{kind=link}
{kind=link}
{kind=link}
Custom editor extension to open files in raw byte representation. Also renders possible text decoding results. Doesn't support editing the document (yet).
- Open files of arbitrary size
- Multiple decoders to render textual data
- Supports multibyte encodings
- Custom decoder scripts (not supported in virtual environments)
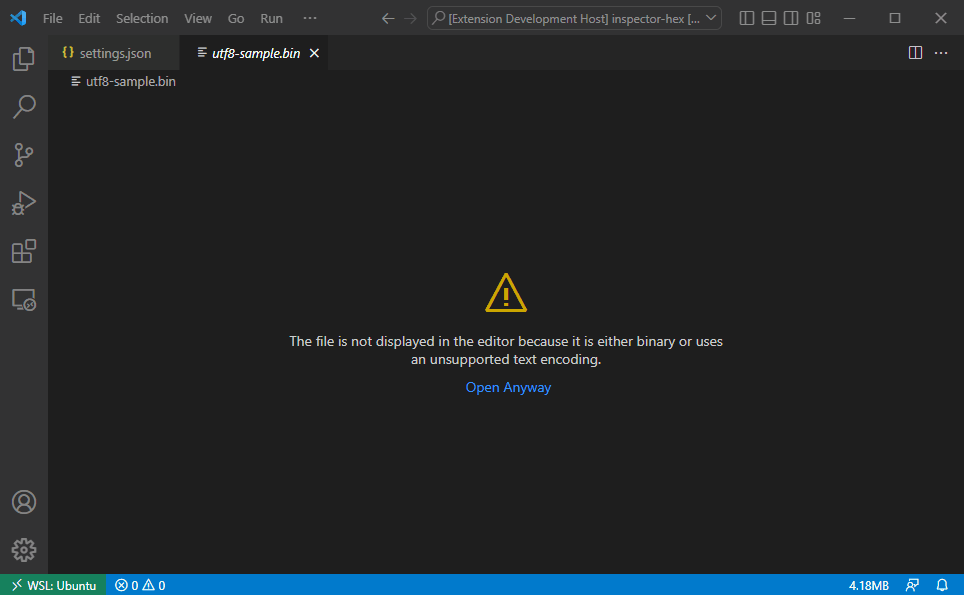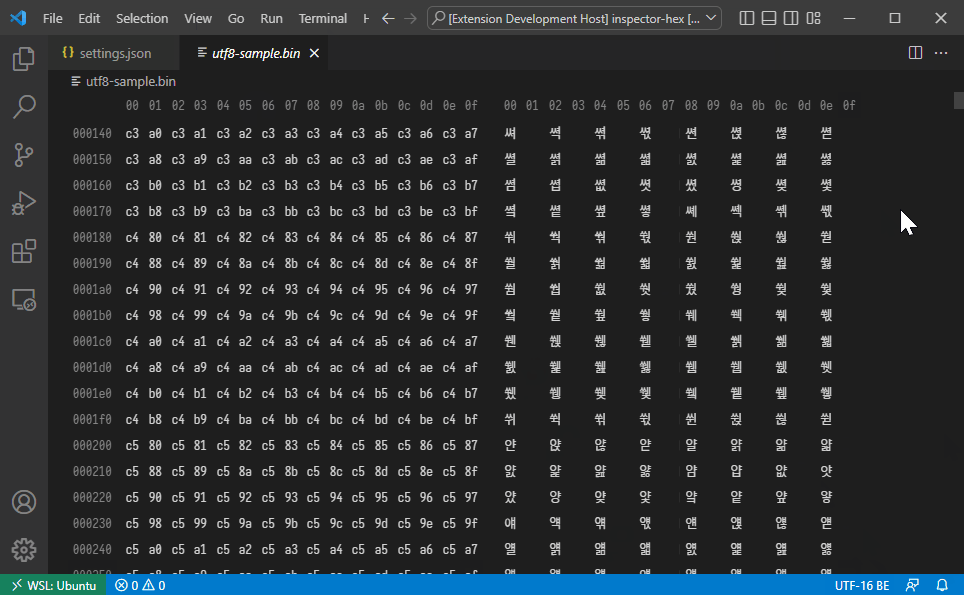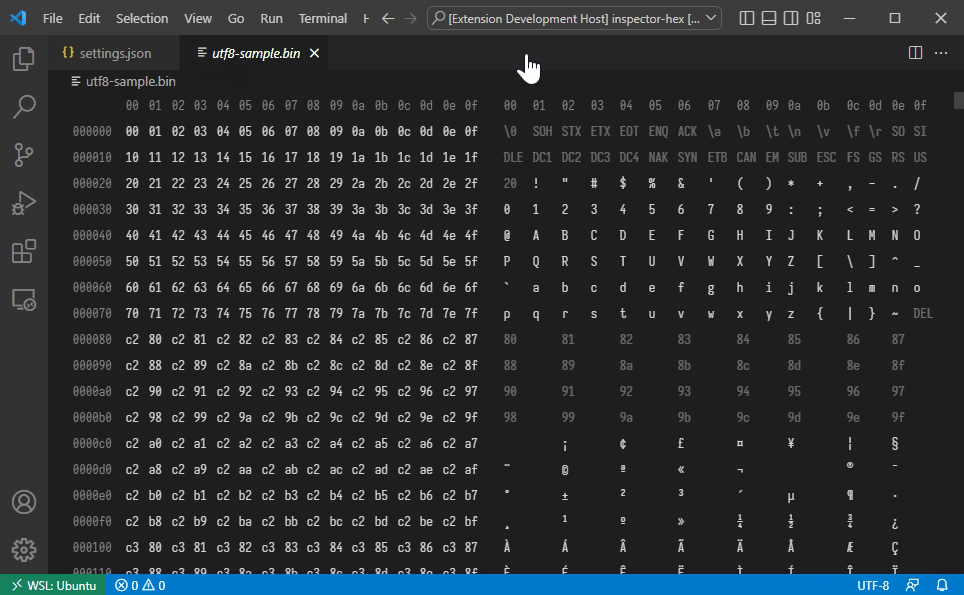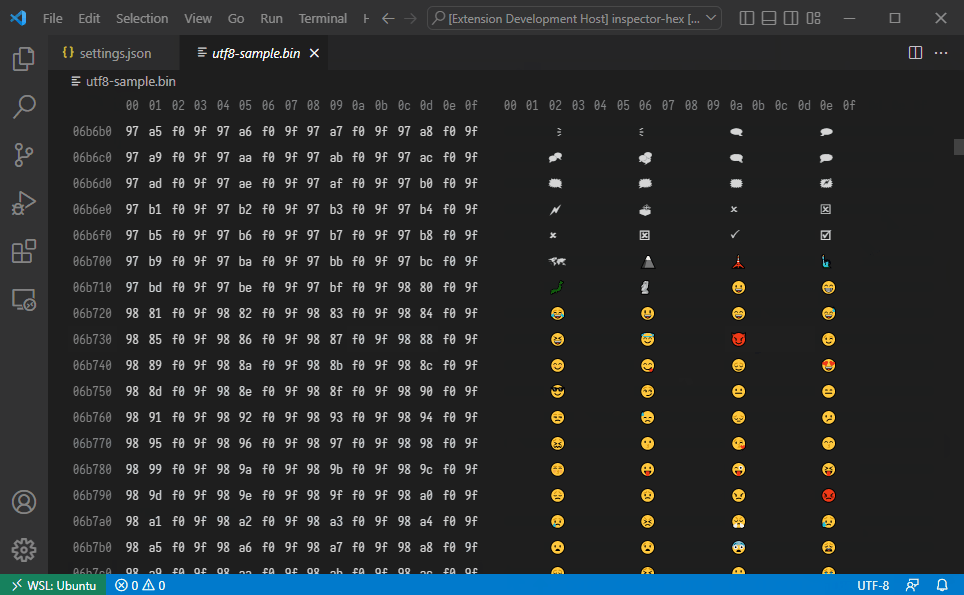
The extension implements built-in decoders for standard text encodings. The following decoders are currently implemented:
- ASCII (default)
- ISO 8859-1
- UTF-8
- UTF-16
- UTF-32
Decoders for multibyte encodings like UTF-8 will skip invalid byte sequences and render the skipped bytes with an error color.
Custom decoder scripts are currently only supported in non-virtual workspaces. The decoder script should be a CommonJS script that exports a single function. The function should adhere to the Decoder type in the definitions below:
type RenderControlCharacters = 'hex' | 'abbreviation' | 'escape' | 'caret' | 'picture';
interface DecoderState = {
offset: number; // the offset of the given buffer in the file
file: {
byteLength: number; // size of the file
uri: string; // absolute path to the file
handle: FileHandle; // file handle access for complex decoders
};
settings: {
// user settings that
renderControlCharacters: 'off' | RenderControlCharacters | RenderControlCharacters[];
};
};
type DecodedValue =
| null // undecoded single byte, rendered as dot with weaker text color
| string // decoded single byte
| {
// can be used for multibyte sequences
// or for single byte values that should be rendered in a specific color
text?: string; // treated like null above if not specified
length?: number; // length of the byte sequence, defaults to 1
style?: {
color?: string; // valid CSS color string, can also be a CSS variable defined by VS Code for theming
};
};
interface DecoderResult {
offset: number; // start offset of the decoded result
values: DecodedValue[];
}
type Decoder = (data: Buffer, state: DecoderState) => DecoderResult | Promise<DecoderResult>;Type definitions can also be imported from the @inspector-hex/decoder-api package. The package version should always match the extension's version.
Custom decoders for single-byte encodings should be pretty straight forward. Below is a sample decoder, that simply renders the numeric value of each byte in its decimal form:
module.exports = (data, { offset }) => {
return {
offset,
values: Array.from(data, (byte) => `${byte}`),
};
}Multibyte encodings are potentially more challenging. To be able to display files of arbitrary size, the extension only loads parts of a file into memory and replaces them while scrolling the document. A custom decoder has to take this into account and deal with the fact that the given buffer starts or ends in the middle of a multibyte sequence. To deal with this a custom decoder can be asynchronous and use the given file handle to read missing information relevant for decoding from anywhere in the file. The decoder can return a different offset than the given buffer start and the length of the decoded values doesn't have to match the input buffer, although it is advised to try to match the input buffers size more or less, preferably it should be a little larger than a little smaller. If the custom decoder script needs to import additional code, the script's working directory is the workspace it is in or relative to the script itself if it is outside the workspace (specified by an absolute path).
In any case, the start and end of the buffer should be well outside the currently visible data. If preceeding information isn't relevant for continuing correct decoding after a few bytes, the start of the buffer could well be ignored. This is done for example by the built-in UTF-8 decoder.
⚠️ Often a decoded text unit is a single character but it doesn't have to be. The extension can render strings of arbitrary length for a single byte, the CSS grid layout makes sure the columns will align. With that said, strings that exceed two or three characters will likely distort the layout in unpleasant ways.
To use a custom decoder it has to be registered in the settings. The configuration entry point is inspectorHex.customDecoders and is an object lists key/value pairs, where the key is the name for the decoder and the value is the path to the script file. Relative paths are resolved from the workspace root.
⚠️ Custom decoder scripts are not sandboxed as VS Code extensions aren't either. So don't run custom decoders from untrusted sources.
The script file is watched and whenever it updates custom decoders are automatically reloaded. This does not apply to dependencies (via require or import) though, as this functionality would also require parsing the script file and generating a dependency tree to watch. This means to see changes in a dependency reflected, either save the actual decoder script file or run the Reload decoders command.
A custom decoder can alternatively be written in TypeScript. Note that this feature is currently experimental. TypeScript source files are transformed on demand by the @esbuild-kit/cjs-loader package. As the name suggests, the loader itself is using esbuild under the hood, which has a few restrictions regarding TypeScript. See the section TypeScript caveats in the esbuild documentation for specifics.
In TypeScript the above example could be written like this:
import type { Decoder } from '@inspector-hex/decoder-api';
export const decoder: Decoder = (data, { offset }) => {
return {
offset,
values: Array.from(data, (byte) => `${byte}`),
};
}Valid exports are an identifier named decoder or the default export. Note though, that default exports make it a little more annoying to type the export with the Decoder type. From TypeScript 4.9 the satisfies operator could be used to achieve this without an additional identifier.
Map of custom decoders. Keys are decoder names and values are the path to the JS file. Relative paths are resolved from the workspace root.
{
"type": "object",
"additionalProperties": {
"type": "string"
},
"default": {},
}Map of default decoders. Keys are glob patterns and values are decoder names. Relative paths are resolved from the workspace root. Decoder names can be either one defined in inspectorHex.customDecoders or one of the built-ins:
ASCIIISO 8859-1UTF-8UTF-16 BEUTF-16 LEUTF-32 BEUTF-32 LE
{
"type": "object",
"additionalProperties": {
"type": "string"
},
"default": {},
}Render control characters with a graphical representation. Supports multiple options for choosing a representation. If specified as an array of options, they are evaluated from left to right in descending priority (not all options cover all the control characters). Possible representations can be seen on Wikipedia. The hex option is the only one that also covers C1 control codes.
{
"oneOf": [
{
"type": "string",
"enum": [
"off",
"hex",
"abbreviation",
"escape",
"caret",
"picture"
]
},
{
"type": "array",
"items": {
"type": "string",
"enum": [
"hex",
"abbreviation",
"escape",
"caret",
"picture"
]
},
"minItems": 1,
"uniqueItems": true
}
],
"default": "off",
}Used to select a decoder for the currently opened file. This can also be set from the status bar in the lower right of the VS Code UI.
Useful when testing custom decoder scripts.
Scroll to the given offset in the active file.
These are just ideas that may or may not happen:
- shifted decoding for multibyte decoders
- more builtin decoders for standard text encodings like Windows 1252
- data inspection
- display unicode information for decoded text
- find byte sequences / decoded text
- settings for visualizing non-printing characters other than control characters
- settings for rendering combined emoji
- make case of hexadecimal letters configurable
- configurable offset width
- There are multiple issues regarding virtual workspaces (e.g. vscode.dev or github.dev)
- The extension can only load whole files at once into memory. To prevent crashes a warning is displayed before trying to open files larger than 10 MB.
- Custom decoders are not supported.
- Generally broken in Safari.
- To be able to open files of arbitrary size, the extension uses custom scrollbars to overcome DOM size limitations. Only basic scroll functionality has been implemented, still missing some typical functionality.
- Dragging scroll handle
- Wheel scrolling (horizontal with shift key)
- Touchpad scrolling
- Keyboard interactions
- Other features missing?