WIP: Docs draft for integration with DVC #323
There are no files selected for viewing
| Original file line number | Diff line number | Diff line change | ||||
|---|---|---|---|---|---|---|
| @@ -0,0 +1,115 @@ | ||||||
| # Get Started DVC | ||||||
|
|
||||||
| To leverage concepts of Model and Data Registries in a more explicit way, you | ||||||
| can denote the `type` of each output. This will let you browse models and data | ||||||
| separately, address them by `name` in `dvc get`, and eventually, see them in DVC | ||||||
| Studio. | ||||||
|
|
||||||
| Let's start with marking an artifact as data or model. | ||||||
|
There was a problem hiding this comment.
Suggested change
Personally, I don't think that "data" is a valid example for a type There was a problem hiding this comment. Why? I assumed Data Registry would show There was a problem hiding this comment. It carries 0 information though, right? There was a problem hiding this comment. Good point. Maybe it's There was a problem hiding this comment. My 2cs. Data is not abstract for me (it's different vs model in my perception). But in DVC it's not needed. Any I would personally try to simplify all of this - no multiple types initially. only models. We are prematurely generalizing this I think. There was a problem hiding this comment. I think of the terms Would love to keep the idea of data registry support around, haven't thought a lot about using I would love to use/try With all of that said I think prioritizing the There was a problem hiding this comment. Trying to think of advantages of having There was a problem hiding this comment. If I might chip in as a user - I absolutely would like GTO to be used also to build a data(set) registry (together with DVC) and possibly a combined data(set) and model registry. In fact, we intend to use GTO and DVC to build a dataset registry for one (fairly large) client in the coming weeks. By the way, while stuff like MLFlow is a viable alternative to the GTO+MLEM-based model registry (it does not have all of its features but has some others), I don't know any open source alternative to a GTO+DVC-based dataset registry (and general I've yet to see data versioning done better than with DVC)...which means it is a very good selling point IMO. I like the idea of viewing GTO as a tool to build pretty much any artifact registry, though models and datasets are the most likely use-cases. |
||||||
|
|
||||||
| If you're using `dvc add` to track your artifact, you'll need to run: | ||||||
|
|
||||||
| ```dvc | ||||||
| $ dvc add mymodel.pkl --type model | ||||||
| ``` | ||||||
|
|
||||||
| If you're producing your models in DVC pipeline, you'll need to add | ||||||
| `type: model` to `dvc.yaml` instead: | ||||||
|
|
||||||
|
There was a problem hiding this comment. Now I think there is a user case this change may not support that well. One of our prospects asked to allow a single file (let's say The motivation is to be able to promote The only workaround I see now is to create a "mirror file" with There was a problem hiding this comment. Agree with @omesser that it's related the discussion above. Take a look at the top-level plots schema, where plots may be identified by either path or an arbitrary name. Feels like following a similar syntax may be best here. |
||||||
| ```yaml | ||||||
| stages: | ||||||
| train: | ||||||
| cmd: python train.py | ||||||
| deps: | ||||||
| - data.xml | ||||||
| outs: | ||||||
| - mymodel.pkl: | ||||||
| type: model # like this | ||||||
|
There was a problem hiding this comment. to make it symmetrical with plots, params, etc- why don't we make it: models:
