🚀 Feature Request: Loading audio data from BytesIO or memory #800
Comments
|
Hi @antimora (and @faroit ) cc @vincentqb Thanks for bring this up. I gave some thoughts to this and did quick research. Let me start with stating where we stand.
We use
I do not see a way to pass file object (
There is nothing much we can do about it. Following these, I looked at some Python solution for MP3, and it seems that miniaudio supports in-memory MP3 decoding. I did not use this library, but if this library provides MP3 decoding, then one should be able to convert it to (via NumPy array) torch Tensor type. As of adding such functionality to However at this moment, we, If someone can confirm that What do you think? |
|
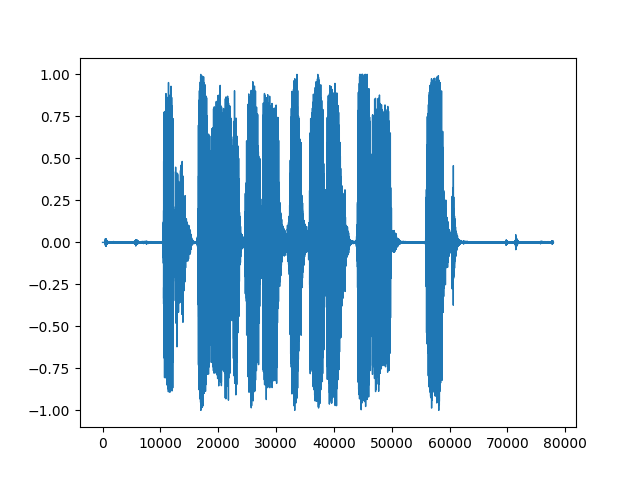
@mthrok , thank you very much for you detailed quick response. This is very helpful. I agree with you regarding the challenges and limitations of currently used back-ends. After you have mentioned miniaudio library, I have checked out and I can confirm it perfectly satisfies my use case. Not only I can load MP3 data from memory but I can also down-sample (from 44100 to 16000) on the fly. Also the library seems native and does not spawn a separate process like pydub.AudioSegment. Another bonus is there are no OS dependency, like ffmpeg. miniaudio uses C lib (https://miniaud.io/). I definitely recommend looking into this as a new backend. For those who wishes to see a working code, here it is: from pathlib import Path
import matplotlib.pyplot as plt
import torch
from miniaudio import SampleFormat, decode
# get mp3 bytes
audio_bytes = Path('common_voice_en_20603299.mp3').read_bytes()
# decode mp3 bytes, and at the same time downsample and have the output in signed 32 bit integer
decoded_audio = decode(audio_bytes, nchannels=1, sample_rate=16000, output_format=SampleFormat.SIGNED32)
# create tensor out of the audio samples
decoded_audio = torch.FloatTensor(decoded_audio.samples)
# normalize 32 integer bit audio by dividing by 2147483648 (or short hand 1 << 31)
decoded_audio /= (1 << 31)
print('Max:', decoded_audio.max())
print('Min:', decoded_audio.min())
print('Shape:', decoded_audio.shape)
print('Dtype:', decoded_audio.dtype)
# plot to visually verify
plt.plot(decoded_audio.numpy(), linewidth=1)
plt.savefig('miniaudio-16000-normalized.png')MP3 file: common_voice_en_20603299.zip Plot output: |
|
I am glad that it worked well for your needs, and thank you for the code snippet. This is useful for the whole torchaudio user base.
|
|
Thanks, @vincentqb . I think minimp3 could be another good candidate for torchaudio's backend. Unfortunately, a python project with minimp3 binding seems to unmaintained and unreleased: https://github.com/pyminimp3/pyminimp3. So I cannot immediately use it. It looks like miniaudio uses dr_libs for its decoders: Probably dr_libs decoders is more suitable for torchaudio since it does not have extra functionalities, such as playing playing audio on a device. One note that I wanted to share with others. miniaudio uses Linear Resampling (https://miniaud.io/docs/manual/index.html#ResamplingAlgorithms) as its default resampling algorithm. Does anyone know how much this might affect speech training vs if sinc_interpolation is uses, such as in torchaudio's resample: https://pytorch.org/audio/transforms.html#resample? |
I compared several resampling methods in some speech recognition tasks a long time ago, but we did not find a large impact. With feature extraction, normalization, and re-training, such difference can be ignored. (it might be a problem if we cannot re-train a model). |
|
EDIT (by @mthrok): The memory leak issue mentioned here is fixed at irmen/pyminiaudio@07773a6 UPDATE: I have discovered I have filed a bug with pyminiaudio about this: irmen/pyminiaudio#19 I will do more debugging to see if there is a workaround. But currently I am back where I started. |
Thanks for sharing your finding. That's very unfortunate. |
|
@mthrok and others. I found a workaround for the memory leak that I described a comment of the bug I have reported: irmen/pyminiaudio#19 (comment). The solution still uses miniaudio's functionality but calls different function. The memory leak appears in pyminiaudio's implementation of decode* functions, which do not release memory. For those wishing to use pyminiaudio's in memory MP3 decoder, here is a working code which I will be using in my Common Voice training. Note: I have reimplemented import numpy as np
import torchaudio
import array
from pathlib import Path
import matplotlib.pyplot as plt
import torch
from miniaudio import DecodeError, ffi, lib
import resampy
import soundfile as sf
# get mp3 bytes
audio_bytes = Path('common_voice_en_20603299.mp3').read_bytes()
def mp3_read_f32(data: bytes) -> array:
'''Reads and decodes the whole mp3 audio data. Resulting sample format is 32 bits float.'''
config = ffi.new('drmp3_config *')
num_frames = ffi.new('drmp3_uint64 *')
memory = lib.drmp3_open_memory_and_read_pcm_frames_f32(data, len(data), config, num_frames, ffi.NULL)
if not memory:
raise DecodeError('cannot load/decode data')
try:
samples = array.array('f')
buffer = ffi.buffer(memory, num_frames[0] * config.channels * 4)
samples.frombytes(buffer)
return samples, config.sampleRate, config.channels
finally:
lib.drmp3_free(memory, ffi.NULL)
ffi.release(num_frames)
decoded_audio, sample_rate, channels = mp3_read_f32(audio_bytes)
assert channels == 1
# TODO handle channels > 1 cases
decoded_audio = np.asarray(decoded_audio)
# Resample to 16000
decoded_audio = resampy.resample(decoded_audio, sample_rate, 16000, axis=0, filter='kaiser_best')
decoded_audio = torch.FloatTensor(decoded_audio)
# Or resample with torchaudio's sinc_interpolation
# resampler = torchaudio.transforms.Resample(sample_rate, 16000)
# decoded_audio = resampler(decoded_audio)
# Scale down to [-1:1] Resampling somehow scales up.
decoded_audio /= decoded_audio.abs().max()
print('Max:', decoded_audio.max())
print('Min:', decoded_audio.min())
print('Shape:', decoded_audio.shape)
print('Dtype:', decoded_audio.dtype)
# plot to visually verify
plt.plot(decoded_audio, linewidth=1)
plt.savefig('mp3_read_f32-16000-torchaudio-normalized-kaiser_best.png')
# test audio quality
sf.write(open('mp3_read_f32.wav', 'wb'), decoded_audio.numpy(), 16000)
|

|
Hi @antimora That's wonderful! I am glad that it's working again for you and thanks for sharing the resolution 😀 |
|
Just for information, I'm working on a pure-C ffmpeg audio reading bindings for PyTorch (currently C-side allocates gives back a DLPack tensor): https://github.com/vadimkantorov/readaudio I'm planning to also support filter graphs (for augmentation) and decoding from byte array. Of course it's not mature or tested, but if using ffmpeg directly works okay from perf point of view, this simple approach may be okay. |
|
@vadimkantorov Thanks for the information and your effort. I started using miniaudio API to decode which is very fast compared to other python converted. However, when I used resampy or torchaudio's resampling, the conversation ended up being extremely slow (see my previous comment. Luckily miniaudio has resample function which is fast. Uses linear algorithm (https://miniaud.io/docs/manual/index.html#ResamplingAlgorithms) which is the same as torchaudio's linear resampler ( audio/torchaudio/compliance/kaldi.py Line 890 in ddb8577 I'll post my working function for in-memory mp3 decoder and resampler (48000 -> 16000). I'll be using to convert CommonVoice MP3 files. Currently it converts 100K mp3 files (4 second long) in 9 mins. |
@vadimkantorov FYI torchvision has FFmpeg binding which can decode video (and audio, I think). One proposal we got is to adopt it to torchaudio once they clean up the installation process. @antimora If you want a fast resampling, you can also do |
|
@antimora Thank you for your work. If you have time can you please share the final code using miniaudio for resampling and decoding? Thank you! |
|
file-like object support has been added in #1158 |
|
Thanks @antimora for the fantastic example! |
* Example for combining DDP + RPC Summary: The example includes a simple model consisting of a sparse part and a dense part. The sparse part is an nn.EmbeddingBag stored on a parameter server and the dense part is an nn.Linear module residing on the trainers. The dense part on the trainers are replicated via DistributedDataParallel. A master creates the nn.EmbeddingBag and drives the training loop on the trainers. The training loop performs an embedding lookup via the Distributed RPC Framework and then executes the local dense component. Test Plan: Reviewers: Subscribers: Tasks: Tags: * Address review comments. Summary: Test Plan: Reviewers: Subscribers: Tasks: Tags: * Address more comments. Summary: Test Plan: Reviewers: Subscribers: Tasks: Tags: Co-authored-by: pritam <[email protected]>
🚀 Feature
The load API does not support loading audio bytes from the memory. It would a great addition to be able to load file like object, e.g. BytesIO. This is would be similar to SoundFile's read function (https://github.com/bastibe/SoundFile/blob/master/soundfile.py#L170)
Motivation
This addition will support a use case for reading audio as blobs directly from DB instead writing the files locally first.
Pitch
Without this feature, torchaudio.load is not useful for users who load files from DB and would love to use torchaudio for all audio operations.
Alternatives
SoundFile supports loading from bytes but currently does not support MP3 files. CommonVoice's audio files are saved in MP3, which requires to convert to FLAC or WAV before training.
The text was updated successfully, but these errors were encountered: