![]()
Peer-To-Peer Permanence of Web Archives

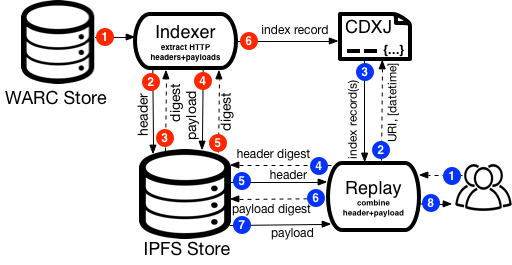
InterPlanetary Wayback (ipwb) facilitates permanence and collaboration in web archives by disseminating the contents of WARC files into the IPFS network. IPFS is a peer-to-peer content-addressable file system that inherently allows deduplication and facilitates opt-in replication. ipwb splits the header and payload of WARC response records before disseminating into IPFS to leverage the deduplication, builds a CDXJ index with references to the IPFS hashes that are returned, and combines the header and payload from IPFS at the time of replay.
InterPlanetary Wayback primarily consists of two scripts:
- ipwb/indexer.py - archival indexing script that takes the path to a WARC input, extracts the HTTP headers, HTTP payload (response body), and relevant parts of the WARC-response record header from the WARC specified and creates byte string representations. The indexer then pushes the byte strings into IPFS using a locally running IPFS daemon then creates a CDXJ file with this metadata for replay.py.
- ipwb/replay.py - rudimentary replay script to resolve requests for archival content contained in IPFS for replay in the browser.
A pictorial representation of the ipwb indexing and replay process:
An important aspect of archival replay systems is rewriting various resource references for proper memento reconstruction so that they are dereferenced properly from the archive from around the same datetime as of the root memento and not from the live site (in which case the resource might have changed or gone missing). Many archival replay systems perform server-side rewriting, but it has its limitations when URIs are generated using JavaScript. To handle this, we use Service Worker for rerouting requests on the client-side when they are dereferenced to avoid any server-side rewiring. For this, we have implemented a separate library, Reconstructive, which is reusable and extendable by any archival replay system.
Another important feature of archival replays is the inclusion of an archival banner in mementos. The purpose of an archival banner is to highlight that a replayed page is a memento and not a live page, to provide metadata about the memento and the archive, and to facilitate additional interactivity. Many archival banners used in different web archival replay systems are obtrusive in nature and have issues like style leakage. To eliminate both of these issues we have implemented a Custom HTML Element, as part of the Reconstructive library and used in the ipwb.
InterPlanetary Wayback (ipwb) requires Python 3.9+. ipwb can also be used with Docker (see below).
For conventional usage, the latest release of ipwb can be installed using pip:
$ pip install ipwb
The latest development version containing changes not yet released can be installed from source:
$ git clone https://github.com/oduwsdl/ipwb
$ cd ipwb
$ pip install ./
The InterPlanetary File System (ipfs) daemon must be installed and running before starting ipwb. See the Install IPFS page to accomplish this. In the future, we hope to make this more automated. Once ipfs is installed, start the daemon:
$ ipfs daemon
If you encounter a conflict with the default API port of 5001 when starting the daemon, running the following prior to launching the daemon will change the API port to access to one of your choosing (here, shown to be 5002):
$ ipfs config Addresses.API /ip4/127.0.0.1/tcp/5002
In a separate terminal session (or the same if you started the daemon in the background), instruct ipwb to push contents of a WARC file into IPFS and create an index of records:
$ ipwb index (path to warc or warc.gz)
...for example, from the root of the ipwb repository:
$ ipwb index samples/warcs/salam-home.warc
The ipwb indexer partitions the WARC into WARC Records and extracts the WARC Response headers, HTTP response headers, and the HTTP response bodies (payloads). Relevant information is extracted from the WARC Response headers, temporary byte strings are created for the HTTP response headers and payload, and these two bytes strings are pushed into IPFS. The resulting CDXJ data is written to STDOUT by default but can be redirected to a file, e.g.,
$ ipwb index (path to warc or warc.gz) >> myArchiveIndex.cdxj
An archival replay system is also included with ipwb to re-experience the content disseminated to IPFS. A CDXJ index needs to be provided and used by the ipwb replay system by specifying the path of the index file as a parameter to the replay system:
$ ipwb replay <path/to/cdxj>
ipwb also supports using an IPFS hash or any HTTP location as the source of the CDXJ:
$ ipwb replay http://myDomain/files/myIndex.cdxj
$ ipwb replay QmYwAPJzv5CZsnANOTaREALhashYgPpHdWEz79ojWnPbdG
Once started, the replay system's web interface can be accessed through a web browser, e.g., http://localhost:2016/ by default.
To run it under a domain name other than localhost, the easiest approach is to use a reverse proxy that supports HTTPS. The replay system utilizes Service Worker for URL rerouting/rewriting to prevent live leakage (zombies). However, for security reason many web browsers have mandated HTTPS for the Service Worker API with only exception if the domain is localhost. Caddy Server and Traefik can be used as a reverse-proxy server and are very easy to setup. They come with built-in HTTPS support and manage (install and update) TLS certificates transparently and automatically from Let's Encrypt. However, any web server proxy that has HTTPS support on the front-end will work. To make ipwb replay aware of the proxy, use --proxy or -P flag to supply the proxy URL. This way the replay will yield the supplied proxy URL as a prefix when generating various fully qualified domain name (FQDN) URIs or absolute URIs (for example, those in the TimeMap or Link header) instead of the default http://localhost:2016. This can be necessary when the service is running in a private network or a container, and only exposed via a reverse-proxy. Suppose a reverse-proxy server is running and ready to forward all traffic on the https://ipwb.example.com to the ipwb replay server then the replay can be started as following:
$ ipwb replay --proxy=https://ipwb.example.com <path/to/cdxj>
A pre-built Docker image is made available that can be run as following:
$ docker container run -it --rm -p 2016:2016 oduwsdl/ipwb
The container will run an IPFS daemon, index a sample WARC file, and replay it using the newly created index. It will take a few seconds to be ready, then the replay will be accessible at http://localhost:2016/ with a sample archived page.
To index and replay your own WARC file, bind mount your data folders inside the container using -v (or --volume) flag and run commands accordingly. The provided docker image has designated /data directory, inside which there are warc, cdxj, and ipfs folders where host folders can be mounted separately or as a single mount point at the parent /data directory. Assuming that the host machine has a /path/to/data folder under which there are warc, cdxj, and ipfs folders and a WARC file at /path/to/data/warc/custom.warc.gz.
$ docker container run -it --rm -v /path/to/data:/data oduwsdl/ipwb ipwb index -o /data/cdxj/custom.cdxj /data/warc/custom.warc.gz
$ docker container run -it --rm -v /path/to/data:/data -p 2016:2016 oduwsdl/ipwb ipwb replay /data/cdxj/custom.cdxj
If the host folder structure is something other than /some/path/{warc,cdxj,ipfs} then these volumes need to be mounted separately.
To build an image from the source, run the following command from the directory where the source code is checked out. The name of the locally built image could be anything, but we use oduwsdl/ipwb to be consistent with the above commands.
$ docker image build -t oduwsdl/ipwb .
By default, the image building process also performs tests, so it might take a while to build the image. It ensures that an image will not be created with failing tests. However, it is possible to skip tests by supplying a build-arg --build-arg SKIPTEST=true as shown below:
$ docker image build --build-arg SKIPTEST=true -t oduwsdl/ipwb .
Usage of sub-commands in ipwb can be accessed through providing the -h or --help flag, like any of the below.
$ ipwb -h
usage: ipwb [-h] [-d DAEMON_ADDRESS] [-v] [-u] {index,replay} ...
InterPlanetary Wayback (ipwb)
optional arguments:
-h, --help show this help message and exit
-d DAEMON_ADDRESS, --daemon DAEMON_ADDRESS
Multi-address of IPFS daemon (default
/dns/localhost/tcp/5001/http)
-v, --version Report the version of ipwb
-u, --update-check Check whether an updated version of ipwb is available
ipwb commands:
Invoke using "ipwb <command>", e.g., ipwb replay <cdxjFile>
{index,replay}
index Index a WARC file for replay in ipwb
replay Start the ipwb replay system
$ ipwb index -h
usage: ipwb [-h] [-e] [-c] [--compressFirst] [-o OUTFILE] [--debug]
index <warc_path> [index <warc_path> ...]
Index a WARC file for replay in ipwb
positional arguments:
index <warc_path> Path to a WARC[.gz] file
optional arguments:
-h, --help show this help message and exit
-e Encrypt WARC content prior to adding to IPFS
-c Compress WARC content prior to adding to IPFS
--compressFirst Compress data before encryption, where applicable
-o OUTFILE, --outfile OUTFILE
Path to an output CDXJ file, defaults to STDOUT
--debug Convenience flag to help with testing and debugging
$ ipwb replay -h
usage: ipwb replay [-h] [-P [<host:port>]] [index]
Start the ipwb relay system
positional arguments:
index path, URI, or multihash of file to use for replay
optional arguments:
-h, --help show this help message and exit
-P [<host:port>], --proxy [<host:port>]
Proxy URL
This repo contains the code for integrating WARCs and IPFS as developed at the Archives Unleashed: Web Archive Hackathon in Toronto, Canada in March 2016. The project was also presented at:
- The Joint Conference on Digital Libraries 2016 in Newark, NJ in June 2016.
- The Web Archiving and Digital Libraries (WADL) 2016 workshop in Newark, NJ in June 2016.
- The Theory and Practice on Digital Libraries (TPDL) 2016 in Hannover, Germany in September 2016.
- The Archives Unleashed 4.0: Web Archive Datathon in London, England in June 2017.
- The International Internet Preservation Consortium (IIPC) Web Archiving Conference (WAC) 2017 in London, England in June 2017.
- The Decentralized Web Summit 2018's IPFS Lab Day in San Francisco, CA in August 2018.
There are numerous publications related to this project, but the most significant and primary one was published in TPDL 2016. (Read the PDF)
Mat Kelly, Sawood Alam, Michael L. Nelson, and Michele C. Weigle. InterPlanetary Wayback: Peer-To-Peer Permanence of Web Archives. In Proceedings of the 20th International Conference on Theory and Practice of Digital Libraries, pages 411–416, Hamburg, Germany, June 2016.
@INPROCEEDINGS{ipwb-tpdl2016,
AUTHOR = {Mat Kelly and
Sawood Alam and
Michael L. Nelson and
Michele C. Weigle},
TITLE = {{InterPlanetary Wayback}: Peer-To-Peer Permanence of Web Archives},
BOOKTITLE = {Proceedings of the 20th International Conference on Theory and Practice of Digital Libraries},
PAGES = {411--416},
MONTH = {June},
YEAR = {2016},
ADDRESS = {Hamburg, Germany},
DOI = {10.1007/978-3-319-43997-6_35}
}MIT