#Pome
Pome stands for Postgres Metrics. Pome is a PostgreSQL Metrics Dashboard to keep track of the health of your database. This project is at a very early stage and there are a lot of missing features, but I'm hoping to be able to make the project progress quickly. You can read more about the motivation behind Pome here

##How to install Pome
Pome provides pre-built binaries with the releases, but you can also use the Go packaging system:
go get github.com/rach/pome
Then to update Pome:
go get -u github.com/rach/pome
To install Go, you can follow the Go documentation or use your internal packaging system.
##How to run Pome
The command line provides some help on how to use Pome:
$> pome --help
usage: Pome --username=USERNAME [<flags>] <DBNAME>
A Postgres Metrics Dashboard.
Flags:
--help Show context-sensitive help (also try --help-long and --help-man).
-h, --host=HOSTNAME database server host (default: localhost)
-p, --port=PORT database server port (default: 2345)
-s, --sslmode=require database SSL mode (default: disable)
-W, --password=PASSWORD
-U, --username=USERNAME
--version Show application version.
Args:
<DBNAME>
If your database doesn't have a password set, then you can run Pome like this:
$> pome -U myuser mydatabase
2015/12/09 12:09:43 Starting Pome 0.1.0
2015/12/09 12:09:43 Application will be available at http://127.0.0.1:2345
If your database is protected by a password, then you need to pass it as an argument. In the future, Pome will prompt the user for the password (see this issue).
Once Pome is running, you can access the dashboard via your browser and you should see an interface like this:
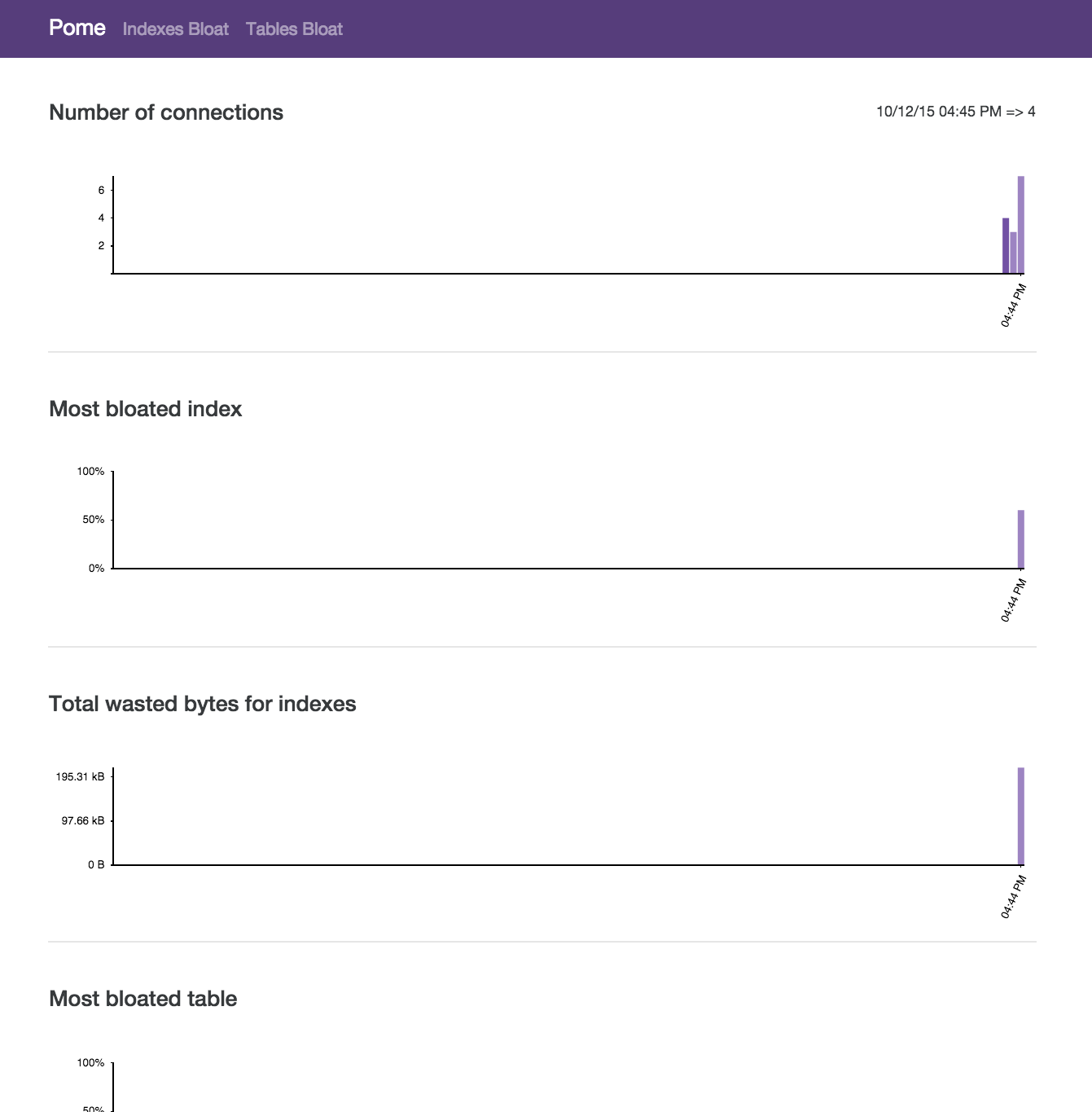
##Which metrics does Pome provide
Right now, Pome collects the following metrics:
- Database size
- Tables size
- Indexes size
- Number of Connections
- Ratio of the most bloated table
- Ratio of the most bloated index
- Total of wasted bytes due to bloat in tables
- Total of wasted bytes due to bloat in indexes
- The bloat ratio on individual tables and indexes
- Wasted bytes per table
There are a lot of other metrics that will be added soon, like:
- Unused indexes
- Cache hit ratio
- Amount of wal files
- Transactions per second
- Number of queries longer than 5s and 5min
- Etc
If you are interested in monitoring CPU, disk IO ... This will need to be done via another tool. Pome will only be collecting data which can be gathered through Postgres
##Why build Pome?
PostgreSQL is incredibly stable, especially with small databases. You too often see databases in the wild without the care of a loving DBA. This can give the illusion that everything is alright even when your database is slowly getting worse. A lot of things can be analyzed within postgres to get a health status but sadly it misses a simple tool to use for less experienced people.
This project follows 3 principles: Simplicity, Opinionated, Batteries included.
Simplicity, the project aims to be easy to deploy and run. It's why Pome can run as a binary. The project also aims to feel like the psql command and uses common arguments.
Opinionated, Pome has the goal to be pre-configured and analyse commonly useful metrics. We want the project to have sensible defaults. In the future, the tool will allow some level of configuration but without compromising Simplicity.
Batteries Included, Pome is built to be accessed via a web interface. The web app is shipped within the binary and Pome is taking care of serving the assets (HTML, js, CSS). Pome is not built to be a public facing tool so performance in delivering assets was not a concern. It should be possible to run the frontend individually if it's a concern for you. Pome tries to not depend on any dependency which cannot be shipped with the binary and it's one of the reasons why Pome is stateless right now.
Pome isn't aiming to be a tool for humongous Postgres instances which are already in the hands of a DBA who can have the time to setup more advanced monitoring tools. Pome won't be an alternative to a more configurable tool like collectd.
##Can I use Pome in Production?
If the database is heavily used then I would avoid it for now until we get more load testing and more configuration options.
##Supported PostgreSQL Versions
The tool has been developed and tested against PG 9.4 and it should be working on the future versions. Pome doesn't have the intent to support older versions because it may require to have different SQL statements for different versions but if there are some requests it will be considered.
##Stateless
Pome is stateless (at least for now) to keep the tool simple. I did consider using few options:
- using an external time series database
- using the current PostgreSQL database (as pg_diagnose does)
- using an embedded key/value database for Go like bolt. But at the end, I decided to keep it simple and store the last 120 metrics in-memory with the trade-offs that it implies. Let see where Pome goes, so that may change.
##Contributing
This project had also some learning motivation, as I had never written a Go project and hadn't touched react for a while. I may have made some mistakes or didn't follow some good practices for which I would appreciate some feedbacks.
Otherwise, there are a few tasks which can be done if you want to help
- Suggesting new metrics
- Testing the tools and submitting issues
- Reviewing and Improving the current code codebase. Both languages used are not my daily programming language so I probably did beginner mistakes
- Correcting my English. Sorry, I'm not a native English speaker so mistakes will happen
- Report issues
- Solving bugs from the issue trackers
##Inspirations
When Pome was only a rough idea, I checked online what already existed and I found a few similar projects which inspired me:
- postgresql-metrics from Spotify
- pg_diagnose from Heroku
- Powa
- Bucardo check_postgres
- RethinkDB dashboard
Pome has a different goal from the tools above.
##Licence
Pome is licensed under Apache V2 license, the full license text can be found here