大约在1990年,Tim Berners-Lee设计了构筑万维网(world wide web)基础的三大技术规范:为web提供文档格式化的超文本标记语言(HTML);为文档之间添加链接的Universal Resource Locators(URL)技术;为各机器在internet上传送文件的超文本传输协议(HTTP),这些技术的规范及实现都由CERN组织免费提供。
web世界快速发展,1993年,国家超级计算应用中心NCSA(National Center for Supercomputing Applications)推出了Mosaic浏览器,用户突然拥有了一个魅力浏览器,利用它可以在各个相互关联的文档之间进行网络冲浪了,伴随着用户量的激增,更多的创作者被web所吸引,更多的内容随之被传播。
在最开始,HTML只是一个简单的结构化文档格式,用来在文本字符串之间添加标签(tags)来指明文本的角色。例如:一个文本的字符串可以被标记为段落,同时另一些字符串可以被标记为可点击链接,这些元素在早期的HTML中,其逻辑性更胜其于呈现性。例如,HTML将会把一些文本标记为标题元素(heading),但不会描述标题(heading)元素该如何呈现。文本的呈现-包括使用字体、颜色、大小等主要由浏览器决定。
像CERN这样的科研组织更注重逻辑、结构和内容,而不是美学、意象和样式,这种结构化的观念反映到HTML设计中就表现为段落就标记为"段落"(paragraph),标题(heading)就赋予一个级别编号,以指明它们在文档结构中的地位(译者注: 如h1、h2这种标题编号)。
由于web吸引了更多的科研组织以外的人,web创作者们开始抱怨他们没有足够的覆盖原生页面外观的影响力,新的web创作者们最常抱怨的一个问题就是如何更改元素的字体和颜色。以下内容是1994年初发送到www-talk邮件列表的邮件摘要,由此可以看出web创作者们和浏览器标准制定者的紧张关系(我在本章中引用了发送给开发者社区的邮件消息列表,并将在后续章节中反复引用,邮件列表对于早期的网络社区聚集至关重要,邮件列表的超文本档案在20世纪90年代初快速崛起并发展壮大,10年后的今天,这些档案为web的设计和开发提供了宝贵的视角):
In fact, it has been a constant source of delight for me over the past year to get to continually tell hordes (literally) of people who want to – strap yourselves in, here it comes – control what their documents look like in ways that would be trivial in TeX, Microsoft Word, and every other common text processing environment: 'Sorry, you're screwed.'
事实上,在过去一年里,我不断的告诉那些成群结队(字面意思)的人——那些想要把自己绑在这里,试着像在Tex、Microsoft Word等常见文本处理软件那样在web上处理好文本展示的人:“哈哈,对不起,你完蛋了!”,这对我来说是一件无比搞笑的事。
这篇消息的作者是Marc Andreessen,他是流行浏览器——NCSA Mosaic背后的一名开发者,后来他成为了网景浏览器(Netscape)的联合创始人,网景浏览器通过在HTML中引入表示性的标签来满足创作者们的需求。1994年10月13日,网景公司发布了他们的第一款beta版浏览器,网景浏览器支持一组新的表示性HTML标签(如居中标签:center),不久,更多的同类标签加入进来。
通过向html中添加表示性标签,它从一种抽象的、结构化的超文本标记语言(创作者们为文本标记不同的逻辑性角色(段落、标题、列表等)),演变为强调文档的最终呈现方式(字体、颜色和布局)的具体的表示性语言。 在传统的印刷出版时代,读者会收到经过处理后的成品印刷物,印刷物上的每个文字都有其固定的位置、形状、大小和颜色,读者无法更改其展现方式。然而,电子文档是半成品,必须经过装配(assembly)处理后才能呈现给人类读者,装配过程中(常被称为格式化(formatting)过程),对如何呈现文档提供了多种多样的选择性。例如:浏览器在彩色屏幕上呈现文档时必须要选择要使用的字体和颜色。电子文档所需处理的等级将会因文档的不同格式而有很大的差异,电子文档类似于家具:有些家具已事先预装好,而有些家具买来时只是一个个打包的平面板子,需要买主自己组装好。如果一方文档需要做大量的处理,我们称其为较高级别的抽象,如果一份文档只需要少量的处理,我们则称其为较低级别的抽象。 确定合适的抽象级别是文档格式设计的重要环节,如果抽象的级别较高,创作和格式化的复杂度也会随之增加,创作者必须涉及到不可见的抽象概念,在接收端,如果元素的抽象级别较高,浏览器必须把高度抽象的元素转变为具体的对象,这将变得非常复杂,不过高级抽象也并非没有好处,它的好处是便于在多处上下文中复用,例如:标题元素可以在印刷文档中以大写字母的形式呈现,并且标题元素在文本朗读系统中将会具有更大的声音。 相反,较低的抽象级别将会使创作和格式化过程变得更加简易(在某种成都上来说),创作者将会使用所见即所得的富文本编辑工具(WYSIWYG),并且浏览器在呈现视图的过程中也无需执行复杂的转换任务,使用“面向表现对象”的文档格式的缺点是——内容在其它上下文中难以复用,例如:难以在不同屏幕尺寸的设备上实现“面向表示对象”的内容,也很难让视力障碍者获取“面向表示对象”的内容。 将文档从一种格式转换为另一种格式时,两种格式可能处于不同的抽象级别,通常,可以将文档从较高级别的抽象转换为较低级别的抽象,但反之则不行。本论文将介绍一种度量抽象级别的“抽象阶梯”。
在HTML中引入表示性标签是“抽象阶梯”的向下移动,其中一些新元素(如闪烁标签(BLINK)等)仅对特定的输出设备有意义(毕竟,文本朗读系统中无法表示闪烁性文本)。HTML的创建者希望HTML的标签可以在多种设置中生效,但表示性标签威胁到了设备的独立性、可访问性和内容的复用性。 将HTML开发为面向表示的语言也改变了创作者和用户之间的权力平衡,结构化的文档在呈现之前必须经过浏览器的格式化处理,而用户可以在某种程度上影响到格式化处理过程,然而,如果用户取得的文档是最终形态的(已完成了格式化),用户就无法影响到文档了。 web创作者们要求自己能对文档产生更大的影响力,并一直对这种改变翘首以盼,但在社区中也存在着很多持反对意见的人,许多人认为,在读者(而不是出版商)掌控的情况下,网络可以实现更具个性化的潜力,内容应该根据读者的偏好进行选择,多媒体和呈现的形式也应该是读者的选择。通过将html转换为表示性语言,有可能失去实现以用户为中心的“出版”模式的自由度。
在HTML由结构化语言演变为表示性语言的过程中,样式表作为一种替代方案被提出。术语“样式表”是传统出版体系中用来确保文档一致性的一种方法[芝加哥 1993],在传统出版过程中,会在手稿上附带一份样式表,作为特定手稿措辞及语言规则的连续记录[Brüggemann-Klein&Wood 1992]。
20世纪80年代,随着个人电脑的普及,出版业发生了巨大的变化,电子出版提供了一些工具,可以简化从创作、编辑到打印的全部出版流程。在电子出版中,术语“样式表”是指一组关于如何呈现样式的规则,而不是如何创作内容的规则,样式表将由设计师指定,并在打印前发送给排字机,通常,它用来描述以文本为中心的文档布局及视觉展示(包括字体,颜色,空白)。
在本文,术语“样式表”指代一组规则,这些规则将文档元素中的样式属性和值与结构元素相关联,从而决定如何展示稳定。样式表通常不包含内容,可以在文档中相互关联,并且可以在文档中复用,这种定义就允许了“样式表”可以在电子出版和web世界中使用。
大约从1980年开始,样式表开始在电子出版系统中被使用(参加第2章和第3章),与结构文档相结合后,样式表提供了内容和表示的延迟绑定(late binding)[Reid 1989],意即:内容和表示在创作完成后才合并,这个理念吸引出版商的原因有以下两点:首先,可以在一系列的出版物中实现一致风格,其次,创作者再也不用担心内容的展现方式了,他们可以专注于内容本身。
事实上,一些作者发现在创作过程中不必担心细节表示是一种解放[Cailliau 1997],然而,大多数作者最终使用了强调表示而不是结构的创作系统。
所见即所得 —— 是一种文档创作的矛盾模式,所见即所得程序不断更新最终的呈现方式,当创作者输入时,屏幕将会更新以反映该点打印文档时将呈现的页面布局。
和结构文档与样式表所采用的样式与内容的延迟绑定相比,所见即所得模式提供了即时绑定。所有的编辑操作都会即时更改最终的呈现。这种方案通常会导致作者过分强调文档的最终呈现(通常是打印文档),而不是逻辑标签。
一些应用程序尝试将结构化文档和所见即所得的编辑模式相结合,包括Adobe的FrameMaker[FrameMaker]、Microsoft的Word[MS-Word]和W3C的Amaya[Amaya],通常这些应用程序会为创作者提供文档的几个视图view,其中之一是所见即所得视图,其它视图为更具结构化的视图,这将使创作者通过所见即所得工具创作结构性文档,然而,使用所见即所得工具也存在风险:它们允许创作者进行纯粹的展示性文档修改时,会影响到文档结构的稳定性。
研究表明,当以文本印刷为最终目的进行创作时,很难激发创作者在逻辑层面而不是视觉层面的创作热情,然而,随着web的出现,内容的可复用性得到增强,web文档不再局限于纸张上打印和分发了,而是通过电子形式传递到用户电脑上,文档分发转变为电子文档形式影响到了创作过程和样式表语言,其具有如下几个关键特征:
-
延迟绑定变为延后绑定:在web上,文档以电子的形式传递到用户加算计上,电子出版中内容与呈现形式间的延迟绑定在web上变得更晚了,这种绑定不再发生于出版社,而是发生在用户的计算机上,这种转变增加了呈现的自由度,但随之也带来了新的性能挑战,因为在“延后绑定”进行时,用户只得默默等待,此外,因为创作者不在最终呈现的现场,他没法保证最终的呈现是正确的。
-
以纸张为中心的出版模式转变到以屏幕为中心:在web出现之前,大多数电子文档最终都处理成打印文档,它们在计算机屏幕上完成编辑和处理流程,但它们大多在最后被处理成打印媒体格式,毕竟,在web上,大多数用户在屏幕上浏览文档。
-
单一传输转变为多元输出:尽管屏幕是web世界中的主要媒介,但也存在着很多其它类型,创作者无法知道用户到底使用哪种类型的输出设备,不再只有一个终极呈现形式,而是有很多个,因此,样式表必须能在各种输出设备上都能描述呈现方式。
-
创作者控制转变为传作者和用户的共同控制:由于内容和展现间的绑定发生于用户的计算机上,来自多个源头的影响可能组合形成为一种展现形式,考虑到这种自由性,用户以及创作者一个都有影响文档展示的能力,基于用户需求和偏好的个性展现成功可能,这将与其它发布模式产生区别,在其它发布环节中,创作者和出版社完成垄断了文档的展示。
-
独立稳定转变为超链接:web是个大量超链接文档的集合,以前表示为引用信息的文本现在表示成一个个超链接。
-
确定的传输转变成不确定:web资源广泛的分布在各种连接在一起的计算机上,资源不能用的可能性很高。另一个变化是,web比出版社的出版系统更可能失败,虽然使样式表可用时自然而然的,但可能资源并不总是会在客户端上可用。
因此,随着web的引入,样式表的重心由创作过程中的创作者工具转移到内容生成后的内容复用工具,web上的样式表可能比以纸张为中心的样式表更为重要,因为内容的复用可能性更大,正如样式表的性质由纸质出版转变为电子出版一样,web的样式表性质也发生了改变。
在CERN的NeXT设备上,第一个粗糙的样式表被硬编码到了在其上实现的第一个WWW客户端,但是,没有规定样式表的编写的规范,也没有指明样式表的语法规则,每个浏览器各自把页面以他们认为最好的呈现方式展示给用户。
在web上使用样式表的潜在好处是显而易见的,和不断改进的HTML相比,一个开发良好的样式表应给予创作者期望的更丰富的风格词汇,此外HTML还会 继续保留结构化的语法,以便它能运行在各种设备上。
因为这些原因,www-talk邮件列表(早期进行电子交流的网络社区)上的许多人都一致认为电子表将给web带来好处,但是,社区对于web是否需要一种新的样式表语言,或者采用现存语言中的一种(专为纸质出版而设计的)更合适,还存在着分歧。
1993年,几种专为web设计的样式表语言被提出(参见第四章: 网络样式表提案),但它们最终都没获得成功,主要原因是因为它们没能获得浏览器的支持,只要Mosaic浏览器(迄今最流行的浏览器)不支持哪种样式表,创作者就没有使用它们进行编写的动力,此外,这些提案都没能发展成稳定版,一份成功的web样式表必须做到既能激发浏览器开发者的开发热情,又能激发创造者的创作热情。
在网景(Netscape)公司宣布他们最新浏览器的3天前,css开发者发布了web世界上的第一版css提案(Cascading HTML style sheets的缩写名)[lie 1994],除了描述字体、颜色和文档布局之外(有几个提案已经完成),CSS还引入了几个全新功能来强调web发布的改变,CSS的设计理念旨在允许创作者和用户都能对文档展示做出影响:
The proposed scheme supplies the brower with an ordered list (cascade) of style sheets. The user supplies the initial sheet which may request total control of the presentation, but – more likely – hands most of the influence over to the style sheets referenced in the incoming document.
该提案为有序列表(级联)提供了样式,用户提供初始样式表(该样式表可能会完全控制文档的展示),但更可能的是,大部分的文档展示还是交友文档中自身引用的样式表。
达成创作者和用户之间的成功谈判是CSS的主要愿景之一,如果成功,创作者将获得他们在文档展示上应有的影响力,不会觉得的他们是被迫来展示HTML和其它技巧,另一方面,用户可以自由的文档展示,他们既可以选择创作者制定的样式展示,也可以选择自己的样式展示。
其实在大多数情况下,创作者不会和用户产生冲突,当二者都不想给文档指定特定样式时,浏览器就必须带一个默认的样式表来对HTML进行默认展示,因此,关于CSS的定义将会有三个来源:创作者、用户、浏览器,CSS能够将这三者合并后来进行最终的文档渲染,我们将处理这几种样式的组合 — 解决三者之间可能出现的冲突的过程称之为“串联|级联(cascading)”。
第一版css提案是本着公开交流web如何发展的精神而提出的,并且在公开的邮件列表中进行了讨论,许多人[Bos 1994][Behlendorf 1994][Wei 1994]对该草案做出了回应,促进了草案的进一步发展,在1995年期间,共发布了大约8次修订,该年12月份发布的最后一次修订版被选为稳定版,并鼓励浏览器厂商将该版本作为基础实现标准。
除了一些小的意外错误,19995年12月份发布的草案在语法上基本上稳定保持了下来,其中第一份部分关于css语法的介绍依然保持下来:
Designing simple style sheets is easy. One only needs to know a little HTML and some basic desktop publishing terminology. E.g., to set the text color of 'H1' elements to blue, one can say:
H1 { color: blue }The example consists of two main parts: selector ('H1') and declaration ('color: blue'). The declaration has two parts, property ('color') and value ('blue').
