Rethink how .ext formats (v.s. ?_format=) works before 1.0 #1439
Comments
|
The challenge comes down to telling the difference between the following:
|
|
An alternative solution would be to use some form of escaping for the characters that form the name of the table. The obvious way to do this would be URL-encoding - but it doesn't hold for Surprisingly in this case Vercel DOES keep it intact, but Cloud Run does not. It's still no good though: I need a solution that works on Vercel, Cloud Run and every other potential hosting provider too. |
|
But... what if I invent my own escaping scheme? I actually did this once before, in 9fdb47c - while I was working on porting Datasette to ASGI in #272 (comment) because ASGI didn't yet have the I could bring that back - it looked like this: But I didn't particularly like it - it was quite verbose. |
|
Here's an alternative I just made up which I'm calling "dot dash" encoding: def dot_dash_encode(s):
return s.replace("-", "--").replace(".", "-.")
def dot_dash_decode(s):
return s.replace("-.", ".").replace("--", "-")And some examples: for example in (
"hello",
"hello.csv",
"hello-and-so-on.csv",
"hello-.csv",
"hello--and--so--on-.csv",
"hello.csv.",
"hello.csv.-",
"hello.csv.--",
):
print(example)
print(dot_dash_encode(example))
print(example == dot_dash_decode(dot_dash_encode(example)))
print()Outputs: |
|
So given the original examples, a table called
And if for some horific reason you had a table with the name
|
|
The documentation should definitely cover how table names become URLs, in case any third party code needs to be able to calculate this themselves. |
|
Maybe I should use |
|
I added a Link header to solve this problem for the JSON version in: |
def dash_encode(s):
return s.replace("-", "--").replace(".", "-.").replace("/", "-/")
def dash_decode(s):
return s.replace("-/", "/").replace("-.", ".").replace("--", "-")>>> dash_encode("foo/bar/baz.csv")
'foo-/bar-/baz-.csv'
>>> dash_decode('foo-/bar-/baz-.csv')
'foo/bar/baz.csv' |
|
(If I make this change it may break some existing Datasette installations when they upgrade - I could try and build a plugin for them which triggers on 404s and checks to see if the old format would return a 200 response, then returns that.) |
|
How does URL routing for https://latest.datasette.io/fixtures/table%2Fwith%2Fslashes.csv work? Right now it's Lines 1098 to 1101 in 7d24fd4 That's not going to capture the dot-dash encoding version of that table name: >>> dot_dash_encode("table/with/slashes.csv")
'table-/with-/slashes-.csv'Probably needs a fancy regex trick like a negative lookbehind assertion or similar. |
|
I want a match for this URL: Maybe this: Here we are matching a sequence of: So a combination of not-slashes OR -/ or -. Or -- sequences
Try that with non-capturing bits:
Here's the explanation on regex101.com https://regex101.com/r/CPnsIO/1
|


|
With this new pattern I could probably extract out the optional |
|
I think I got format extraction working! https://regex101.com/r/A0bW1D/1 I had to make that crazy inner one even more complicated to stop it from capturing Visualized:
So now I have a regex which can extract out the dot-encoded table name AND spot if there is an optional
If I end up using this in Datasette it's going to need VERY comprehensive unit tests and inline documentation. |


Here's what those look like with the updated version of
|
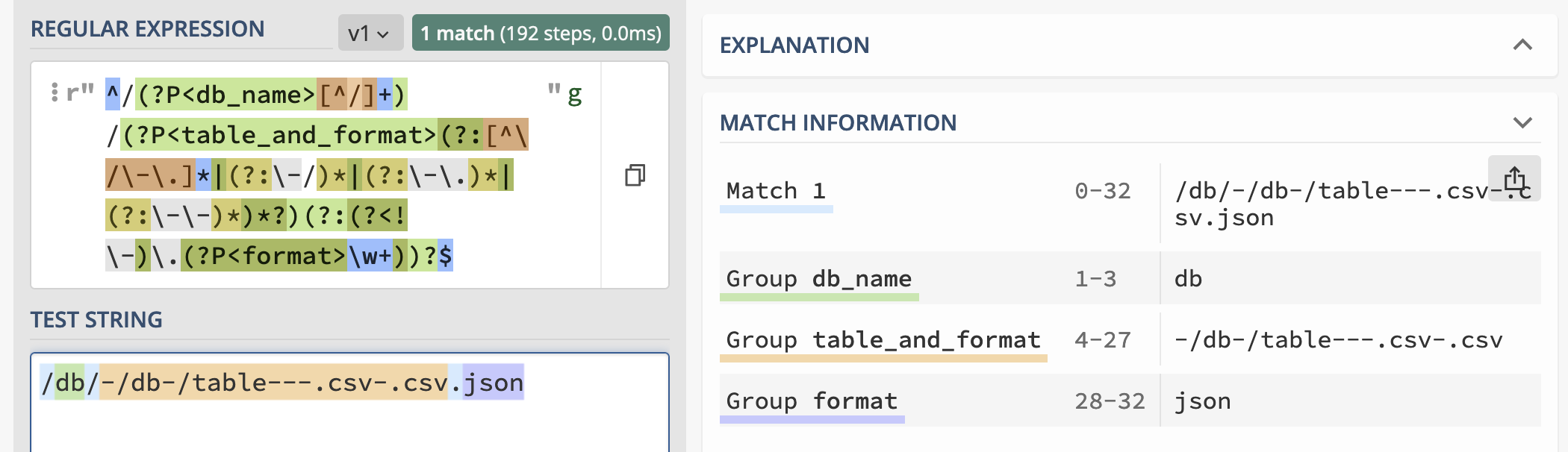
|
Ugh, one disadvantage I just spotted with this: Datasette already has a And I've thought about adding Maybe change this system to use |
def dot_encode(s):
return s.replace(".", "..").replace("/", "./")
def dot_decode(s):
return s.replace("./", "/").replace("..", ".")No need for hyphen encoding in this variant at all, which simplifies things a bit. (Update: this is flawed, see #1439 (comment)) |
>>> dot_encode("/db/table-.csv.csv")
'./db./table-..csv..csv'
>>> dot_decode('./db./table-..csv..csv')
'/db/table-.csv.csv'I worry that web servers might treat |
Do both of those survive the round-trip to populate No! In both cases the It looks like this might even be a client issue - So |
I don't think this matters. The new regex does indeed capture that kind of page:
But Datasette goes through configured route regular expressions in order - so I can have the regex that captures |

I think dash-encoding (new name for this) is the right way forward here. |
|
One other potential variant: def dash_encode(s):
return s.replace("-", "-dash-").replace(".", "-dot-").replace("/", "-slash-")
def dash_decode(s):
return s.replace("-slash-", "/").replace("-dot-", ".").replace("-dash-", "-")Except this has bugs - it doesn't round-trip safely, because it can get confused about things like >>> dash_encode("/db/table-.csv.csv")
'-slash-db-slash-table-dash--dot-csv-dot-csv'
>>> dash_decode('-slash-db-slash-table-dash--dot-csv-dot-csv')
'/db/table-.csv.csv'
>>> dash_encode('-slash-db-slash-table-dash--dot-csv-dot-csv')
'-dash-slash-dash-db-dash-slash-dash-table-dash-dash-dash--dash-dot-dash-csv-dash-dot-dash-csv'
>>> dash_decode('-dash-slash-dash-db-dash-slash-dash-table-dash-dash-dash--dash-dot-dash-csv-dash-dot-dash-csv')
'-dash/dash-db-dash/dash-table-dash--dash.dash-csv-dash.dash-csv' |
|
This made me worry that my current >>> dash_encode("/db/table-.csv.csv")
'-/db-/table---.csv-.csv'
>>> dash_encode('-/db-/table---.csv-.csv')
'---/db---/table-------.csv---.csv'
>>> dash_decode('---/db---/table-------.csv---.csv')
'-/db-/table---.csv-.csv'
>>> dash_decode('-/db-/table---.csv-.csv')
'/db/table-.csv.csv'The regex still works against that double-encoded example too:
|

|
Adopting this could result in supporting database files with surprising characters in their filename too. |
|
Should it encode Is it worth expanding dash-encoding outside of just |
|
Here's a useful modern spec for how existing URL percentage encoding is supposed to work: https://url.spec.whatwg.org/#percent-encoded-bytes |
|
Note that I've ruled out using |
|
Lots of great conversations about the dash encoding implementation on Twitter: https://twitter.com/simonw/status/1500228316309061633 @dracos helped me figure out a simpler regex: https://twitter.com/dracos/status/1500236433809973248
|

|
This comment from glyph got me thinking:
What happens if a table name includes a I should consider |
|
I want to try regular percentage encoding, except that it also encodes both the Should check what it does with emoji too. |
|
OK, for that percentage thing: the Python core implementation of URL percentage escaping deliberately ignores two of the characters we want to escape: _ALWAYS_SAFE = frozenset(b'ABCDEFGHIJKLMNOPQRSTUVWXYZ'
b'abcdefghijklmnopqrstuvwxyz'
b'0123456789'
b'_.-~')It also defaults to skipping I'm going to try borrowing and modifying the core of the Python implementation: https://github.com/python/cpython/blob/6927632492cbad86a250aa006c1847e03b03e70b/Lib/urllib/parse.py#L795-L814 class _Quoter(dict):
"""A mapping from bytes numbers (in range(0,256)) to strings.
String values are percent-encoded byte values, unless the key < 128, and
in either of the specified safe set, or the always safe set.
"""
# Keeps a cache internally, via __missing__, for efficiency (lookups
# of cached keys don't call Python code at all).
def __init__(self, safe):
"""safe: bytes object."""
self.safe = _ALWAYS_SAFE.union(safe)
def __repr__(self):
return f"<Quoter {dict(self)!r}>"
def __missing__(self, b):
# Handle a cache miss. Store quoted string in cache and return.
res = chr(b) if b in self.safe else '%{:02X}'.format(b)
self[b] = res
return res |
_ESCAPE_SAFE = frozenset(
b'ABCDEFGHIJKLMNOPQRSTUVWXYZ'
b'abcdefghijklmnopqrstuvwxyz'
b'0123456789_'
)
# I removed b'.-~')
class Quoter(dict):
# Keeps a cache internally, via __missing__
def __missing__(self, b):
# Handle a cache miss. Store quoted string in cache and return.
res = chr(b) if b in _ESCAPE_SAFE else '-{:02X}'.format(b)
self[b] = res
return res
quoter = Quoter().__getitem__
''.join([quoter(char) for char in b'foo/bar.csv'])
# 'foo-2Fbar-2Ecsv' |
|
Probably too late… but I have just seen this because And it reminded me of comma tools at W3C. Example, the text version of W3C homepage
I haven't checked all the cases in the thread. |
|
Needs more testing, but this seems to work for decoding the percent-escaped-with-dashes format: |
|
Suggestion from a conversation with Seth Michael Larson: it would be neat if plugins could easily integrate with whatever scheme this ends up using, maybe with the Making it easy for plugins to do the right, consistent thing is a good idea. |
|
Test: Lines 651 to 666 in d2e3fe3 One big advantage to this scheme is that redirecting old links to |
* Dash encoding functions, tests and docs, refs #1439 * dash encoding is now like percent encoding but with dashes * Use dash-encoding for row PKs and ?_next=, refs #1439 * Use dash encoding for table names, refs #1439 * Use dash encoding for database names, too, refs #1439 See also https://simonwillison.net/2022/Mar/5/dash-encoding/
|
I didn't need to do any of the fancy regular expression routing stuff after all, since the new dash encoding format avoids using |
|
OK, this has broken a lot more than I expected it would. Turns out https://datasette.io/-/databases for example has two: [
{
"name": "docs-index",
"path": "docs-index.db",
"size": 1007616,
"is_mutable": false,
"is_memory": false,
"hash": "0ac6c3de2762fcd174fd249fed8a8fa6046ea345173d22c2766186bf336462b2"
},
{
"name": "dogsheep-index",
"path": "dogsheep-index.db",
"size": 5496832,
"is_mutable": false,
"is_memory": false,
"hash": "d1ea238d204e5b9ae783c86e4af5bcdf21267c1f391de3e468d9665494ee012a"
}
] |
It's broken. This fixes #94 See also simonw/datasette#1439
|
If I want to reserve _ALWAYS_SAFE = frozenset(b'ABCDEFGHIJKLMNOPQRSTUVWXYZ'
b'abcdefghijklmnopqrstuvwxyz'
b'0123456789'
b'_.-~')So I'd add both |
|
I'm happy with this now that I've landed Tilde encoding in #1657. |
Datasette currently has surprising special behaviour for if a table name ends in
.csv- which can happen when a tool likecsvs-to-sqlitecreates tables that match the filename that they were imported from.https://latest.datasette.io/fixtures/table%2Fwith%2Fslashes.csv illustrates this behaviour: it links to
.csvand.jsonthat look like this:Where normally Datasette would add the
.csvor.jsonextension to the path component of the URL (as seen on other pages such as https://latest.datasette.io/fixtures/facet_cities) here the path_with_format() function notices that there is already a.in the path and instead adds?_format=csvto the query string instead.The problem with this mechanism is that it's pretty surprising. Anyone writing external code to Datasette who wants to get back the
.csvor.jsonversion giving the URL to a table page will need to know about and implement this behaviour themselves. That's likely to cause all kinds of bugs in the future.The text was updated successfully, but these errors were encountered: