Visualizing American Community Survey data on people and households from the Census Bureau.
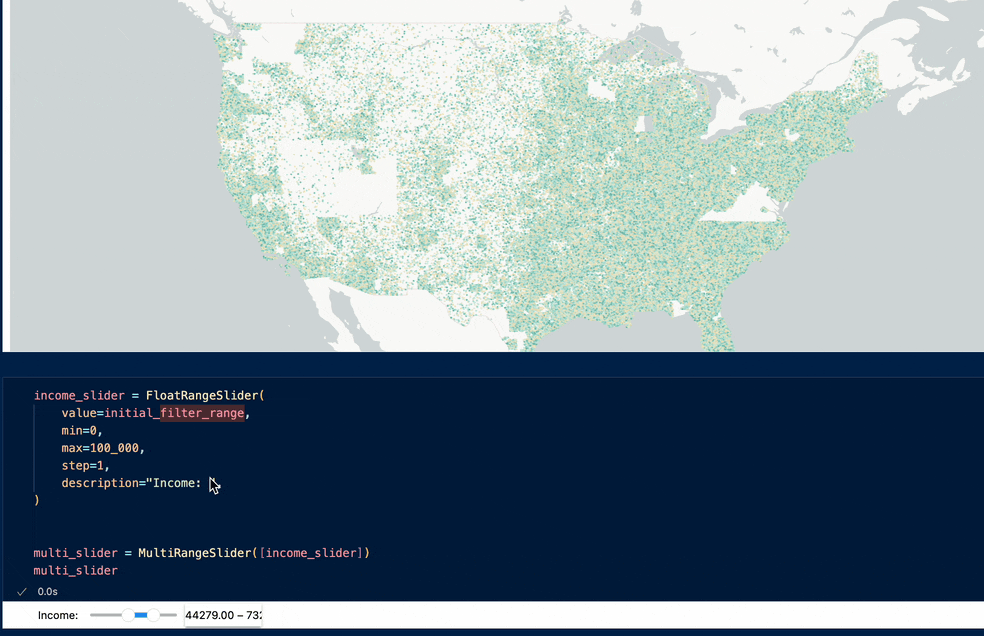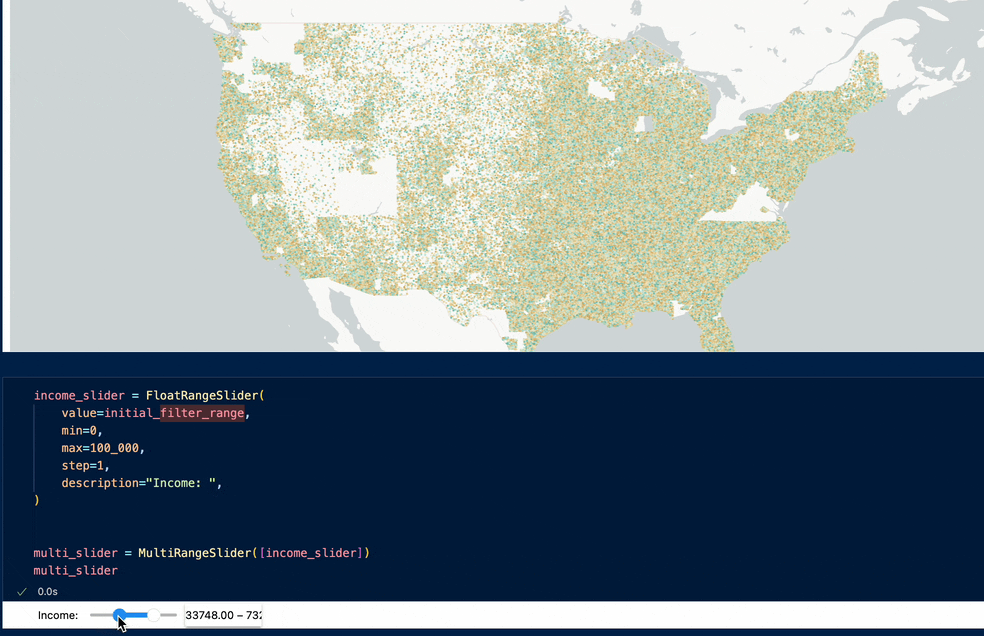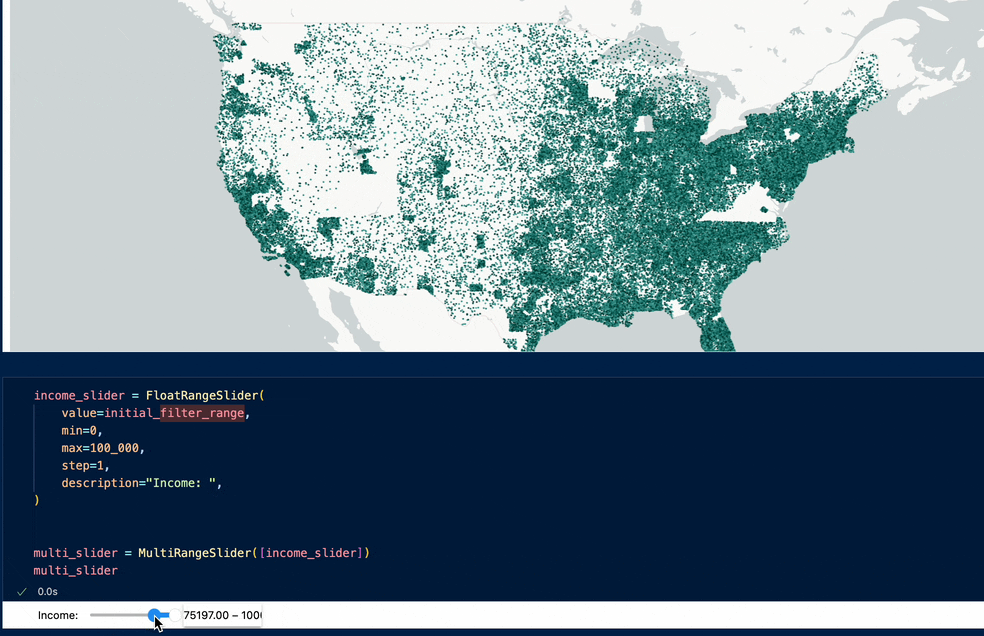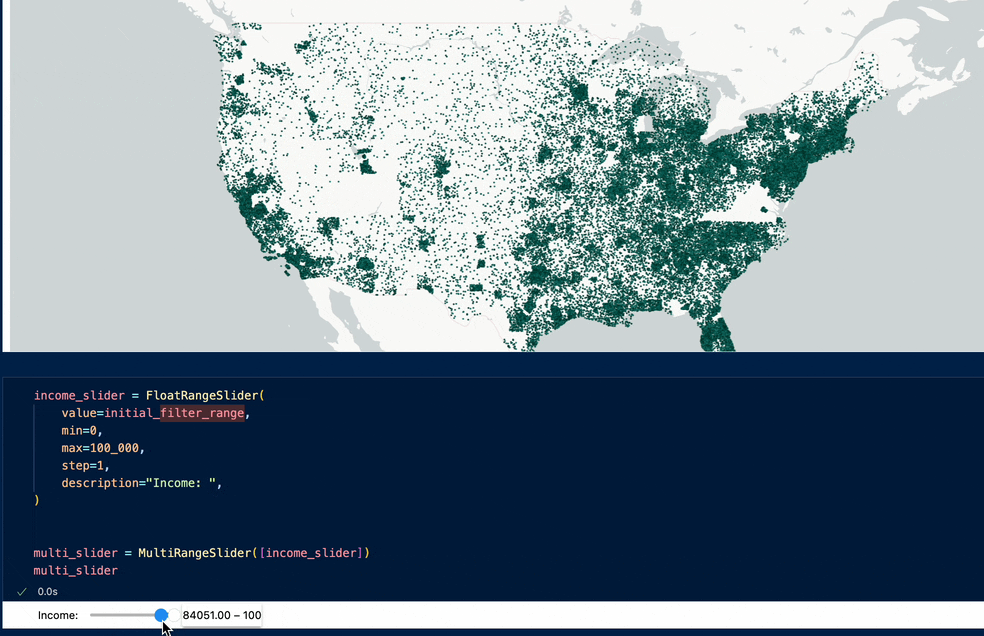
Example visualization:
Or, 38 million Americans' income over 2 decades:

This is an Observable Framework project. To start the local preview server, run:
yarn dev
Then visit http://localhost:3000 to preview your project.
For more, see https://observablehq.com/framework/getting-started.
A typical Framework project looks like this:
.
