StoryWeb is a project aimed to extract networks of entities from journalistic reporting. The idea is to reverse engineer stories into structured graphs of the persons and companies involved, and to capture the relationships between them.
https://storyweb.opensanctions.org
StoryWeb consumes news articles as input data. Individual articles can be imported via the web interface, but there's also a possibility for bulk import using the articledata micro-format. One producer of articledata files is mediacrawl, which can be used to crawl news websites and harvest all of their articles.
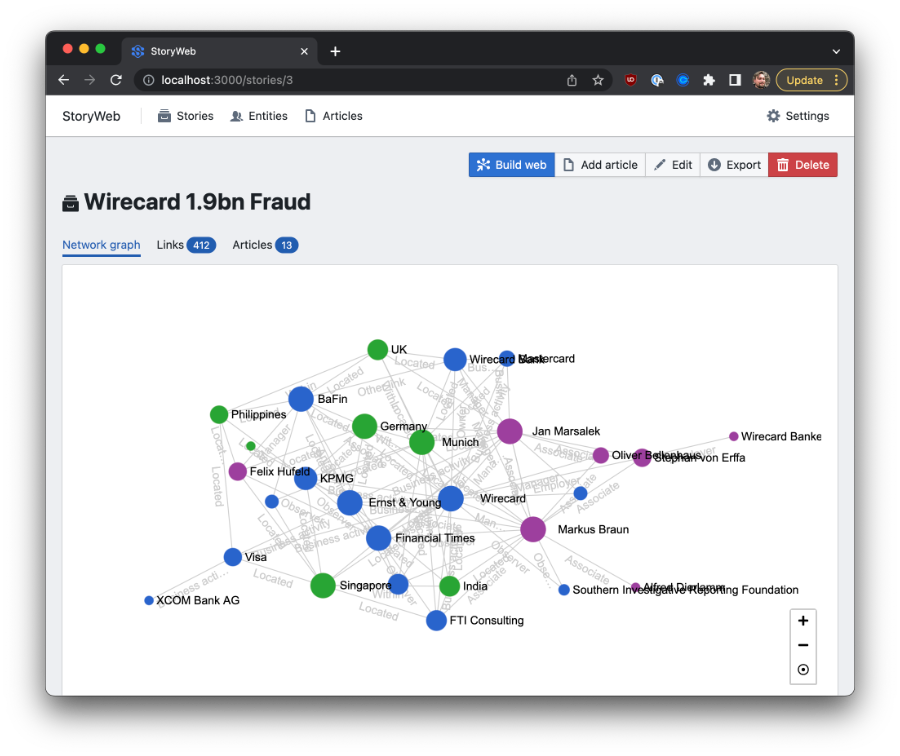
Storyweb can be run as a Python web application from a developer's machine, or via a docker container. We recommend using docker for any production deployment and as a quick means to get the application running if you don't intend to change its code.
You can start up the a docker instance by running the following commands in an empty directory:
wget https://raw.githubusercontent.com/opensanctions/storyweb/main/docker-compose.yml
docker-compose upThis will make the storyweb user interface available on port 8000 of the host machine.
Before installing storyweb on the host machine, we recommend setting up a Python virtual environment of some form (venv, virtualenv, etc.).
As a first step, let's install the spaCy models that are used to extract person and company names from the given articles:
pip install spacy
python3 -m spacy download en_core_web_sm
python3 -m spacy download de_core_news_sm
python3 -m spacy download xx_ent_wiki_sm
python3 -m spacy download ru_core_news_smNext, we'll install the application itself, and its dependencies. Run the following command inside of a git checkout of the storyweb repository:
pip install -e ".[dev]"You also need to have a PostgreSQL server running somewhere (e.g. on the same machine, perhaps installed via homebrew or apt). Create a fresh database on that server and point storyweb to it like this:
export STORYWEB_DB_URL=postgresql://storyweb:storyweb@db/storyweb
# Create the database tables:
storyweb initYou now have the application configured and you can explore the commands exposed by the storyweb command-line tool:
Usage: storyweb [OPTIONS] COMMAND [ARGS]...
Storyweb CLI
Options:
--help Show this message and exit.
Commands:
auto-merge Automatically merge on fingerprints
compute Run backend computations
graph Export an entity graph
import Import articles into the DB
import-url Load a single news story by URL
init Initialize the database
The import command listed here will accept any data file in the articledata format, which is emitted by the mediacrawl tool.
Finally, you can run the backend API using uvicorn:
uvicorn --reload --host 0.0.0.0 storyweb.server:appThis will boot up the API server of port 8000 of the local host and enable hot reloads whenever the code changes during development.
Once you have the API running, you can install and run the development server for the frontend. Storyweb uses React and ReduxToolkit internally and will use a Webpack dev server to dynamically re-build the frontend during development.
cd frontend/
npm install
npm run devRemember that you need to run npm run dev whenever you do frontend development.
Thanks to Heleen Emanuel and Tobias Sterbak for their advice on the design and implementation of StoryWeb.
This project receives financial support from the German Federal Ministry for Education and Research (Bundesministerium für Bildung und Forschung, BMBF) under the grant identifier 01IS22S42. The full responsibility for the content of this publication remains with its authors.
The software is licensed under the MIT license, see LICENSE in this repository.