mymodel.pkldo we plan / need other artifact types? (data can be covered by There was a problem hiding this comment. QQ: in this case, do you assume other fields can be specified like: models:
mymodel.pkl:
name: particles-classifier
description: best hits
labels:
- boson
- higgs? For now it looks like We also have a user asking if we could allow this to have a separate file, that's another "+" for having a There was a problem hiding this comment. I'm thinking it might make more sense to have a dedicated section for There was a problem hiding this comment. A top-level If we go this direction, the biggest question is whether to call it
There was a problem hiding this comment. Thanks for ideas. I've updated the docs page - please TAL. There was a problem hiding this comment. I think the This would reuse most of what we already have between:
I think we can mostly leave alone everything already implemented and only add this new top-level section. I would suggest that only things listed in There was a problem hiding this comment. It's in the right direction,I like it. by I would make it even simpler initially and do the first class citizen top level There was a problem hiding this comment. I think there are good reasons to generalize types. Besides those mentioned above in this thread and by users, we already support |
||||||
| ``` | ||||||
|
|
||||||
| You can also specify that while using DVCLive: | ||||||
|
|
||||||
| ```py | ||||||
| live.log_artifact(artifact, "path", type="model") | ||||||
| ``` | ||||||
|
|
||||||
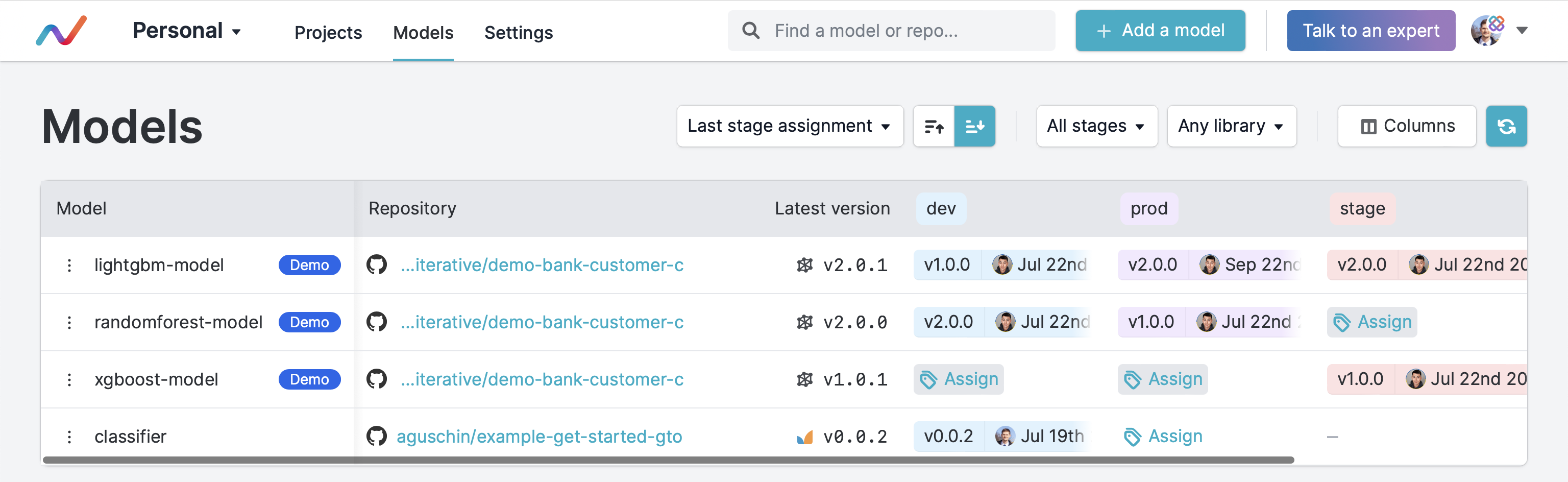
| This will make them appear in DVC Model Registry: | ||||||
|
There was a problem hiding this comment.
Suggested change
(Fo now,. it's still called Studio and not DVC.Cloud or similar) There was a problem hiding this comment. Thanks! Overall, let's keep the review scope to the level of ideas and user experience. We don't even know if this will be a separate page in DVC docs, or maybe we integrate it with some other page. There was a problem hiding this comment. yeah this is a nitpick 😉 but was hard for me to pass the opportunity and suggest |
||||||
|
|
||||||
|  | ||||||
|
|
||||||
| and make them shown as models in `dvc ls`: | ||||||
|
|
||||||
| ```dvc | ||||||
| $ dvc ls --registry # add `--type model` to see models only | ||||||
| Path Name Type Labels Description | ||||||
| mymodel.pkl model | ||||||
| data.xml stackoverflow-dataset data data-registry,get-started imported code | ||||||
| data/data.xml another-dataset data data-registry,get-started imported | ||||||
| ``` | ||||||
|
There was a problem hiding this comment. Does Studio need this, or is solely to provide a CLI option to view the registry? I don't think the latter needs to be high priority unless I'm missing some use case where you need to access it from the CLI. Not sure whether it can fit into There was a problem hiding this comment. By the way, do we define an artifact as any output that has a There was a problem hiding this comment.
If user would like to download a model locally, but not quite sure which one at the moment, he might want to see this. E.g. I don't remember the model name, but know labels or remember description. This OFC can be solved via Studio, and if we want to push users for that, that's also a decision. Another use case would be if you're investigating a repo that's not familiar to you (let's say your team has few repos or you look at another team's repo). Again, if we want to make people go to Studio every time for this, it a valid workflow, but IMO it makes you leave CLI and do extra things which can't be inconvenient.
