-
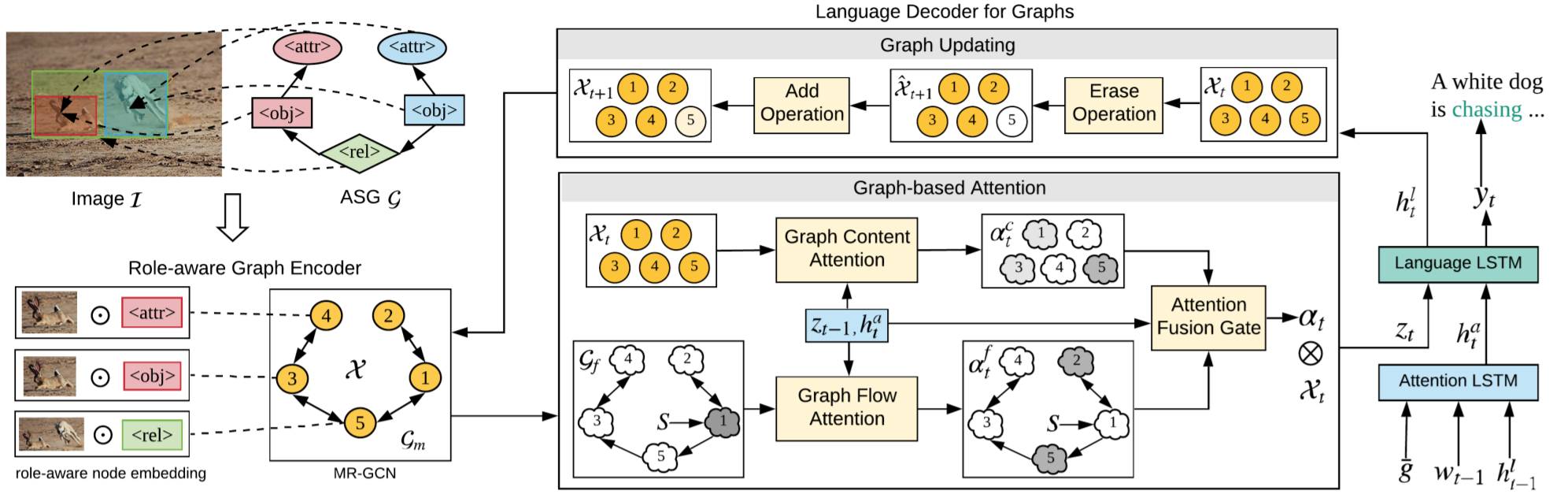
Say As You Wish: Fine-Grained Control of Image Caption Generation With Abstract Scene Graphs
oralShizhe Chendetails
-
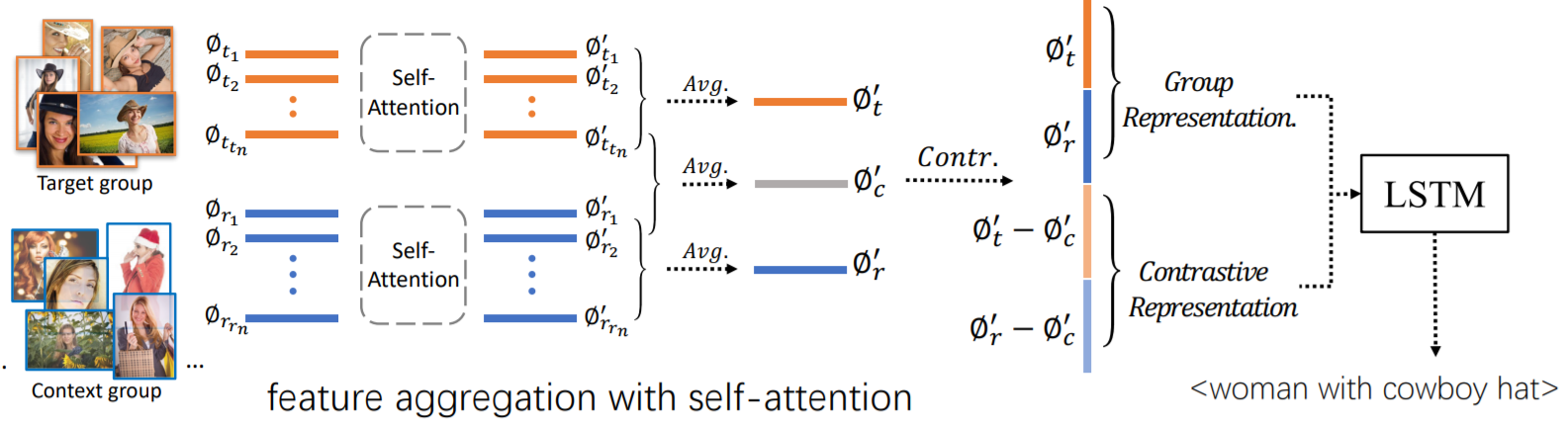
Context-Aware Group Captioning via Self-Attention and Contrastive Features
details
-
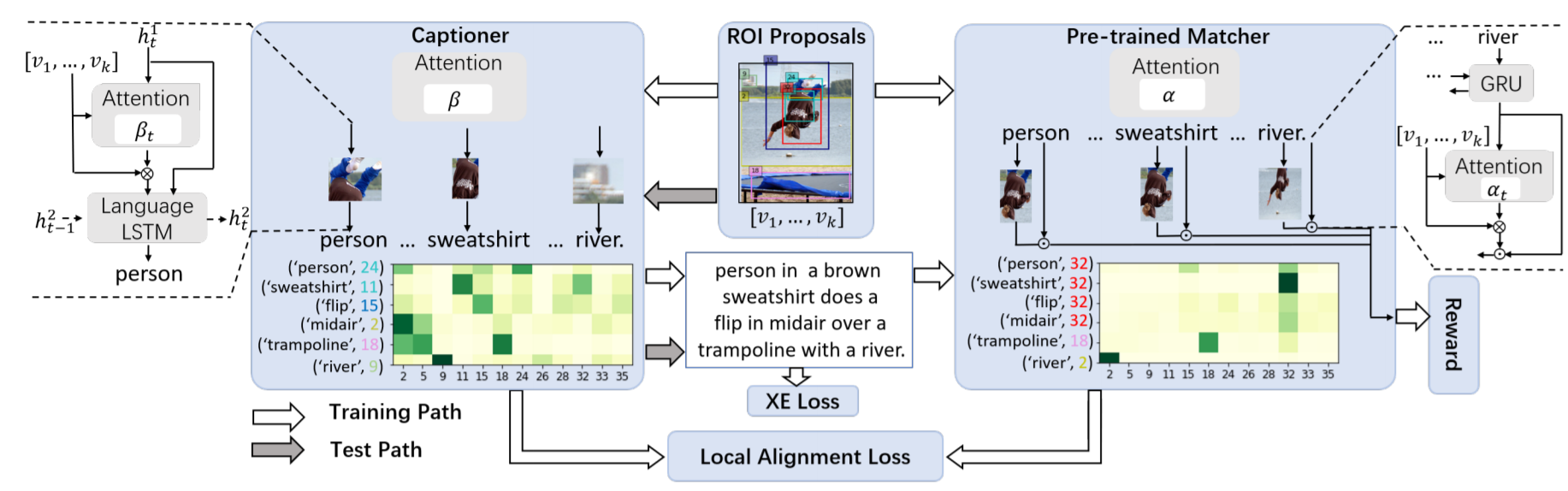
More Grounded Image Captioning by Distilling Image-Text Matching Model
details
-
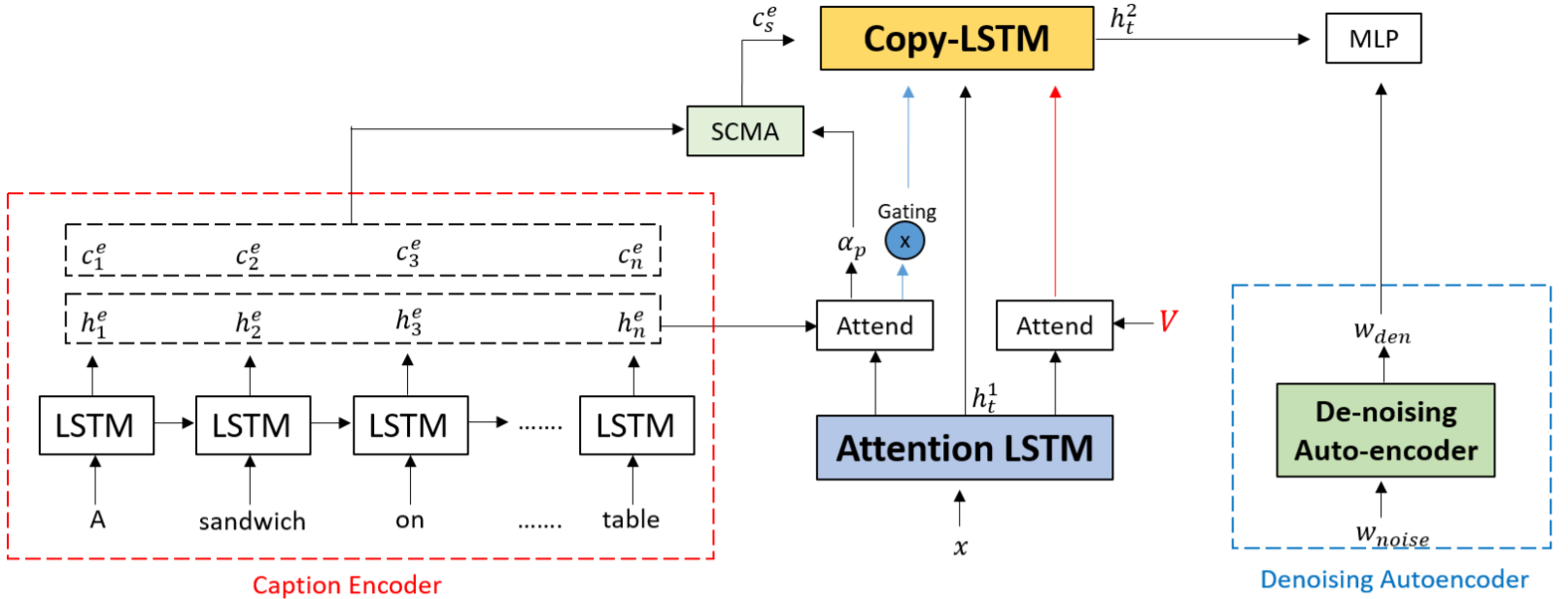
Show, Edit and Tell: A Framework for Editing Image Captions
details
-
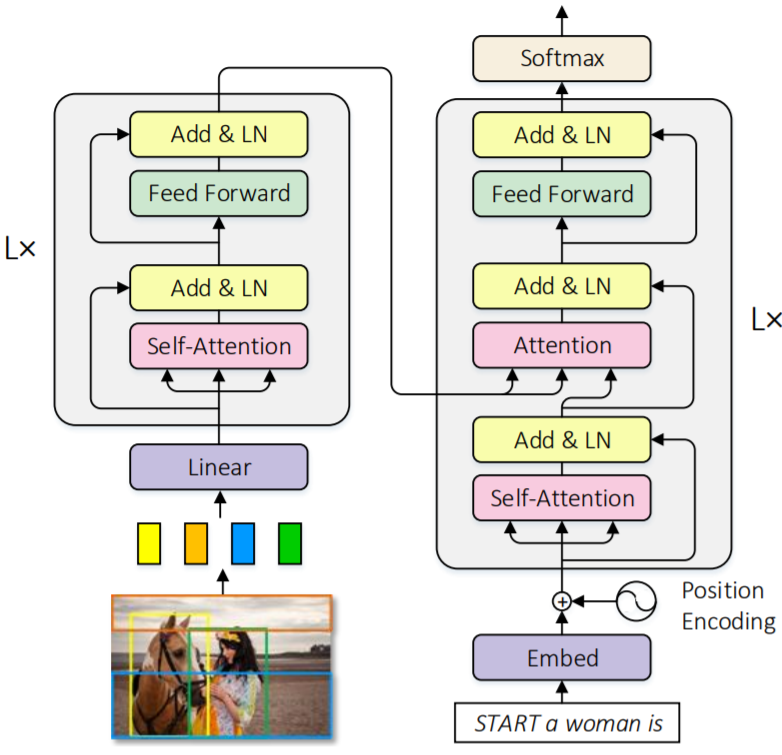
Normalized and Geometry-Aware Self-Attention Network for Image Captioning
details
-
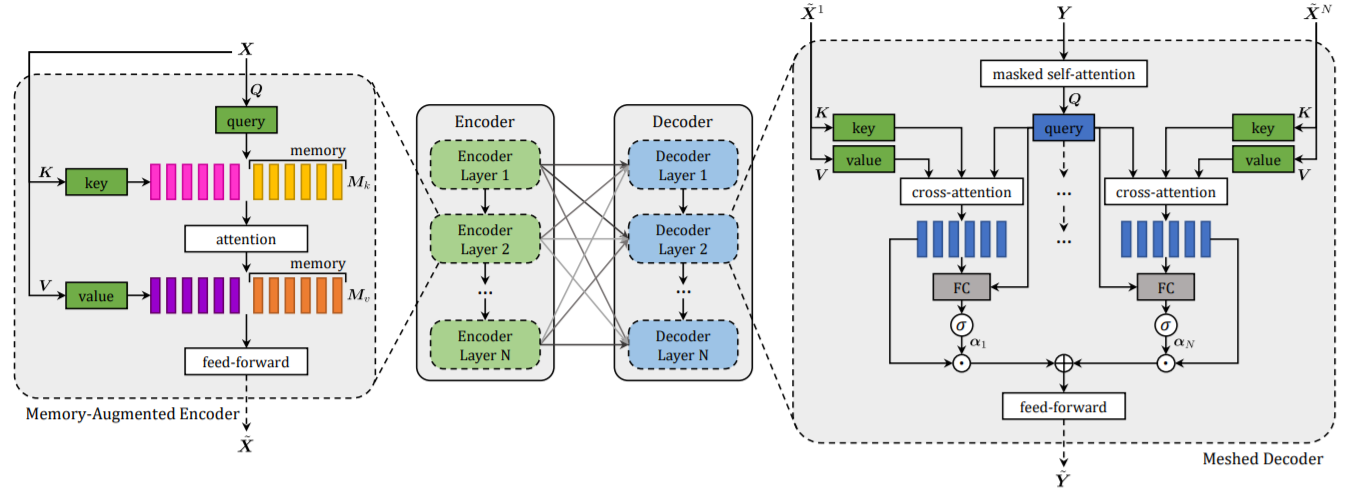
Meshed-Memory Transformer for Image Captioning
details
-
Better Captioning With Sequence-Level Exploration
JinQindetails
-
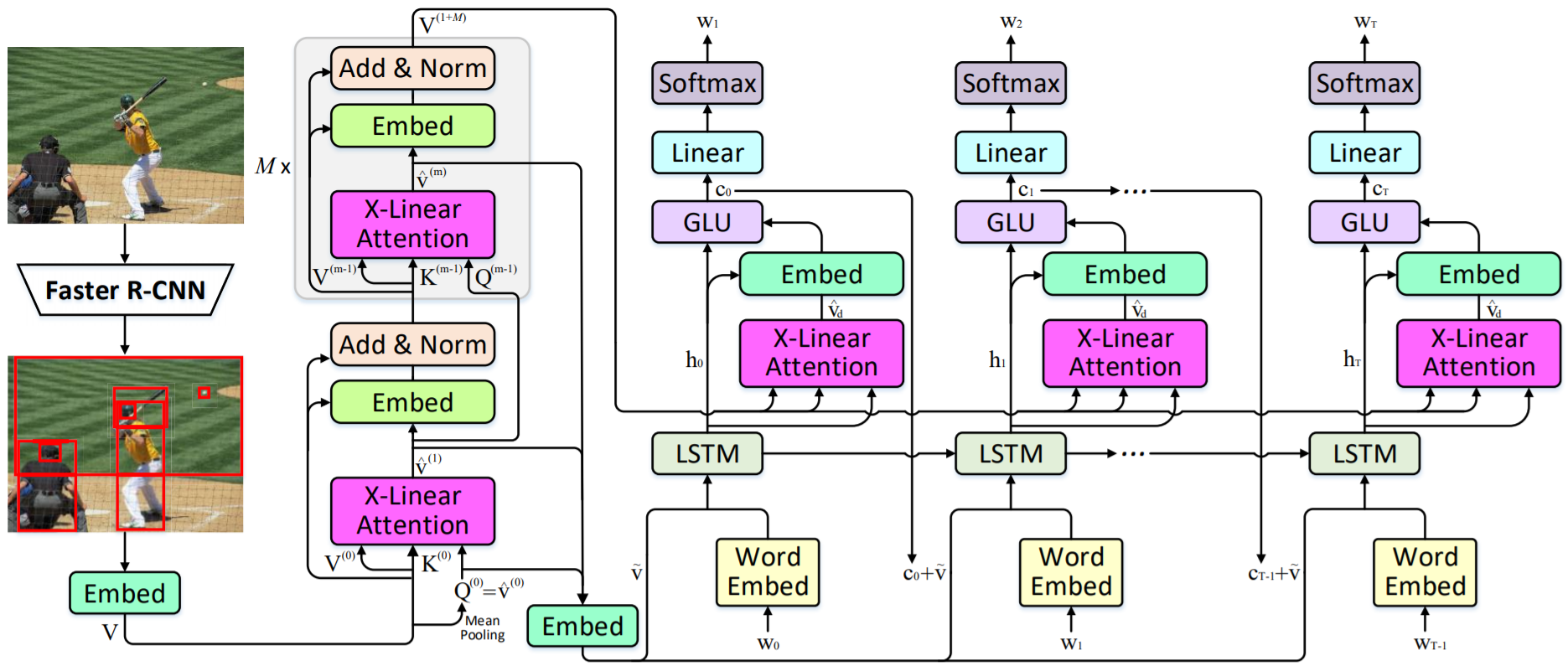
X-Linear Attention Networks for Image Captioning
JD AIdetails
-
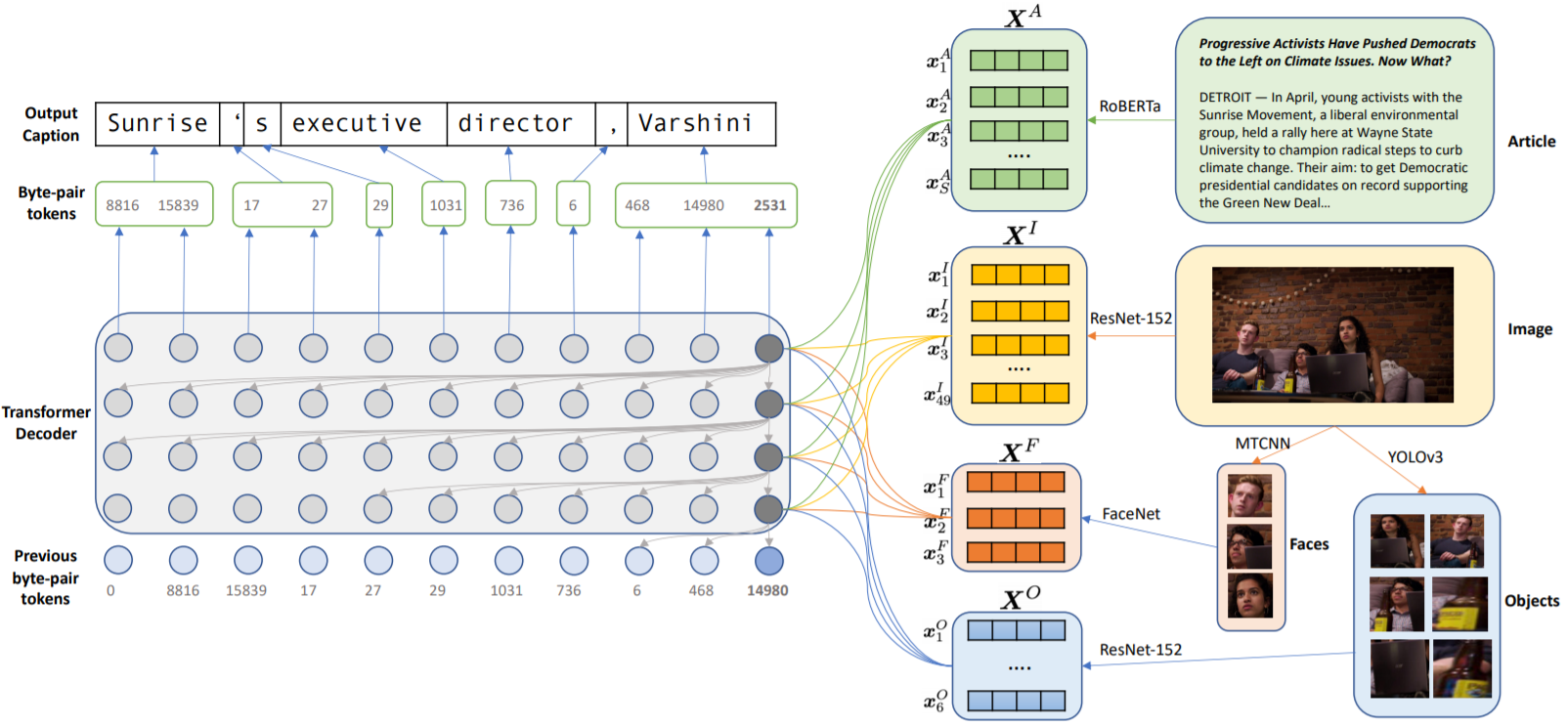
Transform and Tell: Entity-Aware News Image Captioning
details
-
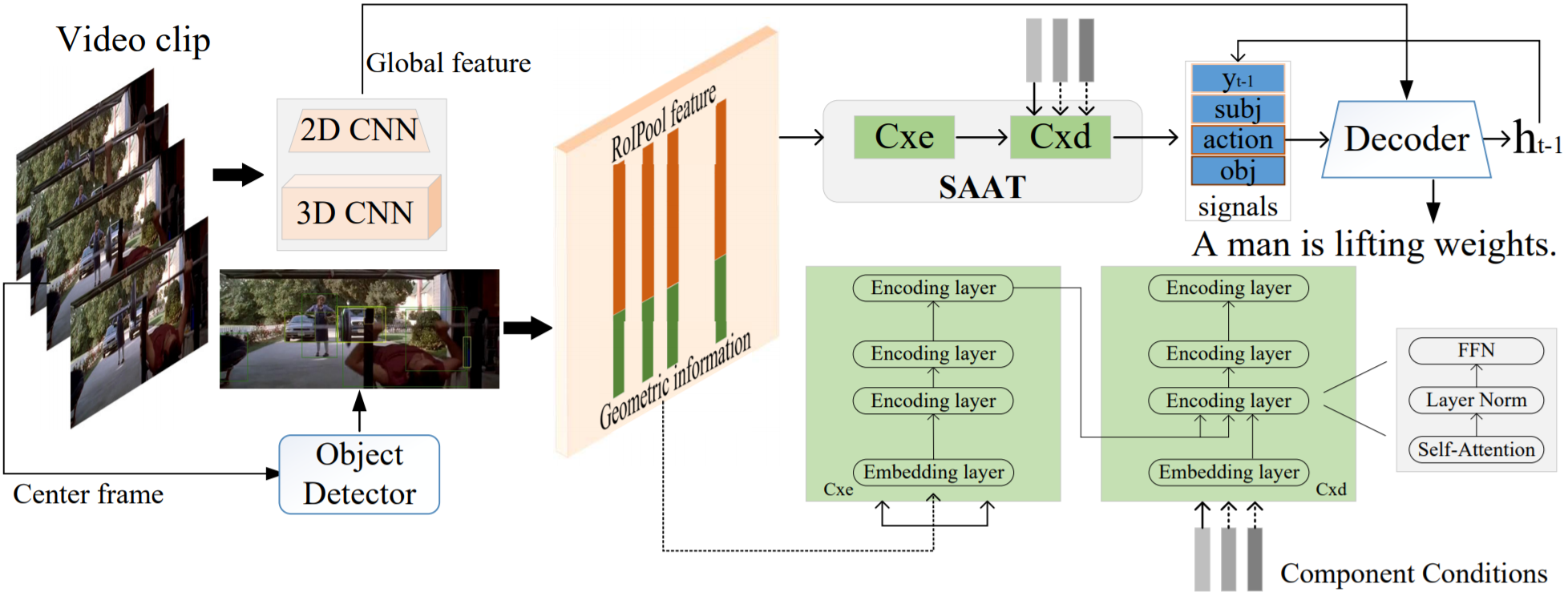
Syntax-Aware Action Targeting for Video Captioning
Dacheng Taodetails
-
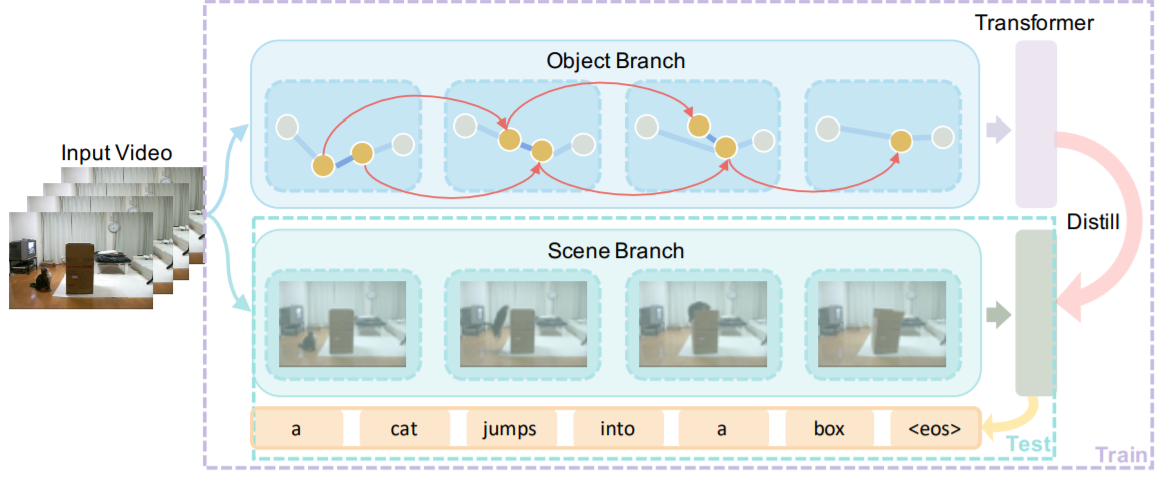
Spatio-Temporal Graph for Video Captioning With Knowledge Distillation
