cmd/pprof: macOS 12.6.1 profile overcounts system calls (again) #57722
Comments
|
Testing on an Intel MacOS (MacOS 12.6.1) go version
go env
I'm a bit of a go noob (start during advent of code lol), so I wasn't able to set up the UI you used but my IDE's built in pprof output looks similar to yours. If you want the matching profiler UI and send me a how-to link I can set it up :) TestInterleavedIO TestSequentialIO |


|
@cbedard thanks, this looks like Intel Macs have the same issue. The UI doesn't matter, this is fine :). |
|
@golang/runtime |
|
It would not surprise me if darwin has unfair SIGPROF delivery. e.g., if the system call return path updates the CPU timers, it may be more likely to trigger overflow and deliver SIGPROF to itself vs threads that do not make system calls. |
|
I think this could be tested with a simple C program. Two threads, one running a busy loop, the other with a busy loop that makes a system call. Do they both receive ~50% of SIGPROF signals? |
|
I haven't read the sample code. Just wonder, for the "interleaved" case, are the compression and I/O running concurrently on different goroutines/threads, or they are on the same thread but just interleaved? If the latter, do you know what frequency or time period the interleaving is, and is it faster than the profile sampling frequency (100 Hz)? Thanks. |
It's the latter. But I suspect that there could be concurrent/parallel read-ahead happening on the OS level.
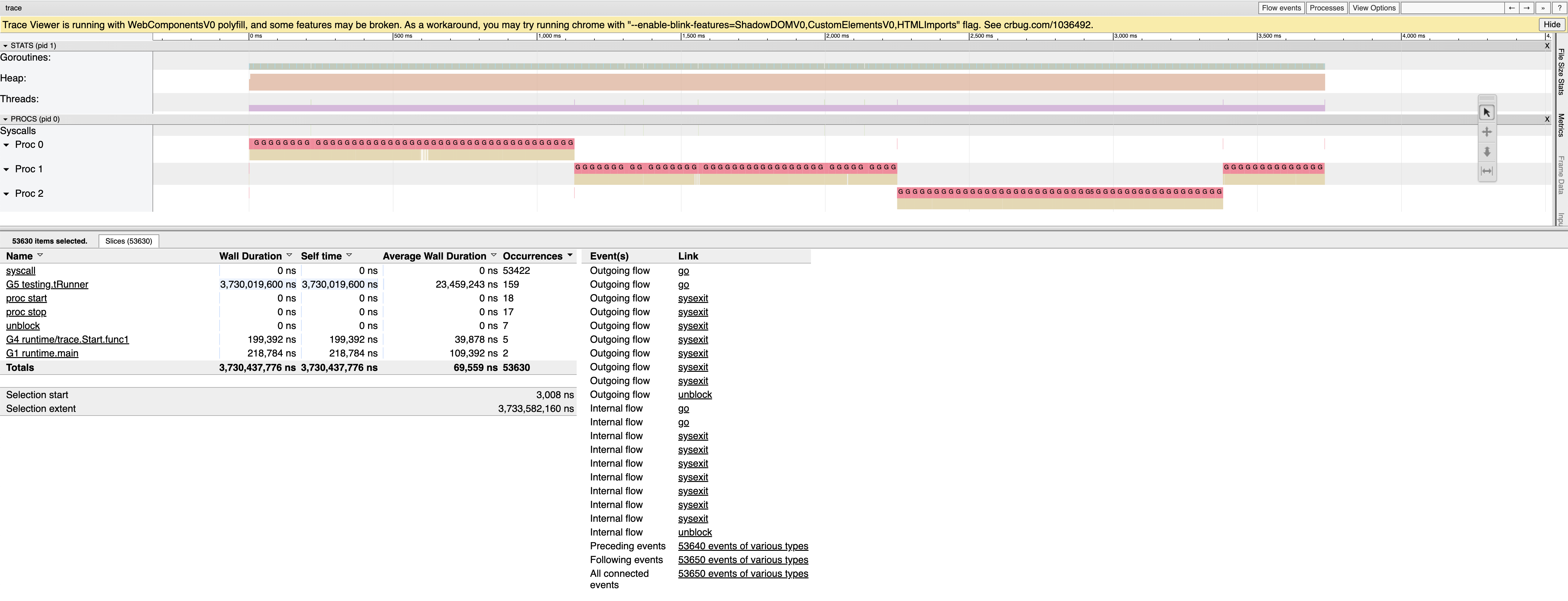
According to the trace (shown below), the workload issues 53k syscalls in 3.7s, so at ~14kHz it's much faster than the profiling frequency.
What syscall would you use? It would have to be a non-blocking one to see 50%? But yeah, a small C reproducer could be useful for this. |
|
I'd start with getpid or something similar, though perhaps it needs to go through the scheduler, so a very briefly blocking system call may be needed. |
|
In triage now, since it seems like the next step is a C reproducer to confirm unfair SIGPROF delivery? Does that sound right? (The assignee is mostly just for tracking, there's no obligation; feel free to remove it.) |
|
I tried to reproduce the problem in C with this program, but no luck. The compute thread gets around 1200 ticks each of 1ms CPU (which is a huge underestimate since /usr/bin/time reports 6.1s of user CPU), but the main thread gets 0 ticks unless I increase the argument to fib(). Any suggestions? |
|
I spent some time look into this. I ran the original Go reproducer with both profiling and tracing turned on, and saw that while the syscalls and compression are interleaved, the profiling samples indeed mostly land on syscalls.
This is a (small portion of a) trace with Interestingly, there seems also some bias with
This is a (total) trace of
The pink/magenta bars are profiling samples. There is a train of samples before the syscall, and then when the syscall starts, it gets exactly 1 sample. The syscall last much longer, but there is no more sample land on that syscall. So while for the interleaved case syscalls are over-sampled, for long running syscall, it is under-sampled (!). (To rule out other possibilities, I also turned off async preemption, in case that the preemption signal interrupts syscalls or affects profiling signal delivery, but it doesn't make a difference. To make sure the runtime is doing the right accounting, I printed signal PCs and it is indeed that most of them landed in libc address range.) C reproducerInspired by the interleaved IO and Alan's C program, I wrote this C program https://go.dev/play/p/x3zK__wMKly , which does interleaved (short) That is, I also used the macOS builtin Most sample land in |



|
For the long syscall, if it is mostly IO and the kernel counts only CPU time for profiling timers, the under-sampling may be okay. For the short ones, maybe the kernel is more likely to update its accounting at syscalls and only then find that it should trigger a profiling timer and deliver the signal... |
|
Not sure a +1 is useful here, but this is still true in macOS 14.2.1 (23C71) and very visible in anything that calls crypto/rand.Read, making it appear as if all the time was spent on |
I recently looked into how the |
What version of Go are you using (
go version)?This is on macOS 12.6.1 with an M1 chip, but the problem seems to affect Intel as well.
Does this issue reproduce with the latest release?
Yes.
What operating system and processor architecture are you using (
go env)?go envOutputWhat did you do?
Create a CPU profile of a CPU-bound workload that is interleaved with short system calls.
For example TestInterleavedIO is a reproducer that is compressing a 250MB file containing random data.
What did you expect to see?
A profile that is similar to the one shown below for linux. Most of time should be spent on gzip compression, and a little bit on syscalls.
What did you see instead?
On macOS the majority of time is attributed to read and write syscalls. The gzip compression is barely showing up at all.
Sanity Check
TestSequentialIO implements the same workload, but instead of interleaved I/O, it does one big read first, followed by gzip compression, followed by a big write.
As expected, Linux produces a profile dominated by gzip compression.
And macOS now shows the right profile too.
Conclusion
macOS
setitimer(2)seems to bias towards syscalls. This issue was reported and fixed in the past, see #17406 (2016) and #6047 (2013). So this could be a macOS regression.I've uploaded all code, pprofs and screenshots to this google drive folder.
The text was updated successfully, but these errors were encountered: