- Monthly average land temperature from Jan 1823 - Sept 2013 (2289 months)
The dataset is split into train-test set for model validation. The test set will have the last five years of data (60 months). Note that training deep learning requires an additional validation data, thus a 20% of train set will be used as validation set.
Check whether the datetime of dataset is continuous, apply imputation if not.
- Check for existance of trend by plotting the original time series and ACF
- Check for existance of seasonality by plotting ACF
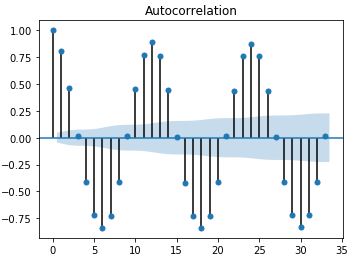
A) The following ACF plot shows strong seasonality with 12 months period.
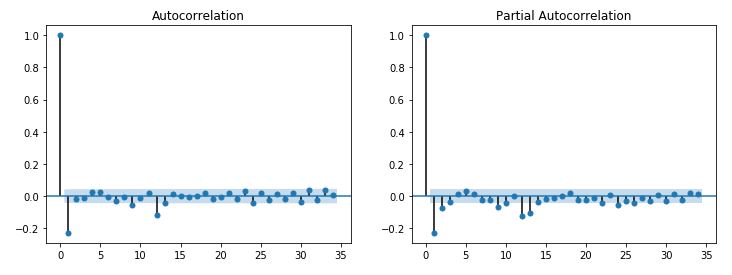
B) Below is the ACF/PACF plot after applying 12-period seasonal differencing. The ACF plot indicates setting Q to 1 while the PACF plot indicates setting P to 1.
.JPG)
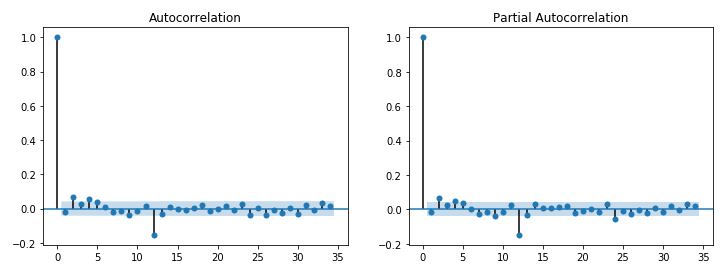
C) Below is the ACF/PACF plot of residuals for SARIMAX (0,0,0)(1,1,1,12). The decaying pattern of ACF plot shows the data is underdifferenced, a regular differencing might help to forecast better thus a new model will be built with parameter d set to 1.
_00011112.JPG)
D) Below is the ACF/PACF plot of residuals for SARIMAX (0,1,0)(1,1,1,12). The ACF plot shows that q should be set to 1 while the PACF plot shows that p should be set to 1 too.
E) Based on analysis from previous model, a new model, SARIMAX (1,1,1)(0,1,1,12) has been trained and below is the ACF/PACF plot of residuals for the model. Most of the residuals are within 95% confidence interval. Therefore it can be concluded that the model fits the data well.
F) AIC, BIC and RMSE from the three models above:
| Model | AIC | BIC | RMSE |
|---|---|---|---|
| SARIMAX (0,0,0)(1,1,1,12) | 4209 | 4226 | 0.7413 |
| SARIMAX (0,1,0)(1,1,1,12) | 4688 | 4705 | 0.7522 |
| SARIMAX (1,1,1)(1,1,1,12) | 3845 | 3873 | 0.7804 |
Conclusion
- By considering the three important criteria (AIC, BIC, RMSE) as shown above, it can be concluded that although the 3rd model has slightly higher RMSE than the other two, but it has much lower AIC and BIC, so the 3rd model should be selected as the best model.
- In fact, this conclusion is just a prove to the analysis done earlier, whereby plotting residual of the 1st model leads to the hyperparameter setting for the second model and, plotting residual of the 2nd model leads to the hyperparameter setting of the 3rd model.
- Training stops after the 3rd model is being trained because the residual plot indicates that the model has well fit the data.
Prophet is a statistical forecasting model introduced by Facebook, it is more convenient than SARIMAX as it does not require to train a few models then compare the results. The analysis from SARIMAX training can be used to configure the parameters of Prophet model, such as seasonality_mode.
The RMSE of Prophet forecast for Cuba Temperature is 0.8155.
Among many deep learning models, LSTM is used because it allows input by timeseteps and it is capable of remembering long sequences. Different configurations are needed in order to train LSTM model. Firstly is the input shape, where LSTM requires 3-dimensional input: (batch , timesteps , feature). Since Cuba Temperature dataset has seasonal period of 12 and only one feature, the timesteps and feature will be set to 12 and 1 respectively. The original 2-dimensional data should be transformed to required shape, one option to do this is by using the TimeSeriesGenerator.
The LSTM output could be a normal dense layer or a TimeDistributed dense layer, depends on your architecture design. Besides, with LSTM, we can build a lot of models rather than just vanilla LSTM model. For example, I have trained several stacked vanilla LSTM and stacked encoder-decoder LSTM models. Please refer to the notebook for further details.
| Model | RMSE |
|---|---|
| SARIMAX (best) | 0.7804 |
| Prophet (best) | 0.8155 |
| Stacked vanilla LSTM (best) | 1.3326 |
| Stacked encoder-decoder LSTM (best) | 1.0584 |
Conclusion
-
In terms of RMSE comparison, SARIMAX model outperformed the other three types of models. Whereas Prophet model has the least fitting time. Although deep learning models did not forecast as accurate as statistical models, at least their forecast results show that they have learnt some pattern (please refer to notebook) and not blindly making prediction. It is believed that deep learning models will perform better when there are more data available.
-
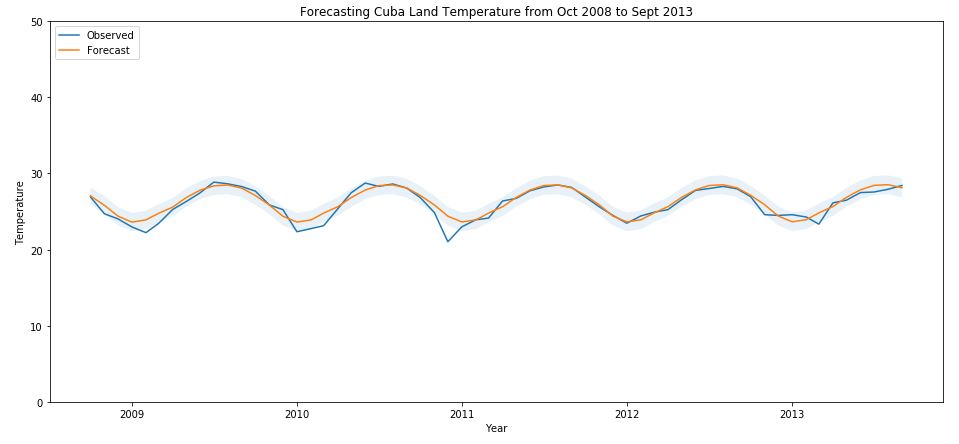
The following illustrates the forecast from SARIMAX model: