Official PyTorch implementation of ConvNeXt, from the following paper:
A ConvNet for the 2020s. arXiv 2022.
Zhuang Liu, Hanzi Mao, Chao-Yuan Wu, Christoph Feichtenhofer, Trevor Darrell and Saining Xie
Facebook AI Research, UC Berkeley
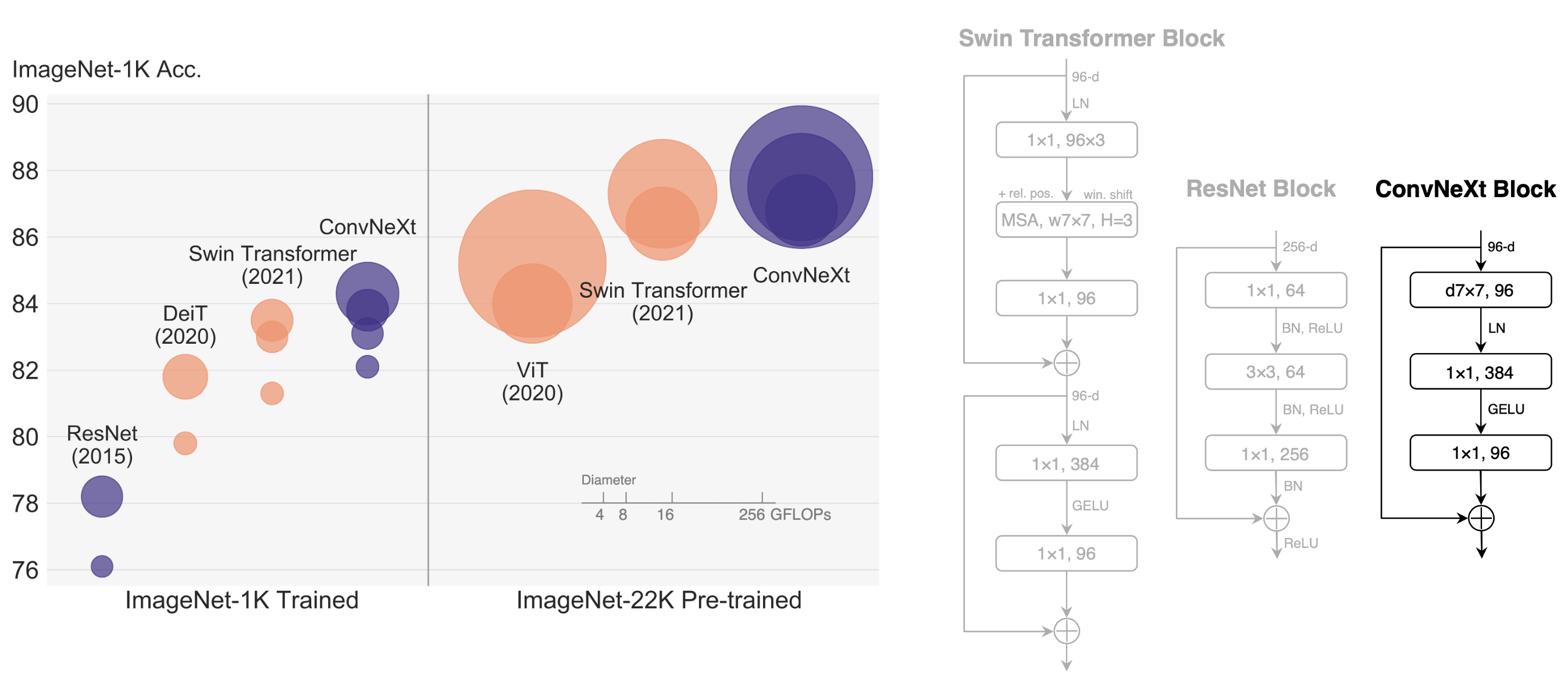
We propose ConvNeXt, a pure ConvNet model constructed entirely from standard ConvNet modules. ConvNeXt is accurate, efficient, scalable and very simple in design.
- ImageNet-1K Training Code
- ImageNet-22K Pre-training Code
- ImageNet-1K Fine-tuning Code
- Downstream Transfer (Detection, Segmentation) Code
- Image Classification [Colab] and Web Demo
- Fine-tune on CIFAR with Weights & Biases logging [Colab]
| name | resolution | acc@1 | #params | FLOPs | model |
|---|---|---|---|---|---|
| ConvNeXt-T | 224x224 | 82.1 | 28M | 4.5G | model |
| ConvNeXt-S | 224x224 | 83.1 | 50M | 8.7G | model |
| ConvNeXt-B | 224x224 | 83.8 | 89M | 15.4G | model |
| ConvNeXt-B | 384x384 | 85.1 | 89M | 45.0G | model |
| ConvNeXt-L | 224x224 | 84.3 | 198M | 34.4G | model |
| ConvNeXt-L | 384x384 | 85.5 | 198M | 101.0G | model |
| name | resolution | acc@1 | #params | FLOPs | 22k model | 1k model |
|---|---|---|---|---|---|---|
| ConvNeXt-B | 224x224 | 85.8 | 89M | 15.4G | model | model |
| ConvNeXt-B | 384x384 | 86.8 | 89M | 47.0G | - | model |
| ConvNeXt-L | 224x224 | 86.6 | 198M | 34.4G | model | model |
| ConvNeXt-L | 384x384 | 87.5 | 198M | 101.0G | - | model |
| ConvNeXt-XL | 224x224 | 87.0 | 350M | 60.9G | model | model |
| ConvNeXt-XL | 384x384 | 87.8 | 350M | 179.0G | - | model |
| name | resolution | acc@1 | #params | FLOPs | model |
|---|---|---|---|---|---|
| ConvNeXt-S | 224x224 | 78.7 | 22M | 4.3G | model |
| ConvNeXt-B | 224x224 | 82.0 | 87M | 16.9G | model |
| ConvNeXt-L | 224x224 | 82.6 | 306M | 59.7G | model |
Please check INSTALL.md for installation instructions.
We give an example evaluation command for a ImageNet-22K pre-trained, then ImageNet-1K fine-tuned ConvNeXt-B:
Single-GPU
python main.py --model convnext_base --eval true \
--resume https://dl.fbaipublicfiles.com/convnext/convnext_base_22k_1k_224.pth \
--input_size 224 --drop_path 0.2 \
--data_path /path/to/imagenet-1k
Multi-GPU
python -m torch.distributed.launch --nproc_per_node=8 main.py \
--model convnext_base --eval true \
--resume https://dl.fbaipublicfiles.com/convnext/convnext_base_22k_1k_224.pth \
--input_size 224 --drop_path 0.2 \
--data_path /path/to/imagenet-1k
This should give
* Acc@1 85.820 Acc@5 97.868 loss 0.563
- For evaluating other model variants, change
--model,--resume,--input_sizeaccordingly. You can get the url to pre-trained models from the tables above. - Setting model-specific
--drop_pathis not strictly required in evaluation, as theDropPathmodule in timm behaves the same during evaluation; but it is required in training. See TRAINING.md or our paper for the values used for different models.
See TRAINING.md for training and fine-tuning instructions.
This repository is built using the timm library, DeiT and BEiT repositories.
This project is released under the MIT license. Please see the LICENSE file for more information.
If you find this repository helpful, please consider citing:
@Article{liu2022convnet,
author = {Zhuang Liu and Hanzi Mao and Chao-Yuan Wu and Christoph Feichtenhofer and Trevor Darrell and Saining Xie},
title = {A ConvNet for the 2020s},
journal = {arXiv preprint arXiv:2201.03545},
year = {2022},
}