Implement vertical query merging and compaction #90
Comments
|
This should be relatively straightforward from what I can see. For us, BlockReader is an interface and we need to make sure the overlapping blocks turnout to be a single block of that interface. What we essentially want is I hope clear from the following pictures: Now if the same series exists in overlapping blocks, we want to merge the data, but if there exists samples with the same time-stamp but different values, we just drop the "second" (arbitrarily choose one) one. This is okay as it violates the TSDB invariants. PS: This might take some extra memory, but that is okay given how we don't want to recommend this. |
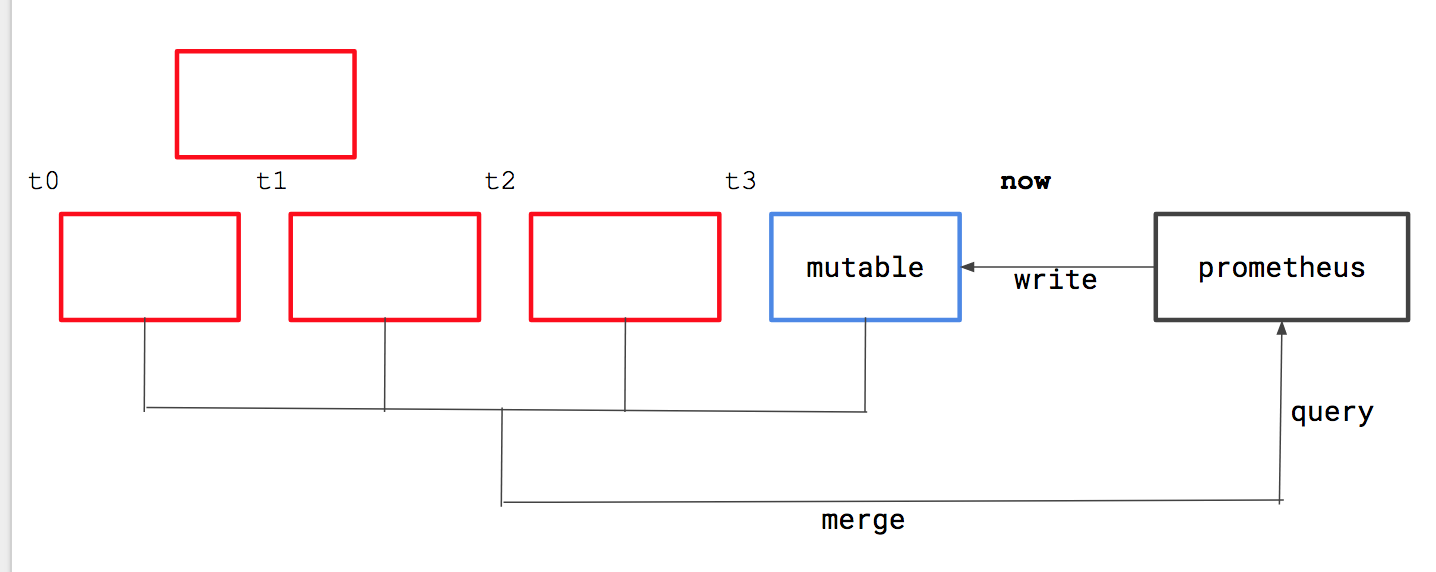
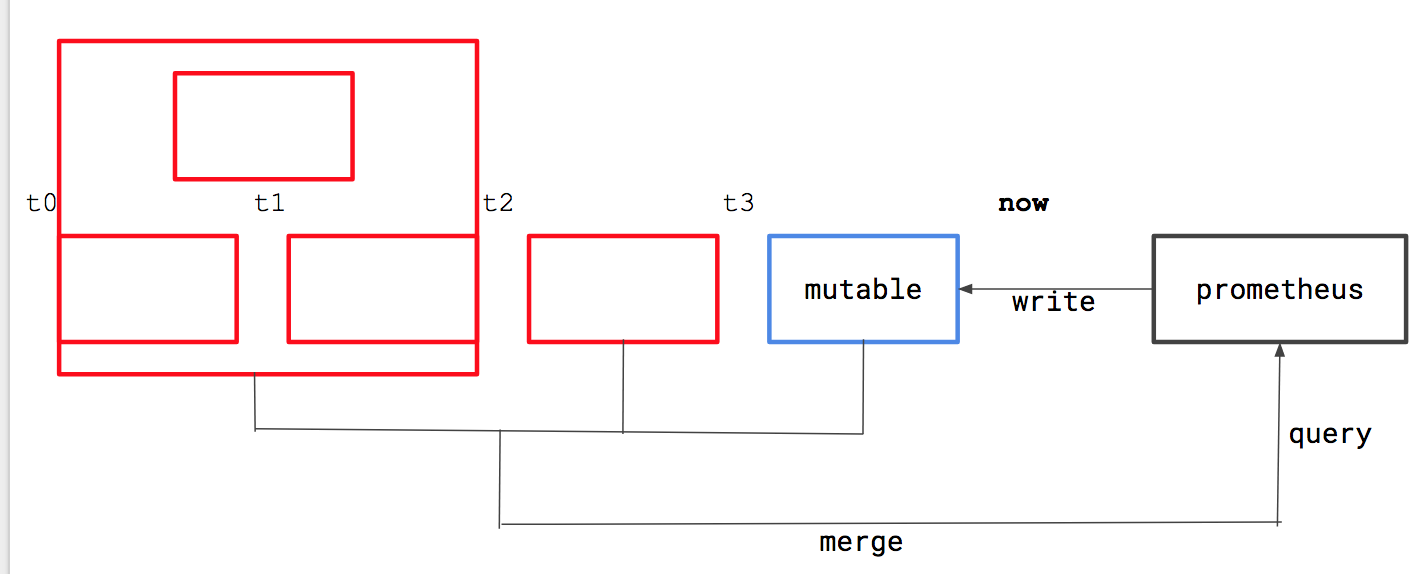
|
From IRC, @brian-brazil on the semantics:
We can do the same thing mentioned above, but, we delete the data that is overlapping in the existing blocks in promtool when inserting data using promtool. Little more work, but we can start with the proposal above, and then when integrating with promtool, implement the deletes. |
|
I can see on IRC that the main question about this issues is "why we need that", can we enumerate the use cases, before starting to designing this? For me this issues is also about the assumptions taken by compaction. Basically, I would love to have compactor be resilient on eventual storage write-read consistency. Why? Because so far it (lack of support for it) produced major release issue for 2.2.0 as well as major compaction issues on Thanos a month ago. Basically:
Making compactor aware that overlaping block is a think will basically reduce damage radius if any of these bugs happen again. @gouthamve can you explain more, how bulk insert can result in overlapping (same) data? (I think I am missing the context on how bulk insert is exactly planned to be done) I would also keep in mind that TSDB is a library and while mainly used for Prometheus, other use it as well. For Thanos this feature would be extremely valuable, because:
So yea. It is needed for Thanos for sure, any other use cases? Issue was created Jan 2017, so @fabxc had some certain use cases in mind for sure (: |
|
I can work on this once we define the why/what/how |
|
just watched @gouthamve's video that add's another use case - back-filling |
|
I'd think in general handling this at query time first will be by far
sufficient. Compaction adds lots of attack surface for data loss and
regressions and we don't have a use case where we'd be dealing with high
fragmentation.
…On Wed, May 16, 2018 at 11:06 AM Krasi Georgiev ***@***.***> wrote:
just watched @gouthamve <https://github.com/gouthamve>'s video that add
add another use case - back-filling
https://youtu.be/0UvKEHFNu4Q?t=1219
—
You are receiving this because you were mentioned.
Reply to this email directly, view it on GitHub
<#90 (comment)>, or mute
the thread
<https://github.com/notifications/unsubscribe-auth/AEuA8jXC3lXg4KLxzPEx8J4sNEA6uFKhks5ty-wygaJpZM4NxdgD>
.
|
|
Yea, but we need to make sure compaction does not add regression when you put overlapping blocks. Currently, with overlap check we added, we just block the compaction flow. It is not safe to just unblock compaction in the current form in case of overlapping blocks |
|
Any ideas for this? It is blocking: thanos-io/thanos#348 |
|
I would like to work on this, will come up with ideas for this soon. |
|
great, I will find time to review it.
don't forget to sync with @gouthamve and @fabxc tsdb gurus for the best design approach 😜 |
|
@fabxc @gouthamve |
|
Again, IMO vertical compaction is must-have. (: For bulk import if you want bulk import further in past, but also more resilient compaction overall. Plus thanos-io/thanos#348 |
We should add support to query and compact time-overlapping blocks. Probably no need for sophisticated handling of overlapping chunks.
This is a rather complex one and we have to discuss specifics. But once done, it makes our life for restoring from backups etc. a lot easier.
The text was updated successfully, but these errors were encountered: