This document is adapted, in part, from the original project description document.
- Project Abstract
- Project Description
- User Stories and Design Diagrams
- Project Tasks and Timeline
- ABET Concerns Essay
- Slideshow
- Self-Assessment Essays
- Professional Biographies
- Budget
- Appendix
- TODO
There have been many recent advances in game-playing AIs, such as the Dota2 AI and AlphaGo. With this project, we explored the use of conventional and cutting edge ML techniques to create a self-learning Starcraft II (SC2) AI agent capable of defeating Blizzard's Very Easy AI.
Kyle Arens - [email protected]
Ryan Benner - [email protected]
Jon Deibel - [email protected]
Dr. Ali Minai - http://www.ece.uc.edu/~aminai/
Inspired by recent advances in game-playing AI, we are attempting to address a similarly themed, albeit different problem - creating an SC2 AI agent that operates at human APM (actions per minute), up to ~400apm. Current SC2 AI agents abuse the fact that agents are able to take an inhuman number of actions extraordinarily quickly (such as 5000apm). Our initial goal was to restrict APM down to ~300apm in order to model our AI off of human capabilities and to more-effectively learn decisions. However, we settled on an upper limit of ~480apm, which is still human attainable by the most skilled players. With a hard-limit of ~480apm, any given action taken will have more importance than if the bot had a higher limit, such as ~5000apm.
We are scoping our project in the following manner:
- the agent will play as Terran
- against a Very Easy Terran AI provided in the retail version of the game
- on the maps Simple64 and flat64.

This diagram represents the highest level view of our architecture. Starcraft 2 game replay data is taken in, and used to generate a model for autonomously playing the game.
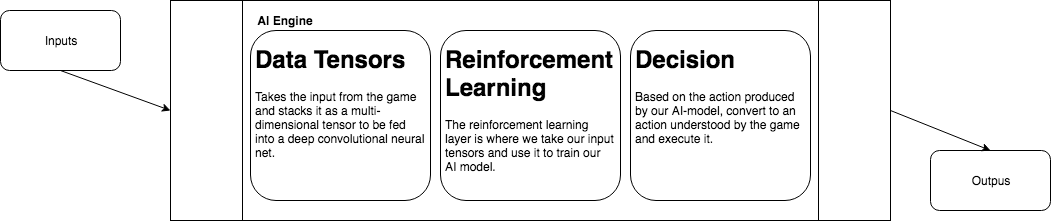
This diagram elaborates on our AI engine, and gives a high level view of what is being done at each stage. First the game state is parsed, then that parsed data is used to train the model, and turn the model decisions into in-game actions.
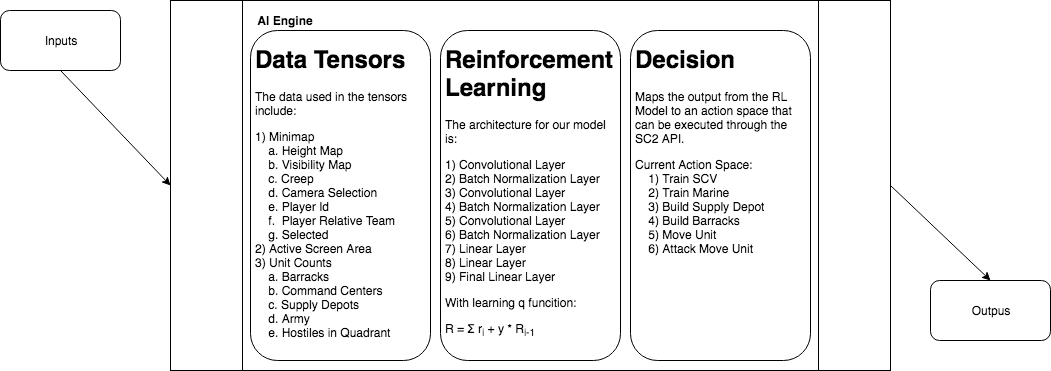
This diagram gives a much more in depth breakdown of what each portion of our AI engine does. It elaborates greatly on how the data is parsed, and how it's used in long and short term planning by our model.
Combined Task List, Timeline, and Effort Matrix.
Fall Presentation. Spring Presentation.
Fall Video. A recorded presentation was not created for Spring Semester.
Each member wrote their own assesment essay.
There have been no expenses to date.
Python abstraction: https://github.com/deepmind/pysc2
Raw C++ API for starcraft: https://github.com/Blizzard/s2client-proto
For deep model creation: https://github.com/tensorflow/tensorflow
Silver, David, et al. "Mastering the game of go without human knowledge." Nature 550.7676 (2017): 354-359.
| Work | Time | Team Members |
|---|---|---|
| Learning the basics of Reinforcement Learning | 25 Hours | Kyle Arens, Jon Deibel, Ryan Benner |
| Understanding C++/Python API | 10 Hours | Jon Deibel, Ryan Benner, Kyle Arens |
| Creation of baseline AI/First RL based AI | 10 Hours | Jon Deibel, Ryan Benner |
| Documentation | 5 Hours | Ryan Benner, Kyle Arens, Jon Deibel |
| Reading + Understanding AlphaGo | 5 Hours | Ryan Benner, Kyle Arens, Jon Deibel |
- Update design diagrams.
- Update task list (further).
- Research Actor-Critic Model.
- Continue research on Q-tables and Q-functions.
- Discussions on game state.