Torch code for "Deep Affordance-grounded Sensorimotor Object Recognition" link
What's in the repo so far:
- The baseline object appearance model.
- The GTM slow multi-level fusion model that fuses object appearance with the corresponding accumulated 3D flow magnitude.
To do:
- use a better spatiotemporal architecture (maybe c3d).
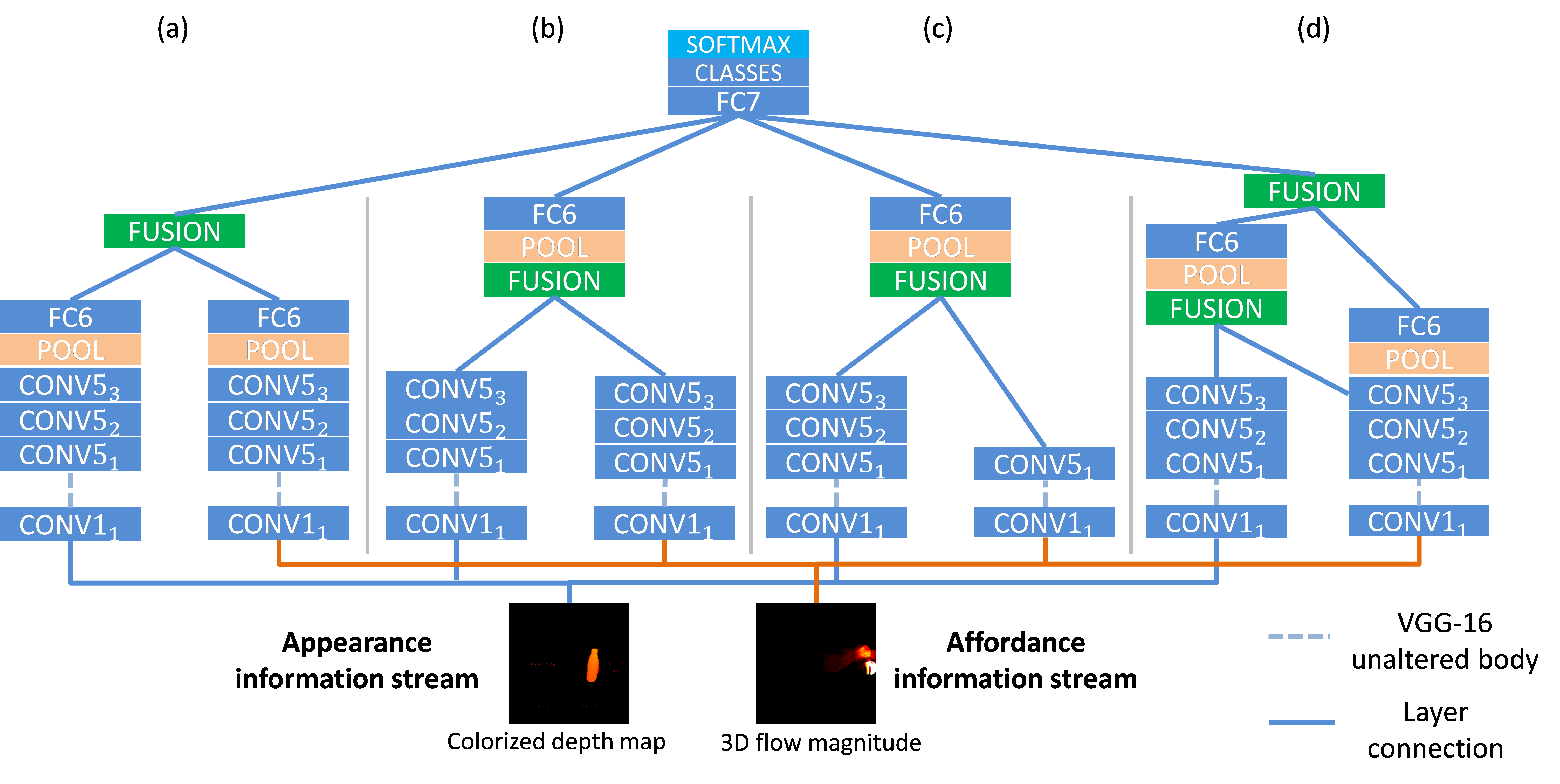
Slow multi-level fusion is the (d) model.
Bibtex:
@InProceedings{Thermos_2017_CVPR,
author = {Thermos, Spyridon and Papadopoulos, Georgios Th. and Daras, Petros and Potamianos, Gerasimos},
title = {Deep Affordance-Grounded Sensorimotor Object Recognition},
booktitle = {The IEEE Conference on Computer Vision and Pattern Recognition (CVPR)},
month = {July},
year = {2017}
}
The dataset and the data preprocessing are available here
The data are organised in train, validation and test set. We just use a simple convention: SubFolderName == ClassName. So, for example: if you have classes {bottle, knife}, bottle images go into the folder train/bottle and knife images go into train/knife.
Object sample:

Accumulated 3D flow magnitude (affordance) samples:

We use VGG ILSVRC-2014 16-layer backed with loadcaffe (thanks szagoruyko) as base model.
To train the baseline (appearance) model, edit the train.sh script (add train_baseline). Edit the path to appearance data (train, val) in the script.
To test the baseline model, run the edit the test.sh script (add test_baseline). Edit the paths to appearance data (test) and best saved model in the script.
xlua is used for confusion matrix visualization.
To train the SML model, run the train.sh script. Edit the path to appearance/affordance data (train, val) in the script.
To test the SML model, run the test.sh script. Edit the paths to appearance/affordance data (test) and best saved model in the script.
xlua is used for confusion matrix visualization.
The log file created during training can be visualized using the jupyter notebook as in this repo