设计简单的样式表很容易,你只需知道一点HTML知识和一些基础的桌面出版术语,例如,要将'H1'标签的文本颜色设置为蓝色,可以这样说:
H1 { color: blue }该例子包含了两个主要部分:选择器(h1)和声明(color: blue),声明分为两部分:属性(color)和属性值(blue)。
1996年12月,CSS1规范成为W3C的推荐标准[CSS1 1996]。1998年5月,CSS2成为W3C推荐标准[CSS2 1998],第6章(层叠样式表)将会更详细的叙述其发展史。
在第一版CSS天发布十年后,所有的主流web浏览器都支持了CSS,并且大多数网页都使用CSS,全面评估CSS本身及其对web的影响可能还为时尚早,但我们可以学习和研究css的设计,将其与其它样式表语言和香港方案做比较。
在文的本章节中介绍了一些关键概念,HTML是为web开发的一种简单的结构文档格式,当web创作者要求他们能对文档产生更多的表示性影响时,HTML开始发展成为一种表示性语言,而不是一种结构化语言,为了让抽象阶梯停止向下滑动,CSS被开发为web的样式表语言,自1980年以来,样式表一直是电子出版系统中的一部分,在web上,样式表的焦点从创作过程中的工具转移到内容生成后的内容复用工具。
本文将详细地探讨为什么web需要不同于其它发布类型的样式表语言,以及这门语言是如何被设计出来的,然而,在探讨之前,还有必要探讨另外两个议题:首先,必须要理解结构化文档,因为样式表是应用在结构化文档之上的,其次,必须研究在web出现之前,样式表语言的发展情况,以此来确定这些样式表语言是否适用于web,这两项议题将分别在第2章和第3章中讨论。
样式表语言和结构化文档相互依赖,没有样式表,结构化文档将无法呈现,反之,没有结构化文档,样式表将无用武之地,因为二者的紧密关系,在学习样式表语言前,务必理解结构化文档。本章节将讨论一些对样式表语言产生了最多影响的结构化文档。
在一部名为“结构化文档”的重要著作中[André, et al. 1989],其主题思想是:
A document may be described as a collection of objects with higher-level objects formed from more primitive objects. The object relationships represent the logical relationships between components of the document. For example, the present document is described as a book at the highest level. The book is subdivided into chapters, each chapter into sections, subsections, paragraphs, and so forth. Such a document organization has come to be known as the structured document representation.
文档可以被描述为由更原始的对象形成的更高级别对象的对象集合,对象之间的关系也可以表示为文档组件之间的逻辑关系,例如:本文档可以被描述为更高级别的书本,书本可以拆分成为章节,每个章节又可以拆分为小节,段落等,这种组织文档的方式就被称之为结构化文档展示。
结构化文档展示性的一个重要特征在于它具有确定的抽象级别,当样式表与结构化文档相结合形成展示时,确定抽象的级别是尤为重要的。因此,本章第一部分将讨论抽象文档的抽象级别,并提出一个叫“抽象阶梯”的概念来度量web文档格式的抽象级别。
本章的第二部分将介绍几种开创性的抽象化文档系统:Scribe、LaTex、开放式文档架构(ODA)、标准通用标记语言(SGML)、超文本标记语言(HTML)、可扩展性标记语言(XML),针对每个系统都会在其历史和技术上进行简要介绍,并着重介绍它们与样式表语言之间的关系。
