-
Notifications
You must be signed in to change notification settings - Fork 0
Commit
This commit does not belong to any branch on this repository, and may belong to a fork outside of the repository.
Merge pull request #26 from sharkutilities/featuring/timeseries/merge…
…-existing Timeseries Utility Functions for Data Frame Objects
- Loading branch information
Showing
7 changed files
with
575 additions
and
0 deletions.
There are no files selected for viewing
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -0,0 +1,59 @@ | ||
| # Time Series Utilities | ||
|
|
||
| <div align = "justify"> | ||
|
|
||
| Feature engineering, time series stationarity checks are few of the use-cases that are compiled in this gists. Check | ||
| individual module defination and functionalities as follows. | ||
|
|
||
| ## Stationarity & Unit Roots | ||
|
|
||
| Stationarity is one of the fundamental concepts in time series analysis. The | ||
| **time series data model works on the principle that the [_data is stationary_](https://www.analyticsvidhya.com/blog/2021/04/how-to-check-stationarity-of-data-in-python/) | ||
| and [_data has no unit roots_](https://www.analyticsvidhya.com/blog/2018/09/non-stationary-time-series-python/)**, this means: | ||
| * the data must have a constant mean (across all periods), | ||
| * the data should have a constant variance, and | ||
| * auto-covariance should not be dependent on time. | ||
|
|
||
| Let's understand the concept using the following example, for more information check [this link](https://www.analyticsvidhya.com/blog/2018/09/non-stationary-time-series-python/). | ||
|
|
||
| 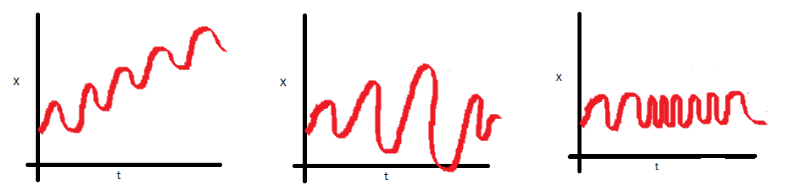 | ||
|
|
||
| <div align = "center"> | ||
|
|
||
| | ADF Test | KPSS Test | Series Type | Additional Steps | | ||
| | :---: | :---: | :---: | --- | | ||
| | ✅ | ✅ | _stationary_ | | | ||
| | ❌ | ❌ | _non-stationary_ | | | ||
| | ✅ | ❌ | _difference-stationary_ | Use differencing to make series stationary. | | ||
| | ❌ | ✅ | _trend-stationary_ | Remove trend to make the series _strict stationary. | | ||
|
|
||
| </div> | ||
|
|
||
| ```{eval-rst} | ||
| .. automodule:: pandaswizard.timeseries.stationarity | ||
| :members: | ||
| :undoc-members: | ||
| :show-inheritance: | ||
| ``` | ||
|
|
||
| ## Time Series Featuring | ||
|
|
||
| Time series analysis is a special segment of AI/ML application development where a feature is dependent on time. The code here | ||
| is desgined to create a *sequence* of `x` and `y` data needed in a time series problem. The function is defined with two input | ||
| parameters (I) **Lootback Period (T) `n_lookback`**, and (II) **Forecast Period (H) `n_forecast`** which can be visually | ||
| presented below. | ||
|
|
||
| <div align = "center"> | ||
|
|
||
|  | ||
|
|
||
| </div> | ||
|
|
||
| ```{eval-rst} | ||
| .. automodule:: pandaswizard.timeseries.ts_featuring | ||
| :members: | ||
| :undoc-members: | ||
| :show-inheritance: | ||
| ``` | ||
|
|
||
| </div> |
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -0,0 +1,29 @@ | ||
| # -*- encoding: utf-8 -*- | ||
|
|
||
| """ | ||
| A Set of Utility Functions for a Time Series Data for ``pandas`` | ||
| A time series analysis is a way of analyzing a sequence of data which | ||
| was collected over a period of time and the data is collected at a | ||
| specific intervals. The :mod:`pandas` provides various functions to | ||
| manipulate a time object which is a wrapper over the ``datetime`` | ||
| module and is a type of ``pd.Timestamp`` object. | ||
| The module provides some utility functions for a time series data | ||
| and tests like "stationarity" which is a must in EDA! | ||
| .. caution:: | ||
| The time series module consists of functions which was earlier | ||
| developed in `GH/sqlparser <https://gist.github.com/ZenithClown/f99d7e1e3f4b4304dd7d43603cef344d>`_. | ||
| .. note:: | ||
| More details on why the module was merged is | ||
| available `GH/#24 <https://github.com/sharkutilities/pandas-wizard/issues/24>`_. | ||
| .. note:: | ||
| Code migration details are mentioned | ||
| `GH/#27 <https://github.com/sharkutilities/pandas-wizard/issues/27>`_. | ||
| """ | ||
|
|
||
| from pandaswizard.timeseries.stationarity import * | ||
| from pandaswizard.timeseries.ts_featuring import * |
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -0,0 +1,86 @@ | ||
| # -*- encoding: utf-8 -*- | ||
|
|
||
| """ | ||
| Stationarity Checking for Time Series Data | ||
| A functional approach to check stationarity using different models | ||
| and the function attrbutes are as defined below. | ||
| (`More Information <http://ds-gringotts.readthedocs.io/>`_) | ||
| """ | ||
|
|
||
| from statsmodels.tsa.stattools import kpss # kpss test | ||
| from statsmodels.tsa.stattools import adfuller # adfuller test | ||
|
|
||
| def checkStationarity(frame : object, feature: str, method : str = "both", verbose : bool = True, **kwargs) -> bool: | ||
| """ | ||
| Performs ADF Test to Determine Data Stationarity | ||
| Given an univariate series formatted as `frame.set_index("data")` | ||
| the series can be tested for stationarity using the Augmented | ||
| Dickey Fuller (ADF) and Kwiatkowski-Phillips-Schmidt-Shin (KPSS) | ||
| test. The function also returns a `dataframe` of rolling window | ||
| for plotting the data using `frame.plot()`. | ||
| :type frame: pd.DataFrame | ||
| :param frame: The dataframe that (ideally) contains a single | ||
| univariate feature (`feature`), else for a | ||
| dataframe containing multiple series only the | ||
| `feature` series is worked upon. | ||
| :type feature: str | ||
| :param feature: Name of the feature, i.e. the column name | ||
| in the dataframe. The `rolling` dataframe returns | ||
| a slice of `frame[[feature]]` along with rolling | ||
| mean and standard deviation. | ||
| :type method: str | ||
| :param method: Select any of the method ['ADF', 'KPSS', 'both'], | ||
| using the `method` parameter, name is case | ||
| insensitive. Defaults to `both`. | ||
| """ | ||
|
|
||
| results = dict() # key is `ADF` and/or `KPSS` | ||
| stationary = dict() | ||
|
|
||
| if method.upper() in ["ADF", "BOTH"]: | ||
| results["ADF"] = adfuller(frame[feature].values) # should be send like `frame.col.values` | ||
| stationary["ADF"] = True if (results["ADF"][1] <= 0.05) & (results["ADF"][4]["5%"] > results["ADF"][0]) else False | ||
|
|
||
| if verbose: | ||
| print(f"Observations of ADF Test ({feature})") | ||
| print("===========================" + "=" * len(feature)) | ||
| print(f"ADF Statistics : {results['ADF'][0]:,.3f}") | ||
| print(f"p-value : {results['ADF'][1]:,.3f}") | ||
|
|
||
| critical_values = {k : round(v, 3) for k, v in results["ADF"][4].items()} | ||
| print(f"Critical Values : {critical_values}") | ||
|
|
||
| # always print if data is stationary/not | ||
| print(f"[ADF] Data is :", "\u001b[32mStationary\u001b[0m" if stationary else "\x1b[31mNon-stationary\x1b[0m") | ||
|
|
||
| if method.upper() in ["KPSS", "BOTH"]: | ||
| results["KPSS"] = kpss(frame[feature].values) # should be send like `frame.col.values` | ||
| stationary["KPSS"] = False if (results["KPSS"][1] <= 0.05) & (results["KPSS"][3]["5%"] > results["KPSS"][0]) else True | ||
|
|
||
| if verbose: | ||
| print(f"Observations of KPSS Test ({feature})") | ||
| print("============================" + "=" * len(feature)) | ||
| print(f"KPSS Statistics : {results['KPSS'][0]:,.3f}") | ||
| print(f"p-value : {results['KPSS'][1]:,.3f}") | ||
|
|
||
| critical_values = {k : round(v, 3) for k, v in results["KPSS"][3].items()} | ||
| print(f"Critical Values : {critical_values}") | ||
|
|
||
| # always print if data is stationary/not | ||
| print(f"[KPSS] Data is :", "\x1b[31mNon-stationary\x1b[0m" if stationary else "\u001b[32mStationary\u001b[0m") | ||
|
|
||
| # rolling calculations for plotting | ||
| rolling = frame.copy() # enable deep copy | ||
| rolling = rolling[[feature]] # only keep single feature, works if multi-feature sent | ||
