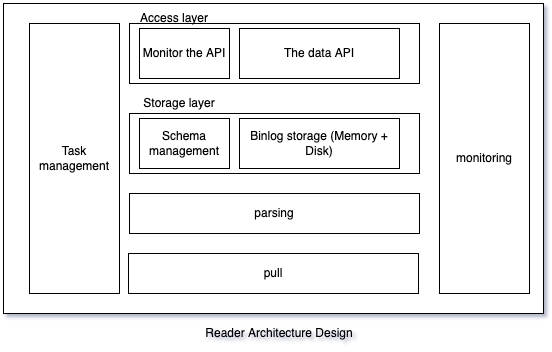
架构设计

上图为简单的部署架构图,下面简单解释一下该图:
- 一个Reader集群有多个Reader服务实例组成,一般为跨机房部署,一个Reader集群中所有的Reader服务实例完全一致,多个实例的目的主要为容灾和压力负载均衡。
- 一个Reader任务只拉取一个MySQL集群实例的binlog,所以Reader任务与MySQL集群的对应关系是1对1的关系。Reader任务默认是拉取从库的binlog。关于Reader服务拉取binlog是否会对从库或者主库有影响,DBA官方给出的结论是微乎及微的影响
- 一个Reader服务实例实例可以有多个Reader任务,所以Reader集群与MySQL集群的对应关系是1对N的关系。
- 一个SDK集群有多个Writer服务实例组成,一般也为跨机房部署,每个SDK任务的分片数会平均分配到集群中每个实例上。
- 实现了MySQL Replication协议,伪装为一个MySQL Slaver,拉取MySQL的binlog。
- 管理表结构(下面称为:Schema),根据Schema结构,将binlog解析并缓存起来(支持磁盘和内存两种缓存模式)。
- 管理与SDK的链接,并根据SDK的订阅位点,将指定位点的binlog发送给SDK(默认使用ProtoBuf编码发送binlog数据)。
- 一个Reader服务可以容纳多个Reader任务,一个Reader任务关联一个数据库集群。
Ptubes存储层分为两部分, 内存存储和文件存储
内存
使用堆外内存存储数据,可以配置不同任务使用的大小;使用堆内内存存储索引。
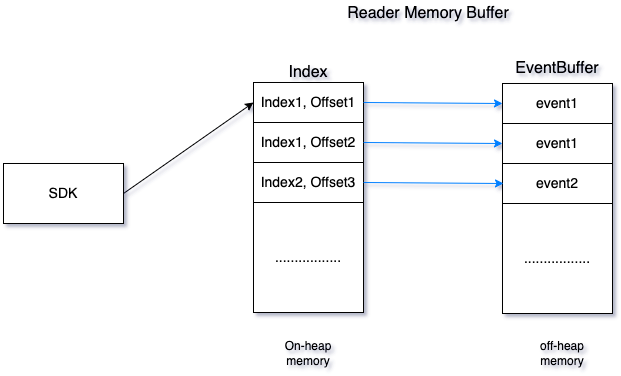
缓存由Index和EventBuffer组成,index和eventBuffer都是基于PtubesEventBuffer实现,支持高效读写;
Index存储的是EventBuffer中每个block的索引,数据写入EventBuffer后,会更新Index,寻址的时候,会先在Index中定位数据所在的block(为提升找点效率,使用二分法进行找点),然后遍历EventBuffer中对应block的所有数据,根据SDK请求的存储点以及分片信息返回数据给SDK
由于Ptubes支持时间、binlog位置以及gtid寻址,因此Index结构如下:

文件存储
文件存储结构
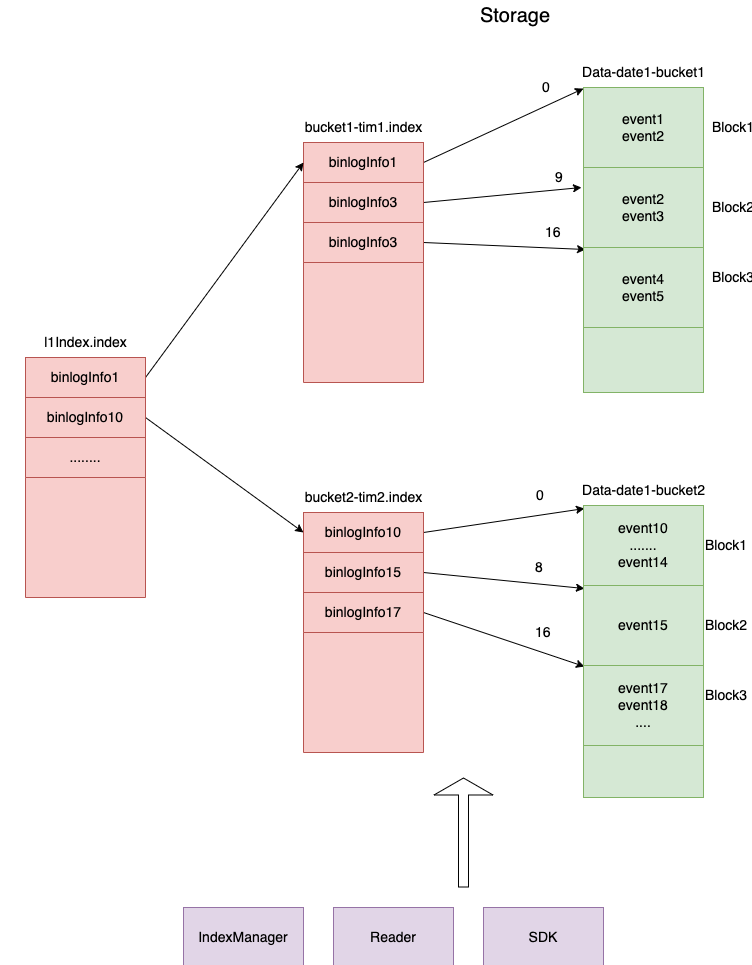
文件树形图如下
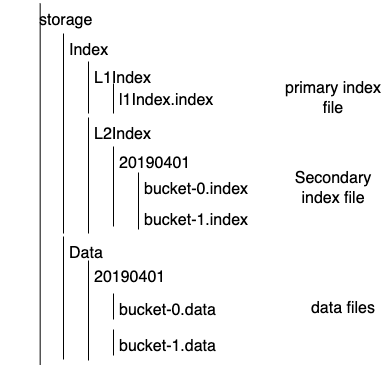
存储数据结构
BinlogInfo:用于唯一标记一个event的binlog信息,index文件中的key值
| 字段名 | length(byte) | 含义 |
|---|---|---|
| changeId | 2 | 初始值为0,每发生一次切库,changeId+1,用于保证切库之后,索引还是递增的 |
