Policy and value heads are from AlphaGo Zero, not Alpha Zero #47
Comments
|
Thinking about it, the value head coming from a single 1 x 8 x 8 means it can only represent 64 evaluations. This would already be little for Go, where ahead or behind can be represented in stones. But for chess, where we often talk about centipawns, it's even worse. |
|
OMG How did I miss this 😱. Kind of amazing it does what it does right now... |
|
I am also wondering now which kind of value head they used in AlphaZero, since it is not written in the paper. I will try a few architectures. |
|
|
@gcp According to the AlphaGoZero paper, the network also applies a batchnorm and ReLu in both heads. Why did you skip this?
|
|
We definitely need some kind of non linearity in the fully connected layer.
Otherwise we will only ever be able to learn a linear function for each
head. I also see no reason not to apply batch normalization, but that is
not as crucial.
F. Huizinga <[email protected]> schrieb am Mi., 24. Jan. 2018, 20:22:
… @gcp <https://github.com/gcp> According to the AlphaGoZero paper, the
network also applies a batchnorm and ReLu in both heads. Why did you skip
this?
The output of the residual tower is passed into two separate ‘heads’ for
computing the policy and value. The policy head applies the following
modules:
(1) A convolution of 2 filters of kernel size 1 × 1 with stride 1
(2) Batch normalization
(3) A rectifier nonlinearity
(4) A fully connected linear layer that outputs a vector of size 19 2 + 1
= 362,
corresponding to logit probabilities for all intersections and the pass
move
The value head applies the following modules:
(1) A convolution of 1 filter of kernel size 1 × 1 with stride 1
(2) Batch normalization
(3) A rectifier nonlinearity
(4) A fully connected linear layer to a hidden layer of size 256
(5) A rectifier nonlinearity
(6) A fully connected linear layer to a scalar
(7) A tanh nonlinearity outputting a scalar in the range [−1, 1]
—
You are receiving this because you were mentioned.
Reply to this email directly, view it on GitHub
<#47 (comment)>,
or mute the thread
<https://github.com/notifications/unsubscribe-auth/AAic-Y1ojSpYzhqD_9FK4vUJ210TttRSks5tN4L0gaJpZM4Rrl0X>
.
|
|
No never mind, I didn't read correctly. He does apply both BN and the ReLu, it's encoded in the |
|
Ok, given the above I'm trying out two different networks: 1. NN 64x5Policy Head
Value Head
2. NN 128x5Policy Head
Value Head
|
|
Wow, great call @gcp. Glad you caught this before we kicked off the distributed learning process. |
|
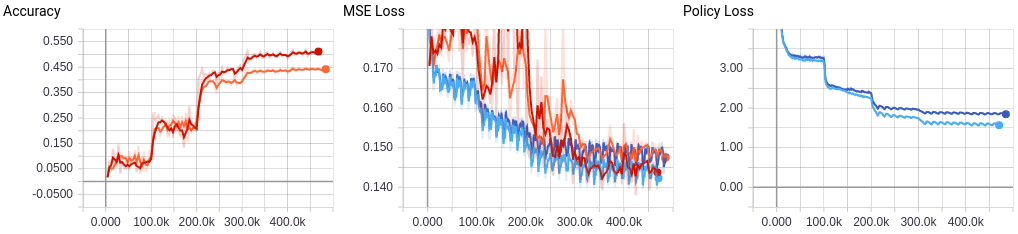
Using the above networks I'm reaching an accuracy of 45% and 52% respectively. There is a strange periodicity that I'm not sure about. I'm using a shufflebuffer of 2^18 and 16 prefetches. Thoughts? |

|
I don't want to bother you again with the same thing, but your MSE plot is again near 0.15 that, scaled by 4, gives ~0.6 (you should stop scaling the MSE loss by the way, al least while you are studying the value head real convergence). That loss of around ~0.6 (given we are working with 3 integer outputs z=-1,0,1) means the NN learns nothing but a statistical mean response. I repeated this lot of times in the other post:
|
|
I also started training a network (on the stockfish data) which is at mse=0.09 (on the test set) after 10k steps. I will see if I observe the same periodicity. |
|
@Zeta36 I know, I didn't want to alter the result outputs without having a merge into master. Otherwise comparing results is just more confusing. |
|
@kiudee Did you also use a value head weight of 0.01? |
|
@Error323 Yes, but ignore my results for now. I think there was a problem with the chunks I generated. I will report back as soon as the chunks are generated (probably tomorrow). |
|
@Error323 Somewhere, there must be a bug. I re-chunked the Stockfish data, converted it to train/test and let it learn for a night and got the following (too good to be true and likely massively overfit) result: I am using the following config: name: 'kb1-64x5' # ideally no spaces
gpu: 0 # gpu id to process on
dataset:
num_samples: 352000 # nof samples to obtain
train_ratio: 0.75 # trainingset ratio
skip: 16 # skip every n +/- 1 pos
input: './data/' # supports glob
path: './data_out/' # output dir
training:
batch_size: 512
learning_rate: 0.1
decay_rate: 0.1
decay_step: 100000
policy_loss_weight: 1.0
value_loss_weight: 0.01
path: '/tmp/testnet'
model:
filters: 64
residual_blocks: 5 |

|
Hmmm how did you generate the chunks and how many games are there? Given n chunks and skip size s you should generate (n*15000)/s samples. This makes sure you're sampling across the entire set of chunks. Over here things start to look promising @Zeta36 |

|
@gcp is just implementing a validation split for a Tensorflow training code in Leela Zero (leela-zero/leela-zero#747), and it fixed a lot of problems for the reinforcement learning pipeline there. You might check out if any of this is relevant for you as well... |
|
They already have this fix in their training code (the skip in the configuration), I think. As well as the validation splits. The training data generation was changed quite a bit to deal with the 10x increase in inputs and even faster network evaluation (8x8 vs 19x19) you get in chess. |
|
@Error323 I have 352000 games which result in 3354 chunks. So, from your equation I should set the number of samples to 3144375? |
|
Yes, it looks promising, @Error323. Can you check the game level of that network looking for some kind of chess strategy learning? If you could compare the (strategy) game level of the orange NN against the red new one it'd great. If the red network really learned something beyond the mean I think we should already see it (probably it'll be easier to see this improvement after the opening phase is over -the policy head is really strong and determinant in the first dozen movements-). |
|
I found the bug that was causing the random play: innerproduct<32*width*height, NUM_VALUE_CHANNELS>(value_data, ip1_val_w, ip1_val_b, winrate_data);I forgot to adjust the sizes of the inner products which failed silently. I think we should replace these magic constants by global constants. |
|
I'm struggling with the same hah, crap. I fully agree on the magic constants to global. Any more places you're seeing problems? I'm using 73 output planes in both heads. I don't have segfaults anymore but am wondering whether I fixed everything correctly. https://gist.github.com/Error323/46a05ab5548eaeac95916ea428dd9dec @gcp @glinscott did I miss anything? |
|
@Error323 one way to validate is to run it under asan. I do that with the debug build, and Your changes look correct to me though. |
|
@Error323 Looks good. After adjusting those places leela-chess started to play sane chess for me. |
|
Ok so I'm still running an evaluation tournament of "orange" vs "red" in the graph above. Orange having higher accuracy and higher MSE. Red having lower accuracy but also lower MSE. So far the score is in favor of Orange with I know it's only 800 playouts, but I still think this is inferior play given the network and the dataset. Both still just give away material or fail to capture important material for the taking. So I don't think we're ready for self play yet. The networks need to be better. Currently trying out a 64x5 network and 128x5 with 0.1 loss weight on the value head. Value head is 8x8x8 -> 64 -> 1 and policy head is 32x8x8 -> 1924. Let me know if you have different ideas/approaches. |
|
@Error323 interesting! What happens if you take a normal midgame position, run the network on it, and then eg. remove the queen, and re-run. Does the win percentage change? |
|
@glinscott Using the midgame from @kiudee it does seem to be well aware of the queen. And the same initial FEN string with 16K playouts: |
|
I think at this point there are two valid approaches.
Either way, with both approaches it might be good to build the learning-rate-decay function. @glinscott shall I give that a try? |
Nice! I think we should also start to focus more on the C++ side again now. The nodes per second needs to go up. I'm experimenting with caffe and TensorRT in #52 and I definitely think that the heads should go to the GPU as you suggested in #51. Before we launch the self-learning we should be as fast as possible to utililize all those precious cycles as best we can :) I was wondering what kind of GPU's people here have? Also we need Windows testers. |
The problem of TensorRT is that it requires optimization to the specific weights of the network. It's OK once you have a trained network, but not if you're still training it or have variable weights. (I guess the question is if you could pre-transform the networks on the server machine - that might work) INT8 support is exclusive to the 1080 GTX (Ti or not I'm not sure?) only, AFAIK. Anything that depends on cuDNN also requires the end user to make an account on NVIDIA's site and download themselves due to licensing restrictions. I don't know how TensorRT's license looks. It's also NVIDIA-only. I try to stay as far away as possible from vendor lock in. But some people have made a version of Leela Zero that does the network eval by a TCP server and have that calculated by Theano using cuDNN, for example. If you don't care for end-user setup complexities more things are possible. |
There are implementations of this in Leela Zero's pull requests. (They were not merged because for Go there was no gain) |
Indeed, that was the thinking. Pretransform once per new network and deploy across all nv based workers.
I believe it's also available on latest titans and their Volta architecture. Maybe 1080 too? Not sure about that though.
This fact reaaaaaaaaaaaally sucks :(
I understand indeed, this is good. I just want to squeeze every drop of performance out of my nv cards.
This sounds very inefficient? |
|
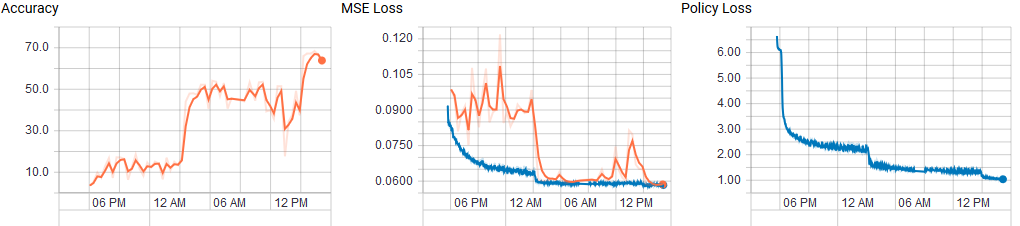
After training for 2 days and 20 hours, the network is done. Below you can see the tensorboard graphs.
kbb-net.zip contains the weights, config yaml file and results. With your permission @glinscott I'd like to suggest we hereby close #20. |

|
What's the Elo rating for Gnuchess at the settings you used? |
|
@Error323 Good job. I am going to try playing that network.
For now (at iteration 220k) it still plays quite bad, but through search it is typically able to improve its moves, which suggests that the learned value head is providing some benefit. |
|
@Error323 congrats! That's awesome progress :). One thing I'm curious about - which version of GnuChess did you use? Here are the ratings for the different versions from CCRL: http://www.computerchess.org.uk/ccrl/4040/cgi/compare_engines.cgi?family=GNU%20Chess&print=Rating+list&print=Results+table&print=LOS+table&print=Ponder+hit+table&print=Eval+difference+table&print=Comopp+gamenum+table&print=Overlap+table&print=Score+with+common+opponents |
|
It's 6.2.2 the default in Ubuntu 16.04. I don't know the ELO rating. Note that I handicapped it severely with 30 moves per minute. |
|
@glinscott that site is a goldmine for supervised learning 😍 The PGN files seem to be available. |
|
I am aborting my training run now. This is the state after 400k steps: Even though it has an accuracy of almost 80% on the stockfish data, it still has problems finding good moves with a low number of playouts. I suspect there might be a problem of variety in the Stockfish data, causing it to have similar positions in train/test. The learned value function is able to compare positions relatively (which is why it improves its move choice when letting it do more playouts), but the absolute score is always hovering around 55% for white. It looks like a local optimum where it learned to adjust the score slightly based on the position. If you want I can upload weights and config, but the file is too large for attaching it here. |

I agree. I think that even though the final gamestates may be different, the first n ply share many similarities. Given your graphs it should be annihilating everything, but the data compared to the entire chess gametree is too sparse. |
|
Just to get an idea, this is the PV of the start position including the points where it changed its mind: |
|
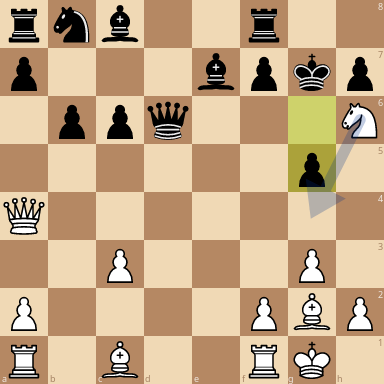
I found something interesting. I gave the network trained by @Error323 the following position from the 10th game of AlphaZero vs Stockfish:
After 325950 playouts the network prefers the move Re1: |
|
@kiudee it's not immediately obvious to me. Could you elaborate? |
|
If you analyze the position with Stockfish, it thinks the move is losing/even (depending on depth). Stockfish at depth 42: |
|
Puzzling it does not consider taking knight at all |
|
Here it decides for no reason to give up knight. But stockfish thinks that black is even better with d6e5 |
|
Positions are from the full game it played with 1600 playouts |
|
@Error323 Scanning through this, the periodicity in the earlier graphs is almost certainly an artifact of the shuffling behavior. We were rather constantly surprised by the shuffle behavior not quite doing what we expected. We ended up turning the shuffle size up to almost the total number of steps we take per generation (2M)... not quite the same as what you're doing w/ SL here but that periodicity really, really jumped out at me. |
|
@Error323 re: how to see when to drop the learning rate. It was suggested to us that we monitor the gradient updates as a way to see when it's time to drop the rate, and adjust accordingly. |
Well this is somewhat scary. When using a shuffle buffer of 2^18 my memory consumption already went through the roof.
Thanks! This is very different from what I had in mind, and probably better! I'm gonna examine code and comments! |
In Leela Zero this was solved by dropping 15/16th of the training data randomly. This trades of 16x the input processing CPU usage for a 16 times saving of memory. You can make this bigger if you have more or faster cores in the training machine. Whether this is usable somewhat depends on the input pipeline. But yes, shuffle buffer by themselves aren't good enough if the training data is sequential positions from games. |
|
we dropped data as well, sampling only 5% of the positions (here). This is for RL though not SL -- i haven't done much with SL |
|
Fixed now :). |
Turns out that is actually what they did. From empirical experiments, doing the 1x1 256->1 down-convolution before the FC layers works very well (and better than doing, say, 1x1 or 3x3 256->32 and using that as FC input). That said, making the value head FC layer bigger(!) than the input to it still seems strange to me and looks like it was carried over from the other games more than anything else. |
leela-chess/training/tf/tfprocess.py
Line 366 in 09eb87f
The structure of these heads matches Leela Zero and the AlphaGo Zero paper, not the Alpha Zero paper.
The policy head convolves the last residual output (say 64 x 8 x 8) with a 1 x 1 into a 2 x 8 x 8 outputs, and then converts that with an FC layer into 1924 discrete outputs.
Given that 2 x 8 x 8 only has 128 possible elements that can fire, this seems like a catastrophic loss of information. I think it can actually only represent one from and one to square, so only the best move will be correct (and accuracy will look good, but not loss, and it can't reasonably represent MC probabilities over many moves).
In the AGZ paper they say: "We represent the policy π(a|s) by a 8 × 8 × 73 stack of planes encoding a probability distribution over 4,672 possible moves." Which is quite different.
They also say: "We also tried using a flat distribution over moves for chess and shogi; the final result was almost identical although training was slightly slower."
But note that for the above-mentioned reason it is almost certainly very suboptimal to construct the flat output from only 2 x 8 x 8 inputs. This works fine for Go because moves only have a to-square, but chess also has from-squares. 64 x 8 x 8 may be reasonable, if we forget about underpromotion (we probably can).
The value head has a similar problem: it convolves to a single 8 x 8 output, and then uses an FC layer to transform 64 outputs into...256 outputs. This does not really work either.
The value head isn't precisely described in the AZ paper, and a single 1 x 8 x 8 is probably good enough, but the 256 in the FC layer make no sense then. The problems the value layer has right now might have a lot to do with the fact that the input to the policy head is broken, so the residual stack must try to compensate this.
The text was updated successfully, but these errors were encountered: