token indices sequence length is longer than the specified maximum sequence length #1791
Comments
|
This means you're encoding a sequence that is larger than the max sequence the model can handle (which is 512 tokens). This is not an error but a warning; if you pass that sequence to the model it will crash as it cannot handle such a long sequence. You can truncate the sequence: |
|
Thank you. I truncate the sequence and it worked. But I use the parameter |
|
Hi, could you show me how you're using the Edit: The recommended way is to call the tokenizer directly instead of using the from transformers import GPT2Tokenizer
text = "This is a sequence"
tokenizer = GPT2Tokenizer.from_pretrained("gpt2")
x = tokenizer(text, truncation=True, max_length=2)
print(len(x)) # 2Previous answer: If you use it as such it should truncate your sequences: from transformers import GPT2Tokenizer
text = "This is a sequence"
tokenizer = GPT2Tokenizer.from_pretrained("gpt2")
x = tokenizer.encode(text, max_length=2)
print(len(x)) # 2 |
|
I use It works. I previously set |

|
Glad it works! Indeed, we should do something about this warning, it shouldn't appear when a max length is specified. |
|
Thank you very much! |
|
What if I need the sequence length to be longer than 512 (e.g., to retrieve the answer in a QA model)? |
|
Hi @LukasMut this question might be better suited to Stack Overflow. |
|
I have the same doubt as @LukasMut . Did you open a Stack Overflow question? |
|
did you got the solution @LukasMut @paulogaspar |
|
Not really. All solutions point to using only the 512 tokens, and choosing what to place in those tokens (for example, picking which part of the text) |
|
Having the same issue @paulogaspar any update on this? I'm having sequences with more than 512 tokens. |
Take a look at my last answer, that's the point I'm at. |
|
Also dealing with this issue and thought I'd post what's going through my head, correct me if I'm wrong but I think the maximum sequence length is determined when the model is first trained? In which case training a model with a larger sequence length is the solution? And I'm wondering if fine-tuning can be used to increase the sequence length. |
|
Same question. What to do if text is long? |
|
That's a research questions guys |
|
This might help people looking for further details facebookresearch/fairseq#1685 & google-research/bert#27 |
|
Hi, |
|
Most transformers are unfortunately completely constrained, which is the case for BERT (512 tokens max). If you want to use transformers without being limited to a sequence length, you should take a look at Transformer-XL or XLNet. |
|
I thought XLNet has a max length of 512 as well. Transformer-XL is still is a mystery to me because it seems like the length is still 512 for downstream tasks, unlike language modeling (pre-training). Please let me know if my understanding is incorrect. Thanks! |
|
XLNet was pre-trained/fine-tuned with a maximum length of 512, indeed. However, the model is not limited to such a length: from transformers import XLNetLMHeadModel, XLNetTokenizer
tokenizer = XLNetTokenizer.from_pretrained("xlnet-base-cased")
model = XLNetLMHeadModel.from_pretrained("xlnet-base-cased")
encoded = tokenizer.encode_plus("Alright, let's do this" * 500, return_tensors="pt")
print(encoded["input_ids"].shape) # torch.Size([1, 3503])
print(model(**encoded)[0].shape) # torch.Size([1, 3503, 32000])The model is not limited to a specific length because it doesn't leverage absolute positional embeddings, instead leveraging the same relative positional embeddings that Transformer-XL used. Please note that since the model isn't trained on larger sequences thant 512, no results are guaranteed on larger sequences, even if the model can still handle them. |
|
I was going to try this out, but after reading this out few times now, I still have no idea how I'm supposed to truncate the token stream for the pipeline. I got some results by combining @cswangjiawei 's advice of running the tokenizer, but it returns a truncated sequence that is slightly longer than the limit I set. Otherwise the results are good, although they come out slow and I may have to figure how to activate cuda on py torch. Update: There is an article that shows how to run the summarizer on large texts, I got it to work with this one: https://www.thepythoncode.com/article/text-summarization-using-huggingface-transformers-python |
