This repository has been archived by the owner on Jan 26, 2021. It is now read-only.
Multiverso Torch Binding Benchmark
Perform CIFAR-10 classification with torch resnet implementation.
Microsoft/fb.resnet.torch multiverso branch
Please follow this guide to setup your environment.
- Hosts : 1
- GPU : Tesla K40m * 8
- CPU : Intel(R) Xeon(R) CPU E5-2680 v2 @ 2.80GHz
- Memory : 251GB
- depth 32
- nEpochs 164
- learningRate 0.1(epoch <= 80), 0.01(81 <= epoch <= 121), 0.001(121 <= epoch)
- The train data is divided evenly to each worker.
- Master strategy is used to warm up the initial model.
- Workers sync after each batch and has a barrier after each epoch.
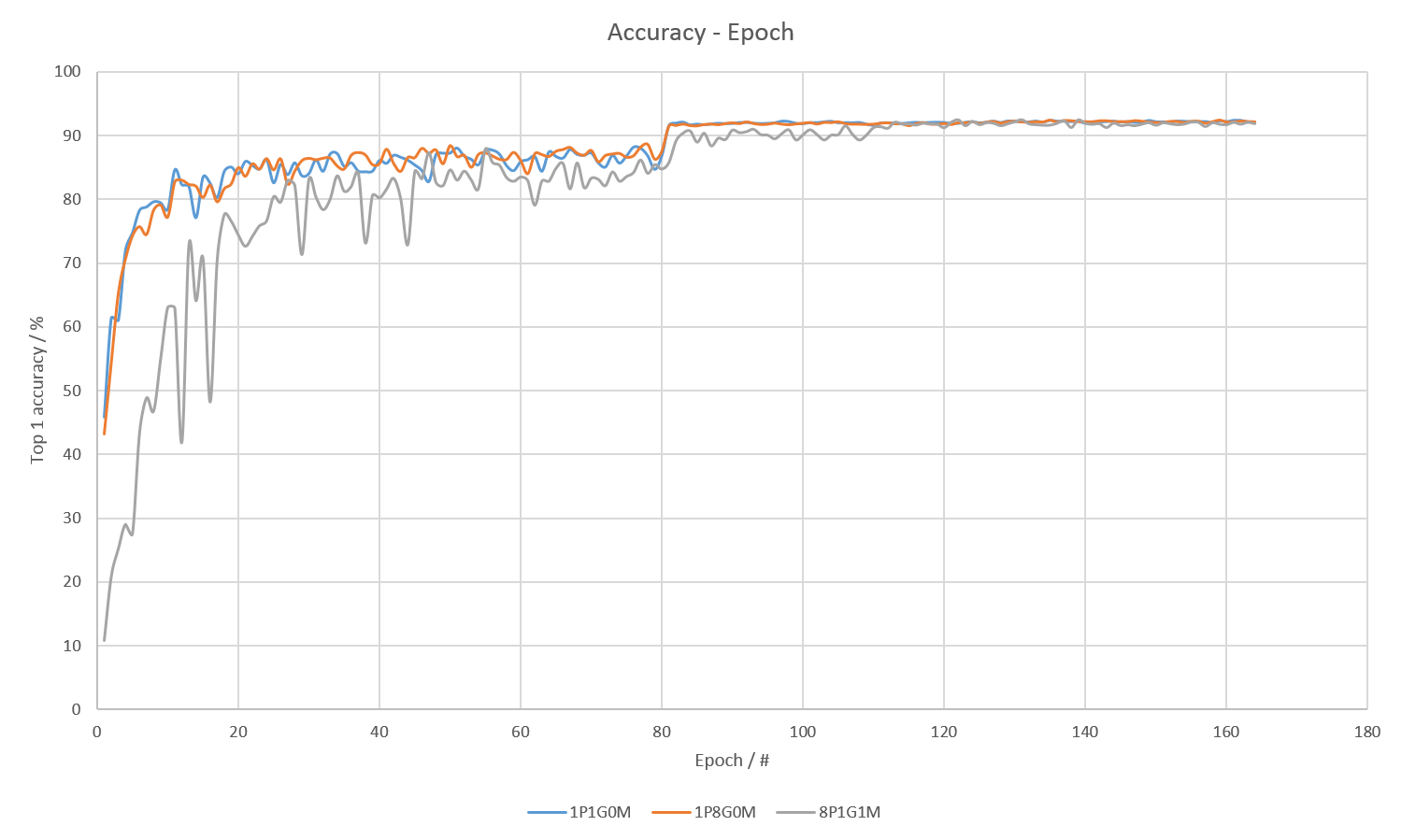
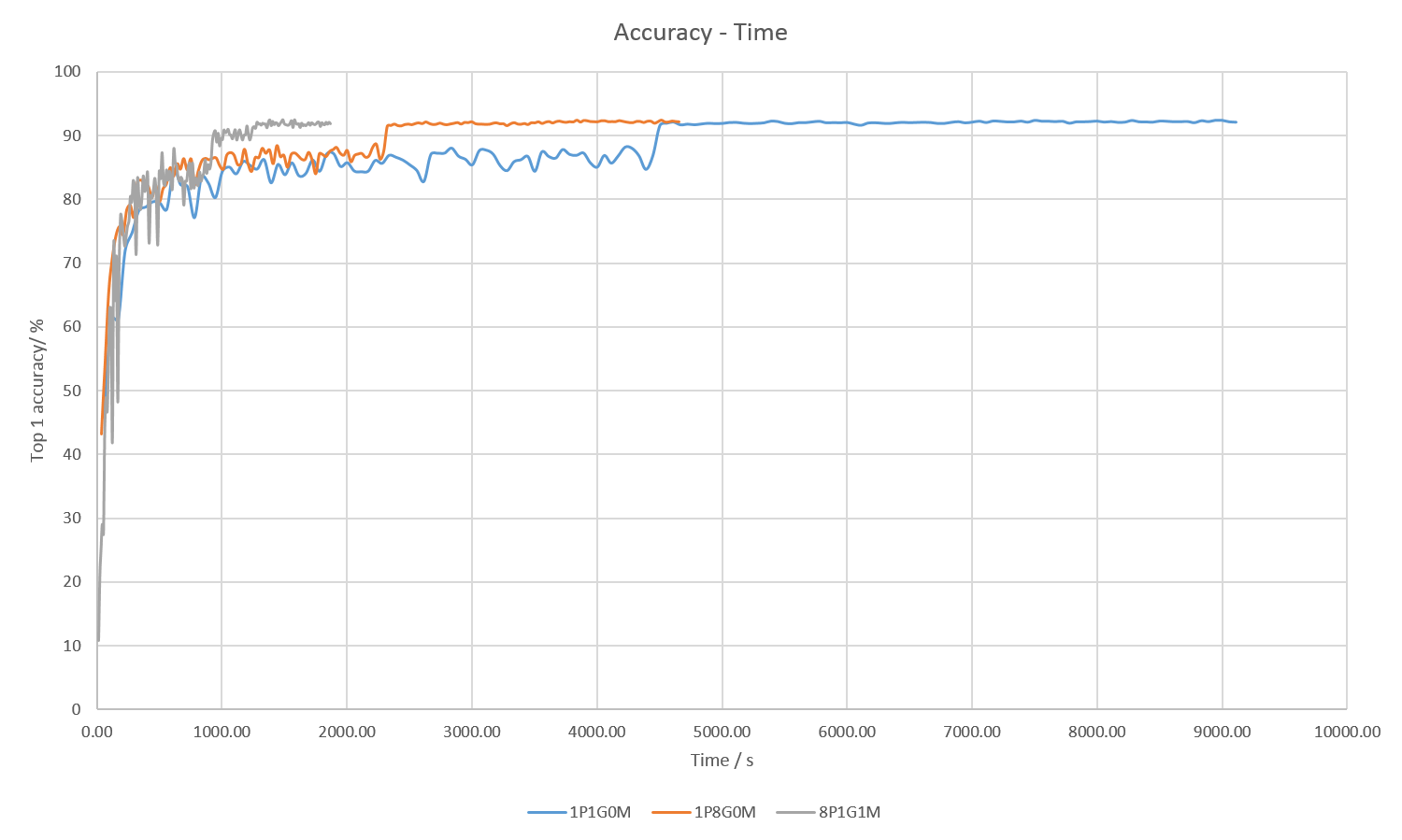
| Code Name | #Process(es) | #GPU(s) per Process | Use multiverso | Batch size | Initial learning rate | Seconds per epoch | Best Model |
|---|---|---|---|---|---|---|---|
| 1P1G0M | 1 | 1 | 0 | 128 | 0.1 | 55.57 | 92.435 % |
| 1P8G0M | 1 | 8 | 0 | 128 | 0.1 | 28.38 | 92.464 % |
| 8P1G1M | 8 | 1 | 1 | 64 | 0.05 | 11.37 | 92.449 % |