- About
- Prerequisites for running
- Prerequisites for dev
- Prerequisites for huggingface model quantization
- Installing using pipx
- Installing from mypi using pip
- Installing for dev mode
- Command line arguments
- Environment Variables
- Running PAR_LLAMA
- Running against a remote instance
- Running under Windows WSL
- Quick start chat workflow
- Custom Prompts
- Themes
- Screen Help
- Contributing
- FAQ
- Roadmap
- What's new



PAR LLAMA is a TUI application designed for easy management and use of Ollama based LLMs. The application was built with Textual and Rich and runs on all major OS's including but not limited to Windows, Windows WSL, Mac, and Linux.

Supports Dark and Light mode as well as custom themes.
- Install and run Ollama
- Install Python 3.11 or newer
- https://www.python.org/downloads/ has installers for all versions of Python for all os's
- On Windows the Scoop tool makes it easy to install and manage things like python
- Install Scoop then do
scoop install python
- Install Scoop then do
- Install uv
- See the Using uv section
- Install GNU Compatible Make command
- On windows if you have scoop installed you can install make with
scoop install make
- On windows if you have scoop installed you can install make with
If you want to be able to quantize custom models from huggingface, download the following tool from the releases area: HuggingFaceModelDownloader
Install Docker Desktop
Pull the docker image ollama/quantize
docker pull ollama/quantizeIf you don't have uv installed you can run the following:
curl -LsSf https://astral.sh/uv/install.sh | shuv tool install parllamaTo upgrade an existing uv installation use the -U --force flags:
uv tool install parllama -U --forceuvx parllamauv tool install git+https://github.com/paulrobello/parllamaTo upgrade an existing installation use the --force flag:
uv tool install git+https://github.com/paulrobello/parllama -U --forceIf you don't have pipx installed you can run the following:
pip install pipx
pipx ensurepathpipx install parllamaTo upgrade an existing pipx installation use the --force flag:
pipx install parllama --forcepipx install git+https://github.com/paulrobello/parllamaTo upgrade an existing installation use the --force flag:
pipx install git+https://github.com/paulrobello/parllama --forceClone the repo and run the setup make target. Note uv is required for this.
git clone https://github.com/paulrobello/parllama
cd parllama
make setupusage: parllama [-h] [-v] [-d DATA_DIR] [-u OLLAMA_URL] [-t THEME_NAME] [-m {dark,light}]
[-s {local,site,chat,prompts,tools,create,options,logs}] [--use-last-tab-on-startup {0,1}] [-p PS_POLL] [-a {0,1}]
[--restore-defaults] [--purge-cache] [--purge-chats] [--purge-prompts] [--no-save] [--no-chat-save]
PAR LLAMA -- Ollama TUI.
options:
-h, --help show this help message and exit
-v, --version Show version information.
-d DATA_DIR, --data-dir DATA_DIR
Data Directory. Defaults to ~/.parllama
-u OLLAMA_URL, --ollama-url OLLAMA_URL
URL of your Ollama instance. Defaults to http://localhost:11434
-t THEME_NAME, --theme-name THEME_NAME
Theme name. Defaults to par
-m {dark,light}, --theme-mode {dark,light}
Dark / Light mode. Defaults to dark
-s {local,site,chat,prompts,tools,create,options,logs}, --starting-tab {local,site,chat,prompts,tools,create,options,logs}
Starting tab. Defaults to local
--use-last-tab-on-startup {0,1}
Use last tab on startup. Defaults to 1
-p PS_POLL, --ps-poll PS_POLL
Interval in seconds to poll ollama ps command. 0 = disable. Defaults to 3
-a {0,1}, --auto-name-session {0,1}
Auto name session using LLM. Defaults to 0
--restore-defaults Restore default settings and theme
--purge-cache Purge cached data
--purge-chats Purge all chat history
--purge-prompts Purge all custom prompts
--no-save Prevent saving settings for this session
--no-chat-save Prevent saving chats for this session
Unless you specify "--no-save" most flags such as -u, -t, -m, -s are sticky and will be used next time you start PAR_LLAMA.
- PARLLAMA_DATA_DIR/.env
- HOST Environment
- ParLlama Options Screen
- PARLLAMA_DATA_DIR - Used to set --data-dir
- PARLLAMA_THEME_NAME - Used to set --theme-name
- PARLLAMA_THEME_MODE - Used to set --theme-mode
- OLLAMA_URL - Used to set --ollama-url
- PARLLAMA_AUTO_NAME_SESSION - Set to 0 or 1 to disable / enable session auto naming using LLM
From anywhere:
parllamaFrom parent folder of venv
source venv/Scripts/activate
parllamaparllama -u "http://REMOTE_HOST:11434"Ollama by default only listens to localhost for connections, so you must set the environment variable OLLAMA_HOST=0.0.0.0:11434
to make it listen on all interfaces.
Note: this will allow connections to your Ollama server from other devices on any network you are connected to.
If you have Ollama installed via the native Windows installer you must set OLLAMA_HOST=0.0.0.0:11434 in the "System Variable" section
of the "Environment Variables" control panel.
If you installed Ollama under WSL, setting the var with export OLLAMA_HOST=0.0.0.0:11434 before starting the Ollama server will have it listen on all interfaces.
If your Ollama server is already running, stop and start it to ensure it picks up the new environment variable.
You can validate what interfaces the Ollama server is listening on by looking at the server.log file in the Ollama config folder.
You should see as one of the first few lines "OLLAMA_HOST:http://0.0.0.0:11434"
Now that the server is listening on all interfaces you must instruct PAR_LLAMA to use a custom Ollama connection url with the "-u" flag.
The command will look something like this:
parllama -u "http://$(hostname).local:11434"Depending on your DNS setup if the above does not work, try this:
parllama -u "http://$(grep -m 1 nameserver /etc/resolv.conf | awk '{print $2}'):11434"PAR_LLAMA will remember the -u flag so subsequent runs will not require that you specify it.
From repo root:
make dev- Start parllama.
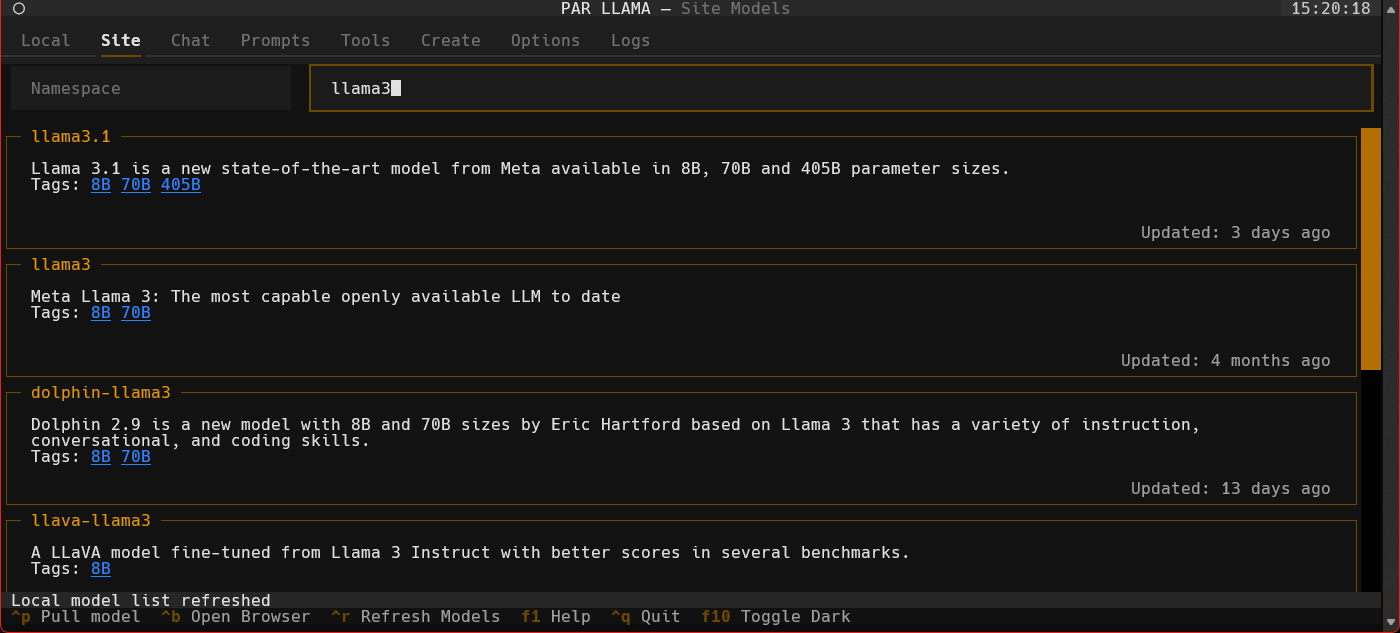
- Click the "Site" tab.
- Use ^R to fetch the latest models from Ollama.com.
- Use the "Filter Site models" text box and type "llama3".
- Find the entry with title of "llama3".
- Click the blue tag "8B" to update the search box to read "llama3:8b".
- Press ^P to pull the model from Ollama to your local machine. Depending on the size of the model and your internet connection this can take a few min.
- Click the "Local" tab to see models that have been locally downloaded.
- Select the "llama3:8b" entry and press ^C to jump to the "Chat" tab and auto select the model.
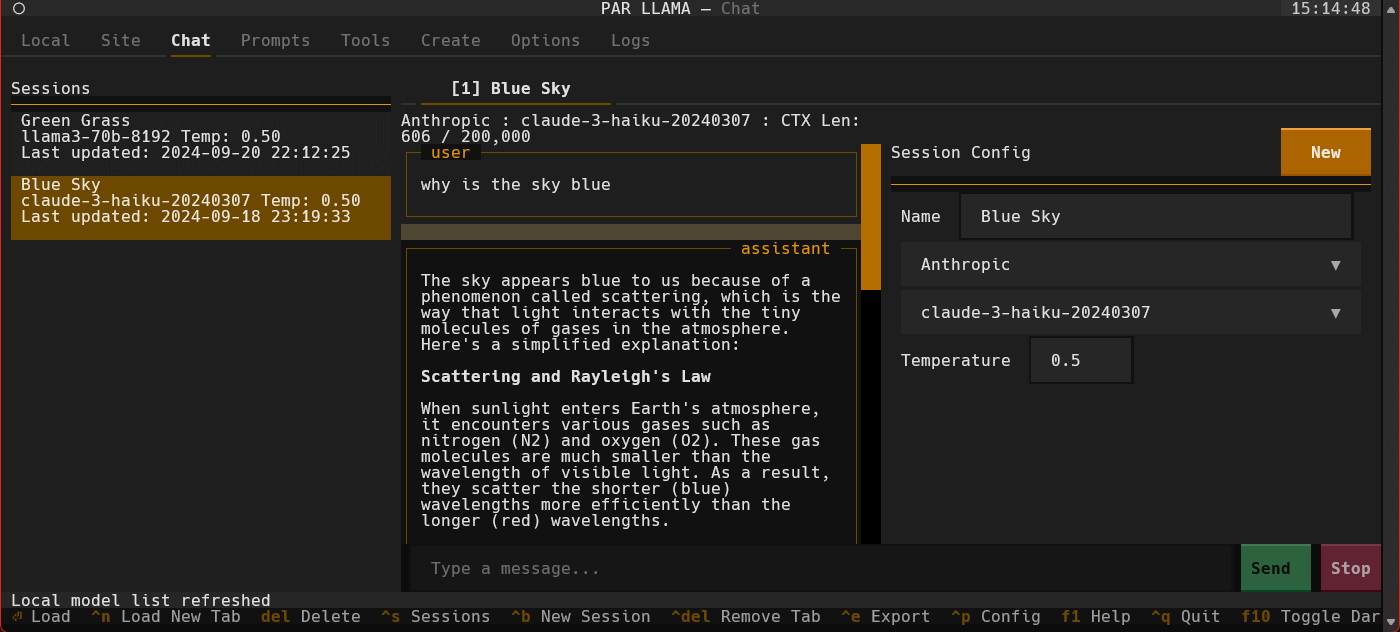
- Type a message to the model such as "Why is the sky blue?". It will take a few seconds for Ollama to load the model. After which the LLMs answer will stream in.
- Towards the very top of the app you will see what model is loaded and what percent of it is loaded into the GPU / CPU. If a model cant be loaded 100% on the GPU it will run slower.
- To export your conversation as a Markdown file type "/session.export" in the message input box. This will open a export dialog.
- Press ^N to add a new chat tab.
- Select a different model or change the temperature and ask the same questions.
- Jump between the tabs to compare responses by click the tabs or using slash commands
/tab.1and/tab.2 - Press ^S to see all your past and current sessions. You can recall any past session by selecting it and pressing Enter or ^N if you want to load it into a new tab.
- Press ^P to see / change your sessions config options such as provider, model, temperature, etc.
- Type "/help" or "/?" to see what other slash commands are available.
- Start parllama.
- Click the "Site" tab.
- Use ^R to fetch the latest models from Ollama.com.
- Use the "Filter Site models" text box and type "llava-llama3".
- Find the entry with title of "llava-llama3".
- Click the blue tag "8B" to update the search box to read "llava-llama3:8b".
- Press ^P to pull the model from Ollama to your local machine. Depending on the size of the model and your internet connection this can take a few min.
- Click the "Local" tab to see models that have been locally downloaded. If the download is complete and it isn't showing up here you may need to refresh the list with ^R.
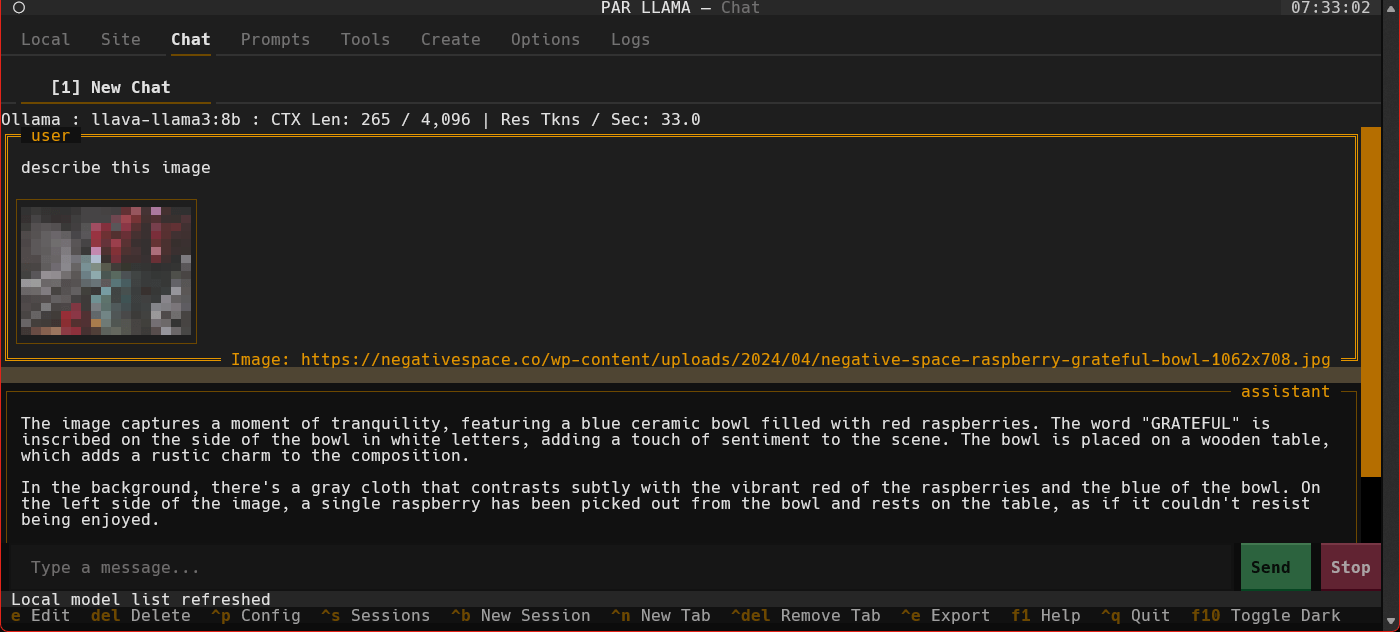
- Select the "llava-llama3" entry and press ^C to jump to the "Chat" tab and auto select the model.
- Use a slash command to add an image and a prompt "/add.image PATH_TO_IMAGE describe whats happening in this image". It will take a few seconds for Ollama to load the model. After which the LLMs answer will stream in.
