




Geomancer is a geospatial feature engineering library. It leverages geospatial data such as OpenStreetMap (OSM) alongside a data warehouse like BigQuery. You can use this to create, share, and iterate geospatial features for your downstream tasks (analysis, modelling, visualization, etc.).

Geomancer can perform geospatial feature engineering for all types of vector data (i.e. points, lines, polygons).
- Feature primitives for geospatial feature engineering
- Ability to switch out data warehouses (BigQuery, SQLite, PostgreSQL (In Progress))
- Compile and share your features using our SpellBook
Geomancer can be installed using pip.
$ pip install geomancer
This will install all dependencies for every data-warehouse we support. If you wish to do this only for a specific warehouse, then you can add an identifier:
$ pip install geomancer[bq] # For BigQuery
$ pip install geomancer[sqlite] # For SQLite
$ pip install geomancer[psql] # For PostgreSQL
Alternatively, you can also clone the repository then run install.
$ git clone https://github.com/thinkingmachines/geomancer.git
$ cd geomancer
$ python setup.py install
Geomancer is powered by a geospatial data warehouse: we highly-recommend using BigQuery as your data warehouse and Geofabrik's OSM catalog as your source of Points and Lines of interest.
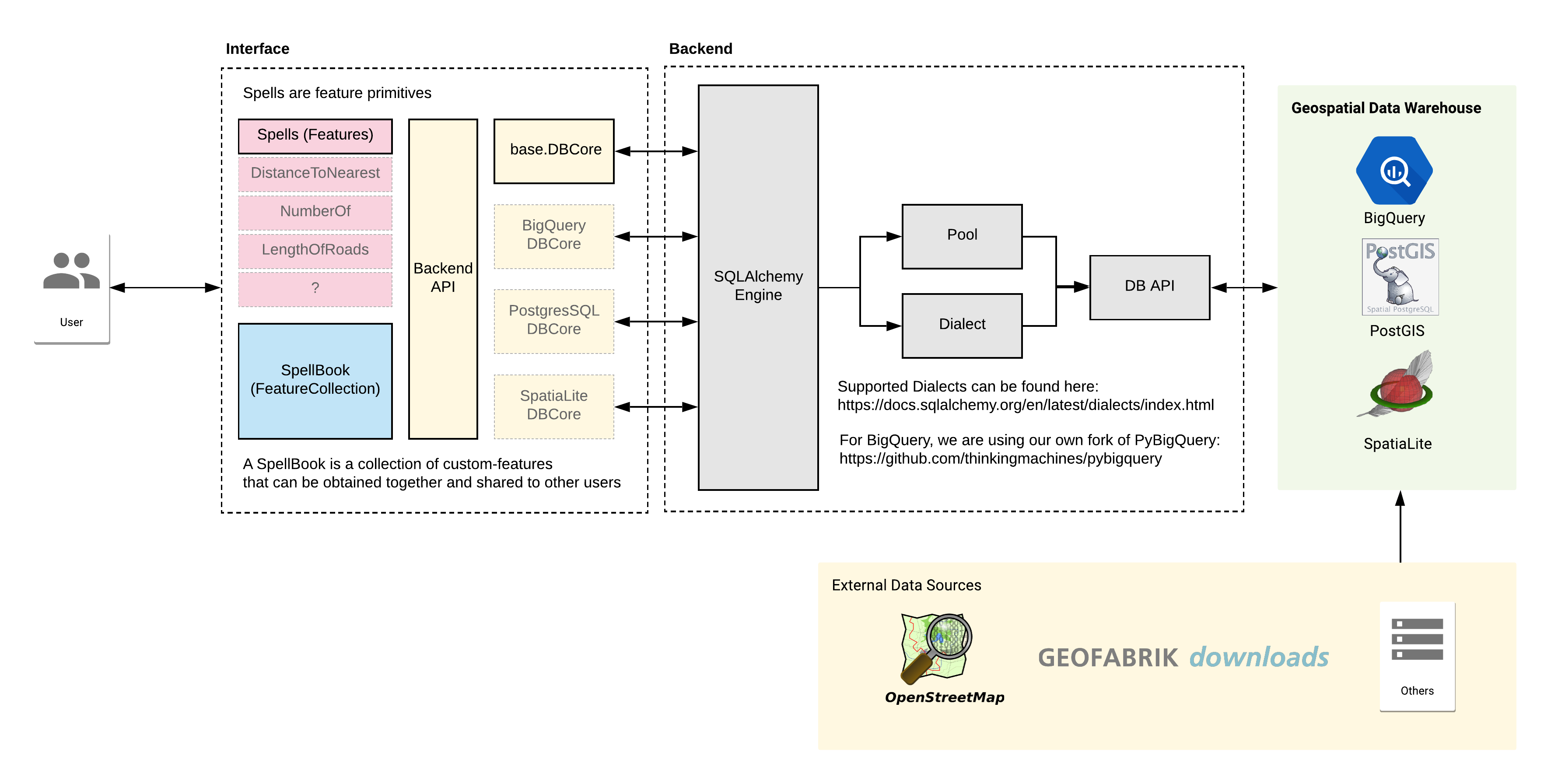
You can see the set-up instructions in this link
All of the feature engineering functions in Geomancer are called "spells". For example, you want to get the distance to the nearest supermarket for each point.
from geomancer.spells import DistanceToNearest
# Load your dataset in a pandas dataframe
# df = load_dataset()
dist_spell = DistanceToNearest(
"supermarket",
source_table="ph_osm.gis_osm_pois_free_1",
feature_name="dist_supermarket",
dburl="bigquery://project-name",
).cast(df)You can specify the type of filter using the format {column}:{filter}. By
default, the column value is fclass. For example, if you wish to look for
roads on a bridge, then pass bridge:T:
from geomancer.spells import DistanceToNearest
# Load the dataset in a pandas dataframe
# df = load_dataset()
dist_spell = DistanceToNearest(
"bridge:T",
source_table="ph_osm.gis_osm_roads_free_1",
feature_name="dist_road_bridges",
dburl="bigquery://project-name",
).cast(df)Compose multiple spells into a "spell book" which you can export as a JSON file.
from geomancer.spells import DistanceToNearest
from geomancer.spellbook import SpellBook
spellbook = SpellBook([
DistanceToNearest(
"supermarket",
source_table="ph_osm.gis_osm_pois_free_1",
feature_name="dist_supermarket",
dburl="bigquery://project-name",
),
DistanceToNearest(
"embassy",
source_table="ph_osm.gis_osm_pois_free_1",
feature_name="dist_embassy",
dburl="bigquery://project-name",
),
])
spellbook.to_json("dist_supermarket_and_embassy.json")You can share the generated file so other people can re-use your feature extractions with their own datasets.
from geomancer.spellbook import SpellBook
# Load the dataset in a pandas dataframe
# df = load_dataset()
spellbook = SpellBook.read_json("dist_supermarket_and_embassy.json")
dist_supermarket_and_embassy = spellbook.cast(df)This project is open for contributors! Contibutions can come in the form of feature requests, bug fixes, documentation, tutorials and the like! We highly recommend to file an Issue first before submitting a Pull Request.
Simply fork this repository and make a Pull Request! We'd definitely appreciate:
- Implementation of new features
- Bug Reports
- Documentation
- Testing
Also, we have a CONTRIBUTING and a CODE_OF_CONDUCT, so please check that one out!
MIT License © 2019, Thinking Machines Data Science