├─ docs
│ ├─ components
│ │ └─ timeline.js # an importable module
│ ├─ data
│ │ ├─ launches.csv.js # a data loader
│ │ └─ events.json # a static data file
│ ├─ example-dashboard.md # a page
│ ├─ example-report.md # another page
│ └─ index.md # the home page
├─ .gitignore
├─ observablehq.config.ts # the project config file
├─ package.json
└─ README.mddocs - This is the “source root” — where your source files live. Pages go here. Each page is a Markdown file. Observable Framework uses file-based routing, which means that the name of the file controls where the page is served. You can create as many pages as you like. Use folders to organize your pages.
docs/index.md - This is the home page for your site. You can have as many additional pages as you’d like, but you should always have a home page, too.
docs/data - You can put data loaders or static data files anywhere in your source root, but we recommend putting them here.
docs/components - You can put shared JavaScript modules anywhere in your source root, but we recommend putting them here. This helps you pull code out of Markdown files and into JavaScript modules, making it easier to reuse code across pages, write tests and run linters, and even share code with vanilla web applications.
observablehq.config.ts - This is the project configuration file, such as the pages and sections in the sidebar navigation, and the project’s title.
| Command | Description |
|---|---|
yarn install |
Install or reinstall dependencies |
yarn dev |
Start local preview server |
yarn build |
Build your static site, generating ./dist |
yarn deploy |
Deploy your project to Observable |
yarn clean |
Clear the local data loader cache |
yarn observable |
Run commands like observable help |
https://chat.openai.com/share/0284945f-996d-4e62-85c5-bdc0f4e68e18
- Use Quicktime Player to record a screen recording.
- Use
ffmpegto trim the recording:
ffmpeg -ss 00:00:03 -to 00:00:08 -i recording.mov -c copy trimmed_recording.mov- Use
ffmpegto convert the trimmed recording to a GIF:
ffmpeg -i trimmed_recording.mov -vf "fps=20,scale=1080:-1:flags=lanczos,palettegen=stats_mode=diff" -y palette.png
ffmpeg -i trimmed_recording.mov -i palette.png -filter_complex "fps=20,scale=1080:-1:flags=lanczos[x];[x][1:v]paletteuse=dither=bayer:bayer_scale=5:diff_mode=rectangle" -y high_quality.gifProcessing a year's worth of American Community Survey individual-level and household data in 5 minutes
Using the Census Bureau's American Community Survey (ACS) data with dbt (data build tool) for creating compressed parquet files for exploratory data analysis and downstream applications. I am doing this as a gift for my partner for our project exploring public space and capital together, and as an excuse to learn about cool new tools :)
Examples are in the /examples directory.
Example plot of this data: https://s13.gifyu.com/images/SCGH2.gif (code here: https://github.com/jaanli/lonboard/blob/example-american-community-survey/examples/american-community-survey.ipynb)
{kind=link}
Example visualization: live demo here - https://jaanli.github.io/american-community-survey/ (visualization code here)
Clone the repo; create and activate a virtual environment:
git clone https://github.com/jaanli/american-community-survey.git
cd american-community-survey
python3 -m venv .venv
source activate
Install the requirements:
pip install -r requirements.txt
The requirements.txt file is generated by running:
pip-compile requirements.in
For debugging, the duckdb command line tool is available on homebrew:
brew install duckdb
To retrieve the list of URLs from the Census Bureau's server and download and extract the archives for all of the 50 states' PUMS files, run the following:
cd data_processing
dbt run --select "public_use_microdata_sample.list_urls" --vars '{"public_use_microdata_sample_url": "https://www2.census.gov/programs-surveys/acs/data/pums/2023/1-Year/", "public_use_microdata_sample_data_dictionary_url": "https://www2.census.gov/programs-surveys/acs/tech_docs/pums/data_dict/PUMS_Data_Dictionary_2023.csv", "output_path": "~/data/american_community_survey"}'
Then save the URLs:
dbt run --select "public_use_microdata_sample.urls" --vars '{"public_use_microdata_sample_url": "https://www2.census.gov/programs-surveys/acs/data/pums/2023/1-Year/", "public_use_microdata_sample_data_dictionary_url": "https://www2.census.gov/programs-surveys/acs/tech_docs/pums/data_dict/PUMS_Data_Dictionary_2023.csv", "output_path": "~/data/american_community_survey"}' --threads 8
Then execute the dbt model for downloading and extract the archives of the microdata (takes ~2min on a Macbook):
dbt run --select "public_use_microdata_sample.download_and_extract_archives" --vars '{"public_use_microdata_sample_url": "https://www2.census.gov/programs-surveys/acs/data/pums/2023/1-Year/", "public_use_microdata_sample_data_dictionary_url": "https://www2.census.gov/programs-surveys/acs/tech_docs/pums/data_dict/PUMS_Data_Dictionary_2023.csv", "output_path": "~/data/american_community_survey"}' --threads 8
Then generate the CSV paths:
dbt run --select "public_use_microdata_sample.csv_paths" --vars '{"public_use_microdata_sample_url": "https://www2.census.gov/programs-surveys/acs/data/pums/2021/1-Year/", "public_use_microdata_sample_data_dictionary_url": "https://www2.census.gov/programs-surveys/acs/tech_docs/pums/data_dict/PUMS_Data_Dictionary_2022.json", "output_path": "~/data/american_community_survey"}' --threads 8
Then parse the data dictionary:
python scripts/parse_data_dictionary.py https://www2.census.gov/programs-surveys/acs/tech_docs/pums/data_dict/PUMS_Data_Dictionary_2022.csvThen execute the dbt model for parsing the data dictionary:
dbt run --select "public_use_microdata_sample.parse_data_dictionary" --vars '{"public_use_microdata_sample_url": "https://www2.census.gov/programs-surveys/acs/data/pums/2021/1-Year/", "public_use_microdata_sample_data_dictionary_url": "https://www2.census.gov/programs-surveys/acs/tech_docs/pums/data_dict/PUMS_Data_Dictionary_2021.csv", "output_path": "~/data/american_community_survey"}' --threads 8
Then generate the SQL commands needed to map every state's individual people or housing unit variables to the easier to use (and read) names:
python scripts/generate_sql_with_enum_types_and_mapped_values_renamed.py ~/data/american_community_survey/csv_paths.parquet ~/data/american_community_survey/PUMS_Data_Dictionary_2022.json
Then execute these generated SQL queries using 1 thread (you can adjust this number to be higher depending on the available processor cores on your system):
dbt run --select "public_use_microdata_sample.generated+" --vars '{"public_use_microdata_sample_url": "https://www2.census.gov/programs-surveys/acs/data/pums/2022/1-Year/", "public_use_microdata_sample_data_dictionary_url": "https://www2.census.gov/programs-surveys/acs/tech_docs/pums/data_dict/PUMS_Data_Dictionary_2022.csv", "output_path": "~/data/american_community_survey"}' --threads 8
Inspect the output folder to see what has been created in the output_path specified in the previous command:
❯ tree -hF -I '*.pdf' ~/data/american_community_survey
[ 224] /Users/me/data/data_processing/
├── [ 128] 2022/
│ └── [3.4K] 1-Year/
│ ├── [ 128] csv_hak/
│ │ └── [2.1M] psam_h02.csv
...
│ ├── [ 128] csv_pwv/
│ │ └── [ 12M] psam_p54.csv
│ └── [ 128] csv_pwy/
│ └── [4.0M] psam_p56.csv
├── [ 26M] individual_people_washington.parquet
├── [5.7M] individual_people_west_virginia.parquet
├── [ 19M] individual_people_wisconsin.parquet
├── [2.0M] individual_people_wyoming.parquet
├── [1.8K] public_use_microdata_sample_csv_paths.parquet
├── [ 533] public_use_microdata_sample_data_dictionary_path.parquet
└── [1.4K] public_use_microdata_sample_urls.parquet
You can change the URL in the command line arguments to retrieve a different year (or 5-Year versus 1-Year sample) , or choose a different output path.
To see the size of the csv output:
❯ du -sh ~/data/american_community_survey/2022
6.4G /Users/me/data/data_processing/2022
And the compressed representation size:
du -hc ~/data/american_community_survey/*.parquet
...
3.0G total
It takes ~ 30 seconds on a Macbook Pro with an M3 processor to download and extract 1 year's worth of public use microdata sample (PUMS) data from the ACS, and ~ 3 minutes to compress the CSV files into parquet files for exploratory data analysis and mapping.
You can inspect how many individual people are represented in the individual-level data with duckdb:
❯ duckdb
v0.9.2 3c695d7ba9
Enter ".help" for usage hints.
Connected to a transient in-memory database.
Use ".open FILENAME" to reopen on a persistent database.
D SELECT COUNT(*) FROM '~/data/american_community_survey/individual_people_*[!united_*].parquet';
┌──────────────┐
│ count_star() │
│ int64 │
├──────────────┤
│ 2777288 │
└──────────────┘
(The regular expression [!united_*] excludes the national-level data.)
You can inspect that how many households are represented in housing unit-level data:
❯ duckdb
v0.9.2 3c695d7ba9
Enter ".help" for usage hints.
Connected to a transient in-memory database.
Use ".open FILENAME" to reopen on a persistent database.
D SELECT COUNT(*) FROM '~/data/american_community_survey/housing_units_*[!united_*].parquet';
┌──────────────┐
│ count_star() │
│ int64 │
├──────────────┤
│ 1323158 │
└──────────────┘
- Use dbt to save the database of the the 2021 1-Year ACS PUMS data and data dictionary from the Census Bureau's server and extract the archives for all of the 50 states' PUMS files:
dbt run --select "public_use_microdata_sample.public_use_microdata_sample_urls" --vars '{"public_use_microdata_sample_url": "https://www2.census.gov/programs-surveys/acs/data/pums/2021/1-Year/", "public_use_microdata_sample_data_dictionary_url": "https://www2.census.gov/programs-surveys/acs/tech_docs/pums/data_dict/PUMS_Data_Dictionary_2021.csv", "output_path": "~/data/american_community_survey"}' --threads 8
Check that the URLs appear correct:
duckdb -c "SELECT * FROM '~/data/american_community_survey/public_use_microdata_sample_urls.parquet'"
- Download and extract the archives for all of the 50 states' PUMS files (takes about 30 seconds on a gigabit connection):
dbt run --select "public_use_microdata_sample.download_and_extract_archives" --vars '{"public_use_microdata_sample_url": "https://www2.census.gov/programs-surveys/acs/data/pums/2023/1-Year/", "public_use_microdata_sample_data_dictionary_url": "https://www2.census.gov/programs-surveys/acs/tech_docs/pums/data_dict/PUMS_Data_Dictionary_2023.csv", "output_path": "~/data/american_community_survey"}' --threads 8
Save the paths to the CSV files:
dbt run --select "public_use_microdata_sample.csv_paths" --vars '{"public_use_microdata_sample_url": "https://www2.census.gov/programs-surveys/acs/data/pums/2023/1-Year/", "public_use_microdata_sample_data_dictionary_url": "https://www2.census.gov/programs-surveys/acs/tech_docs/pums/data_dict/PUMS_Data_Dictionary_2023.csv", "output_path": "~/data/american_community_survey"}' --threads 8
Check that the CSV files are present:
duckdb -c "SELECT * FROM '~/data/american_community_survey/csv_paths.parquet'"
- Parse the data dictionary:
python scripts/parse_data_dictionary.py https://www2.census.gov/programs-surveys/acs/tech_docs/pums/data_dict/PUMS_Data_Dictionary_2023.csvThen:
dbt run --select "public_use_microdata_sample.data_dictionary_path" --vars '{"public_use_microdata_sample_url": "https://www2.census.gov/programs-surveys/acs/data/pums/2023/1-Year/", "public_use_microdata_sample_data_dictionary_url": "https://www2.census.gov/programs-surveys/acs/tech_docs/pums/data_dict/PUMS_Data_Dictionary_2023.csv", "output_path": "~/data/american_community_survey"}' --threads 8
Check that the data dictionary path is displayed correctly:
duckdb -c "SELECT * FROM '~/data/american_community_survey/public_use_microdata_sample_data_dictionary_path.parquet'"
- Generate the SQL commands needed to map every state's individual people or housing unit variables to the easier to use (and read) names:
python scripts/generate_sql_with_enum_types_and_mapped_values_renamed.py ~/data/american_community_survey/csv_paths.parquet PUMS_Data_Dictionary_2023.json
- Execute these generated SQL queries using 8 threads (you can adjust this number to be higher depending on the available processor cores on your system):
dbt run --select "public_use_microdata_sample.generated.2023+" --vars '{"public_use_microdata_sample_url": "https://www2.census.gov/programs-surveys/acs/data/pums/2023/1-Year/", "public_use_microdata_sample_data_dictionary_url": "https://www2.census.gov/programs-surveys/acs/tech_docs/pums/data_dict/PUMS_Data_Dictionary_2023.csv", "output_path": "~/data/american_community_survey"}' --threads 8
- Test that the compressed parquet files are present and have the expected size:
du -sh ~/data/american_community_survey/2021
du -hc ~/data/american_community_survey/*2021.parquet
Check that you can execute a SQL query against these files:
duckdb -c "SELECT COUNT(*) FROM '~/data/american_community_survey/*individual_people_united_states*2021.parquet'"
- Create a data visualization using the compressed parquet files by adding to the
data_processing/models/public_use_microdata_sample/figuresdirectory, and using examples from here https://github.com/jaanli/american-community-survey/ or here https://github.com/jaanli/lonboard/blob/example-american-community-survey/examples/american-community-survey.ipynb
To save time, there is a bash script with these steps in scripts/process_one_year_of_data_processing_data.sh that can be used as follows:
chmod a+x scripts/process_one_year_of_data_processing_data.sh
./scripts/process_one_year_of_data_processing_data.sh 2021
The argument specifies the year to be downloaded, transformed, compressed, and saved. It takes about 5 minutes per year of data.