Either that, or any input/output file DVC keeps track of can be an artifact (without There was a problem hiding this comment. Sounds good. Not sure I see enough to make it a p1 yet. WDYT? There was a problem hiding this comment.
It might also depend on the schema discussion below. If we have a |
||||||
|
|
||||||
| The same way you specify `type`, you can specify `description`, `labels` and | ||||||
| `name`. Defining human-readable `name` (should be unique) is useful when you | ||||||
| have complex folder structures or if you artifact can have different paths | ||||||
| during the project lifecycle. | ||||||
|
There was a problem hiding this comment. I think here we need 1 (concise) example setting all relevant fields dvc add models/mymodel.pkl --name def-detector --type model --description "glass defect image classifier" --label "algo=cnn" --label "owner=aguschin" --label "project=prod-qual-002" |
||||||
|
|
||||||
| You can use `name` to address the object in `dvc get`: | ||||||
|
|
||||||
| ```dvc | ||||||
| $ dvc get $REPO stackoverflow-dataset -o data.xml | ||||||
| ``` | ||||||
|
|
||||||
| Now, you usually need a specific model version rather than one from the `main` | ||||||
| branch. You can keep track of the model's lineage by | ||||||
| [registering Semantic versions and promoting your models](/doc/gto/get-started) | ||||||
| (or other artifacts) to stages such as `dev` or `production` with GTO. GTO | ||||||
| operates by creating Git tags such as `[email protected]` or `mymodel#prod`. | ||||||
|
There was a problem hiding this comment. I thought the stage tags always had some number like There was a problem hiding this comment. It can be |
||||||
| Knowing the right Git tag, you can get the model locally: | ||||||
|
|
||||||
| ```dvc | ||||||
| $ dvc get $REPO mymodel.pkl --rev [email protected] | ||||||
| ``` | ||||||
|
|
||||||
| Check out | ||||||
| [GTO User Guide](/doc/gto/user-guide/#getting-artifacts-in-systems-downstream) | ||||||
| to learn how to get the Git tag of the `latest` version or version currently | ||||||
| promoted to stages like `prod`. | ||||||
|
|
||||||
| ## Getting models in CI/CD | ||||||
|
|
||||||
| Git tags are great to [kick off CI/CD](/doc/gto/user-guide/#acting-in-cicd) | ||||||
| pipeline in which we can consume our model. You can use | ||||||
| [GTO GitHub action](https://github.com/iterative/gto-action) to interpret the | ||||||
| Git tag that triggered the workflow and act based on that. If you simply need to | ||||||
| download the model to CI, you can also use this Action with `download` option: | ||||||
|
|
||||||
| ```yaml | ||||||
| steps: | ||||||
| - uses: actions/checkout@v3 | ||||||
| - id: gto | ||||||
| uses: iterative/gto-action@v1 | ||||||
| with: | ||||||
| download: True # you can provide a specific destination path here instead of `True` | ||||||
|
There was a problem hiding this comment. Can you give an example? Will it download all artifacts in the repo? There was a problem hiding this comment. This should download the artifact, e.g. it will run There was a problem hiding this comment. Updated docs to explain this. |
||||||
| ``` | ||||||
|
|
||||||
| ## Restricting which types are allowed | ||||||
|
|
||||||
| To specify which `type`s are allowed to be used, you can add the following to | ||||||
| your `.dvc/config`: | ||||||
|
|
||||||
| ``` | ||||||
| # .dvc/config | ||||||
| types: [model, data] | ||||||
| ``` | ||||||
|
There was a problem hiding this comment. Do you think it needs to be part of the initial scope? I know it was requested, but it doesn't feel strictly necessary yet. There was a problem hiding this comment. Not necessary. I can make a notes in the docs page for what's extra for now, if that makes sense. |
||||||
|
|
||||||
| ## Seeing new model versions pushed with DVC experiments | ||||||
|
There was a problem hiding this comment.
Suggested change
Also, a question - is this an implicit behavior for artifacts with There was a problem hiding this comment. This only updated MDP, so this is only for There was a problem hiding this comment. I didn't, I'm a bit concerned for implicit behaviors, we should probably find a way to give the user control over what to do with which artifacts on exp push. wdyt? There was a problem hiding this comment. What example of implicit behavior you have in mind? Like There was a problem hiding this comment. yes, auto-pushing, exactly. maybe auto-versioning as well in the future (could be useful if running in the pipeline CI-CD as part of release. generate model, push it, and assign a version using GTO |
||||||
|
|
||||||
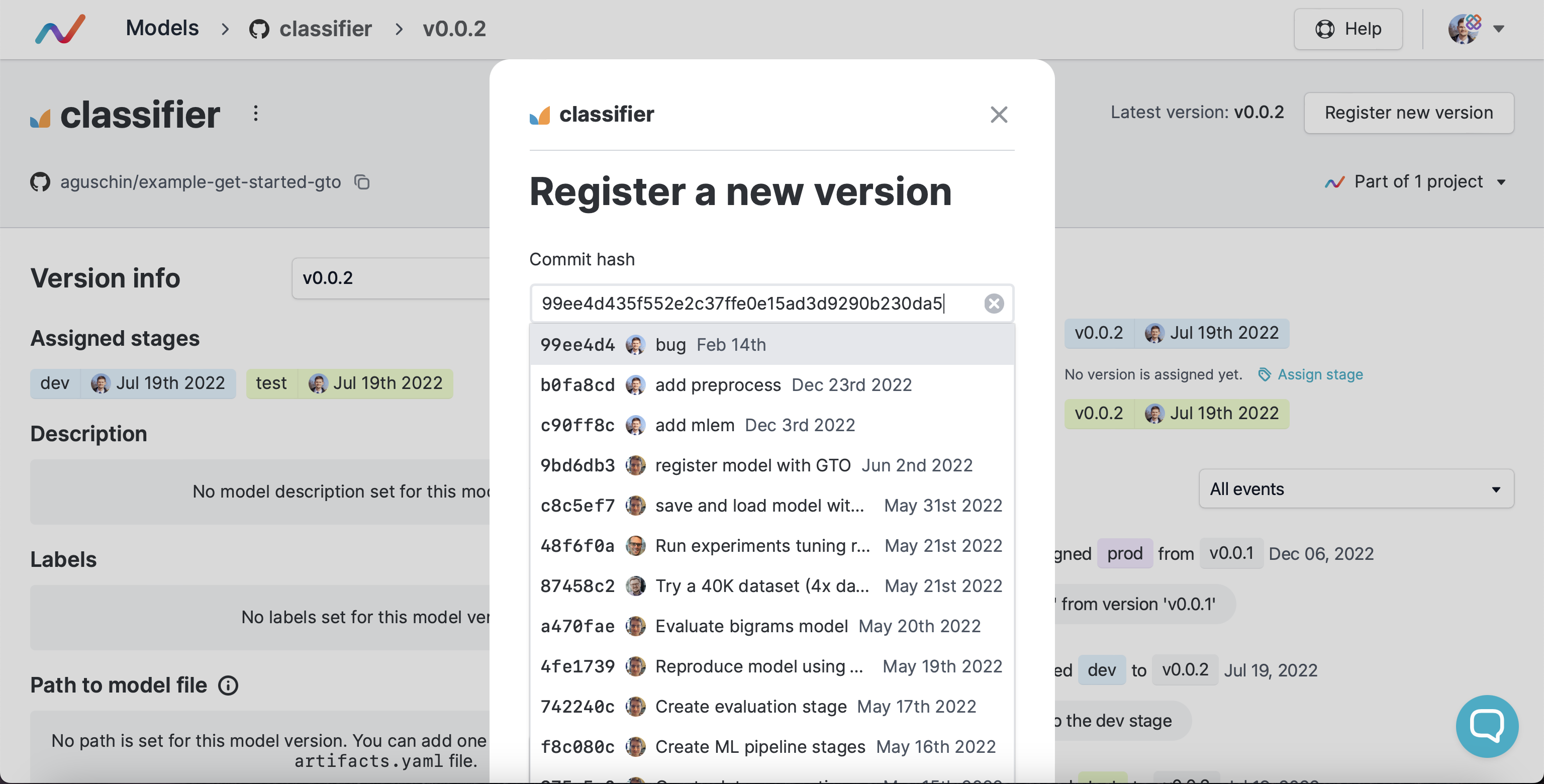
| After you run `dvc exp push` to push your experiment that updates your model, | ||||||
| you'll see a commit candidate to be registered: | ||||||
|
There was a problem hiding this comment. Do you think we should allow registration of unmerged experiments? Or maybe restrict what actions are available for them? There was a problem hiding this comment. Good question. Don't have a strong opinion. There was a problem hiding this comment. Btw, do we have an understanding how |
||||||
|
|
||||||
|  | ||||||
|
|
||||||
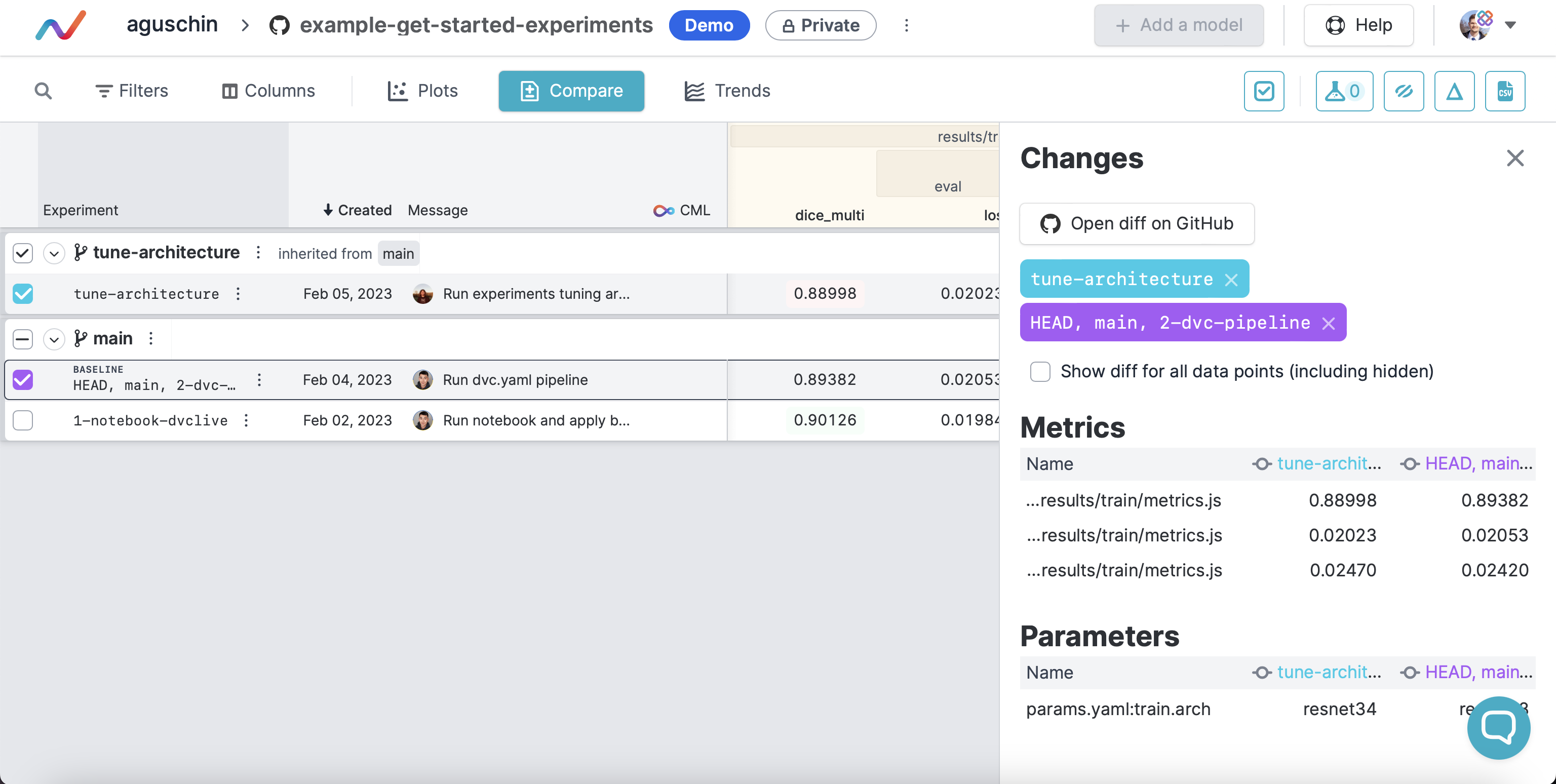
| In future you'll also be able to compare that new model version pushed (even non | ||||||
| semver-registered) with the latest one on this MDP. Or have a button to go to | ||||||
| the main repo view with to compare: | ||||||
|
|
||||||
|  | ||||||
There was a problem hiding this comment.
Choose a reason for hiding this comment
The reason will be displayed to describe this comment to others. Learn more.
HL:
Suggest to add sub-headers / sections
And structure for this page will be something like this: