
Lore is a python framework to make machine learning approachable for Engineers and maintainable for Data Scientists.
- Models support hyper parameter search over estimators with a data pipeline. They will efficiently utilize multiple GPUs (if available) with a couple different strategies, and can be saved and distributed for horizontal scalability.
- Estimators from multiple packages are supported: Keras (TensorFlow/Theano/CNTK), XGBoost and SciKit Learn. They can all be subclassed with build, fit or predict overridden to completely customize your algorithm and architecture, while still benefiting from everything else.
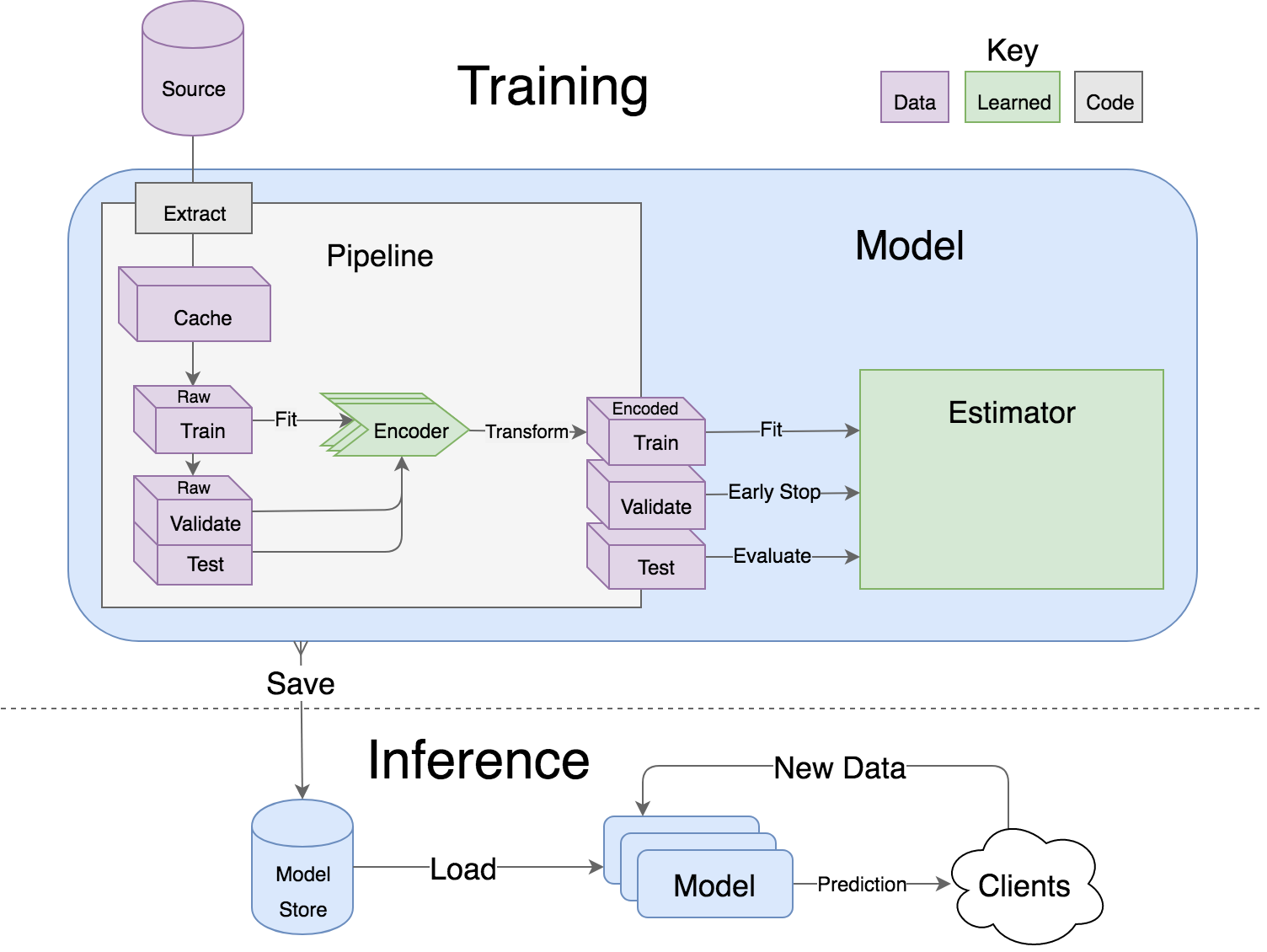
- Pipelines avoid information leaks between train and test sets, and one pipeline allows experimentation with many different estimators. A disk based pipeline is available if you exceed your machines available RAM.
- Transformers standardize advanced feature engineering. For example, convert an American first name to its statistical age or gender using US Census data. Extract the geographic area code from a free form phone number string. Common date, time and string operations are supported efficiently through pandas.
- Encoders offer robust input to your estimators, and avoid common problems with missing and long tail values. They are well tested to save you from garbage in/garbage out.
- IO connections are configured and pooled in a standard way across the app for popular (no)sql databases, with transaction management and read write optimizations for bulk data, rather than typical ORM single row operations. Connections share a configurable query cache, in addition to encrypted S3 buckets for distributing models and datasets.
- Dependency Management for each individual app in development, that can be 100% replicated to production. No manual activation, or magic env vars, or hidden files that break python for everything else. No knowledge required of venv, pyenv, pyvenv, virtualenv, virtualenvwrapper, pipenv, conda. Ain’t nobody got time for that.
- Tests for your models can be run in your Continuous Integration environment, allowing Continuous Deployment for code and training updates, without increased work for your infrastructure team.
- Workflow Support whether you prefer the command line, a python console, jupyter notebook, or IDE. Every environment gets readable logging and timing statements configured for both production and development.
This example demonstrates nested transformers and how to use lore.io with a postgres database users table that has feature first_name and response has_subscription columns. If you don't want to create the database, you can follow a database free example app on medium.
$ pip install lore
$ lore init my_app --python-version=3.6.4 --keras --xgboost --postgres
# fix up .env, config/database.cfg, circle.yml, README.rstWe'll naively try to predict whether users are subscribers, given their first name.
Update config/database.cfg to specify your database url:
# config/database.cfg
[MAIN]
url: $DATABASE_URLyou can set environment variable for only the lore process with the .env file:
# .env
DATABASE_URL=postgres://localhost:5432/developmentCreate a sql file that specifies your data:
-- my_app/extracts/subscribers.sql
SELECT
first_name,
has_subscription
FROM users
LIMIT = %(limit)sPipelines are the unsexy, but essential component of most machine learning applications. They transform raw data into encoded training (and prediction) data for a model. Lore has several features to make data munging more palatable.
# my_app/pipelines/subscribers.py
import lore.io
import lore.pipelines.holdout
from lore.encoders import Norm, Discrete, Boolean, Unique
from lore.transformers import NameAge, NameSex, Log
class Holdout(lore.pipelines.holdout.Base):
def get_data(self):
# lore.io.main is a Connection created by config/database.cfg + DATABASE_URL
# dataframe() supports keyword args for interpolation (limit)
# subscribers is the name of the extract
# cache=True enables LRU query caching
return lore.io.main.dataframe(filename='subscribers', limit=100, cache=True)
def get_encoders(self):
# An arbitrairily chosen set of encoders (w/ transformers)
# that reference sql columns in the extract by name.
# A fair bit of thought will probably go into expanding
# your list with features for your model.
return (
Unique('first_name', minimum_occurrences=100),
Norm(Log(NameAge('first_name'))),
Discrete(NameSex('first_name'), bins=10),
)
def get_output_encoder(self):
# A single encoder that references the predicted outcome
return Boolean('has_subscription')The superclass lore.pipelines.base.Holdout will take care of:
- splitting the data into training_data/validation_data/test_data dataframes
- fitting the encoders to training_data
- transforming training_data/validation_data/test_data for the model
Define some models that will fit and predict the data. Base models are designed to be extended and overridden, but work with defaults out of the box.