| serverId | 4 | 从库的serverId |
| binlogFile | 4 | 从库binlog文件编号 |
| binlogOffset | 8 | 在binlog文件内的偏移量 |
| uuid | 16 | 当前事务的gtid的uuid |
| transactionId | 8 | 当前事务的gtid的transactionId |
| eventIndex | 8 | 当前event在事务中的index |
| timestamp | 8 | binlog时间戳 |
CheckPoint:SDK中用于唯一标记一个event的信息
| 字段名 | length(byte) | 含义 |
|---|---|---|
| serverId | 4 | 从库的serverId |
| binlogFile | 4 | 从库binlog文件编号 |
| binlogOffset | 8 | 在binlog文件内的偏移量 |
| uuid | 16 | 当前事务的gtid的uuid |
| transactionId | 8 | 当前事务的gtid的transactionId |
| eventIndex | 8 | 当前event在事务中的index |
| timestamp | 8 | binlog时间戳 |
DataPosition结构:用于标识index或者data所在的文件以及位置
| 字段名 | length(bit) | 含义 |
|---|---|---|
| date | 18 | binlog日期 |
| bucketNumber | 14 | |
| offset | 32 | data或index文件offset |
MaxBinlogInfo文件:存储层用于存储binlog拉取的位置,重连或者服务重启的时候,从该位置继续拉取binlog,定时刷新
//包含BinlogInfo所有字段
serverId=slaveServerId,
binlogFile=2, //初始值必须是准确的
binlogOffset=774007788,//初始值可以设置为4
binlogTime=2018-12-25 17:51:13,
refreshTime=2018-12-25 17:51:13,
gtid=ec4dafec-8a5b-11e8-81dc-00221358a93e:949976,
gtidSet=ec4dafec-8a5b-11e8-81dc-00221358a93e:1-963237
ChangeIdInfo文件:存储changeId与对应从库的binlog起始位置信息,服务启动的时候检查serverId是否与上一次相同,如果不同,则追加一条changeId,并保存,否则不做变更
changeId=XX,serverId=XXX,gtidSet=XXXX,beginBinlogFile=XXX,beginBinlogOffset=XXX
changeId=XX,serverId=XXX,gtidSet=XXXX,beginBinlogFile=XXX,beginBinlogOffset=XXX
changeId=XX,serverId=XXX,gtidSet=XXXX,beginBinlogFile=XXX,beginBinlogOffset=XXX
文件以小时为单位按时间分路径存储,每个Data bucket 1G,L2Index bucket和Data bucket是一对多关系
L1Index文件结构

L2Index文件结构

Data文件结构

L1Index文件命名:l1Index.index
L2Index文件命名:bucket-序号.index
data文件命名:bucket-序号.data
读写流程
写流程
EventProducer线程处理event存储的时候,同时更新缓存和文件
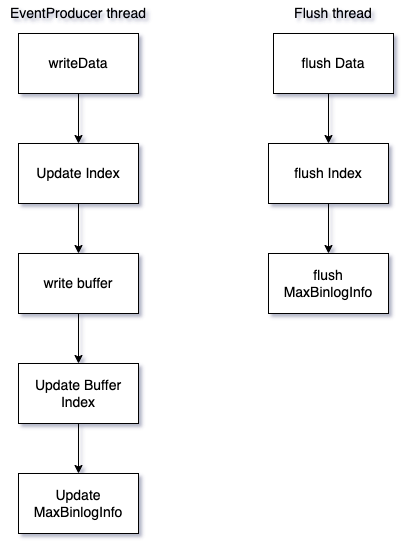
写文件使用DataOutputStream,将数据写入缓存区,异步flush落盘
EventProducer线程:负责更新Buffer、文件以及Index
Flush线程:负责定期Flush Data文件和Index文件
CleanUp线程:负责定期清理Data文件和Index文件
Flush条件:
- 新建bucket
- 写完一个block
- 定时flush
- 程序退出时flush
读流程
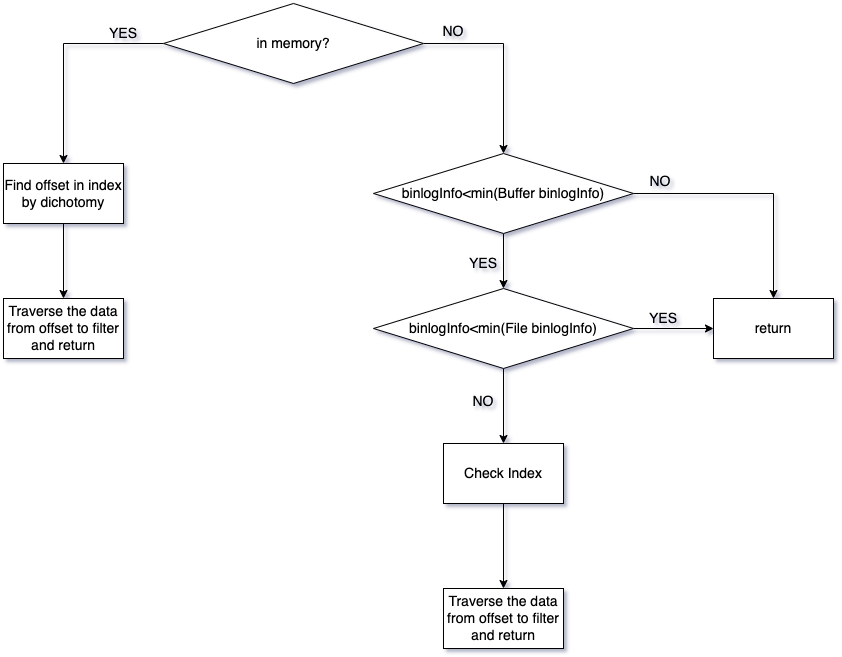
根据SDK请求时候带的binlogInfo进行寻址
- 根据内存buffer binlogInfo范围判断数据是否在内存中,如果在内存中,跳转到步骤2,如果查找的binlogInfo小于内存的最小binlogInfo,跳转到步骤4,如果大于内存最大的binlogInfo,返回结果
- 查找内存index确定block offset
- 遍历data buffer对应的block查找需要的数据,根据分片和存储点进行过滤并返回
- 如果查找的binlogInfo小于Index的最小binlogInfo,返回结果
- 二分法查找Index,获取data文件名和offset
- 从data文件offset处开始遍历数据,返回SDK订阅表对应分片的变更
Data寻址
L1Index会映射到内存,根据binlogInfo参数中的有效值检索到L2Index文件,然后再从对应的L2Index文件中寻找到正确的DataPosition
寻址方式开关
寻址方式通过开关控制,提供GTID_OFFSET,BINLOG_OFFSET,GTID三种种方式
- GTID_OFFSET:binlog_order_commit=ON前提下,binlog中gtid是严格递增的,可以根据GTID_SET生成递增的gitdOffset(long值)进行索引
- BINLOG_OFFSET:根据binlogNumber和offset生成递增的binlogOffset进行索引
- GTID:binlog_order_commit=OFF的时候,binlog中gtid并不是严格有序的