- Towards the very top of the app you will see what model is loaded and what percent of it is loaded into the GPU / CPU. If a model cant be loaded 100% on the GPU it will run slower.
- Type "/help" or "/?" to see what other slash commands are available.
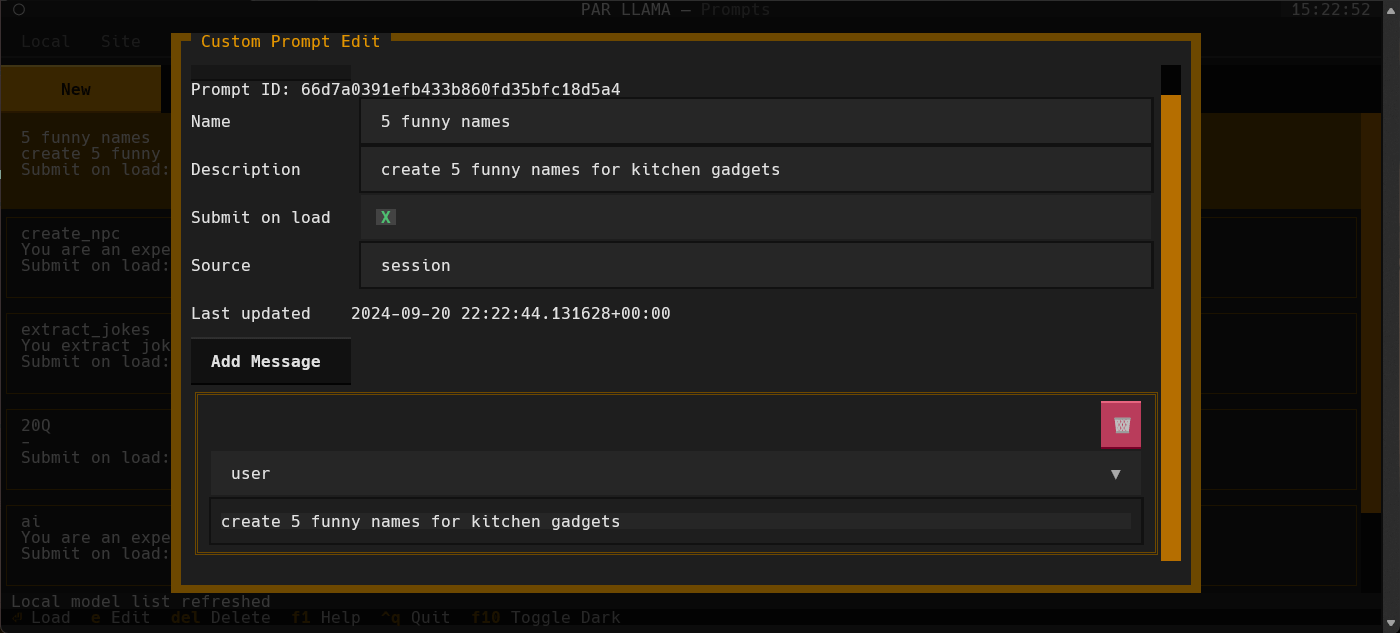
You can create a library of custom prompts for easy starting of new chats.
You can set up system prompts and user messages to prime conversations with the option of sending immediately to the LLM upon loading of the prompt.
Currently, importing prompts from the popular Fabric project is supported with more on the way.
Themes are json files stored in the themes folder in the data directory which defaults to ~/.parllama/themes
The default theme is "par" so can be located in ~/.parllama/themes/par.json
Themes have a dark and light mode are in the following format:
{
"dark": {
"primary": "#e49500",
"secondary": "#6e4800",
"warning": "#ffa62b",
"error": "#ba3c5b",
"success": "#4EBF71",
"accent": "#6e4800",
"panel": "#111",
"surface":"#1e1e1e",
"background":"#121212",
"dark": true
},
"light": {
"primary": "#004578",
"secondary": "#ffa62b",
"warning": "#ffa62b",
"error": "#ba3c5b",
"success": "#4EBF71",
"accent": "#0178D4",
"background":"#efefef",
"surface":"#f5f5f5",
"dark": false
}
}You must specify at least one of light or dark for the theme to be usable.
Theme can be changed via command line with the --theme-name option.
Start by following the instructions in the section Installing for dev mode.
Please ensure that all pull requests are formatted with black, pass mypy and pylint with 10/10 checks.
You can run the make target pre-commit to ensure the pipeline will pass with your changes.
There is also a pre-commit config to that will assist with formatting and checks.
The easiest way to setup your environment to ensure smooth pull requests is:
With uv installed:
uv tool install pre-commitWith pipx installed:
pipx install pre-commitFrom repo root run the following:
pre-commit install
pre-commit run --all-filesAfter running the above all future commits will auto run pre-commit. pre-commit will fix what it can and show what if anything remains to be fixed before the commit is allowed.
- Q: Do I need Docker?
- A: Docker is only required if you want to Quantize models downloaded from Huggingface or similar llm repositories.
- Q: Does ParLlama require internet access?
- A: ParLlama by default does not require any network / internet access unless you enable checking for updates or want to import / use data from an online source.
- Q: Does ParLlama run on ARM?
- A: Short answer is yes. ParLlama should run any place python does. It has been tested on Windows 11 x64, Windows WSL x64, Mac OSX intel and silicon
- Q: Does Parllama require Ollama be installed locally?
- A: No. ParLlama has options to connect to remote Ollama instances
- Initial release - Find, maintain and create new models
- Connect to remote instances
- Chat with history / conversation management
- Chat tabs allow chat with multiple models at same time
- Custom prompt library with import from Fabric
- Auto complete of slash commands, input history, multi line edit
- Ability to use cloud AI providers like OpenAI, Anthropic, Groq, and Google
- Use images with vision capable LLMs
- RAG for local documents and web pages
- Expand ability to import custom prompts of other tools
- LLM tool use
- Fixed crash issues on fresh installs
- Images are now stored in chat session json files
- Added API key checks for online providers
- Image support for models that support them using /add.image slash command. See the Quick start image chat workflow
- Add history support for both single and multi line input modes
- Fixed crash on models that dont have a license
- Fixed last model used not get used with new sessions
- Major rework of core to support providers other than Ollama
- Added support for the following online providers: OpenAI, Anthropic, Groq, Google
- New session config panel docked to right side of chat tab (more settings coming soon)
- Better counting of tokens (still not always 100% accurate)
- Fix for possible crash when there is more than one model loaded into ollama
- Added option to save chat input history and set its length
- Fixed tab switch issue on startup
- Added cache for Fabric import to speed up subsequent imports
- Added first time launch welcome
- Added Options tab which exposes more options than are available via command line switches
- Added option to auto check for new versions
- Added ability to import custom prompts from fabric
- Added toggle between single and multi line input (Note auto complete and command history features not available in multi line edit mode)
- Added custom prompt library support (Work in progress)
- Added cli option and environment var to enable auto naming of sessions using LLM (Work in progress)
- Added tokens per second stats to session info line on chat tab
- Fixed app crash when it cant contact ollama server for PS info
- Fixed slow startup when you have a lot of models available locally
- Fixed slow startup and reduced memory utilization when you have many / large chats
- Fixed session unique naming bug where it would always add a "1" to the session name
- Fixed app sometimes slowing down during LLM generation
- Major rework of internal message handling
- Issue where some footer items are not clickable has been resolved by a library PARLLAMA depends on
- Added ability to edit existing messages. select message in chat list and press "e" to edit, then "escape" to exit edit mode
- Add chat input history access via up / down arrow while chat message input has focus
- Added /session.system_prompt command to set system prompt in current chat tab
- Ollama ps stats bar now works with remote connections except for CPU / GPU %'s which ollama's api does not provide
- Chat tabs now have a session info bar with info like current / max context length
- Added conversation stop button to abort llm response
- Added ability to delete messages from session
- More model details displayed on model detail screen
- Better performance when changing session params on chat tab
- Add chat tabs to support multiple sessions
- Added cli option to prevent saving chat history to disk
- Renamed / namespaced chat slash commands for better consistency and grouping
- Fixed application crash when ollama binary not found
- Added chat history panel and management to chat page
- Fix missing dependency in package
- Added slash commands to chat input
- Added ability to export chat to markdown file
- ctrl+c on local model list will jump to chat tab and select currently selected local model
- ctrl+c on chat tab will copy selected chat message