


![]()
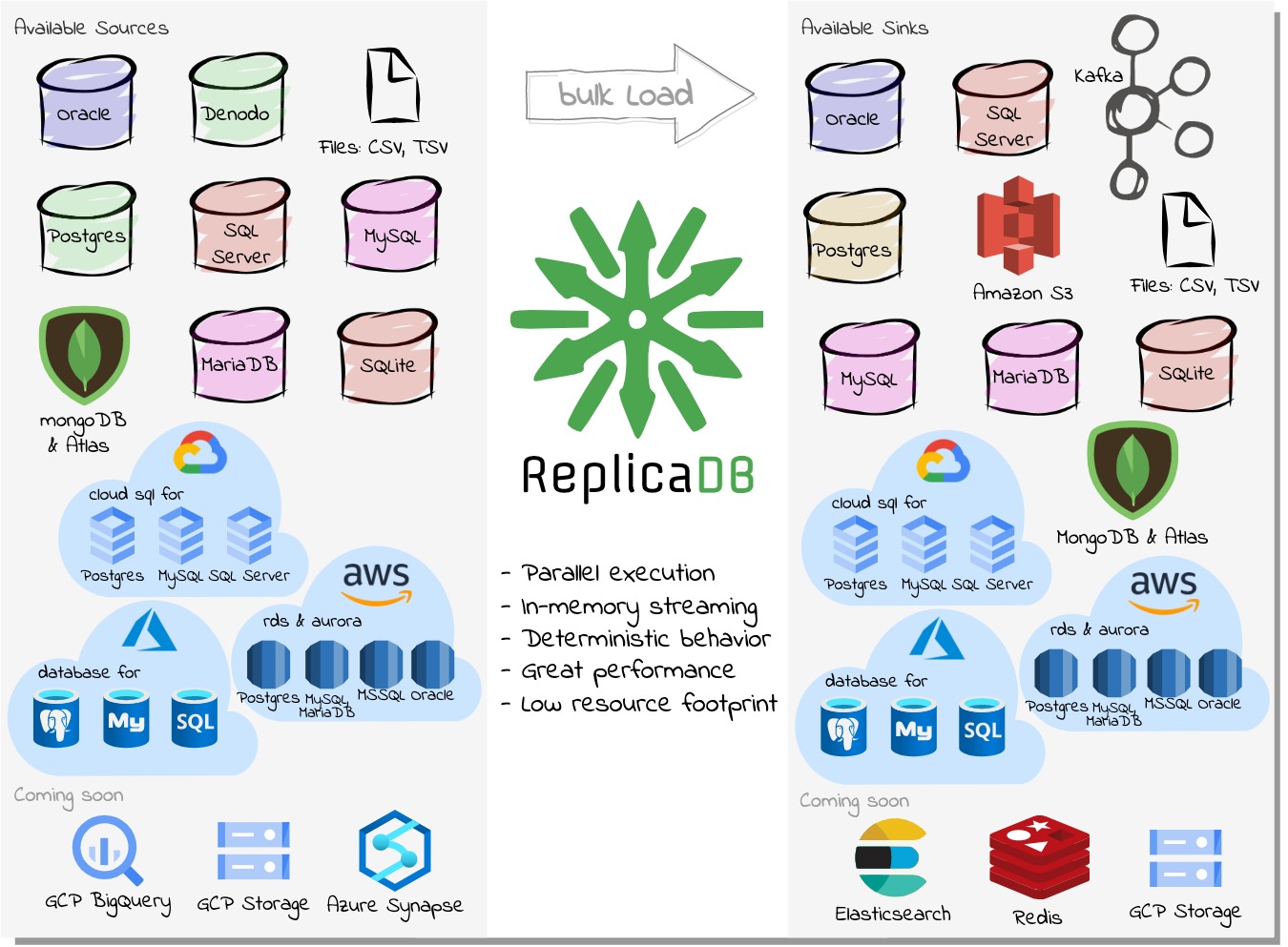
ReplicaDB is an open source tool for database replication designed for efficiently transferring bulk data between relational and NoSQL databases.
ReplicaDB helps offload certain tasks, such as ETL or ELT processing, for efficient execution at a much lower cost. ReplicaDB currently works with Oracle, Postgres, SQL Server, MySQL and MariaDB, SQLite, MongoDB, Denodo, CSV on local files or Amazon S3 and Kafka. Any other JDBC database is also supported with limitations.
ReplicaDB is Cross Platform; you can replicate data across different platforms (Windows, Linux, MacOS), with compatibility for many databases. You can use Parallel data transfer for faster performance and optimal system utilization.
Because I have not found any tool that covers my needs:
- Open Source.
- Java based cross-platform solution, compatible with Linux, Windows, and MacOS.
- Any database engine SQL, NoSQL, or other persistent stores like CSV, Amazon S3, or Kafka.
- Simple architecture, just a command line tool that can run on any server (including my laptop), without any remote agents in the databases.
- Good performance for a large amount of data.
- I do not need streaming replication or a pure change data capture (CDC) system that requires installation in the source database.
I have reviewed and tested other open source tools and none of them meets all the above requirements:
- SymetricDS: It was the best option of all, but I was looking for a smaller solution, mainly focused on performance. SymmetricDS is intrusive since installs database triggers that capture data changes in a data capture table. This table requires maintenance. SymmetricDS is more like a CDC system based on triggers.
- Sqoop: Sqoop is what I was looking for, but oh! it is only valid for Hadoop.
- Pentaho and Talend: Both are very complete ETL tools, but for each of the different source and sink tables that I have to replicate, I should do a custom development
ReplicaDB is written in Java and requires a Java Runtime Environment (JRE) Standard Edition (SE) or Java Development Kit (JDK) Standard Edition (SE) version 8.0 or above. The minimum operating system requirements are:
- Java SE Runtime Environment 8 or above
- Memory - 256 (MB) available
Just download latest release and unzip it.
$ curl -o ReplicaDB-0.15.1.tar.gz -L "https://github.com/osalvador/ReplicaDB/releases/download/v0.15.1/ReplicaDB-0.15.1.tar.gz"
$ tar -xvzf ReplicaDB-0.15.1.tar.gz
$ ./bin/replicadb --helpReplicaDB already comes with all the JDBC drivers for the Compatible Databases. But you can use ReplicaDB with any JDBC-compliant database.
First, download the appropriate JDBC driver for the type of database you want to use, and install the .jar file in the $REPLICADB_HOME/lib directory. Each driver .jar file also has a specific driver class that defines the entry-point to the driver.
If your database is JDBC-compliant and not appear in the Compatible Databases list, you must set the driver class name in the configuration properties as extra JDBC parameter.
For example, to replicate a DB2 database table as both source and sink
######################## ReplicadB General Options ########################
mode=complete
jobs=1
############################# Soruce Options ##############################
source.connect=jdbc:db2://localhost:50000/testdb
source.user=${DB2USR}
source.password=${DB2PASS}
source.table=source_table
source.connect.parameter.driver=com.ibm.db2.jcc.DB2Driver
############################# Sink Options ################################
sink.connect=jdbc:db2://localhost:50000/testdb
sink.user=${DB2USR}
sink.password=${DB2PASS}
sink.table=sink_table
sink.connect.parameter.driver=com.ibm.db2.jcc.DB2Driver$ docker run \
-v /tmp/replicadb.conf:/home/replicadb/conf/replicadb.conf \
osalvador/replicadbVisit the project homepage on Docker Hub for more information.
Based on Red Hat UBI 9
$ podman run \
-v /tmp/replicadb.conf:/home/replicadb/conf/replicadb.conf:Z \
osalvador/replicadb:ubi9-latestYou can find the full ReplicaDB documentation here: Docs
You can create a configuration file for a ReplicaDB process by filling out a simple form: ReplicaDB configuration wizard
Source and Sink tables must exist.
$ replicadb --mode=complete -j=1 \
--source-connect=jdbc:oracle:thin:@${ORAHOST}:${ORAPORT}:${ORASID} \
--source-user=${ORAUSER} \
--source-password=${ORAPASS} \
--source-table=dept \
--sink-connect=jdbc:postgresql://${PGHOST}/osalvador \
--sink-table=dept
2018-12-07 16:01:23,808 INFO ReplicaTask:36: Starting TaskId-0
2018-12-07 16:01:24,650 INFO SqlManager:197: TaskId-0: Executing SQL statement: SELECT /*+ NO_INDEX(dept)*/ * FROM dept where ora_hash(rowid,0) = ?
2018-12-07 16:01:24,650 INFO SqlManager:204: TaskId-0: With args: 0,
2018-12-07 16:01:24,772 INFO ReplicaDB:89: Total process time: 1302msInstead, you can use a configuration file, replicadb.conf:
######################## ReplicadB General Options ########################
mode=complete
jobs=1
############################# Soruce Options ##############################
source.connect=jdbc:oracle:thin:@${ORAHOST}:${ORAPORT}:${ORASID}
source.user=${ORAUSER}
source.password=${ORAPASS}
source.table=dept
############################# Sink Options ################################
sink.connect=jdbc:postgresql://${PGHOST}/osalvador
sink.table=dept$ replicadb --options-file replicadb.conf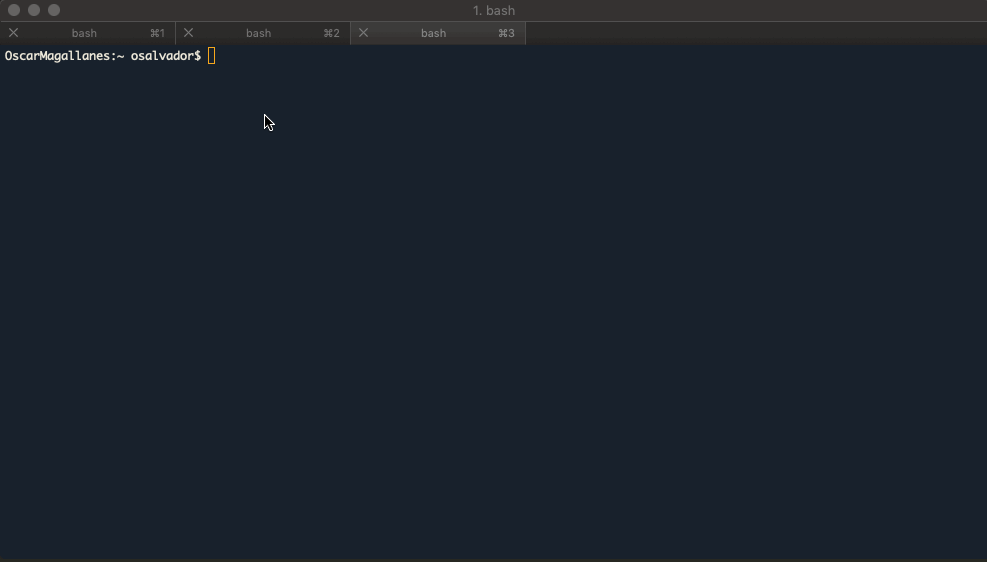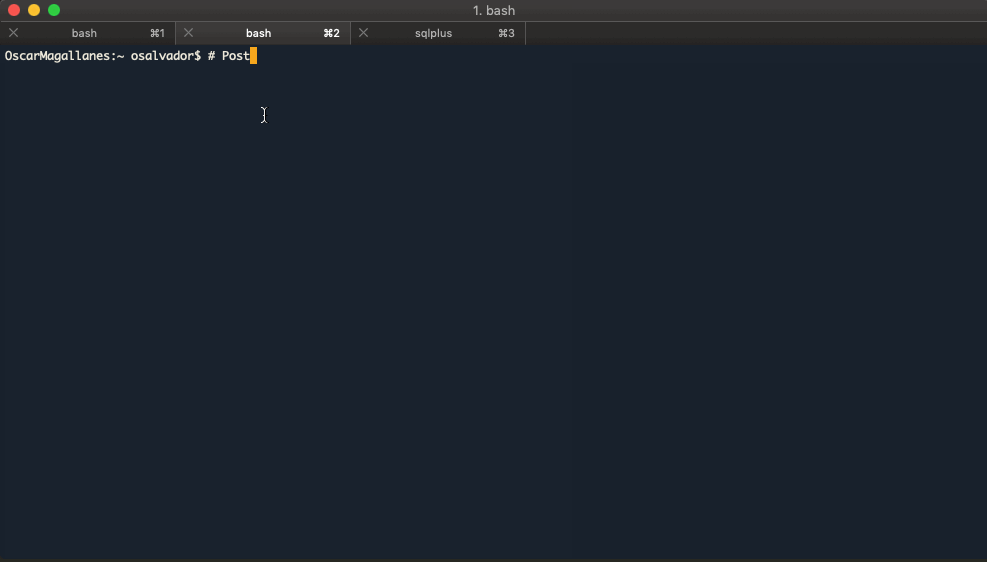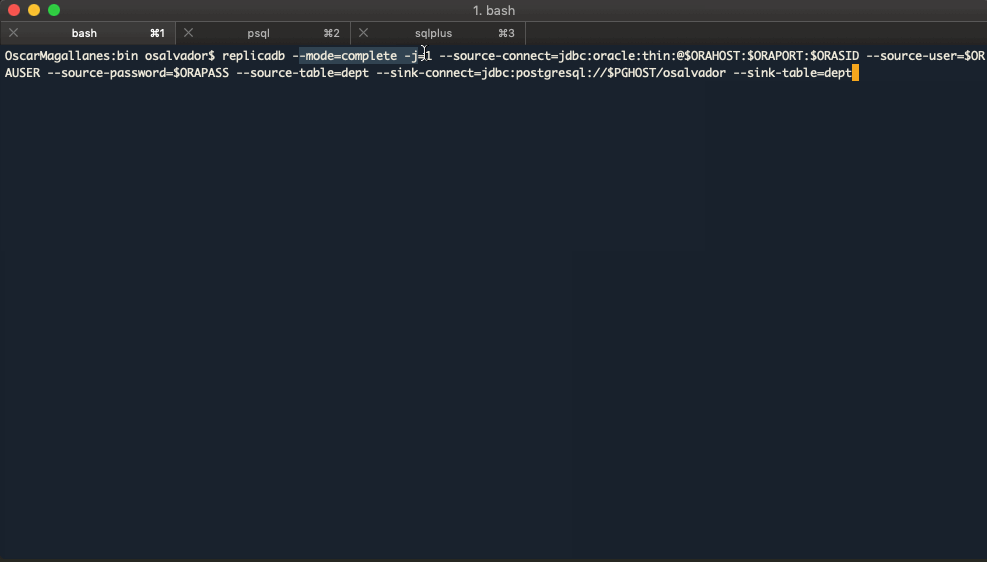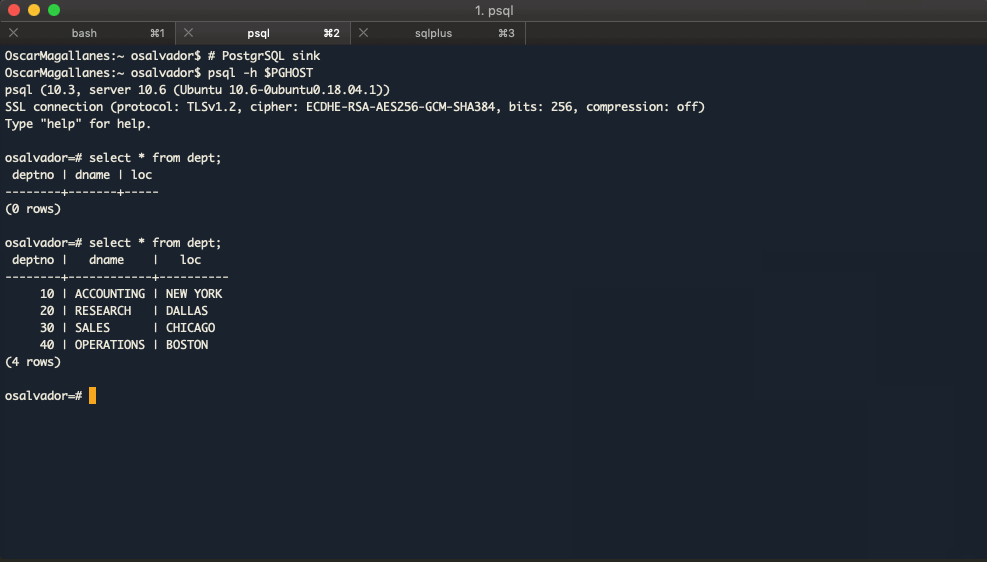
$ replicadb --mode=complete -j=1 \
--sink-connect=jdbc:oracle:thin:@${ORAHOST}:${ORAPORT}:${ORASID} \
--sink-user=${ORAUSER} \
--sink-password=${ORAPASS} \
--sink-table=dept \
--source-connect=jdbc:postgresql://${PGHOST}/osalvador \
--source-table=dept \
--source-columns=dept.*
2018-12-07 16:10:35,334 INFO ReplicaTask:36: Starting TaskId-0
2018-12-07 16:10:35,440 INFO SqlManager:131 TaskId-0: Executing SQL statement: SELECT * FROM dept OFFSET ?
2018-12-07 16:10:35,441 INFO SqlManager:204: TaskId-0: With args: 0,
2018-12-07 16:10:35,550 INFO OracleManager:98 Inserting data with this command: INSERT INTO /*+APPEND_VALUES*/ ....
2018-12-07 16:10:35,552 INFO ReplicaDB:89: Total process time: 1007ms| Persistent Store | Source | Sink Complete | Sink Complete-Atomic | Sink Incremental | Sink Bandwidth Throttling |
