SchedulerExplained
Scheduler explained table of contents
- Block - a customizable worker unit that processes data and produces output
- Topology - a collection of blocks and connections that perform useful work
- Actor - a concurrency computational primitive from the Actor model
- Thread - an independent scheduling of execution (Computing thread)
- Affinity - an association with a set of processors (Processor affinity)
- Thread Pool - a group of threads that execute processing on the actors
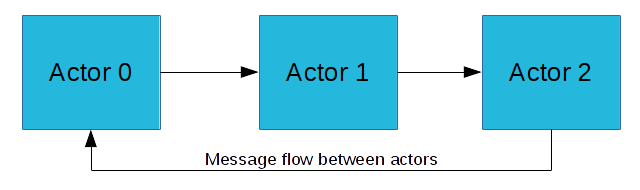
The Actor model is the conceptual basis for concurrent computation in the Pothos scheduler. Every processing block fundamentally behaves as an actor in the system. The actor model gives us a design methodology and concurrency model to make assumptions that guarantee thread-safety and parallelism.
- All blocks are independent entities and may operate concurrently.
- Each block has an internal state with protected sequential access.
- Each block has the ability to send and receive messages to other blocks.
A block is called to perform work only when there is a stimulus event. A stimulus event can be a resource becoming available to an input or output port, an external function call being made on the block, or a self-stimulus from a prior work event producing or consuming resources. A particular block's work implementation decides if the available resources are acceptable to perform useful computation. If not the block can simply exit the work routine, and remain inactive until the next stimulus occurs. These simple event-driven rules combined with the feedback mechanism from the block result in the all of the complexity of interactions occuring within the topology.
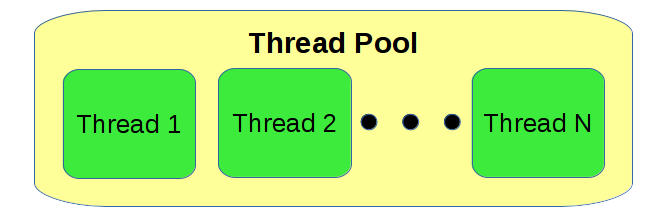
Thread pools are groups of threads that execute useful work among a set of blocks. Thread pools are highly configurable and different thread pools can be associated with different sets of blocks. This allows users to carefully configure and partition processing resources.
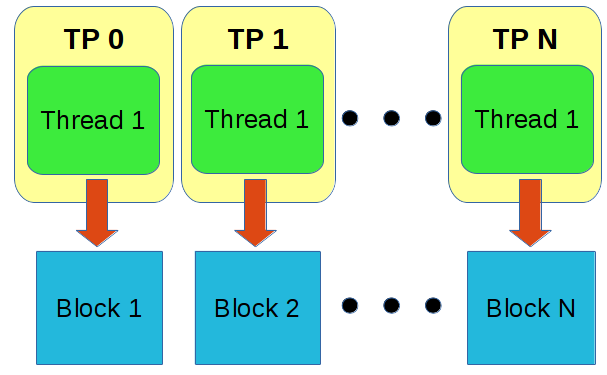
By default, every block is created with a thread pool of one thread. This model is known as "thread-per-block" and is generally regarded as a safe default with very little side-effects. This is because every block can potentially perform work simultaneously so long as they have input/output resources available. It is up to the operating system to effectively schedule the execution of threads.
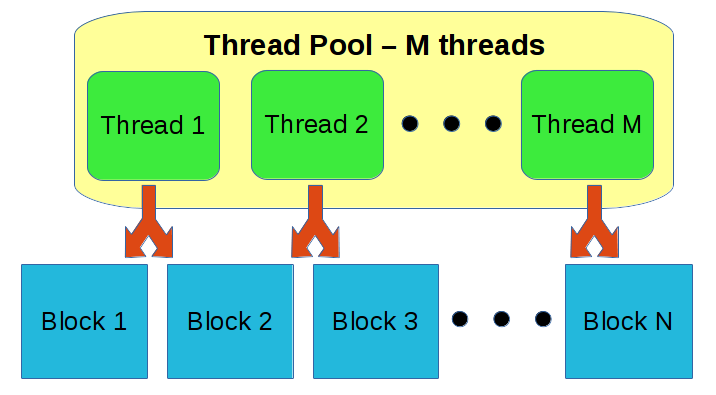
Processors have a finite number of cores, and having more threads than cores does not necessarily equate with additional performance. In-fact, it can hurt performance. Rather than going to sleep and waiting for new resources to become available, a thread can continue to process another block that has available resources. Properly using thread pools can increase throughput and reduce the latency of a design by spending less time overall in thread waits and notifying other threads through system calls.
However, there are possible side-effects. For example, a source block may wait on OS resources such as a network socket using select() or poll(). That thread context is now sleeping in a system call rather that performing useful computational work. If we created a pool with only one thread for each CPU core, then are missing an opportunity for one of those cores to be performing work while the source block waits in a system call.
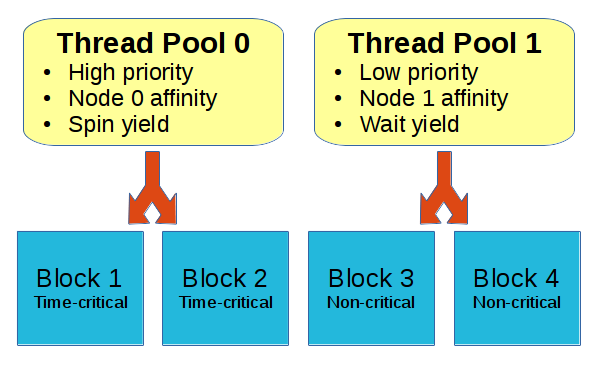
Thread pools are not just configurable in terms of the number of threads: Each thread pool has additional configuration options such as priority, affinity, and scheduling mechanics.
Priority: Increase or decrease the scheduling priority of the threads. This affects how the operating system schedules thread execution. Use increased priority to decrease latency or response time in path-critical blocks. Or use decreased priority to ease the scheduling burden on non-critical blocks.
Affinity: Assign all threads in the pool to a particular set of processors or NUMA nodes. Use this to allocate processing resources, or to more carefully navigate the flow of data across NUMA boundaries.
Yield: This answers the question of what threads should do when no work is available. The yield option modifies the scheduling mechanics by selecting whether to wait on system calls or to spin in userspace until data becomes available. Spinning can reduce latency at the expense of wasting processor cycles and heat.
- See Thread pool args documentation for more information
The flow of data between blocks is implemented on top of message passing. Messages between blocks can be buffers, labels, and arbitrary objects. Although many blocks appear to operate on continuous streaming data, this continuous stream is actually composed of discrete message buffers.
Every input and output port has multiple queues, once for each type of data like buffers, labels, slots, and arbitrary messages. Each queue is protected by its own spin lock which allows for very fast and efficient exchange of data without the need to make system calls into the OS. The assumption is that the chance for contention is small for any individual queue.
The queues are fundamentally non-blocking, and will expand in capacity if need-be. What happens when a down-stream block consumes slower than an upstream producer? There would be an infinite growth in queue size and the system's memory would be entirely consumed.
This is obviously not an acceptable strategy in a real-time data flow system. Fortunately, all flows have a back-pressure mechanism based on finite resources. Specifically, every output port has a fixed-size pool of buffers, and a fixed-size pool of message tokens. When a block depletes an output resource, it will no-longer get called to perform work until that resource replenishes. These resources automatically replenish when upstream consumers release all references to the resource.
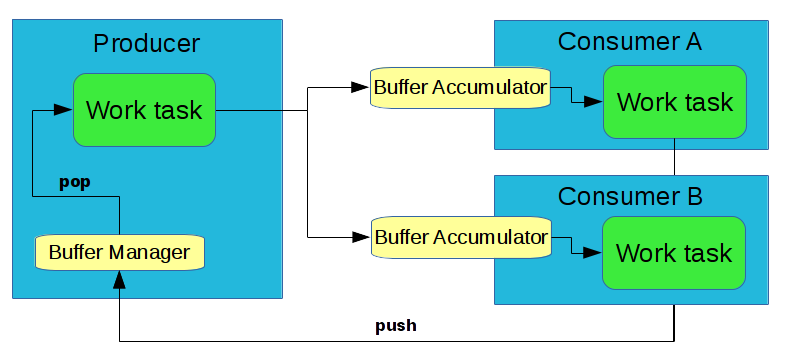
Flexible buffer management is one of the highlights of Pothos. The goal of buffer management is to make the best use of memory possible, to avoid copying, to integrate with DMA devices, and to be generally flexible with memory.
DMA device drivers: Many hardware device drivers allocate their own memory. Pothos provides API hooks to effectively integrate the memory provided by the driver to avoid copying and to directly use that memory in upstream and downstream blocks.
Non-mutating/forwarding blocks: There are a class of processing blocks whose ancillary task is passive because it does not involve muting memory. Consider a block that inspects an input stream and applies a label to the output. Consider a block that routes an input stream to one or more output ports. Consider a block that detects a start of frame in a stream and forwards that chunk of memory as an output message. Pothos allows users to create these kind of blocks efficiently without requiring memory copies.
A buffer manager is a pool of buffers associated with every output port. A buffer manager can present a variety of underlying buffer mechanics, while providing a simple and consistent queue-like interface to the block.
Generic memory slabs: The default manager is simply a pool of several slab-allocated buffers from malloc.
Circularly mapped memory: Doubly-mapped or circularly-mapped memory is a popular optimization to continuously feed blocks that have a rolling input window (example FIR filter). These algorithms would suffer from operating on discontiguous memory. Fortunately, there is a circularly-mapped implementation of the buffer manager specifically for this use-case.
DMA driver provided memory: Devices can provide pools or slabs of driver allocated memory through a custom buffer manager. This buffer manager can be installed into the output port of the DMA source block or the output port of the block upstream to the DMA sink block - which is done automatically by the API hooks.
Examples of projects with custom buffer managers for DMA drivers:
- https://github.com/pothosware/PothosZynq/wiki
- https://github.com/pothosware/PothosOpenCL/wiki
A buffer accumulator is a queue of buffers associated with every input port. The buffer accumulator is not an ordinary queue. It handles reassembly of contiguous chunks of memory, and deals with the memory wrap-around from the circular buffer.
The goal is to provide the biggest contiguous memory regions possible for the consumer. For example, if two buffer arrive into the queue and the second buffer starts where the last buffer ends, they are logically part of a larger contiguous piece of available memory. The buffer accumulator will store a single larger buffer to present to the block.