| rolling.rename(columns = {feature : "original"}, inplace = True) | ||
|
|
||
| rolling_ = rolling.rolling(window = kwargs.get("window", 12)) | ||
| rolling["mean"] = rolling_.mean()["original"].values | ||
| rolling["std"] = rolling_.std()["original"].values | ||
|
|
||
| return results, stationary, rolling |
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -0,0 +1,202 @@ | ||
| # -*- encoding: utf-8 -*- | ||
|
|
||
| """ | ||
| A Set of Methodologies involved with Feature Engineering | ||
| Feature engineering or feature extraction involves transforming the | ||
| data by manipulation (addition, deletion, combination) or mutation of | ||
| the data set in hand to improve the machine learning model. The | ||
| project mainly deals with, but not limited to, time series data that | ||
| requires special treatment - which are listed over here. | ||
| Feature engineering time series data will incorporate the use case of | ||
| both univariate and multivariate data series with additional | ||
| parameters like lookback and forward tree. Check documentation of the | ||
| function(s) for more information. | ||
| """ | ||
|
|
||
| import numpy as np | ||
| import pandas as pd | ||
|
|
||
|
|
||
| class DataObjectModel(object): | ||
| """ | ||
| Data Object Model (`DOM`) for AI-ML Application Development | ||
| Data is the key to an artificial intelligence application | ||
| development, and often times real world data are gibrish and | ||
| incomprehensible. The DOM is developed to provide basic use case | ||
| like data formatting, seperating `x` and `y` variables etc. such | ||
| that a feature engineering function or a machine learning model | ||
| can easily get the required information w/o much needed code. | ||
| # Example Use Cases | ||
| The following small use cases are possible with the use of the | ||
| DOM in feature engineering: | ||
| 1. Formatting a Data to a NumPy ND-Array - an iterable/pandas | ||
| object can be converted into `np.ndarray` which is the base | ||
| data type of the DOM. | ||
| ```python | ||
| np.random.seed(7) # set seed for duplication | ||
| data = pd.DataFrame( | ||
| data = np.random.random(size = (9, 26)), | ||
| columns = list("ABCDEFGHIJKLMNOPQRSTUVWXYZ") | ||
| ) | ||
| dom = DataObjectModel(data) | ||
| print(type(dom.data)) | ||
| >> <class 'numpy.ndarray'> | ||
| ``` | ||
| 2. Breaking an Array of `Xy` into Individual Component - for | ||
| instance a dataframe/tabular data has `X` features along side | ||
| `y` in column. The function considers the data and breaks it | ||
| into individual components. | ||
| ```python | ||
| X, y = dom.create_xy(y_index = 1) | ||
| # or if `y` is group of elements then: | ||
| X, y = dom.create_xy(y_index = (1, 4)) | ||
| ``` | ||
| """ | ||
|
|
||
| def __init__(self, data: np.ndarray) -> None: | ||
| self.data = self.__to_numpy__(data) # also check integrity | ||
|
|
||
| def __to_numpy__(self, data: object) -> np.ndarray: | ||
| """Convert Meaningful Data into a N-Dimensional Array""" | ||
|
|
||
| if type(data) == np.ndarray: | ||
| pass # data is already in required type | ||
| elif type(data) in [list, tuple]: | ||
| data = np.array(data) | ||
| elif type(data) == pd.DataFrame: | ||
| # often times a full df can be passed, which is a ndarray | ||
| # thus, the df can be easily converted to an np ndarray: | ||
| data = data.values | ||
| else: | ||
| raise TypeError( | ||
| f"Data `type == {type(data)}` is not convertible.") | ||
|
|
||
| return data | ||
|
|
||
|
|
||
| def create_xy(self, y_index : object = -1) -> tuple: | ||
| """ | ||
| Breaks the Data into Individual `X` and `y` Components | ||
| From a tabular or ndimensional structure, the code considers | ||
| `y` along a given axis (`y_index`) and returns two `ndarray` | ||
| which can be treated as `X` and `y` individually. | ||
| The function uses `np.delete` command to create `X` feature | ||
| from the data. (https://stackoverflow.com/a/5034558/6623589). | ||
| This function is meant for multivariate dataset, and is only | ||
| applicable when dealing with multivariate time series data. | ||
| The function can also be used for any machine learning model | ||
| consisting of multiple features (even if it is a time series | ||
| dataset). | ||
| :type y_index: object | ||
| :param y_index: Index/axis of `y` variable. If the type is | ||
| is `int` then the code assumes one feature, | ||
| and `y_.shape == (-1, 1)` and if the type | ||
| of `y_index` is `tuple` then | ||
| `y_.shape == (-1, (end - start - 1))` since | ||
| end index is exclusive as in `numpy` module. | ||
| """ | ||
|
|
||
| if type(y_index) in [list, tuple]: | ||
| x_ = self.data | ||
| y_ = self.data[:, y_index[0]:y_index[1]] | ||
| for idx in range(*y_index)[::-1]: | ||
| x_ = np.delete(x_, obj = idx, axis = 1) | ||
| elif type(y_index) == int: | ||
| y_ = self.data[:, y_index] | ||
| x_ = np.delete(self.data, obj = y_index, axis = 1) | ||
| else: | ||
| raise TypeError("`type(y_index)` not in [int, tuple].") | ||
|
|
||
| return x_, y_ | ||
|
|
||
|
|
||
| class CreateSequence(DataObjectModel): | ||
| """ | ||
| Create a Data Sequence Typically to be used in LSTM Model | ||
| LSTM Model, or rather any time series data, requires a specific | ||
| sequence of data consisting of `n_lookback` i.e. length of input | ||
| sequence (or lookup values) and `n_forecast` values, i.e., the | ||
| length of output sequence. The function tries to provide single | ||
| approach to break data into sequence of `x_train` and `y_train` | ||
| for training in neural network. | ||
| """ | ||
|
|
||
| def __init__(self, data: np.ndarray) -> None: | ||
| super().__init__(data) | ||
|
|
||
|
|
||
| def create_series( | ||
| self, | ||
| n_lookback : int, | ||
| n_forecast : int, | ||
| univariate : bool = True, | ||
| **kwargs | ||
| ) -> tuple: | ||
| """ | ||
| Create a Sequence of `x_train` and `y_train` for training a | ||
| neural network model with time series data. The basic | ||
| approach in building the function is taken from: | ||
| https://stackoverflow.com/a/69912334/6623589 | ||
| UPDATE [22-02-2023] : The function is now modified such that | ||
| it now can also return a sequence for multivariate time-series | ||
| analysis. The following changes has been added: | ||
| * 💣 refactor function name to generalise between univariate | ||
| and multivariate methods. | ||
| * 🔧 univariate feature can be called directly as this is the | ||
| default code behaviour. | ||
| * 🛠 to get multivariate functionality, use `univariate = False` | ||
| * 🛠 by default the last column (-1) of `data` is considered | ||
| as `y` feature by slicing `arr[s:e, -1]` but this can be | ||
| configured using `kwargs["y_feat_"]` | ||
| """ | ||
|
|
||
| x_, y_ = [], [] | ||
| n_record = self.__check_univariate_get_len__(univariate) \ | ||
| - n_forecast + 1 | ||
|
|
||
| y_feat_ = kwargs.get("y_feat_", -1) | ||
|
|
||
| for idx in range(n_lookback, n_record): | ||
| x_.append(self.data[idx - n_lookback : idx]) | ||
| y_.append( | ||
| self.data[idx : idx + n_forecast] if univariate | ||
| else self.data[idx : idx + n_forecast, y_feat_] | ||
| ) | ||
|
|
||
| x_, y_ = map(np.array, [x_, y_]) | ||
|
|
||
| if univariate: | ||
| # the for loop is so designed it returns the data like: | ||
| # (<records>, n_lookback, <features>) however, | ||
| # for univariate the `<features>` dimension is "squeezed" | ||
| x_, y_ = map(lambda arr : np.squeeze(arr), [x_, y_]) | ||
|
|
||
| return [x_, y_] | ||
|
|
||
|
|
||
| def __check_univariate_get_len__(self, univariate : bool) -> int: | ||
| """ | ||
| Check if the data is a univariate one, and if `True` then | ||
| return the length, i.e. `.shape[0]`, for further analysis. | ||
| """ | ||
|
|
||
| if (self.data.ndim != 1) and (univariate): | ||
| raise TypeError("Wrong dimension for univariate series.") | ||
|
|
||
| return self.data.shape[0] |
Oops, something went wrong.