Read the paper on arXiv: Self supervised contrastive learning for digital histopathology
We are sharing a new model trained with more images. This model improves over our original paper and the ImageNet by a large margin! Click on the new model button above to download.
You can download the model here with the .ckpt extension (The previous models are also accessible, however the newer one performs better on classification, regression and segmentation tasks):
https://github.com/ozanciga/self-supervised-histopathology/releases/tag/tenpercent
We save every 100th epoch, indexed starting from 0. This checkpoint is epoch 1000, best augmentation settings (see the paper) with Lars optimizer.
Starter code:
import torchvision
import torch
MODEL_PATH = '_ckpt_epoch_9.ckpt'
RETURN_PREACTIVATION = False # return features from the model, if false return classification logits
NUM_CLASSES = 4 # only used if RETURN_PREACTIVATION = False
def load_model_weights(model, weights):
model_dict = model.state_dict()
weights = {k: v for k, v in weights.items() if k in model_dict}
if weights == {}:
print('No weight could be loaded..')
model_dict.update(weights)
model.load_state_dict(model_dict)
return model
model = torchvision.models.__dict__['resnet18'](pretrained=False)
state = torch.load(MODEL_PATH, map_location='cuda:0')
state_dict = state['state_dict']
for key in list(state_dict.keys()):
state_dict[key.replace('model.', '').replace('resnet.', '')] = state_dict.pop(key)
model = load_model_weights(model, state_dict)
if RETURN_PREACTIVATION:
model.fc = torch.nn.Sequential()
else:
model.fc = torch.nn.Linear(model.fc.in_features, NUM_CLASSES)
model = model.cuda()
images = torch.rand((10, 3, 224, 224), device='cuda')
out = model(images)
Please use below to cite this paper if you find this repository useful or if you use pretrained models shared here in your research.
@article{SelfSupervisedHisto,
title = {Self supervised contrastive learning for digital histopathology},
journal = {Machine Learning with Applications},
volume = {7},
pages = {100198},
year = {2022},
issn = {2666-8270},
doi = {https://doi.org/10.1016/j.mlwa.2021.100198},
url = {https://www.sciencedirect.com/science/article/pii/S2666827021000992},
author = {Ozan Ciga and Tony Xu and Anne Louise Martel}
}
 |
|
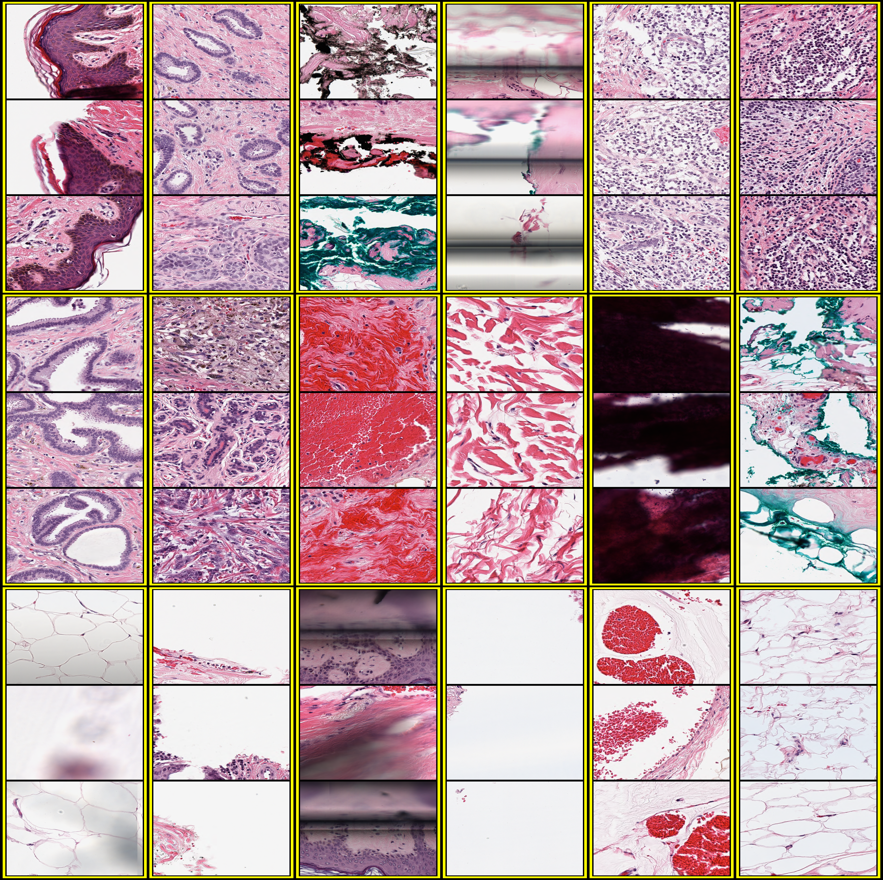
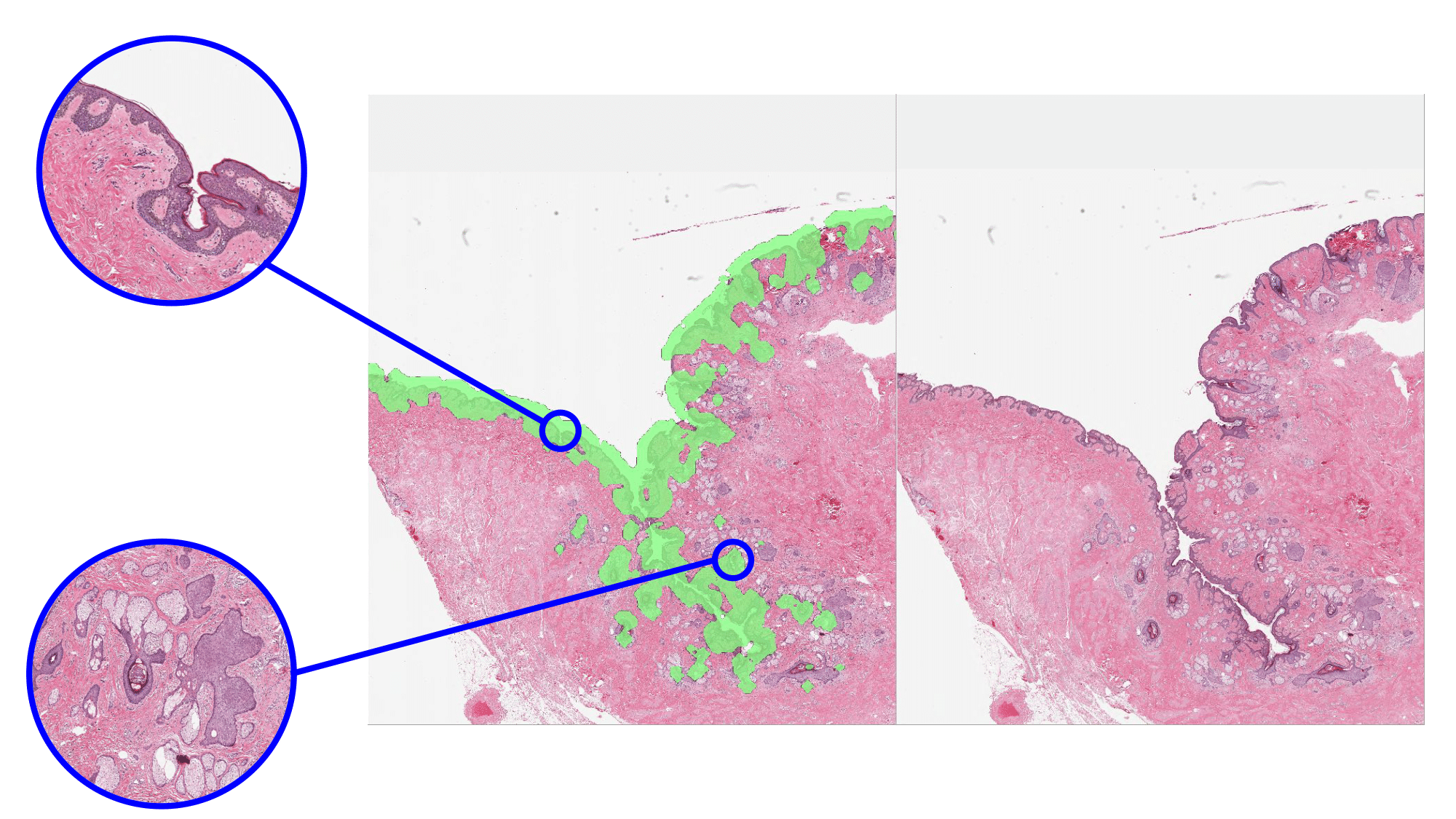
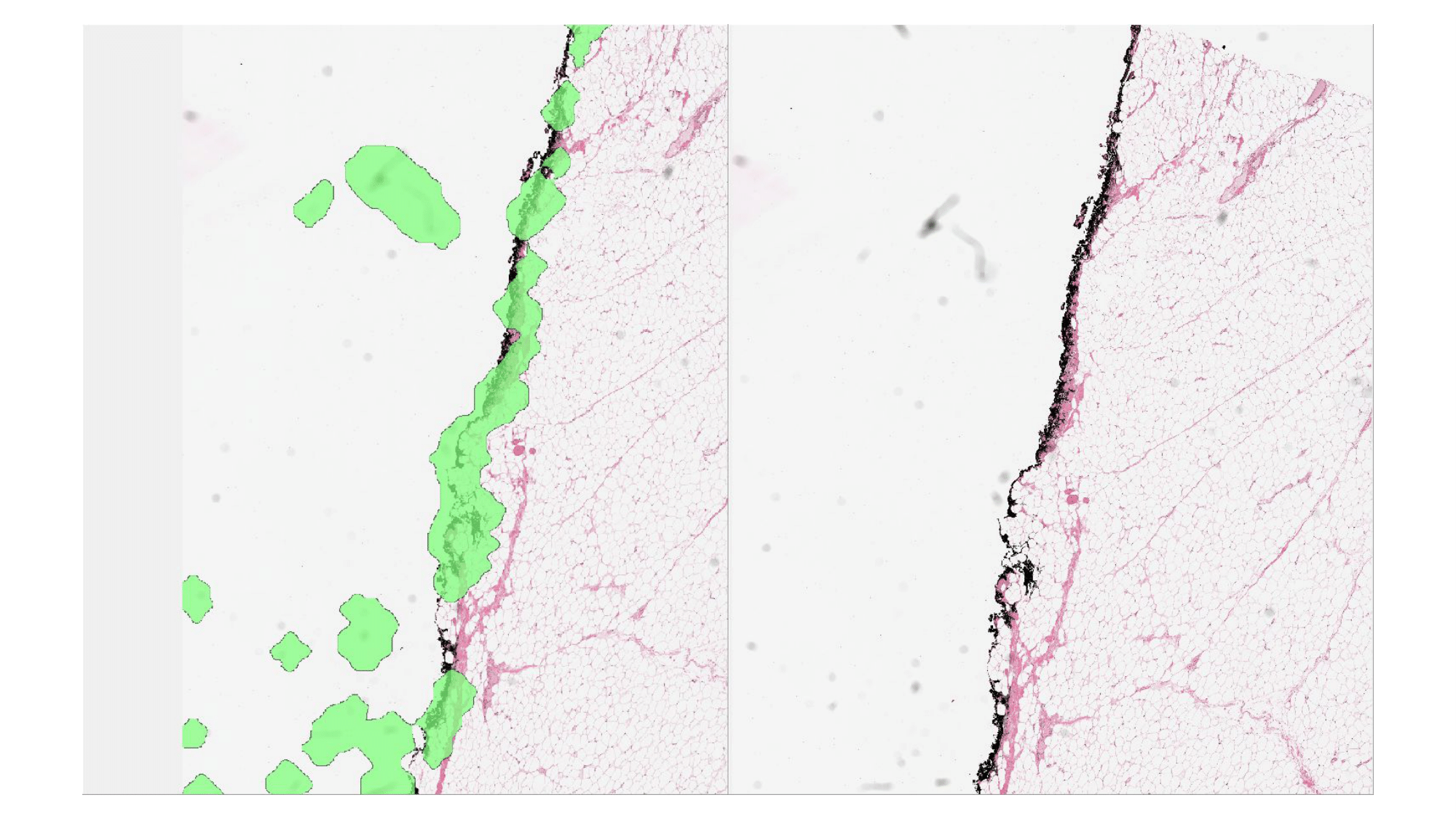
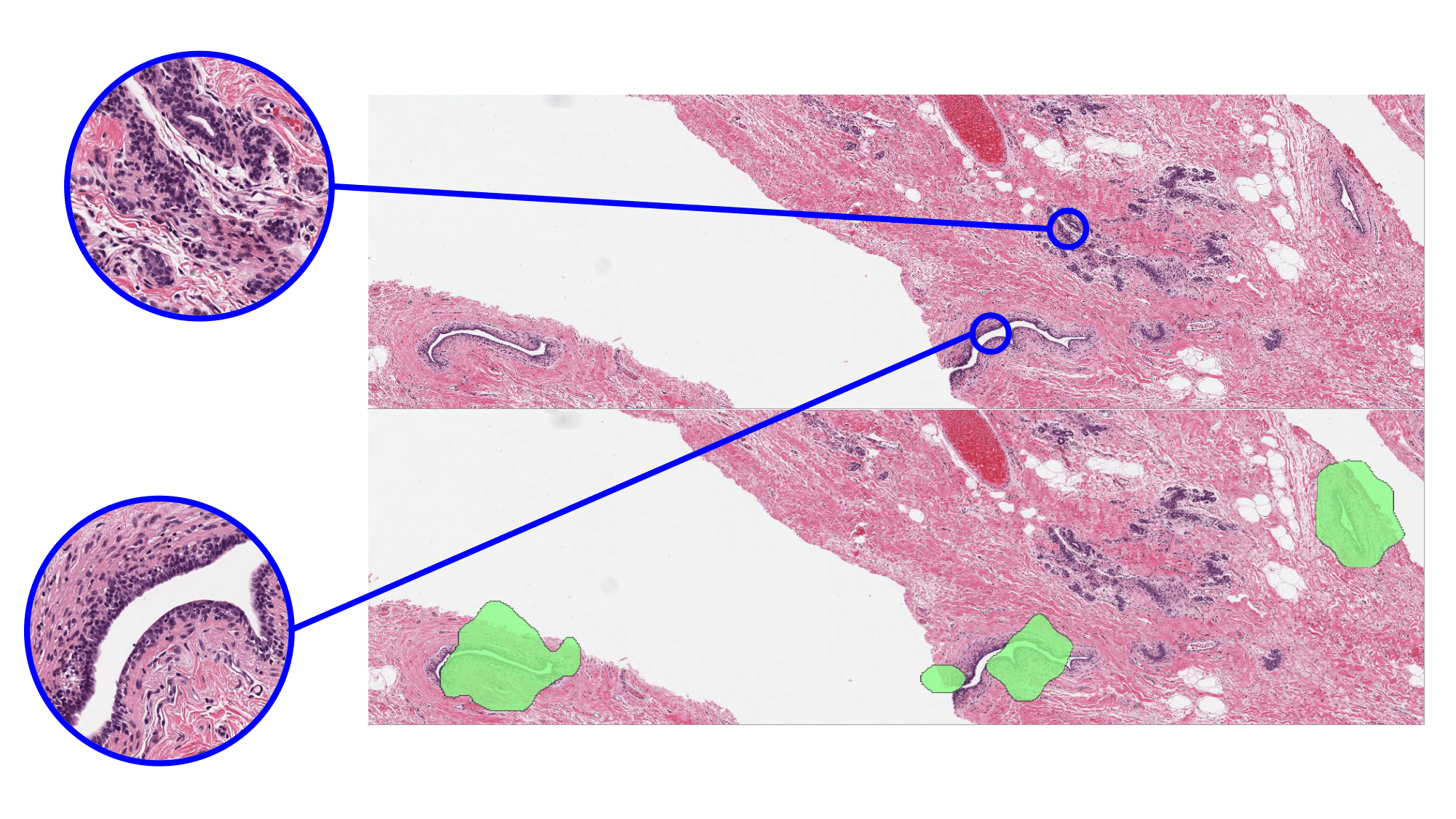
| Random sampling | Sampling using K-means clustering of learned features |
 |
 |
 |