Official pytorch implementation of our CVPR 2021 paper VideoMoCo: Contrastive Video Representation Learning with Temporally Adversarial Examples.
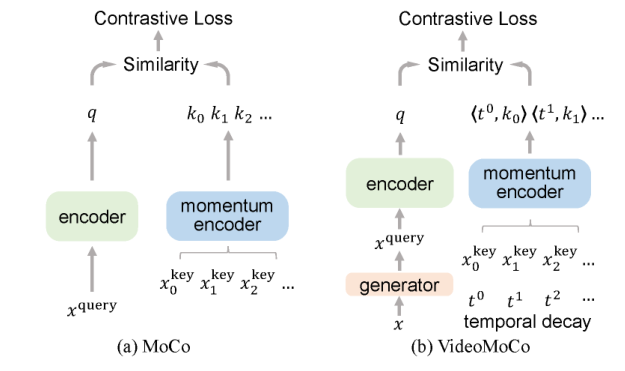
Given a video sequence as an input sample, we improve the temporal feature representations of MoCo from two perspectives. We introduce generative adversarial learning to improve the temporal robustness of the encoder. We use a generator to temporally drop out several frames from this sample. The discriminator is then learned to encode similar feature representations regardless of frame removals. By adaptively dropping out different frames during training iterations of adversarial learning, we augment this input sample to train a temporally robust encoder. Second, we propose a temporally adversarial decay to model key attenuation in the memory queue when computing the contrastive loss. It largely improves MoCo with temporally robust feature representation for the video-related classification/recognition scenario, which is novel in terms of both temporal representation learning methodology and video scenario.
 |
 |
- pytroch >= 1.3.0
- tensorboard
- cv2
- kornia
- Download the Kinetics400 dataset from the official website.
- Download the UCF101 dataset from the official website.
Note that we take 100 epochs to train D for initialization, and then train G and D via adversarial learning for the remaining 100 epochs.
python train.py \
--log_dir $your/log/path\
--ckp_dir $your/checkpoint/path\
-a r2plus1d_18 \
--lr 0.005 \
-fpc 32 \
-b 32 \
-j 128 \
--epochs 200 \
--schedule 120 160 \
--dist_url 'tcp://localhost:10001' --multiprocessing_distributed --world_size 1 --rank 0 \
--resume ./checkpoint_0100.pth.tar \
$kinetics400/dataset/path100 epochs for initialization: https://drive.google.com/file/d/1tE20ZNPg9l882900eXU0HcOc36UtwS5Y/view?usp=sharing
r2d18_200epoch(UCF101 Acc@1 82.518): https://drive.google.com/file/d/1DzA5Yn43x9ZuirX2jV8CuhhqCnSYky0x/view?usp=sharing
python eval.py Our code is based on the implementation of "MoCo: Momentum Contrast for Unsupervised Visual Representation Learning" (See the citation below), including the implementation of the momentum encoder and queue. If you use our code, please also cite their work as below.
If our code is helpful to your work, please cite:
@inproceedings{pan2021videomoco,
title={Videomoco: Contrastive video representation learning with temporally adversarial examples},
author={Pan, Tian and Song, Yibing and Yang, Tianyu and Jiang, Wenhao and Liu, Wei},
booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition},
pages={11205--11214},
year={2021}
}
@inproceedings{he2020momentum,
title={Momentum contrast for unsupervised visual representation learning},
author={He, Kaiming and Fan, Haoqi and Wu, Yuxin and Xie, Saining and Girshick, Ross},
booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition},
pages={9729--9738},
year={2020}
}