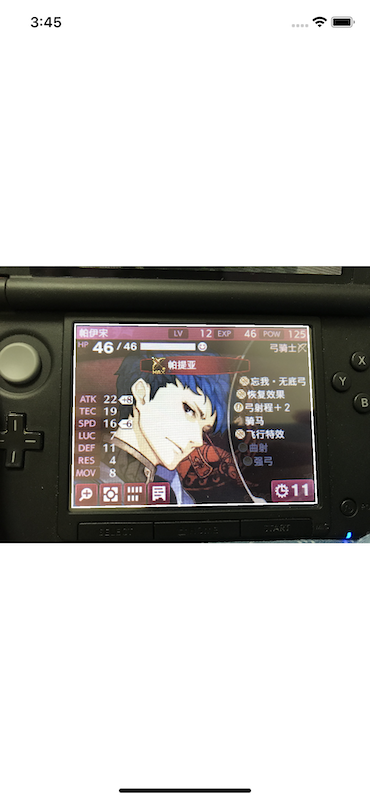
This repository is about to show how to detector the screen area from Nintendo 3DS in an image.
For example, for an input image, recognize the screen area from a conventional angle. Then transform it to a flat image.

This method use CNN and implemented by Keras. This repository also provides an example of how to use trained model in iOS app.
Python
- Python 3.6
- Keras 2.1.6
- coremltools 2.0
- opencv-python 3.4.3.18
iOS
- CoreML
- opencv2
I took a lot of pictures from different angle of Nintendo 3DS.
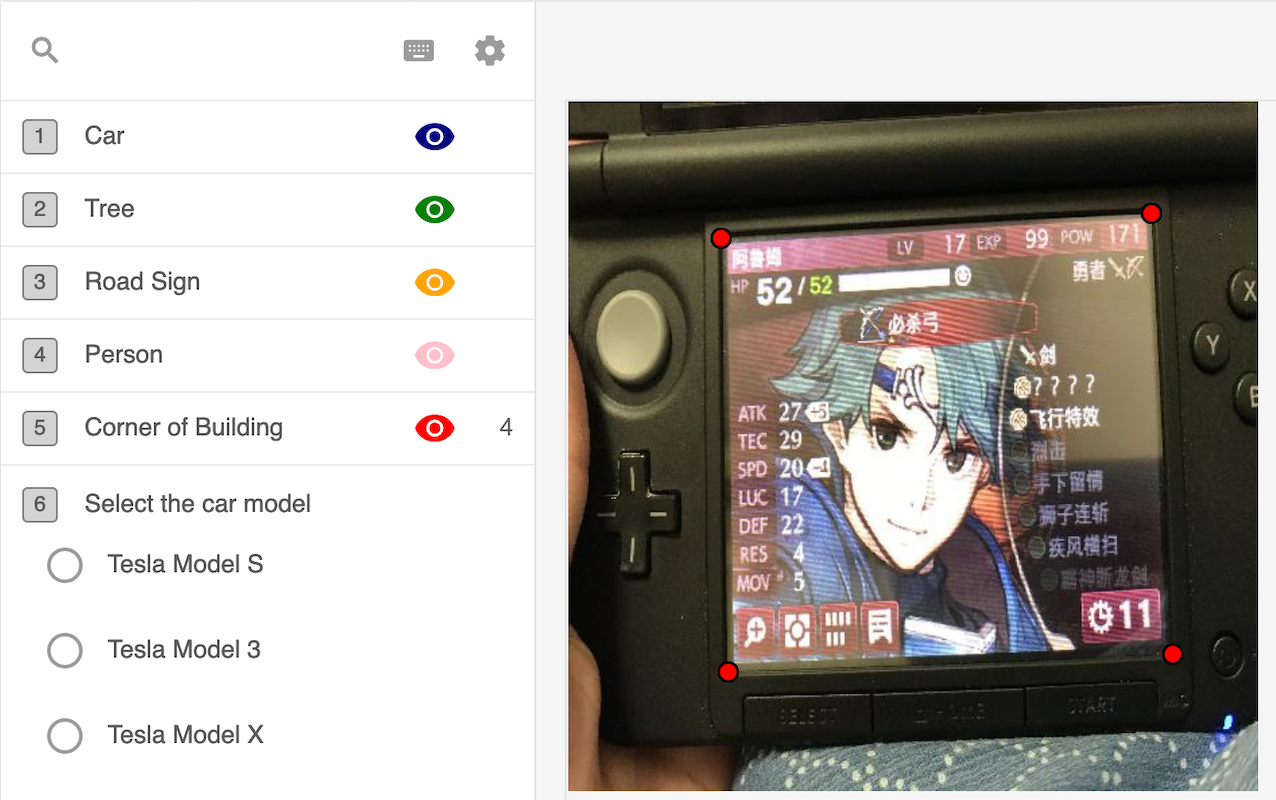
To get the mask of screen area, I use Labelbox which is a great tool to label the image. The origin image is too big so I resized it to 256 x 256 first. I marked every corner coordinate of screen area like this.