|---|---|---|---|---|---|
| Oracle | ✔️ | ✔️ | ✔️ | ✔️ | ✔️ |
| MySQL | ✔️ | ✔️ | ✔️ | ✔️ | ✔️ |
| MariaDB | ✔️ | ✔️ | ✔️ | ✔️ | ✔️ |
| PostgreSQL | ✔️ | ✔️ | ✔️ | ✔️ | ✔️ |
| SQLite | ✔️ | ✔️ | ✖️ | ✔️ | ✔️ |
| SQL Server | ✔️ | ✔️ | ✔️ | ✔️ | ✖️ |
| MongoDB | ✔️ | ✔️ | ✖️ | ✔️ | ✔️ |
| Denodo | ✔️ | N/A | N/A | N/A | N/A |
| CSV | ✔️ | ✔️ | N/A | ✔️ | ✔️ |
| Kafka | ✖️ | N/A | N/A | ✔️ | ✔️ |
| Amazon S3 | ✖️ | ✔️ | N/A | N/A | ✔️ |
| JDBC-Compliant database | ✔️ | ✔️ | ✖️ | ✖️ | ✔️ |
Features:
- Replicate multiple tables in a single run
- Scheduling
- Web interface
- Server mode with API
- Kubernetes compliant
New Databases:
- Elasticsearch
- Redis
- IBM DB2 (full compatibility)
- GCP BigQuery
- Azure Synapse
- Fork it (https://github.com/osalvador/ReplicaDB)
- Create your feature branch (
git checkout -b feature/fooBar) - Commit your changes (
git commit -am 'Add some fooBar') - Push to the branch (
git push origin feature/fooBar) - Create a new Pull Request