perf: optimize lis_algorithm #1438
Conversation
I wrote this lis-based keyed algo even before Inferno existed [1] :) Inferno originally copy-pasted it from here [2]. And here [3] is the latest version that I am using. I've tried to use TypedArrays in this algo long time ago and at that time it was definitely slower on microbenchmarks in V8 (haven't tried to use 3 different types), with TypedArrays it would also makes sense to convert input array to TypedArray. Also, is it really worth to use 3 different typed arrays (8/16/32)? Call sites that accessing different typed arrays will be polymorphic. |
Cool :)
Not sure when this was, but there has been a period where some of these built-ins just weren't optimized in V8 at all. Here's a pretty interesting read on some of those issues not too long ago: https://dzone.com/articles/connecting-the-dots
You could initialize
Doh! This explains why performance degraded so much in my console tests when starting at a smaller size. I should just lock it all to |
Not sure, but I think that it would be better to use |
|
I went ahead and changed edit you beat me to it by a few seconds :) Int32Array seems fine as well. Nothing would ever go over that anyway. I'll adjust it. |
|
Another potential optimisation could be to hoist one typed array that is "virtually" partitioned into pages. var size = 1000 // start smaller (possibly only grows)
var memory = new TypedArray(size)
var page1 = 0
var page2 = size/2
// ... within the function
if (len > size) {
// grow
memory = new TypedArray((page2 = len) * 2)
} else if (size > len * 2) {
// possibly downsize
}Reading/writing from/to This relying on the heuristics that most apps normally have a single unchanging ceiling of average number of nodes within a a single subtree namespace. |
|
In my opinion it isn't worth to overcomplicate lis algo by hoisting and reusing arrays, it is hardly noticeable in the profiler when rearranging DOM nodes. DOM is the bottleneck :) |
|
It is a cool idea though and it could possibly cut time in half once more. But indeed I bet it's <1% of total already with DOM in the mix. |
|
There is a small mistake in the benchmark ( for (let i = 0; i < cnt; ++i) {
inputs[i] = generateList(len);
inputsSorted[i] = inputs[i].sort();
inputsReversed[i] = inputs[i].sort().reverse();
}Should be: for (let i = 0; i < cnt; ++i) {
inputs[i] = generateList(len);
inputsSorted[i] = inputs[i].slice().sort();
inputsReversed[i] = inputs[i].slice().sort().reverse();
} |
|
Good call! http://jsben.ch/MoAdv |
|
Hi @fkleuver thanks for this awesome PR! I remember I tested typed arrays when I converted infernos LIS implementation to use 0's instead of -1 for non existent vNode detection. That time typed arrays didn't perform very well but maybe this has changed. All the tests pass so lets merge this! :-) |
|
Let's see if Vue will steal this updated algo without credit....to be continued.... |
Let me start off by saying thank you for providing such an impressive library to the open source community and raising the bar on performance. Inferno is a great source of inspiration for many libraries including Aurelia.
We hope you don't mind that we borrowed your excellent
lis_algorithmand its usage for our repeater's keyed mode (which we made sure to acknowledge).I personally had a lot of fun figuring out how it all worked and tried to make it even faster, even though it is already very fast and a minor portion of the total cpu usage. I'd like to contribute back the end result of that exercise :)
Objective
This PR implements some perf tweaks for the
lis_algorithminpatching.ts. There are three aspects to this:TypedArray(this matters less in Chrome than in other browsers, but it still saves V8 the overhead of doing the optimization in the first place)Here is a simple benchmark: http://jsben.ch/puCMc (you can modify the
cnt(iterations) andlen(array size) variables at the bottom of the setup block to tweak the benchmark)Unfortunately I was unable to fully follow the instructions for contributing. For example, I couldn't find a
devbranch and the e2e tests failed to start on my machine.Expand for a code snippet to verify there are no regressions (can be pasted directly into browser console)
(edit: I pasted the wrong snippet, made it the same as the benchmark and removed the inline console perf measurement which gets skewed if executed like that)
I can add this to your tests if you'd like, I'm not sure where precisely it would fit in your test suites.
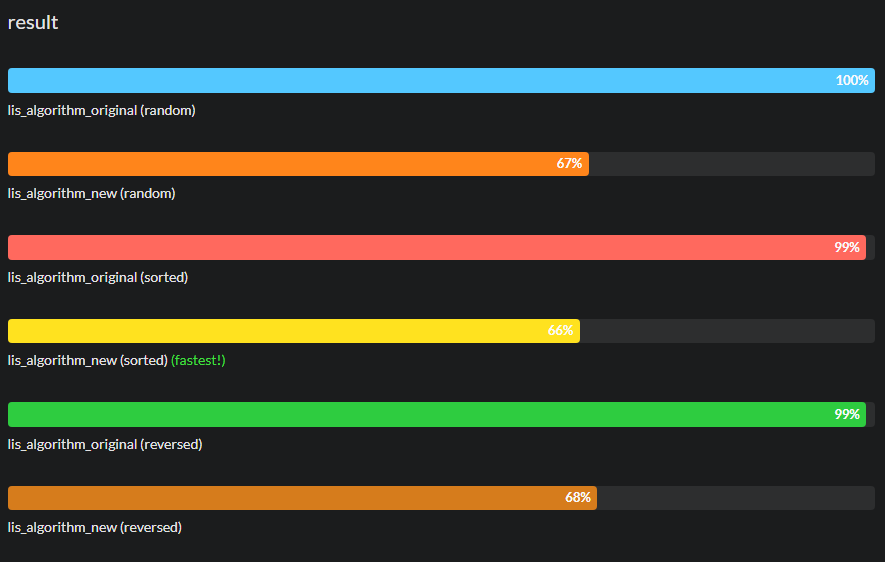
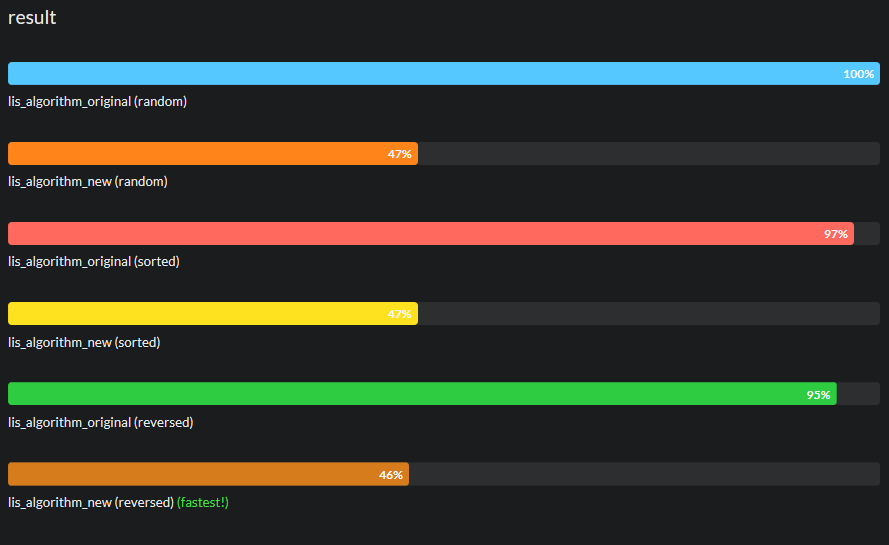
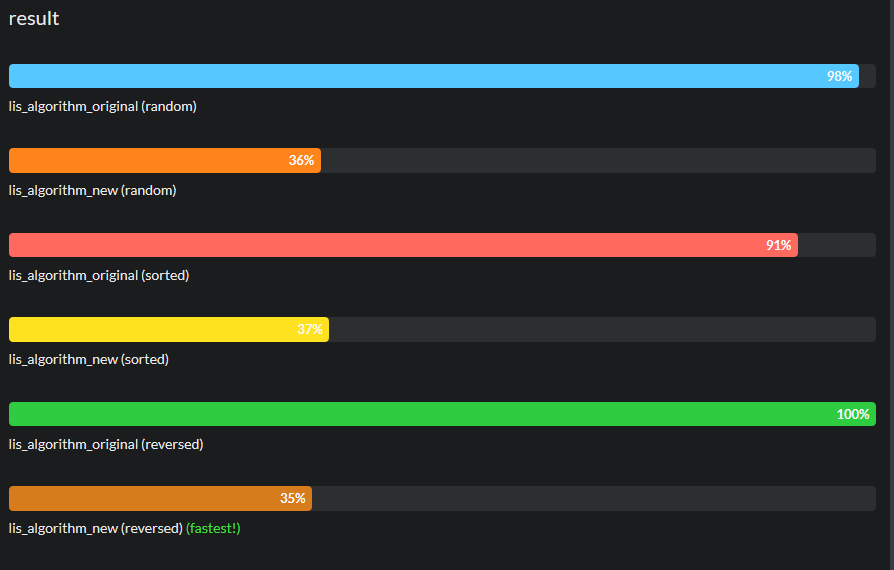
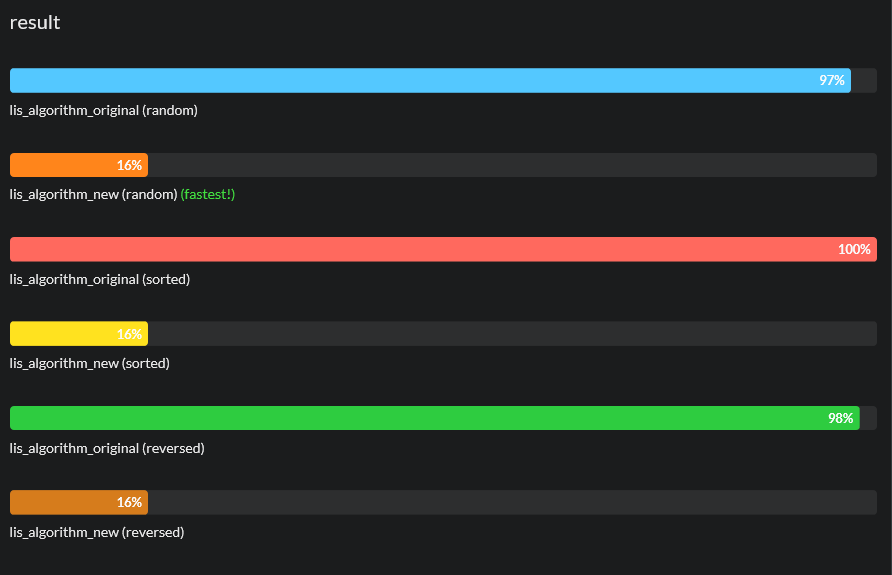
Expand for jsbench results for chrome, edge, firefox and ie11
chrome
edge
firefox
ie11
Let me know if you have any concerns or questions about the code.