LLMs are being used to improve machine translation. This is making it possible to translate text from one language to another more accurately and fluently.

(Image credit: Mooler0410 )
LLMs are still a new technology, but they have the potential to have a major impact on the way we interact with computers. As they continue to develop, we can expect to see even more innovative and exciting applications for this technology.
Multiple large language models have been developed, including
- GPT-3 (Jun 2020), GPT-3.5 (Mar 2022) and GPT-4 (Mar 2023) in ChatGPT from OpenAI,
- LLaMA (Feb 2023), LLaMA-2 (Jul 2023), LLaMA-3 (Apr 2024) from Meta,
- Gemini/Bard (Mar 2023) from Google,
- Claude (Jul 2023) from Anthropic A.I.,
- Mistral (Apr 2023) from Mistral AI.
There is a LLMs ratings & performance Leaderboard, where you can follow the recent LLMs performance tests (Apr 2024 LLMs ratings below):

LLMs can understand language, generate text, and are based on transformer architecture with attention mechanisms to capture context and generate text based on previously generated tokens.

Transformer Architecture (CC Image credit: Wikimedia Commons)

Attention Mechanism (CC Image credit: Wikimedia Commons)
OpenAI ChatGPT, (and its variants Google Gemini, and Anthropic Claude AI)a large language model, gained popularity and attention when it was introduced, but many people still don't understand how it works.
Unlike conventional software, ChatGPT is built on a neural network trained on billions of words of ordinary language, making it difficult for anyone to fully comprehend its inner workings.
Although researchers are working to gain a better understanding, it will take years or even decades to fully comprehend LLMs. This article aims to explain the inner workings of language models by discussing word vectors, transformers, and the training process.
(See: LLM Models Architecture Visualization)

Relative frequency of letters in English language root words (CC Image credit: Wikimedia Commons)
In languages like English, words are represented as a sequence of letters, like C-A-T for cat. Language models use vectors (a list of 300 numbers, for example). Words live in this 300-dimensional "word space". Words with similar meanings are placed closed together. Example of words close to cat are: kitten, dog, pet.
Similarly, words that are close together are: big and small (size), german and Germany (nationality, language), Berlin and Germany (capital), mouse and mice (plural), man to woman (gender), king and queen (role).
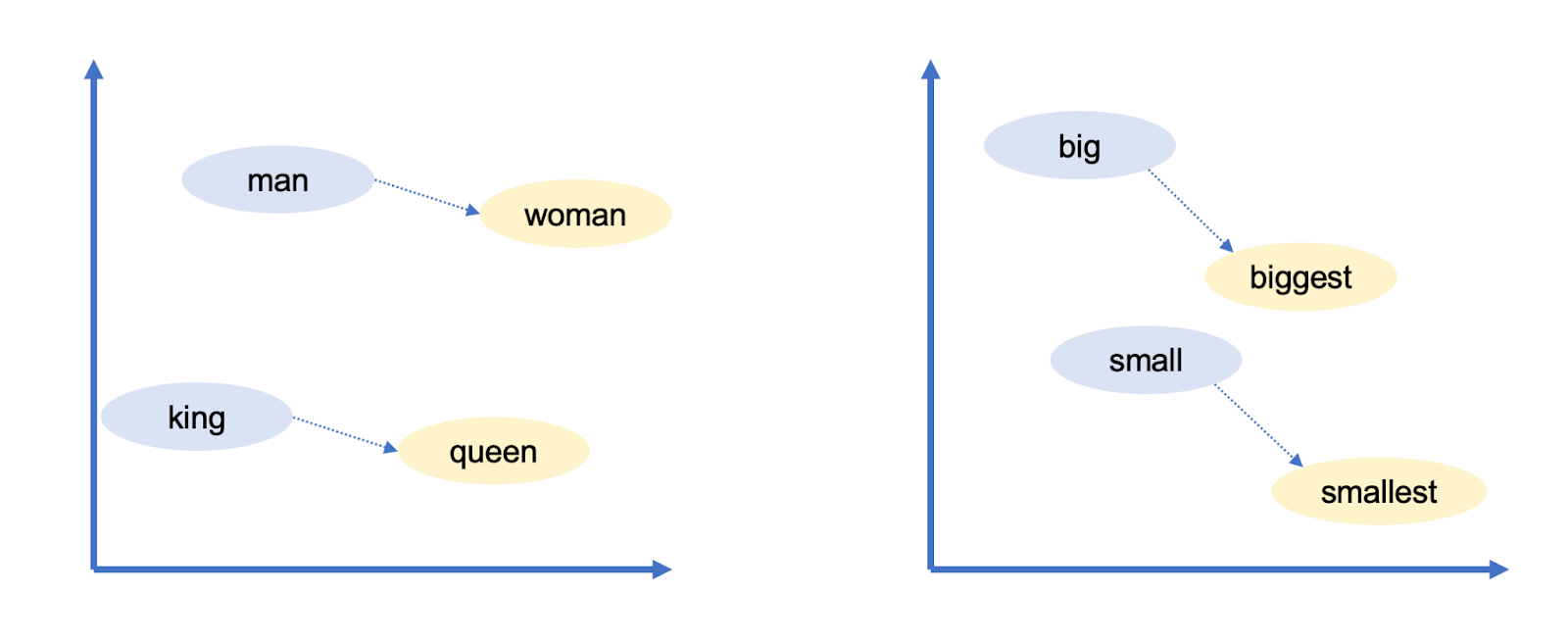
(Image credit: Understanding AI, Timothy B. Lee and Sean Trott)
In Linguistics, there are several ways to classify words.
- Polysemy, words with closely related meanings: magazine, bank, man, ...
- Homonyms, words having the same name but unrelated meanings: bank, row, bark, ...
- Homophones / Homgraphs, words that are pronounced the same but have different meaning: rose, read, by (buy), merry (marry, Mary), depend (deep end), example (egg sample), ...
- Ambiguous: "the professor urged the student to do her homework", "fruit flies like a banana"
We usually resolve ambiguities based on context, with no deterministic rules for doing this. Language models with the help of word vectors, provide a way of having a precise meaning in a specific context.
The [Generative Pre-Trained Transformer](https://en.wikipedia.org/wiki/Generative_pre-trained_transformer 3) (GPT-3) is behind the original of chatGPT large language model released by OpenAI in 2020. GPT-3 Transformer is organized in dozens of neural network layers.
Suppose we have the partial sentence: "John wants his bank to cash the". These words, represented as word2vec-style vectors are fed into the first transformer, as shown in the figure below.

(Image credit: Understanding AI, Timothy B. Lee and Sean Trott)
The transformer figures out that wants and cash are verbs (which are also nouns). The next layer figures out that bank is a financial institution and not a river bank, and that the pronoun his refers to John.
This is a simple example of a two layer model. GPT-3 has 96 layers, and word vectors of 12,288 dimensions.
In a 1,000 word story, the 60th layer might include a vector vector with comment like "John (main character, male, married to Cherryl, cousin of Donald, from Minnesota, currently in Boise, trying to find his missing wallet)".

(Image credit: State of GPT. Andrej Karpathy.)
From the above image, the GPT Assistant training pipeline consists of four stages:
- Pretraining
- Supervised Finetuning
- Reward Modeling
- Reinforcement Learning
Before pretraining takes place, there two preparation steps: Data collection and Tokenization.

(Image credit: State of GPT. Andrej Karpathy.)
The major LLMs, GPT-4, Claude, PaLM, or LLaMA 2, don't disclose the datasets they have used to train their models. From the above table, we can observe the datasets and sizes used to train the LLaMA model from Meta (Facebook). They use publicly available datasets on the Internet. There is only one proportion of the datasets that include near 200,000 available pirated books on the internet. There are already suits against OpenAi and Meta for copyright infringement (See note).

(Image credit: State of GPT. Andrej Karpathy.)
Tokenization is a loseless translation between pieces of words to integers. LLaMA has trained between 1-1.4 Trillion tokens versus 300 Billion in GPT-3.

(Image credit: State of GPT. Andrej Karpathy.)

Example



(Images credits: State of GPT. Andrej Karpathy.)

(Image credit: State of GPT. Andrej Karpathy.)
This process is still not a good quality product.Users review the generated outputs of questions with the Supervised Tuning Model and compare 3 versions and rank which was the best. Then the model is retrained with the selections by the users.


(Images credits: State of GPT. Andrej Karpathy.)
This is done by weighting the better voted responses.


(Image credit: State of GPT. Andrej Karpathy.)
Things we need to keep in mind about LLMs:
- Base models do not answer questions
- They only want to complete internet documents
- They can be tricked into performing tasks with prompt engineering
- Models may be biased
- Models may fabricate (“hallucinate”) information
- Models may have reasoning errors
- Models may have knowledge cutoffs (e.g. September 2021)
- Models are susceptible to prompt injection, “jailbreak” attacks, data poisoning attacks,...
- Large language models, explained with a minimum of math and jargon. Timothy B. Lee, Sean Trott. Understanding AI. July 17th, 2023.
- A LLM Reading List. Evan Miller. Github. 2023.
- The Practical Guide for Large Language Models.
- Chatbot Arena Leaderboard: LLMs ratings & performance
- What we know about LLMs (Primer). Will Thompson. July 23rd, 2023.
- State of GPT. Andrej Karpathy. OpenAI. May 23, 2023.
- Catching up on the weird world of LLMs. Simon Willison. Aug 3, 2023.
- GPT-4 Technical Report. OpenAI. Mar 27, 2023.
- Sparks of Artificial General Intelligence: Early experiments with GPT-4. Sebastien Bubeck. Apr 13, 2023.
- Llama 2: Open Foundation and Fine-Tuned Chat Models. Hugo Touvron et al. Jul 19, 2023.
- Patterns for Building LLM-based Systems & Products. Eugene Yan. Jul, 2023.
Created: 08/06/2023
Updated: 04/22/2024
Carlos Lizárraga
University of Arizona, Data Science Institute.