不同场景下寻址依据
当寻址模式为BINLOG_OFFSET时,Mysql开启GTID以及未开启GTID情况下,不同的场景Index文件检索依据如下
| 寻址判断依据 | |
|---|---|
| SDK第一次请求 | timestamp |
| SDK回溯 | timestamp |
| 切库 | changeId+serverId+binlogFile +binlogOffset |
| 正常情况 | changeId+serverId+binlogFile +binlogOffset |
寻址比较算法
BinlogInfo比较算法
if 只有时间信息有效
比较时间
if changeId相同
比较binlogFile和binlogOffset
else
比较changeId
由于是稀疏索引,从Index文件中找到dataPosition后,需要进行遍历直至找到准确的事务,由于事务中每个event的binlogInfo相同,遍历事务的时候,不需要遍历所有的event,只需解析事务的第一个event中的binlogInfo信息,即可判断是否找到
GTID寻址比较算法
根据GTID寻址不需要使用index文件
- 按时间倒序遍历Data文件,读取Data文件开头的Previous_Gtids,判断请求的gtid是否在Previous_Gtids中,
- 如果Previous_Gtids包含SDK请求的gtid,遍历上一个Data文件,跳转到步骤1
- 如果Previous_Gtids不包含SDK请求的gtid,遍历当前Data文件,解析每个事务的第一个event中的gtid,直到找到为止,找到后,从下一个事务开始读取数据返回给SDK
Binlog压缩
压缩
Ptubes会对一定时间之前的数据做压缩处理, 压缩算法为GZIP, 通过压缩来降低对磁盘的占用
数据清理
缓存由于是使用的是PtubesEventBuffer,数据通过LRU淘汰,而且缓存数据多于磁盘数据,不影响正常的读写,因此无需专门的清理任务做清理
磁盘清理方式:
1.定时任务清理
采用定期清理的方式进行数据清理,可配置清理时间和周期,磁盘数据默认仅保留最近24小时的数据,清理分两个流程清理
- force delete不可读文件
- mv当前过期的可读文件,可读文件变不可读
清理的数据包括data数据以及Index数据,Data数据和L2Index数据由于是按小时存储的,可以直接mv整个路径,L1Index数据是都在一个文件中,通常最多不会超过一万条数据,所以在更新L1Index的时候进行L1Index的过期数据清理
Ptubes-sdk是Ptubes工程的客户端。通过与reader之间进行http通信获取最新的数据变更(参考“3.Ptubes-sdk与Ptubes-reader”)。Ptubes-sdk利用Apache Helix实现了多分片之间的负载均衡(参考 “2.Ptubes-sdk与Apache Helix”)。由于Apache Helix依赖zookeeper,因此Ptubes-sdk也直接依赖zookeeper。
Ptubes-sdk 多机情况下示例图
针对一个同步任务 taskA,运行在两个不同的进程中bizServerProcessA 和bizServerProcessB。其线程结构如下
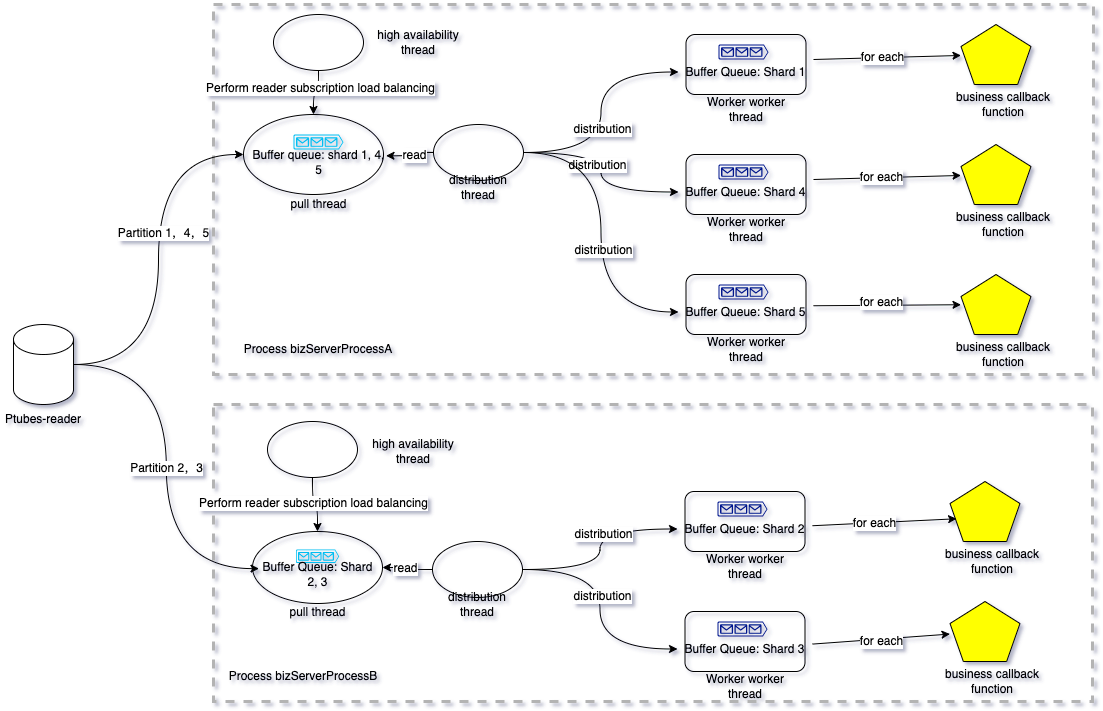
提示:
- 队列中每个“信封”代表一批数据;回调用户时也是按批回调,每批的大小可以调整 [1,n) ,当批次大小为1时相当于依次单条串行回调。
- 同一个Ptubes-sdk任务可以运行在多个java进程中。同时,同一个Ptubes-sdk java进程中可以运行多个不同的Ptubes-sdk任务。由于高可用以及一致性等角度的考量,你不能在同一个线程内启动同一个任务两次。
- 同一个Ptubes-sdk任务订阅的具体Ptubes-reader可能是不同的,具体依赖“高可用线程”进行动态的reader IP的选取。
- Ptubes-sdk的分片。是为了提高数据同步吞吐而诞生的一种并行化手段,在启动任务时,你可以为每个表指定一个分片字段,Ptubes-sdk会根据分片字段的值按照一定的哈希规则(根据分片字段取余hash),将同一个reader任务的数据散列到不同的子数据流中,每一个子数据流对应一个worker线程。显而易见,使用分片可以提高同步效率,同一个子数据流内的数据是顺序发送给下游的。不同子数据流内的数据并行发给下游,且它们之间没有顺序相关的保证。
- 由于Ptubes-sdk的各个子数据流(各个分片对应的数据流)之间的同步是并行的,因此我们为每一个分片保存了一个“存储点”信息。分片的“存储点”信息保存了当前分片对数据流消费的位点情况,随着数据流的推移,“存储点”也会逐步推进。在故障恢复、进程间分片迁移等场景我们可以利用“存储点”还原恢复不同分片的消费场景,并根据指定“存储点”重新订阅reader,保障了数据流的一致性。
- “存储点”是异步刷新到持久化存储介质上的,具体可以参考“2.Ptubes-sdk与Helix”中关于存储点的介绍。
Ptubes-sdk依赖Helix进行分片调度,因此也是强依赖zk的。每个Ptubes-sdk任务对应helix的一个“集群”,同时我们会为每个任务创建一个名为“default-resource”的默认“Helix资源”,每一个Ptubes-sdk的分片对应Helix“default-resource”资源的一个partition。helix通过对“default-resource”资源的负载均衡调度,间接完成了对Ptubes-sdk任务分片负载均衡的调度。
关于Helix的具体概念可以在Helix获取介绍。
正如Helix依赖zookeeper进行分片调度一样,Ptubes-sdk同样将存储点信息保存在zookeeper上,并使用了Helix提供的保存用户自定义数据功能https://helix.apache.org/1.0.2-docs/tutorial_propstore.html
对于一个拥有3个分片的Ptubes-sdk任务taskA而言。其存储点在zookeeper上的目录结构为
| Znode Path | tips | Znode Value Demo |
|---|---|---|
| /taskA/PROPERTYSTORE/partition-storage | 用来在分片迁入迁出、调整分片数量、修改“存储点”等场景,临时保存新的分片数量和存储点信息等。 | "{ "id":"partition-storage" ,"simpleFields":{ "partition-storage":"<br{"partitionNum":11,"buffaloCheckpoint":{"uuid":"00000000-0000-0000-0000-000000000000","transactionId":-1,"eventIndex":-1,"serverId":-1,"binlogFile":-1,"binlogOffset":-1,"timestamp":-1,"versionTs":1622204269854,"checkpointMode":"LATEST"}}" } ,"listFields":{ } ,"mapFields":{ } }" |
| "/taskA/PROPERTYSTORE/0_taskA /taskA/PROPERTYSTORE/1_taskA /taskA/PROPERTYSTORE/2_taskA" |
保存某个分片的“存储点”情况 | "{ "id":"-1" ,"simpleFields":{ "checkpoint":"{"uuid":"c055a63d-99c7-11ea-a39c-0a580a24b346","transactionId":54839254,"eventIndex":0,"serverId":36179070,"binlogFile":68,"binlogOffset":130958732,"timestamp":1624612320000,"versionTs":1622204269854,"checkpointMode":"NORMAL"}" } ,"listFields":{ } ,"mapFields":{ }}" |
存储点的结构为
| 名称 | 类型 | 功能 | 示例 |
|---|---|---|---|
| uuid | 字符串 | 事务 gtid 的uuid | c055a63d-99c7-11ea-a39c-0a580a24b346 |
| transactionId | 64位整型 | 事务 gtid 的事务id | 54839254 |
| eventIndex | 64位整型 | 事务中行号 | 0 |
| serverId | 32位整型 | Server ID | 36179070 |
| binlogFile | 32位整型 | binlog文件号 | 68 |
| binlogOffset | 64位整型 | binlog文件偏移 | 130958732 |
| timestamp | 64位整型 | 事务时间戳 | 1624612320000 |
| versionTs | 32位整型 | 存储点版本信息 | 1622204269854 |
| checkpointMode | 字符串 | "枚举类型:存储点类型 EARLIEST LATEST NORMAL" |
NORMAL |
sdk与reader之间通过3个http接口完成整个数据订阅和消费流程。
| URI | 功能 | 备注 |
|---|---|---|
| /v1/getServerInfo | 获取reader信息 | 获取某reader信息 |
| /v1/subscribe | 订阅 | 对某个readerTask进行订阅,需要在“获取reader信息”后调用 |
| /v1/fetchMessages | 拉取数据 | 拉取一批数据,需要在“订阅”成功后进行调用 |
具体的状态转换如图
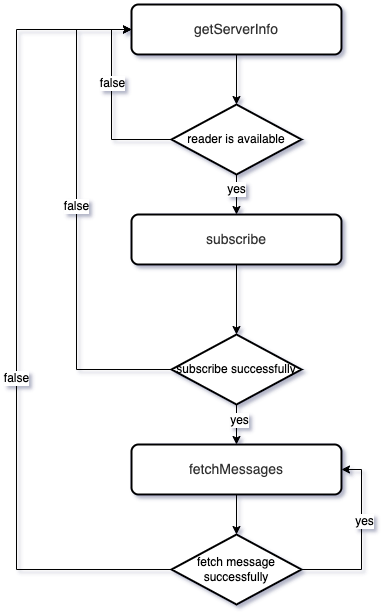
关于数据一致性保证,Ptubes系统承诺保证数据的最终一致。关于数据一致性保证,我们主要通过两个方面保证:
- binlog解析存储阶段保障 Writer服务会将Writer任务每个分片的消费持久化起来(每间隔两分钟持久化一次),所以无论是实例重启还是分片转移,都可以保证按照分片的当前位点重新订阅数据并拉取消费。
- binlog消费阶段保障 (1)定时记录消费位点,宕机/重启后从上一次记录的消费位点开始继续消费;
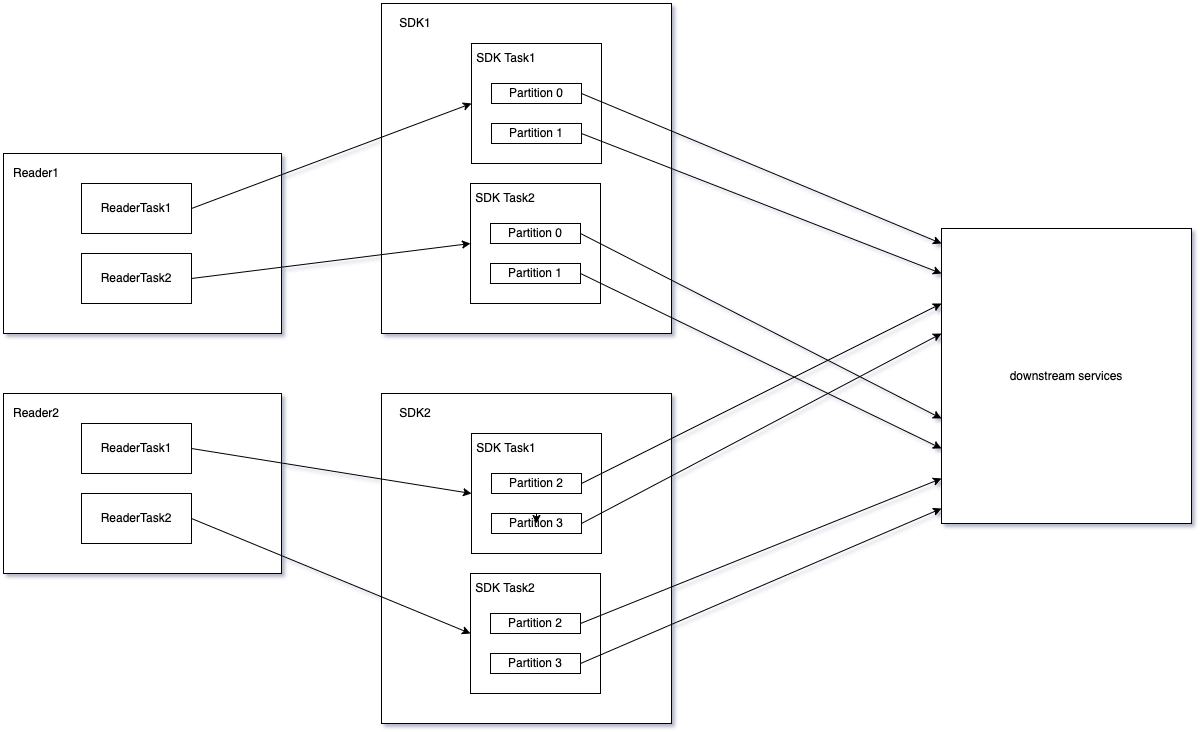
- 分片纬度并行:根据分片字段hash分配分片,每个分片独立消费位点,分片之间并行消费;
- 任务纬度并行:不同的任务独立消费位点,任务并行消费;
- 机器纬度并行:支持水平扩容;
Ptubes中跟顺序有关的名词如下:
- 分片数:Ptubes往下游写数据的并发数,Ptubes保证分片内的数据有序发送。
- 分片字段:每个表可以指定表中的一个字段作为分片字段,分片字段值经过Ptubes内部hash算法后对分片数取模可计算得到处理该条数据的分片号。
拿MQ接入方式举例,假设分片字段是id,Ptubes分片数是3,Mafka分片数是5,则不同id的数据在Ptubes和MQ中的分片分布情况如下图:

同一行数据,只要分片字段值没有变更,可以保证被hash到同一个分片串型处理,保证行级别的有序。
1.分片字段的选择
针对分片字段的选择,有以下几点建议:
- 建议选择主键或者唯一键做分片字段,可以保证数据尽量均匀打散到各个分片中,避免某一个处理的数据过多造成热点导致延迟。
- 建议选择不会变更的字段作为分片字段,分片号的计算是根据这个字段当前的值计算得到的,如果分片字段会发生改变,可能导致同一行数据的两次变更计算得到的分片号不是同一个,影响顺序。 2.分片字段的修改 服务接入后,除了因顺序问题影响下游服务处理数据之外,原则上不允许修改分片字段。