The following variables are available in the individual-level census files for every (anonymized) person, alongside 79 variables for the weight of the person (for computing population-level weighted estimates and allocation flags to denote missing values that were imputed):
Record Type
Housing unit/GQ person serial number
Division code based on 2010 Census definitions Division code based on 2020 Census definitions
Person number
Public use microdata area code (PUMA) based on 2020 Census definition (areas with population of 100,000 or more, use with ST for unique code)
Region code based on 2020 Census definitions
State Code based on 2020 Census definitions
Adjustment factor for income and earnings dollar amounts (6 implied decimal places)
Person's weight
Age
Citizenship status
Year of naturalization write-in
Class of worker
Self-care difficulty
Hearing difficulty
Vision difficulty
Independent living difficulty
Ambulatory difficulty
Veteran service-connected disability rating (percentage)
Veteran service-connected disability rating (checkbox)
Cognitive difficulty
Ability to speak English
Gave birth to child within the past 12 months
Grandparents living with grandchildren
Length of time responsible for grandchildren
Grandparents responsible for grandchildren
Subsidized Marketplace Coverage
Insurance through a current or former employer or union
Insurance purchased directly from an insurance company
Medicare, for people 65 and older, or people with certain disabilities
Medicaid, Medical Assistance, or any kind of government-assistance plan for those with low incomes or a disability
TRICARE or other military health care
VA (enrolled for VA health care)
Indian Health Service
Interest, dividends, and net rental income past 12 months (use ADJINC to adjust to constant dollars)
Travel time to work
Vehicle occupancy
Means of transportation to work
Language other than English spoken at home
Marital status
Divorced in the past 12 months
Married in the past 12 months
Number of times married
Widowed in the past 12 months
Year last married
Mobility status (lived here 1 year ago)
Military service
Served September 2001 or later
Served August 1990 - August 2001 (including Persian Gulf War)
Served May 1975 - July 1990
Served Vietnam era (August 1964 - April 1975)
Served February 1955 - July 1964
Served Korean War (July 1950 - January 1955)
Peacetime service before July 1950
Served World War II (December 1941 - December 1946)
Temporary absence from work (UNEDITED - See 'Employment Status Recode' (ESR))
Available for work (UNEDITED - See 'Employment Status Recode' (ESR))
On layoff from work (UNEDITED - See 'Employment Status Recode' (ESR))
Looking for work (UNEDITED - See 'Employment Status Recode' (ESR))
Informed of recall (UNEDITED - See 'Employment Status Recode' (ESR))
All other income past 12 months (use ADJINC to adjust to constant dollars)
Public assistance income past 12 months (use ADJINC to adjust to constant dollars)
Relationship
Retirement income past 12 months (use ADJINC to adjust to constant dollars)
School enrollment
Grade level attending
Educational attainment
Self-employment income past 12 months (use ADJINC to adjust SEMP to constant dollars)
Sex
Supplementary Security Income past 12 months (use ADJINC to adjust SSIP to constant dollars)
Social Security income past 12 months (use ADJINC to adjust SSP to constant dollars)
Wages or salary income past 12 months (use ADJINC to adjust WAGP to constant dollars)
Usual hours worked per week past 12 months
When last worked
Weeks worked during past 12 months
Worked last week
Year of entry
Ancestry recode
Recoded Detailed Ancestry - first entry
Recoded Detailed Ancestry - second entry
Decade of entry
Disability recode
Number of vehicles calculated from JWRI
Employment status of parents
Employment status recode
Recoded field of degree - first entry
Recoded field of degree - second entry
Health insurance coverage recode
Recoded detailed Hispanic origin
Industry recode for 2018 and later based on 2017 IND codes
Time of arrival at work - hour and minute
Time of departure for work - hour and minute
Language spoken at home
Migration PUMA based on 2020 Census definition
Migration recode - State or foreign country code
Married, spouse present/spouse absent
North American Industry Classification System (NAICS) recode for 2018 and later based on 2017 NAICS codes
Nativity
Nativity of parent
Own child
Occupation recode for 2018 and later based on 2018 OCC codes
Presence and age of own children
Total person's earnings (use ADJINC to adjust to constant dollars)
Total person's income (use ADJINC to adjust to constant dollars)
Place of birth (Recode)
Income-to-poverty ratio recode
Place of work PUMA based on 2020 Census definition
Place of work - State or foreign country recode
Private health insurance coverage recode
Public health coverage recode
Quarter of birth
Recoded detailed race code
Recoded detailed race code
Recoded detailed race code
American Indian and Alaska Native recode (American Indian and Alaska Native alone or in combination with one or more other races)
Asian recode (Asian alone or in combination with one or more other races)
Black or African American recode (Black alone or in combination with one or more other races)
Native Hawaiian recode (Native Hawaiian alone or in combination with one or more other races)
Number of major race groups represented
Other Pacific Islander recode (Other Pacific Islander alone or in combination with one or more other races)
Some other race recode (Some other race alone or in combination with one or more other races)
White recode (White alone or in combination with one or more other races)
Related child
Field of Degree Science and Engineering Flag - NSF Definition
Field of Degree Science and Engineering Related Flag - NSF Definition
Subfamily number
Subfamily relationship
Standard Occupational Classification (SOC) codes for 2018 and later based on 2018 SOC codes
Veteran period of service
World area of birth
Medicare coverage given through the eligibility coverage edit
Medicaid coverage given through the eligibility coverage edit
Medicaid, medical assistance, or any kind of government-assistance plan for people with low incomes or a disability
TRICARE coverage given through the eligibility coverage edit
The following variables are available for every household in the data (alongside 79 weight replicates for computing population-level weighted estimates, and allocation flags to denote missing values that were imputed):
Record Type
Housing unit/GQ person serial number
Division code based on 2010 Census definitions Division code based on 2020 Census definitions
Public use microdata area code (PUMA) based on 2020 Census definition (areas with population of 100,000 or more, use with ST for unique code)
Region code based on 2020 Census definitions
State Code based on 2020 Census definitions
Adjustment factor for housing dollar amounts (6 implied decimal places)
Adjustment factor for income and earnings dollar amounts (6 implied decimal places)
Housing Unit Weight
Number of persons in this household
Type of unit
Access to the Internet
Lot size
Sales of Agriculture Products (yearly sales, no adjustment factor is applied)
Bathtub or shower
Number of bedrooms
Units in structure
Cellular data plan for a smartphone or other mobile device
Other computer equipment
Condominium fee (monthly amount, use ADJHSG to adjust CONP to constant dollars)
Dial-up service
Electricity cost flag variable
Electricity cost (monthly cost, use ADJHSG to adjust ELEP to constant dollars)
Yearly food stamp/Supplemental Nutrition Assistance Program (SNAP) recipiency
Fuel cost flag variable
Fuel cost (yearly cost for fuels other than gas and electricity, use ADJHSG to adjust FULP to constant dollars)
Gas cost flag variable
Gas cost (monthly cost, use ADJHSG to adjust GASP to constant dollars)
House heating fuel
Broadband (high speed) Internet service such as cable, fiber optic, or DSL service
Water heater (Puerto Rico only)
Fire/hazard/flood insurance (yearly amount, use ADJHSG to adjust INSP to constant dollars)
Laptop or desktop
Mobile home costs (yearly amount, use ADJHSG to adjust MHP to constant dollars)
First mortgage payment includes fire/hazard/flood insurance
First mortgage payment (monthly amount, use ADJHSG to adjust MRGP to constant dollars)
First mortgage payment includes real estate taxes
First mortgage status
Other Internet service
Refrigerator
Number of rooms
Meals included in rent
Monthly rent (use ADJHSG to adjust RNTP to constant dollars)
Hot and cold running water
Running water
Satellite Internet service
Sink with a faucet
Smartphone
Total payment on all second and junior mortgages and home equity loans (monthly amount, use ADJHSG to adjust SMP to constant dollars)
Stove or range
Tablet or other portable wireless computer
Telephone service
Tenure
Vacancy duration
Other vacancy status
Vacancy status
Property value
Vehicles (1 ton or less) available
Water cost flag variable
Water cost (yearly cost, use ADJHSG to adjust WATP to constant dollars)
When structure first built
Couple Type
Family income (past 12 months, use ADJINC to adjust FINCP to constant dollars)
Family presence and age of related children
Gross rent (monthly amount, use ADJHSG to adjust GRNTP to constant dollars)
Gross rent as a percentage of household income past 12 months
Household language
Detailed household language
Age of the householder
Recoded detailed Hispanic origin of the householder
Recoded detailed race code of the householder
Household/family type
Household/family type (includes cohabiting)
Household income (past 12 months, use ADJINC to adjust HINCP to constant dollars)
Household with grandparent living with grandchildren
HH presence and age of children
HH presence and age of own children
HH presence and age of related children
Complete kitchen facilities
Limited English speaking household
Multigenerational household
When moved into this house or apartment
Number of own children in household (unweighted)
Number of persons in family (unweighted)
Grandparent headed household with no parent present
Presence of nonrelative in household
Number of related children in household (unweighted)
Selected monthly owner costs as a percentage of household income during the past 12 months
Unmarried partner household
Complete plumbing facilities
Complete plumbing facilities for Puerto Rico
Presence of subfamilies in household
Presence of persons under 18 years in household (unweighted)
Presence of persons 60 years and over in household (unweighted)
Presence of persons 65 years and over in household (unweighted)
Response mode
Selected monthly owner costs (use ADJHSG to adjust SMOCP to constant dollars)
Second or junior mortgage or home equity loan status
Specified rental unit
Specified owner unit
Property taxes (yearly real estate taxes)
Workers in family during the past 12 months
Work experience of householder and spouse
Work status of householder or spouse in family households
https://chat.openai.com/share/2018eb46-c896-4418-bc12-5c831a87bba6
- Scrape the list of URLs:
dbt run --select "public_use_microdata_sample.list_shapefile_urls"
- Create the database file with the list of URLs:
dbt run --select "public_use_microdata_sample.microdata_area_shapefile_urls"
- Download the shapefiles:
dbt run --select "public_use_microdata_sample.download_and_extract_shapefiles"
- Save a database file with the shapefile paths:
dbt run --select "public_use_microdata_sample.microdata_area_shapefile_paths"
- Check that the paths are correct:
❯ duckdb -c "SELECT * FROM '/Users/me/data/data_processing/microdata_area_shapefile_paths.parquet';"
Displays:
┌─────────────────────────────────────────────────────────────────────────────────────────────┐
│ shp_path │
│ varchar │
├─────────────────────────────────────────────────────────────────────────────────────────────┤
│ /Users/me/data/data_processing/PUMA5/2010/tl_2010_02_puma10/tl_2010_02_puma10.shp │
│ · │
│ · │
│ · │
│ /Users/me/data/data_processing/PUMA5/2010/tl_2010_48_puma10/tl_2010_48_puma10.shp │
├─────────────────────────────────────────────────────────────────────────────────────────────┤
│ 54 rows (40 shown) │
└─────────────────────────────────────────────────────────────────────────────────────────────┘
-
- [TODO: currently need to do this step in a Jupyter notebook/python script] Create the database table with the combined shapefile path:
dbt run --select "public_use_microdata_sample.combine_shapefiles*"
- Scavenger Hunts Based on ACS Data: Create city-wide scavenger hunts that encourage participants to explore diverse neighborhoods. Use data points like historical landmarks, unique housing characteristics, and multicultural centers as waypoints to foster appreciation for the city's diversity. (From ChatGPT.)
I'd love to hear what uses you have for this data! Reach me on Twitter or e-mail.