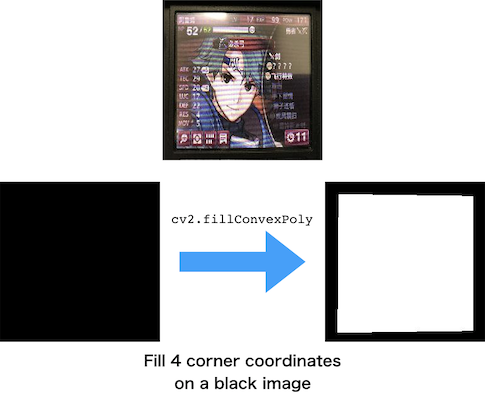
Now I have every 4 corner coordinates for each image. But I'm not going to predict coordinates. I tried, it's difficult and unstable. Maybe there is a good method I just don't know it. I'm going to predict if a pixel in the screen area or not. So, this is a binary classification problem.
I only took 31 pictures. I need more sample to fit the model. I use ImageDataGenerator to increase my sample. ImageDataGenerator can help you create you sample by zooming, sliding, rotating and so on. It keeps core information of a image but increases it's variety. Now I have 640 images. train:val:test is 70:15:15.
I learned this from Bruno G. do Amaral at kallge.
The model is simply a 3 layers CNN.
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d_1 (Conv2D) (None, 256, 256, 32) 896
_________________________________________________________________
conv2d_2 (Conv2D) (None, 256, 256, 32) 9248
_________________________________________________________________
conv2d_3 (Conv2D) (None, 256, 256, 1) 801
=================================================================
Total params: 10,945
Trainable params: 10,945
Non-trainable params: 0
_________________________________________________________________
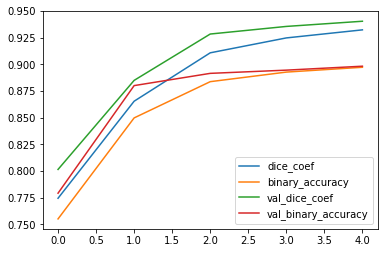
The keypoint is the loss function. It's combiled binary crossentropy and dice coef to emphasize a good prediction accuracy in the mask area.
5 epochs with a batch_size of 10.
model.fit(x_train, y_train, epochs=5, validation_data=(x_val, y_val), batch_size=10, verbose=1)
loss: -0.7986 - dice_coef: 0.9322 - binary_accuracy: 0.8972 - true_positive_rate: 0.9410 - val_loss: -0.8138 - val_dice_coef: 0.9403 - val_binary_accuracy: 0.8982 - val_true_positive_rate: 0.9309
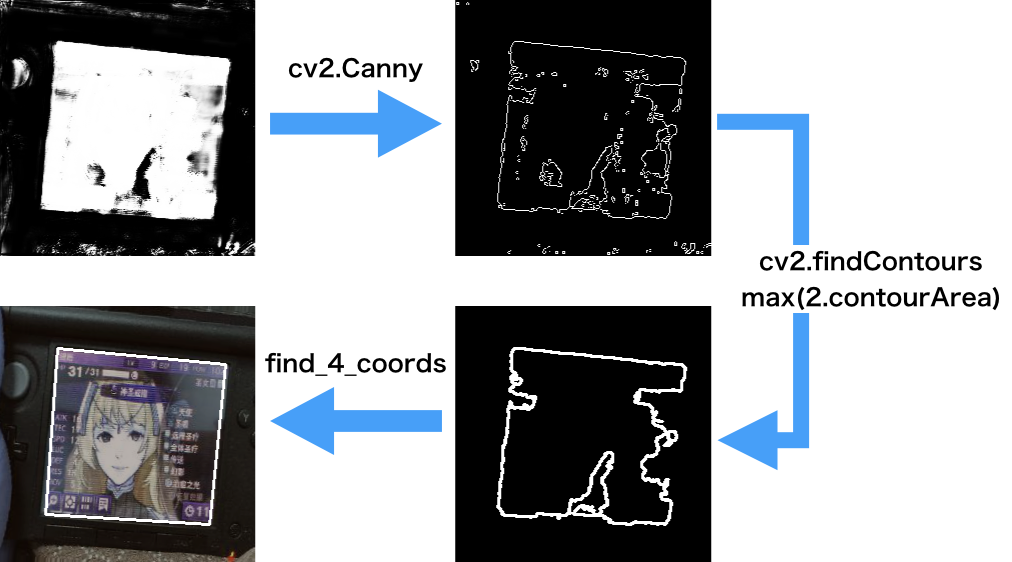
This is the exciting part that you will get the clean image you want.
-
Apply prediction on image. We will get a prediction probability result. Filter the value lower than 0.95. We will get a binary prediction result.
-
Use
cv2.Cannyto get the edge of each block. It may generate many edges. Choose the one that has the biggest area. -
We roughly get the screen edge. But it doesn't shapes as a quadrilateral. We calculate the nearest point to the corner on the edge. Plot the area on the original image.
-
The result shows we get the area that we want.
-
Flat the image using the method pyimagesearch provide. This is basically a matrix transform.
If you want to apply your model to iOS. I provide sample code that read image and detect the area.