# my_app/models/subscribers.py
import lore.models.keras
import lore.models.xgboost
import lore.estimators.keras
import lore.estimators.xgboost
from my_app.pipelines.subscribers import Holdout
class DeepName(lore.models.keras.Base):
def __init__(self):
super(DeepName, self).__init__(
pipeline=Holdout(),
estimator=lore.estimators.keras.BinaryClassifier() # a canned estimator for deep learning
)
class BoostedName(lore.models.xgboost.Base):
def __init__(self):
super(BoostedName, self).__init__(
pipeline=Holdout(),
estimator=lore.estimators.xgboost.Base() # a canned estimator for XGBoost
)Test the models predictive power:
# tests/unit/test_subscribers.py
import unittest
from my_app.models.subscribers import DeepName, BoostedName
class TestSubscribers(unittest.TestCase):
def test_deep_name(self):
model = DeepName() # initialize a new model
model.fit(epochs=20) # fit to the pipeline's training_data
predictions = model.predict(model.pipeline.test_data) # predict the holdout
self.assertEqual(list(predictions), list(model.pipeline.encoded_test_data.y)) # hah!
def test_xgboosted_name(self):
model = BoostedName()
model.fit()
predictions = model.predict(model.pipeline.test_data)
self.assertEqual(list(predictions), list(model.pipeline.encoded_test_data.y)) # hah hah hah!Run tests:
$ lore testExperiment and tune notebooks/ with $ lore notebook using the app kernel
├── .env.template <- Template for environment variables for developers (mirrors production)
├── README.md <- The top-level README for developers using this project.
├── requirements.txt <- keeps dev and production in sync (pip)
├── runtime.txt <- keeps dev and production in sync (pyenv)
│
├── data/ <- query cache and other temp data
│
├── docs/ <- generated from src
│
├── logs/ <- log files per environment
│
├── models/ <- local model store from fittings
│
├── notebooks/ <- explorations of data and models
│ └── my_exploration/
│ └── exploration_1.ipynb
│
├── appname/ <- python module for appname
│ ├── __init__.py <- loads the various components (makes this a module)
│ │
│ ├── api/ <- external entry points to runtime models
│ │ └── my_project.py <- hub endpoint for predictions
│ │
│ ├── extracts/ <- sql
│ │ └── my_project.sql
│ │
│ ├── estimators/ <- Code that make predictions
│ │ └── my_project.py <- Keras/XGBoost implementations
│ │
│ ├── models/ <- Combine estimator(s) w/ pipeline(s)
│ │ └── my_project.py
│ │
│ └── pipelines/ <- abstractions for processing data
│ └── my_project.py <- train/test/split data encoding
│
└── tests/
├── data/ <- cached queries for fixture data
├── models/ <- model store for test runs
└── unit/ <- unit tests
Lore provides python modules to standardize Machine Learning techniques across multiple libraries.
- lore.models are compatibility wrappers for your favorite library — Keras, XGBoost, SciKit Learn. They come with reasonable defaults for rough draft training out of the box.
- lore.pipelines fetch, encode, and split data into training/test sets for models. A single pipeline will have one Encoder per feature in the model.
- lore.encoders operate within Pipelines to transform a single feature into an optimal representation for learning.
- lore.transformers provide common operations, like extracting the area code from a free text phone number. They can be chained together inside encoders. They efficiently
- lore.io allows connecting to postgres/redshift and upload/download from s3
- lore.serializers persist models with their pipelines and encoders (and get them back again)
- lore.stores save intermediate data, for reproducibility and efficiency.
- lore.util has those extra niceties we rewrite in every project, and then some
- lore.env takes care of ensuring that all dependencies are correctly installed before running
Use your favorite library in a lore project, just like you'd use them in any other python project. They'll play nicely together.
- Keras (TensorFlow/Theano/CNTK) + Tensorboard
- XGBoost
- SciKit-Learn
- Jupyter Notebook
- Pandas
- Numpy
- Matplotlib, ggplot, plotnine
- SQLAlchemy, Psycopg2
- Hub
There are many ways to manage python dependencies in development and production, and each has it's own pitfalls. Lore codifies a solution that “just works” with lore install, which exactly replicates what will be run in production.
Python 2 & 3 compatibility
- pip install lore works regardless of whether your base system python is 2 or 3. Lore projects will always use the version of python specified in their runtime.txt
- Lore projects use the system service manager (upstart on ubuntu) instead of supervisord which requires python 2.
Heroku_ buildpack compatibility CircleCI_, Domino_)
- Lore supports runtime.txt to install and use a consistent version of python 2 or 3 in both development and production.
- lore install automatically manages freezing requirements.txt, using a virtualenv, so pip dependencies are exactly the same in development and production. This includes workarounds to support correctly (not) freezing github packages in requirements.txt
Environment Specific Configuration
- Lore supports reading environment variables from .env, for easy per project configuration. We recommend .gitignore .env and checking in a .env.template for developer reference to prevent leaking secrets.
logging.getLogger(__name__)is setup appropriately to console, file and/or syslog depending on environment- syslog is replicated with structured data to loggly in production
- lore.util.timer logs info in development, and records to librato in production
- Exception handling logs stack traces in development and test, but reports to rollbar in production
- lore console interactive python shell is color coded to prevent environmental confusion
Multiple concurrent project compatibility
- Lore manages a distinct python virtualenv for each project, which can be installed from scratch in development with lore install
Binary library installation for MAXIMUM SPEED
- Lore can build tensorflow from source when it is listed in requirements for development machines, which results in a 2-3x runtime training performance increase. Use lore install --native
- Lore also compiles xgboost on OS X with gcc-5 instead of clang to enable automatic parallelization
IO
lore.io.connection.Connection.select()andConnection.dataframe()can be automatically LRU cached to diskConnectionsupports python %(name)s variable replacement in SQLConnectionstatements are always annotated with metadata for pgHeroConnectionis lazy, for fast startup, and avoids bootup errors in development with low connectivityConnectionsupports multiple concurrent database connections
Serialization
- Lore serializers provide environment aware S3 distribution for keras/xgboost/scikit models
- Coming soon: heroku buildpack support for serialized models to marry the appropriate code for repeatable and deploys that can be safely rolled back
Caching
- Lore provides mulitple configurable cache types, RAM, Disk, coming soon: MemCached & Redis
- Disk cache is tested with pandas to avoid pitfalls encountered serializing w/ csv, h5py, pickle
Encoders
- Unique
- Discrete
- Quantile
- Norm
Transformers
- AreaCode
- EmailDomain
- NameAge
- NameSex
- NamePopulation
- NameFamilial
Base Models
- Abstract base classes for keras, xgboost, and scikit - inheriting class to define data(), encoders(), output_encoder(), benchmark() - multiple inheritance from custom base class w/ specific ABC for library
- provides hyper parameter optimization
Fitting
- Each call to Model.fit() saves the resulting model, along with the params to fit, epoch checkpoints and the resulting statistics, that can be reloaded, or uploaded with a Serializer
Keras/Tensorflow
- tensorboard support out of the box with tensorboard --logdir=models
- lore cleans up tensorflow before process exit to prevent spurious exceptions
- lore serializes Keras 2.0 models with extra care, to avoid several bugs (some that only appear at scale)
- ReloadBest callback early stops training on val_loss increase, and reloads the best epoch
Utils
lore.util.timercontext manager writes to the log in development or librato in production*lore.util.timedis a decorator for recording function execution wall time
$ lore server # start an api process
$ lore console # launch a console in your virtual env
$ lore notebook # launch jupyter notebook in your virtual env
$ lore fit MODEL # train the model
$ lore generate [scaffold, model, estimator, pipeline, notebook, test] NAME
$ lore init [project] # create file structure
$ lore install # setup dependencies in virtualenv
$ lore test # make sure the project is in working order
$ lore pip # launch pip in your virtual env
$ lore python # launch python in your virtual env