Gujarati is native language to the Indian state of Gujarat sopken by around 60 million people. It's 6th most widely spoken language of India and 26th most widely spoken language in the world. This is the first speech recognition model for Gujarati Language. Model is trained using deepspeech mozilla framework and currenty achieves 8.7% WER (Word Error Rate).
- To Use speech recognition engine you need to have python 3.7 or below installed on your system.
pip install requirements.txt
Using Command line inference is plain and simple. Note that here we are using sample demo.wav file as input.
deepspeech --model gu_model/output_graph.pb --alphabet gu_model/alphabet.txt --lm gu_model/lm.binary --trie gu_model/trie --audio demo.wav
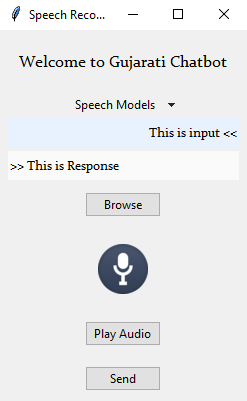
Using gui.py file, you can interact with Speech Recognizer GUI. Check your mic first and then Select speech model.
Speech Database has been created from the multiple sources like: Audiobooks, YouTube Audios etc.
lm.binary file is generate from web scrapping scrips of Gujarati wikipedia and gujarati news/blogs sites. Contact me if you want entire corpus.
- WER Improvement
- Language model enhancement.