第三部分将讨论web中语言转换和样式表语言之间的关系。
在早川一会(Hayakawa [Hayakawa 1940])的 ——《思想与行动中的语言》(Language in Thought and Action)一书中,他提出了语言的抽象阶梯概念,抽象阶梯的最底部就是一个纯粹的对象(object),早川用了一头叫“贝西”(Bessie)的奶牛做例子,奶牛是由肌肉、骨骼、皮肤和其它有生物质组成,登上抽象阶梯的第一步,让我们先忽略奶牛内部的生物属性,保留它的物质属性,如:颜色、尺寸、形状,我们称它为贝西(Bessie)——贝西是成千上万头被归类为奶牛的对象之一,在贝西居住的农场还有其它种类的多种动物,我们称其为牲畜,继续向上攀爬抽象阶梯,可以对应到农场的资产和财富,这个概念如图1所示:
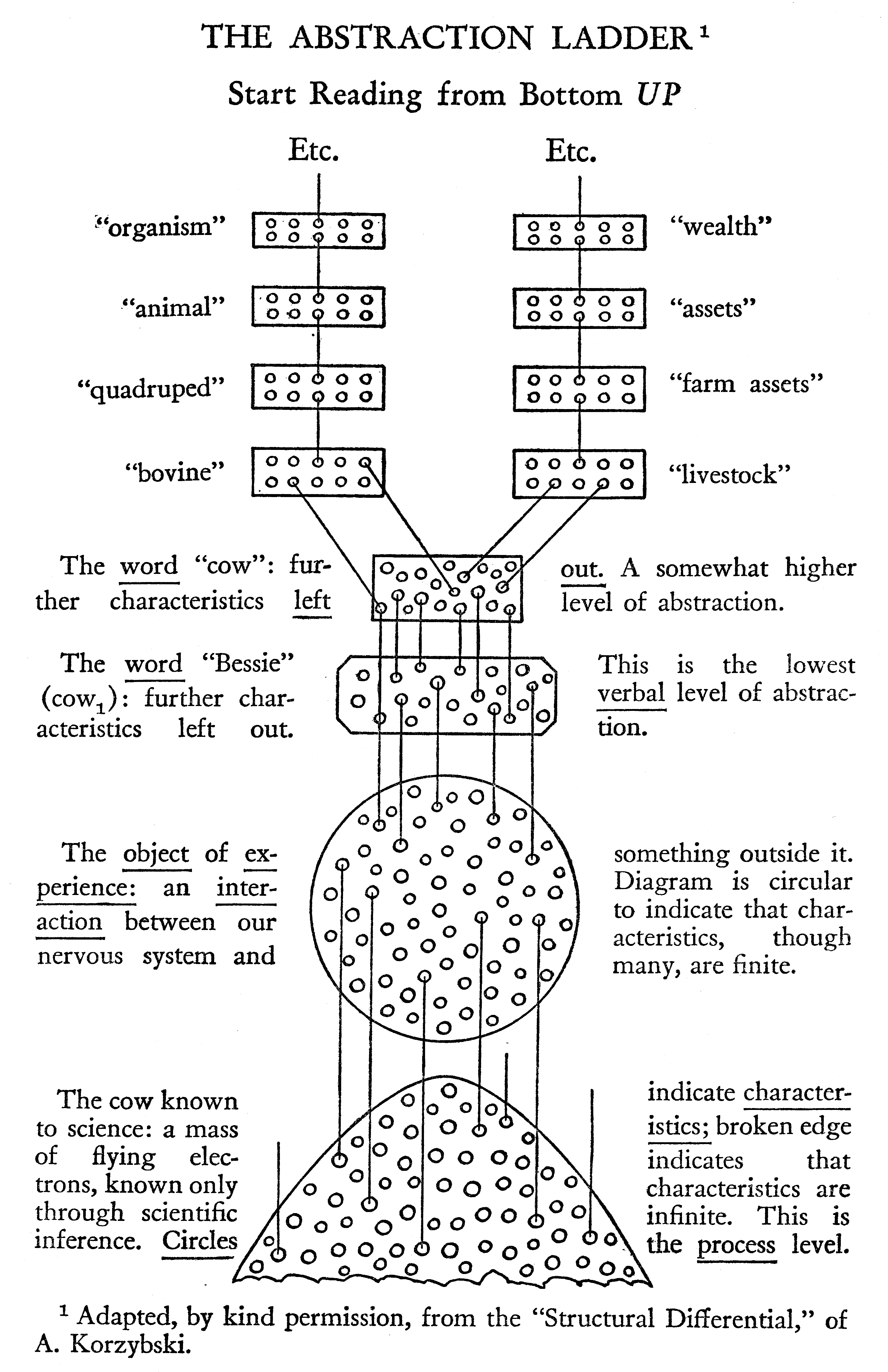
类似的抽象级别例子可以在计算机网络系统中找到,1983年,国际标准化组织(ISO)开发了一种称为开放式系统互联(OSI)的网络模型,该模型定义了计算机通信的框架,ISO/OSI参考模型分为七层,每层都有不同的抽象级别,它们分别是:物理层、数据链路层、网络层、传输层、会话层、表示层、应用层。
我相信抽象阶梯的概念在评估文档格式时有用的,文档在抽象阶梯上的高度决定了它在格式化为展示性文档的复杂度,由于文档的格式化是由样式表决定的,因此抽象级别是样式表成功的关键性特征。
阶梯的垂直性对应了人们描述抽象级别时的高-低特性,高度抽象的文档格式的典型特征是:
- 信息必须经过处理后才能展示出来,例如:为了以可视化的方式渲染一份HTML文档,语句必须拆分为行,必须指定其字体,并且字符必须转换为栅格化字形。
- 信息必须具备以多种不同方式处理并呈现的可能性,以可视化方式展示文档只是众多可能性的一种,其它的包括听觉渲染和盲文嵌入。
- 信息的展示比较紧凑,展示一个8位编码的字符比表示同等字符的图片更紧凑。
相反,用较低抽象级别编写的文档只需较少的处理便能展示,它们拥有较少的展示灵活性,并且不太紧凑。
另一个重要的观察结果是 —— 在抽象阶梯上通常可以对文档进行向下转换,但按相反方向转换则困难得多[Lie&Saarela 1999],例如:图形化web浏览器——视窗协作系统,将文档栅格化为像素点,以此实现了在抽象阶梯上的向下移动信息,而OCR软件试图将图像转换为文字,以此来攀爬抽象阶梯实现向上移动信息,但OCR系统只能工作在特定的场景中,并且容易出错。同样,由于停机问题,不可能设计出一种算法——它能实现用图灵机语言编写的文档的转换任务。
在web文档格式的上下文中,我认为可以用如下几个标准来确定抽象阶梯的级别:
- 文本是否能供人类阅读,意思是说:如果把文档展示给人类读者,ta能否阅读文档
- 文本是否能供机器阅读,意思是说:文档格式中是否有字符编号概念,还是文本被展示成了图片——在这种情况下,文本不可“阅读”。
- 文本的逻辑顺序是否被保留,意思是说:用这种格式编写文档时,是否保留了内容在逻辑上的阅读顺序概念。
- 文档是否可伸缩,意思是说:在不借助人造视觉器(译者注: 类似放大镜)的情况下放大文档。
- 是否有回流(reflow)可能?意思是说:文本是否可能被回流为行、列、页面?
- 是否可以展示各种文本元素的角色?例如:创作者是否能将一部分文本标记为标题、段落,或者计算机程序中的变量名,能否对这些元素的角色进行区分是很重要的,例如:在以盲文的形式制作文档时,某些文本应该进行缩编(例如标题),而其它文本则不用特殊处理(例如变量名)。
- 文档格式是否与设备无关联,意思是说:文档使用该格式进行(译者注:这里是指web文档格式)编写后,能在不同的设备上展示出来(例如:打印机、屏幕、盲文打印机和文本合成器),亦或只能展示于单独的设备类型?
- 文档格式是否包含特定的程序语义?HTML是一种通用的文档格式,它并不试图描述来自更专业领域(如数学和化学)的语义,因此也不会包含特定应用程序的语义,包含特定应用程序语义的格式往往处于抽象阶梯的更高层。
表1:抽象阶梯上各文档格式的对比
| GIF, PNG | private XMLvocabulary | XSL-FO | HTML | MathML | ||
|---|---|---|---|---|---|---|
| 文本是否供人类阅读? | yes | yes | yes | yes | yes | yes |
| 文本是否供机器阅读? | no | yes | yes | yes | yes | yes |
| 文本是否保存逻辑顺序? | unknown | unknown | no | yes | yes | yes |
| 是否可缩放? | no | unknown | yes | yes | yes | yes |
| 是否有回流可能? | no | unknown | no | yes | yes | yes |
| 是否有角色概念? | no | no | no | no | yes | yes |
| 不依赖特定设备? | no | no | no | no | yes | yes |
| 是否包含特定的程序语义? | no | no | no | no | no | yes |
表1为我们展示了各文档格式在抽象阶梯上的相对位置,如下是表1的注释:
- GIF[GIF 1990]和PNG[PNG 1996]是位图图片格式,而不是文档格式,但图片常被用来展示文档,将文档以传真机传输就是一个常见的例子(web之外)。
- PDF[Adobe 1993]是Adobe公司开发的文档格式,PDF是一种面向展示的格式,没有段落和标题概念。许多用户在尝试从PDF文档中复制多列内容时发现 — 当选择文本时,选择区域将跨域多列,导致文档中多个部分的文本将混合到同一选择中。PDF的最新版新加了保留文档逻辑结构的功能[Adobe 2001]。
- XSL-FO 是根据XSL规范[XSL 2001]定义的格式化对象组合成的文档。关于XSL-FO将在后续章节讨论。
- XML[XML 1998] (包括几种新的XML格式)也一同包含在上表中,它指使用私有XML词汇发布的文档,这些文档的语义内容不被普遍知晓的。
- HTML评级基于最好的设计方案,在该方案中,创作者使用语义化元素,而不是通过使用定位或表格等特性来改变元素的阅读顺序。但但多数HTML并不会遵循该方案。
在建立了以抽象阶梯作为结构化文档格式的度量工具之后,下一节将更详细地讨论架构话文档系统。
大约从1980年开始,电子出版和结构化文档领域出现了一个活跃的研究社区,该社区在电子出版会议议程、《电子出版-起源、传播、设计》杂志[电子出版社]上发表他们的研究成果,剑桥大学出版社还出版了一系列关于这一主题的书籍。Richard Furuta列举了文档预编系统历史上重要论文的重要部分: 基础资源[Furuta 1992]
研究人员通常赞同开发商对文档格式进行中立化处理,因为这可以促进文档的交换,这也便于更好的理解格式化文档,但是对结构化文档的处理还有其它几种方案,这几种方案互相竞争而开发,本节将讨论这四种方案:
20世纪70年代末,布赖恩·里德(BrianReid)开发了Scribe[Reid1980]。Scribe开创了结构化文档的概念,并对创作过程中的逻辑标记和展示模版进行了强制性区分,Scribe的设计哲学在 莱斯利·兰伯特(Leslie Lamport)的LaTex得到了延续,LaTex首次发布于1985[Lamport 1985]年,它是纳德·克努特(Donald Knuth)开发的Tex程序上的一个顶部宏包(macro package),该宏包在Tex中负责底层格式化。
开放式文档结构 (ODA) 是一套ISO标准,它用来促进文档的电子化交换,ODA文档既可以以逻辑化形式也可以以表示性形式展示文档。
标准通用标记语言(SGML) [SGML 1986]及其前身GML是由Charles Goldfarb及其同事在1970年代和1980年代[Furuta等人]开发的。1986年,SGML成为ISO标准。
本节将介绍这六种文档系统(Scribe、LaTeX、ODA、SGML、HTML和XML),在讨论它们之前,以非正式的形式列出这六种系统的设计雄心和分别取得的成就可能对我们更有帮助(参见表2)。
表2:6种不同的结构化文档系统的野心和成就
| Is primarily a system to define new languages? | Has notion of document semantics? | Has notion of document presentation? | Enco-ding | Reference | Level of complexity | Main achievement | |
|---|---|---|---|---|---|---|---|
| Scribe | no | yes | yes | text | implementation | moderate | inspired LaTeX |
| LaTex | no | yes | yes | text | implementation | moderate | de facto format in scientific publishing |
| ODA | no | yes | yes | binary | specification | high | became ISO standard |
| SGML | yes | no | no | text | specification | high | became ISO standard, inspired HTML and XML |
| HTML | no | yes | some | text | specification & implementation | moderate | universally understood hypertext format |
| XML | yes | no | no | text | specification | moderate | syntactic basis for emerging formats |
关于文档格式更为正式的分类,请参考《 The Origin of (Document) Species》
除了表格2中列出的成就外,所有的系统都应该感谢它们激励了创作者和程序员,让他们看到了结构化文档的好处。 下面关于各种结构化文件系统的讨论并没有遵循一个严格的模式。这些系统对它们的理解、它们的使用情况、以及目前关于每个系统的可用信息方面有更大的区别。这些描述的主要目的不是进行比较分析,而是讨论这些语言的某些方面,这些方面是作者在样式表的上下文中感兴趣的部分。
抄写系统是于20世纪70年代末由卡内基-卡梅隆大学的 Brian Reid 开发而成,抄写系统开创了结构化文档的创作方法。它鼓励创作者使用预定义的逻辑对象,作者通过不需指定任何格式就可以生成最终形式的文档。
近些年,抄写系统发生了很多改变。这一章我们将讨论一份于1980年编写的抄写系统用户描述手册,该手册试图给出抄写系统的大概论述,而非所有功能的介绍。、
一份抄写文档可以非常简单:
@Make(Text)
@Device(Diablo)
@Heading(Comrades and Strangers)
上面的示例使用到了抄写系统的三个关键性概念:文档类型、命令和格式化环境。第一行从一组不同类型的文档类型中选出一个特定的文档类型(Text)。第二行是一个命令,它指定文档应该在特定的设备上打印。第三行指定某个字符串(Comrades and Strangers)是文档的标题。