This repository holds the implementation of detecting the drivable path in the ground plane for a mobile robot in an indoor environment. A U-Net based Semantic Segmentation model is trained on a custom dataset collected on the campus of the University of Maryland, College Park. This project is done as part of the course 'ENPM673 - Perception for Autonomous Robots' at the University of Maryland, College Park.
- Sparsh Bhogavilli* ([email protected])
- Adarsh Malapaka* ([email protected])
- Kumara Ritvik Oruganti* ([email protected])
- Sai Sandeep Adapa ([email protected])
- Venkata Sai Ram Polina ([email protected])
- * Denotes equal contribution.
- Please contact any one of the team members (listed above) to gain access to the dataset, if you're interested!

- Check out the usage.md for details on training & testing the model on a machine with a CUDA enabled GPU.
| Train Loss v/s Iteration | Train IOU v/s Iteration |
|---|---|
 |
 |
| Validation Loss v/s Iteration | Validation IOU v/s Iteration |
|---|---|
 |
 |
- The model is 3-fold Cross-Validated & the following are the results.
| Metric | Fold-1 | Fold-2 | Fold-3 | Average |
|---|---|---|---|---|
| Test IOU | 0.998 | 0.998 | 0.999 | 0.9983 |
- The following image shows the segmentation output on an image from the test set.

It can be observed that the pillar is classified as Non-drivable region.
- A camera has been mounted on a mobile robot platform and a Raspberry Pi, which is integrated into the platform, is utilized to transmit the camera's video stream to a laptop computer.
- Inference is then conducted on the video stream on the laptop using the inference_laptop.py script.
- The below two images are samples of the same.
| Detected Ground (Feet labeled as non-drivable) | Detected Ground (Floor-mat labeled as drivable) |
|---|---|
 |
 |
- 3rd-person Point-of-View of Mobile Robot transmitting video stream from a corridor & inference on laptop (in top-left)

- Laptop screen capture of inference being run on video stream received from the robot.
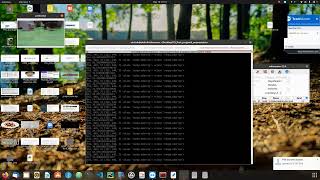
- The learned PyTorch model was converted to ONNX format on the laptop & then to TensorRT engine on a Jetson TX2 platform.
- The following is the terminal output of successful TensorRT conversion.

-
The dataset used for this project is made from the videos collected from the following locations on the University of Maryland's College Park campus.

Drop-down menu: Key for Depicted Locations (with number of videos recorded)
1. Atlantic Bldg (1 video)
2. J.M. Patterson Bldg (2 videos)
3. Chem/Nuclear Bldg (1 video)
4. A.V. Williams Bldg (1 video)
5. Brendan Iribe Center (1 video)
6. Glenn Martin Hall (2 videos)
7. Plant Sciences Bldg (1 video)
8. Psychology/Biology Bldg (1 video)
9. Symons Hall (1 video)
10. Woods Hall (1 video)
11. Tydings Hall (1 video)
12. Lefrak Hall (1 video)
| Robot used for Data Collection | Data Collection in Glenn Martin Hall |
|---|---|
 |
 |
- Resolution: 1280 x 720 (16:9 ratio)
- Video Duration: 5 minutes
- Framerate: 30fps
- Height of Camera: 12 cm approx (from the ground)
- Every 100th frame of each video was extracted to form a total of 1260 images in the dataset.
- The obtained 1260 images are randomly split in the ratio of 80-10-10.
- The tool Dataloop is used for annotating the ground truth masks on the images.
- Data Augmentation techniques like Random crop, Horizontal flip & brightness changes are used.