You can go for BigBird as it takes a input token size of 4096 tokens(but can take upto 16K size) |
|
Let me help with what I have understood. Correct me if I am wrong. The reason you can't use sequence length more than max_length is because of the positional encoding. Let's have a look at the positional encoding in the original Transformer paper So the pos in the formula is the index of the words, and they have set 10000 as the scale to cover the usual length of most of the sentences. Now, if you look at the visualization of these functions, you will notice until the pos value is less than 10000 we will get a unique temporal representation of each word. But once it's length is more than 10000 representation won't be unique for each word (e.g. 1st and 10001 will have the same representation). So if max_length = scale (512 as discussed here) and sequence_length > max_length positional encoding will not work. . |
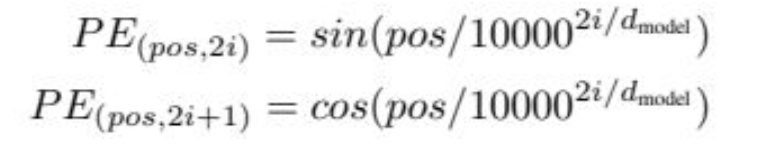
The code and weights for BigBird haven't been published yet, am I right? |
Yes and in that case you have Longformers, Reformers which can handle the long sequences. |
|
My model was pretrained with max_seq_len of 128 and max_posi_embeddings of 512 using the original BERT code release. |
How to apply this method in csv file i have csv file "data.csv" in 2nd column it contains news that to be pass in bert of 512 length |
|
I am trying to create an arbitrary length text summarizer using Huggingface; should I just partition the input text to the max model length, summarize each part to, say, half its original length, and repeat this procedure as long as necessary to reach the target length for the whole sequence? It feels to me that this is quite a general problem. Shouldn't this be supported as part of the |
|
Not sure if this is the best approach, but I did something like this and it solves the problem ^ summarizer = pipeline("summarization", model="facebook/bart-large-cnn")
def summarize_text(text: str, max_len: int) -> str:
try:
summary = summarizer(text, max_length=max_len, min_length=10, do_sample=False)
return summary[0]["summary_text"]
except IndexError as ex:
logging.warning("Sequence length too large for model, cutting text in half and calling again")
return summarize_text(text=text[:(len(text) // 2)], max_len=max_len//2) + summarize_text(text=text[(len(text) // 2):], max_len=max_len//2) |
i have tested and works great awesome |
|
Thanks to sfbaker7 recursive suggestion, i made a similar function for translating Hope this helps someone |
|
Found an elegant solution. If you study this line of the implementation of the For a specific task, use: pipeline(
"summarization", # your preferred task
model="facebook/bart-large-cnn", # your preferred model
<other arguments>, # top_k, ....
"max_length" : 30, # or 512, or whatever your cut-off is
"padding" : 'max_length',
"truncation" : True,
)For loading a pretrained model, use: model = <....>
tokenizer = <....>
pipeline(
model=model,
tokenizer=tokenizer,
<other arguments> # top_k, ....
"max_length" : 30, # or 512, or whatever your cut-off is
"padding" : 'max_length',
"truncation" : True,
)This has worked for me with |
|
I faced the same issue when using the fill-mask pipeline. The fill_mask.py does not consider any preprocess_params or keyword arguments, but can be fixed as follows: https://github.com/huggingface/transformers/blob/main/src/transformers/pipelines/fill_mask.py#L96 -> https://github.com/huggingface/transformers/blob/main/src/transformers/pipelines/fill_mask.py#L201 -> https://github.com/huggingface/transformers/blob/main/src/transformers/pipelines/fill_mask.py#L215 -> After that you can create a pipeline as follows:
I will add a pull request too! |
I tried it and it worked, I think the problem is fixed.. |
|
Hey everyone, Just a quick question: how can I shut this warning off I have figured out how to deal with large context-length with Bert models, so I want to switch off this error. |
❓ Questions & Help
When I use Bert, the "token indices sequence length is longer than the specified maximum sequence length for this model (1017 > 512)" occurs. How can I solve this error?
The text was updated successfully, but these errors were encountered: