This notebook provides an overview and implementation of the YOLOWorld object detection model, which can identify any object in an image based on a textual description. The notebook explains the motivation behind the model, its architecture, and how it can be used identify objects in images.
YOLO-World is a novel object detection model developed by Tencent AI Lab - Computer Vision Center that can identify objects in an offline-vocabulary setting. It is a fusion of vision and language models, which can identify objects based on a textual description. The model fuses the features extracted from the vision model with those of embeddings extracted from the language model to understand the correlation between the image and its description. This allows for the recognition of objects that are not present in the training data and a better understanding of the context of the image.
YOLO-World has three main components: Darknet, CLIP, and Path Aggregation Network (PAN).
Darknet is a 53-layer deep neural network that is trained on the COCO and ImageNet datasets. It is used to extract visual features from the input image.
CLIP is a language-vision model developed by OpenAI that learns to associate images and their textual descriptions. It is used to extract embeddings from the textual description of the image.
PAN is a neural network that is used to combine low-level and high-level features from an image. It is used to make sure that the low-level and high-level features from an image are combined properly, which is important for object detection problems.
YOLO-World outperforms other open-vocabulary models in terms of performance. The following table, taken from the paper, shows how YOLO-World outperforms other open-vocabulary models.
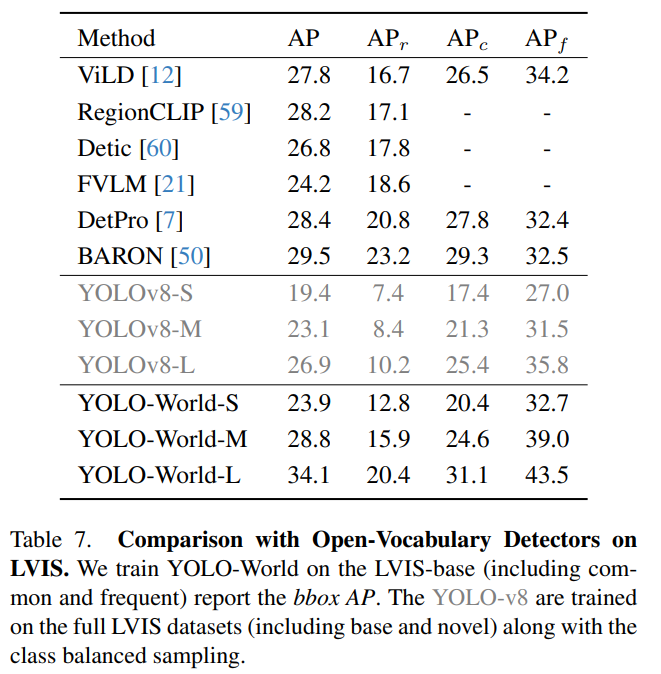
The code in this notebook demonstrates how to use the YOLO-World model to identify objects in images. It includes the following steps:
Installing the dependencies and downloading the pre-trained model and test image. Setting up the YOLO-World model and pipeline. Running the model on the test image and visualizing the results. The code uses the MIM library to install the YOLO-World model and the supervision library to visualize the results.
YOLO-World is a powerful object detection model that can identify any object in an image based on a textual description. It is a fusion of vision and language models that can recognize objects that are not present in the training data and better understand the context of the image. The code in this notebook demonstrates how to use the YOLO-World model to identify objects in images.