details
-
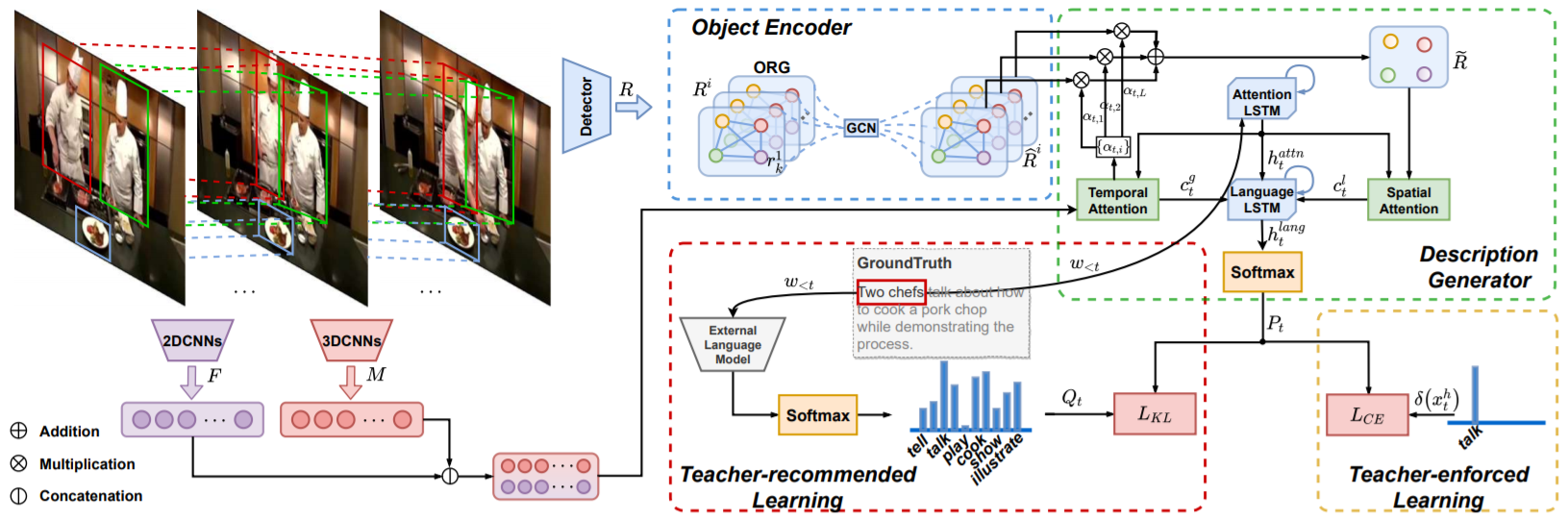
Object Relational Graph With Teacher-Recommended Learning for Video Captioning
details
-
ActBERT: Learning Global-Local Video-Text Representations
oraldetails
-
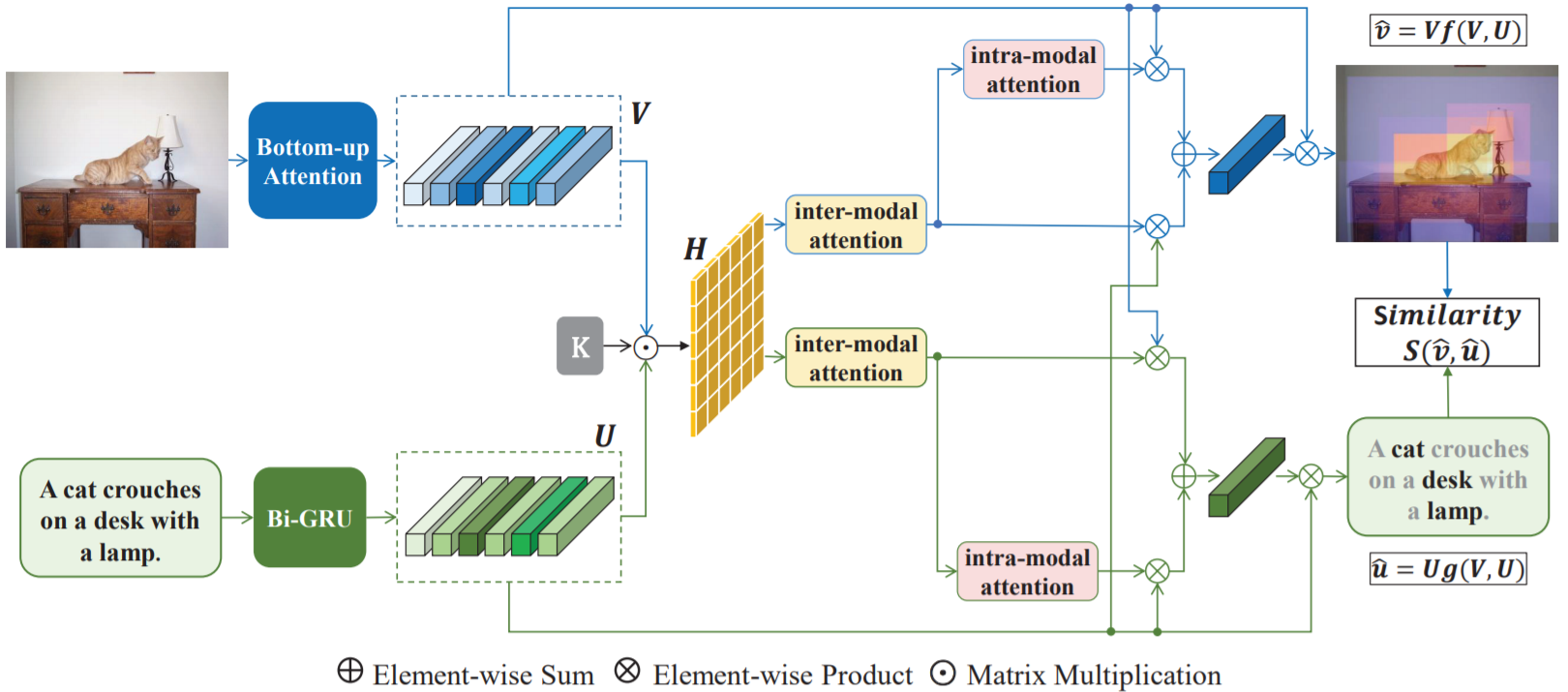
Context-Aware Attention Network for Image-Text Retrieval
details
-
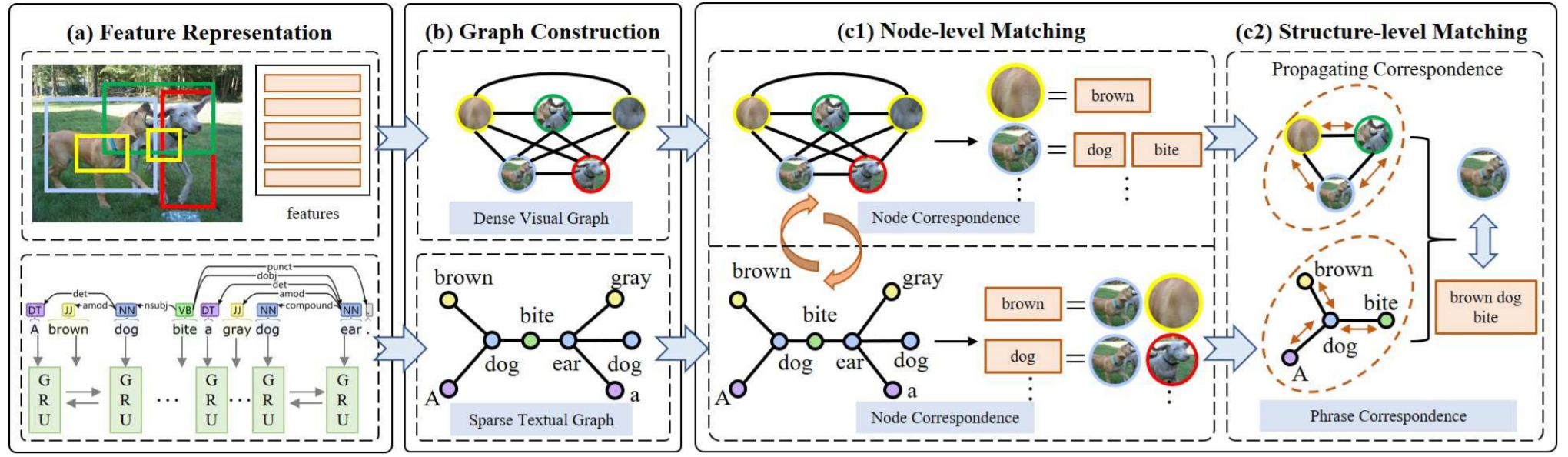
Graph Structured Network for Image-Text Matching
details
-
IMRAM: Iterative Matching With Recurrent Attention Memory for Cross-Modal Image-Text Retrieval
details
-
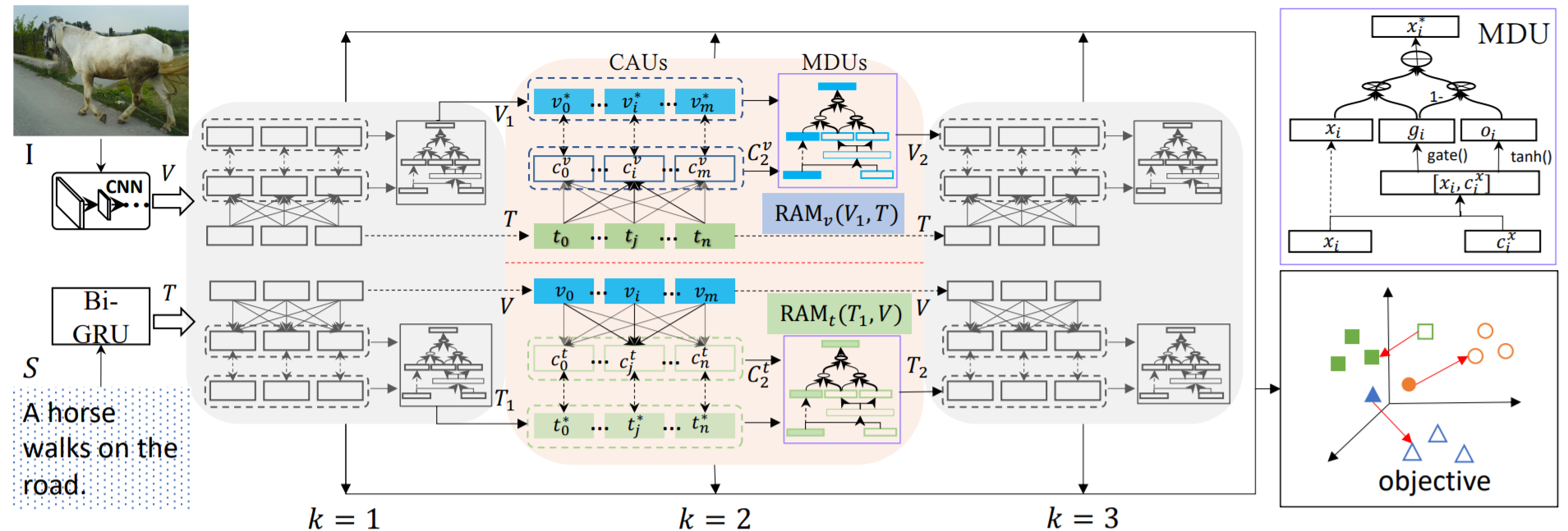
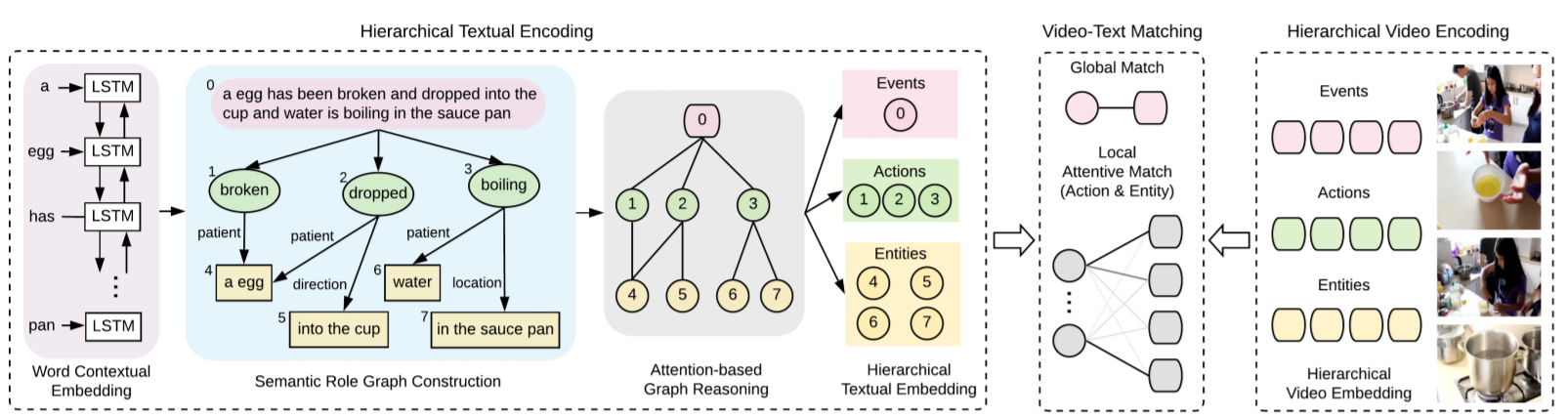
Fine-Grained Video-Text Retrieval With Hierarchical Graph Reasoning
Shizhe Chendetails
-
VIOLIN: A Large-Scale Dataset for Video-and-Language Inference
details
-
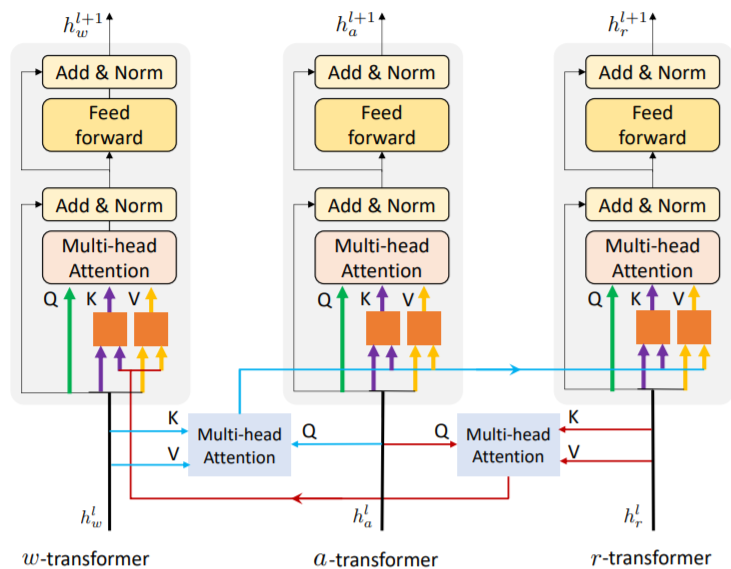
12-in-1: Multi-Task Vision and Language Representation Learning
Jiasen Ludetails


-
Counterfactual Vision and Language Learning
oraldetails
-
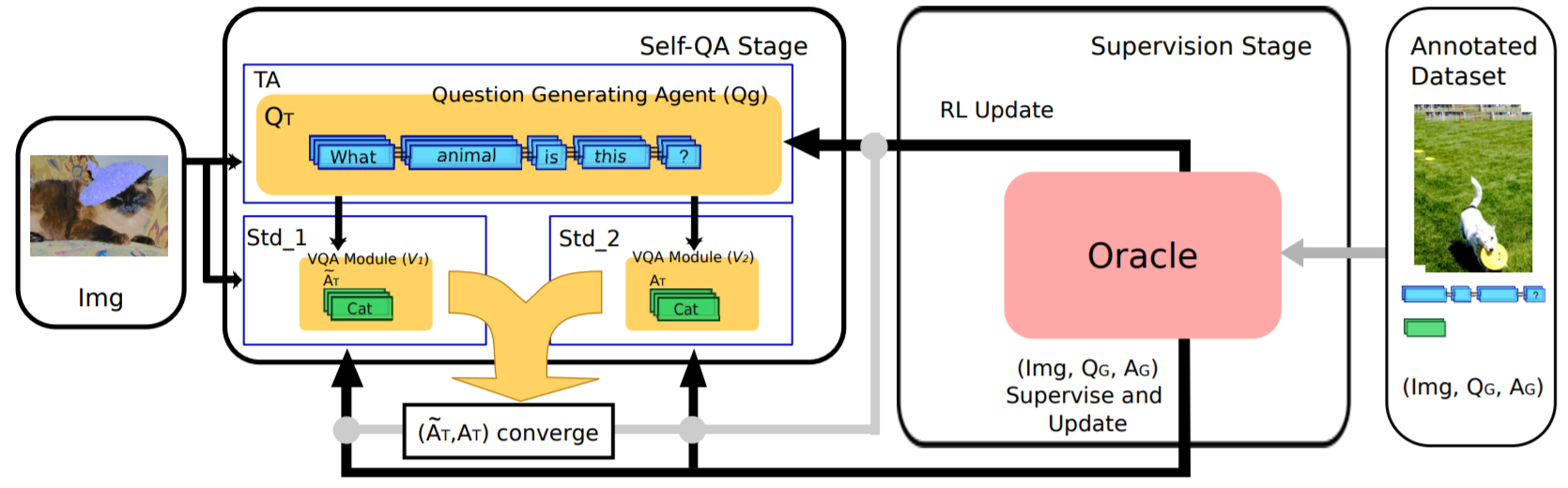
TA-Student VQA: Multi-Agents Training by Self-Questioning
oraldetails
-
SQuINTing at VQA Models: Introspecting VQA Models With Sub-Questions
oraldetails
-
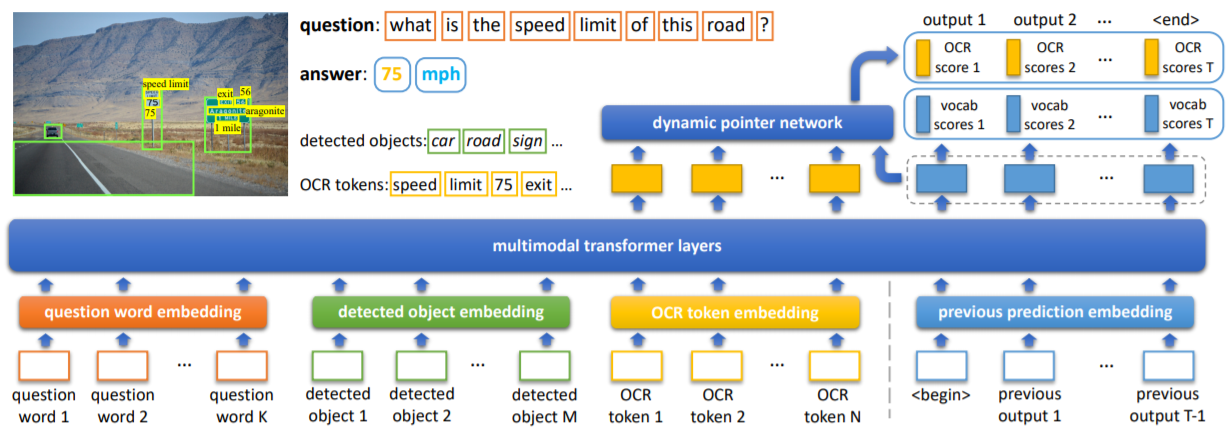
Iterative Answer Prediction With Pointer-Augmented Multimodal Transformers for TextVQA
oraldetails
-
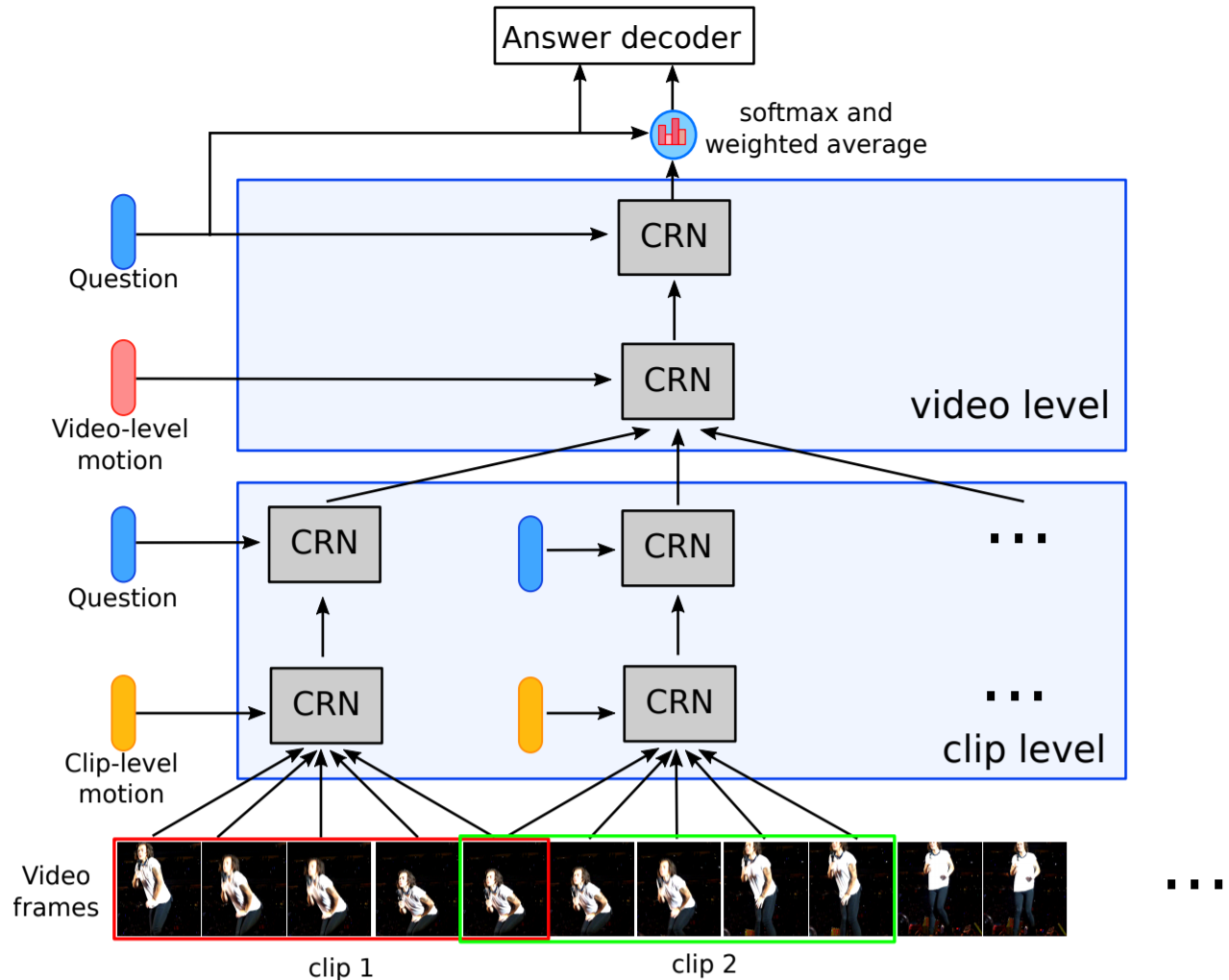
Hierarchical Conditional Relation Networks for Video Question Answering
oraldetails
-
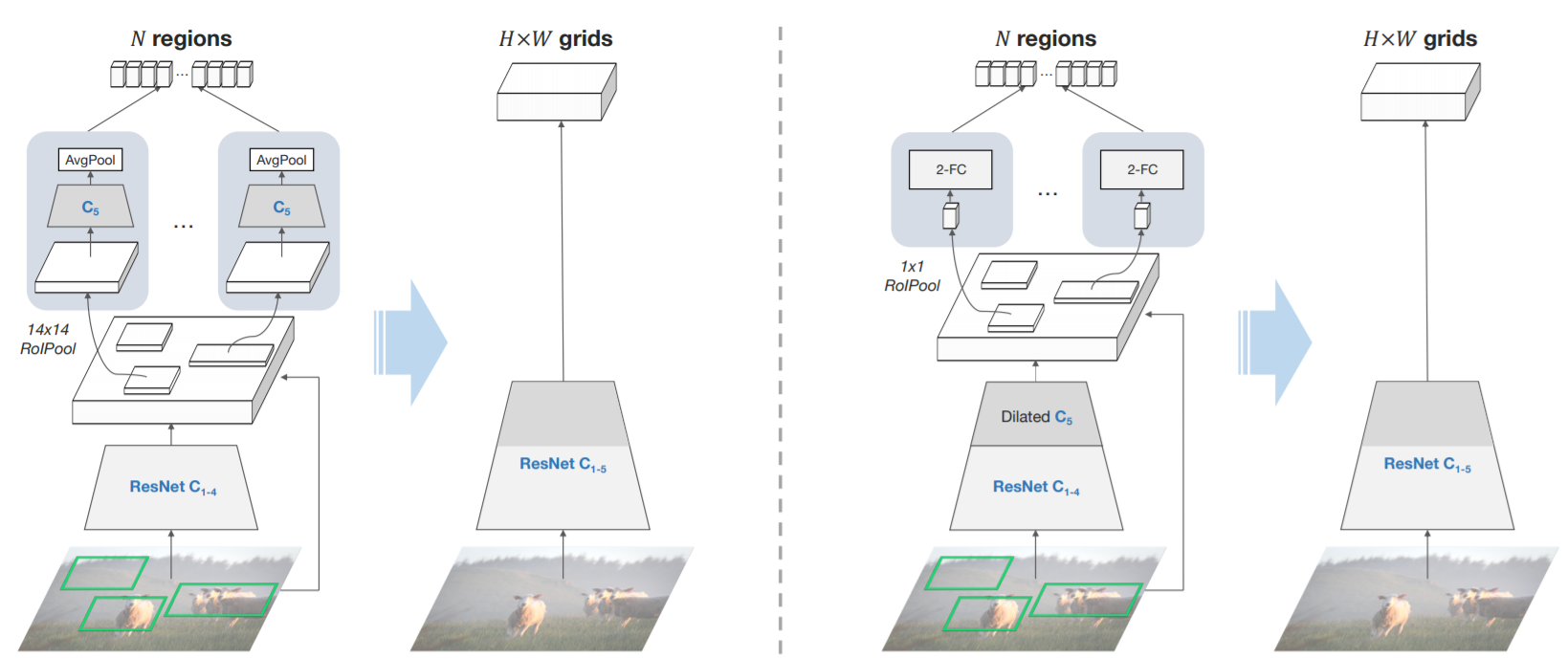
In Defense of Grid Features for Visual Question Answering
details


-
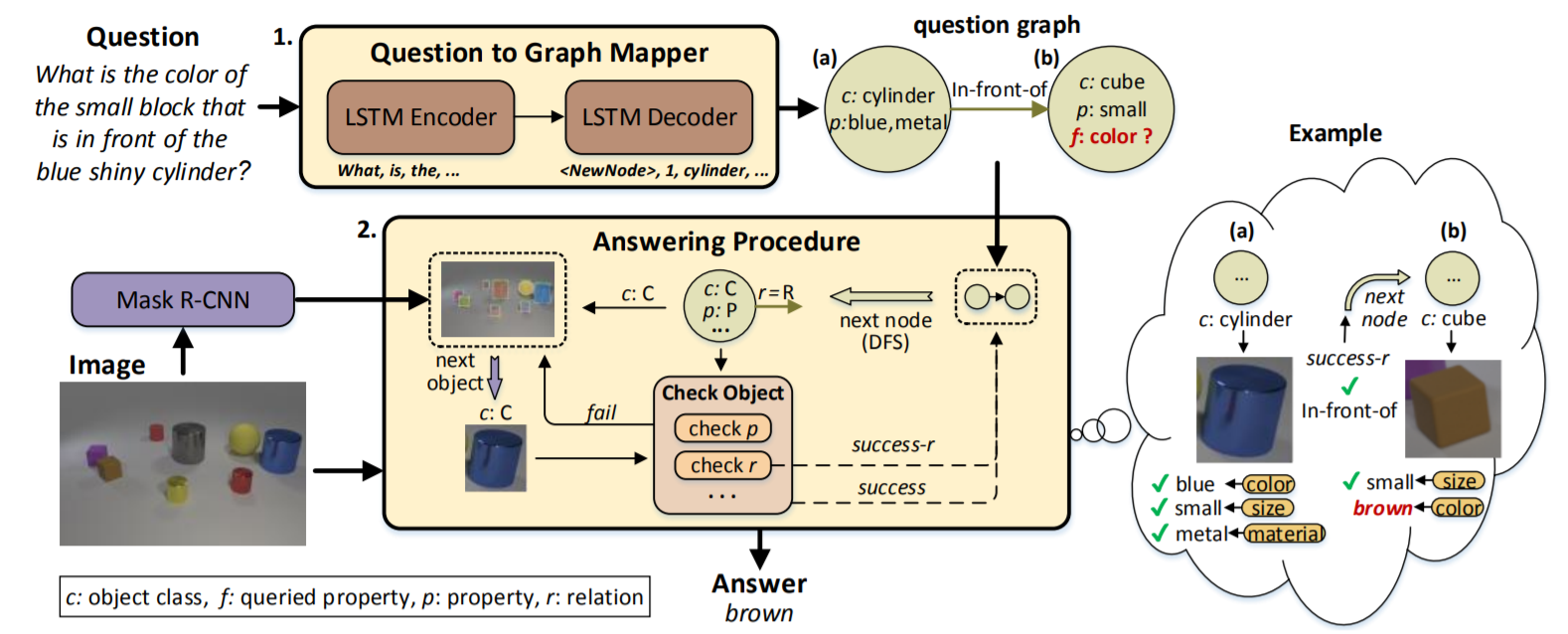
VQA with No Questions-Answers Training
details
-
Counterfactual Samples Synthesizing for Robust Visual Question Answering
details

-
Multi-Task Collaborative Network for Joint Referring Expression Comprehension and Segmentation
oraldetails
-
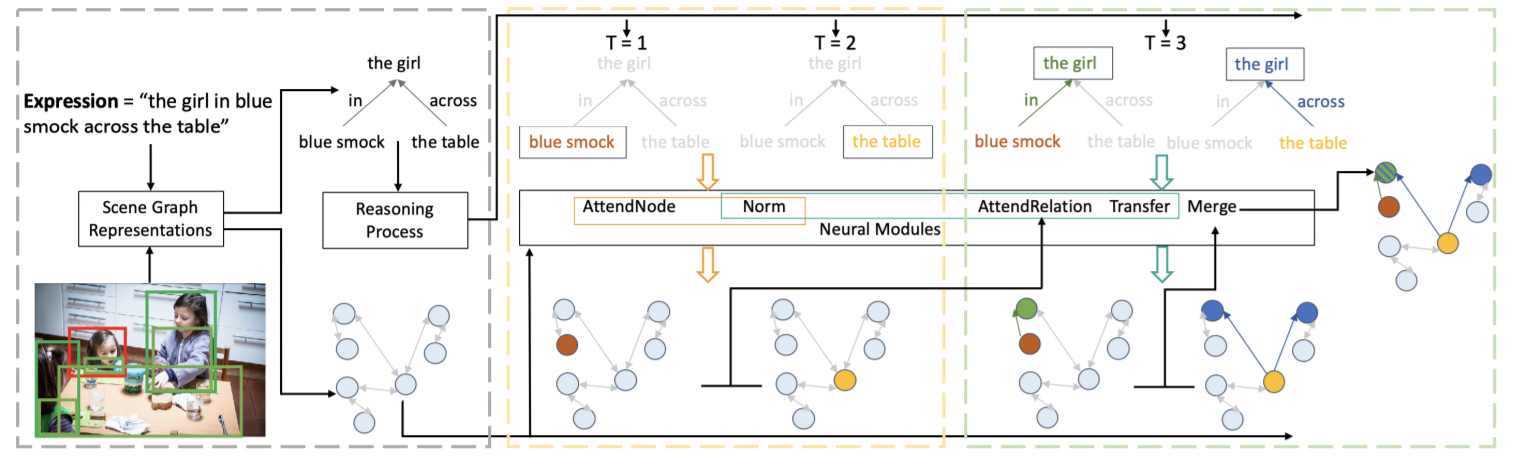
Graph-Structured Referring Expression Reasoning in the Wild
oraldetails
-
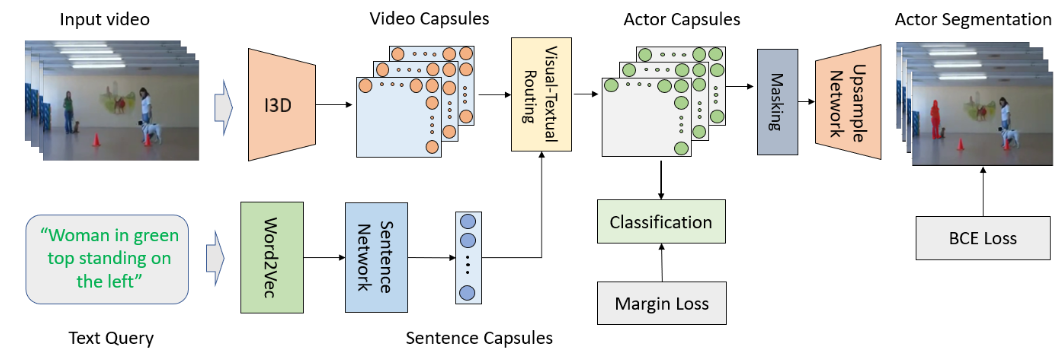
Visual-textual Capsule Routing for Text-based Video Segmentation
oraldetails
-
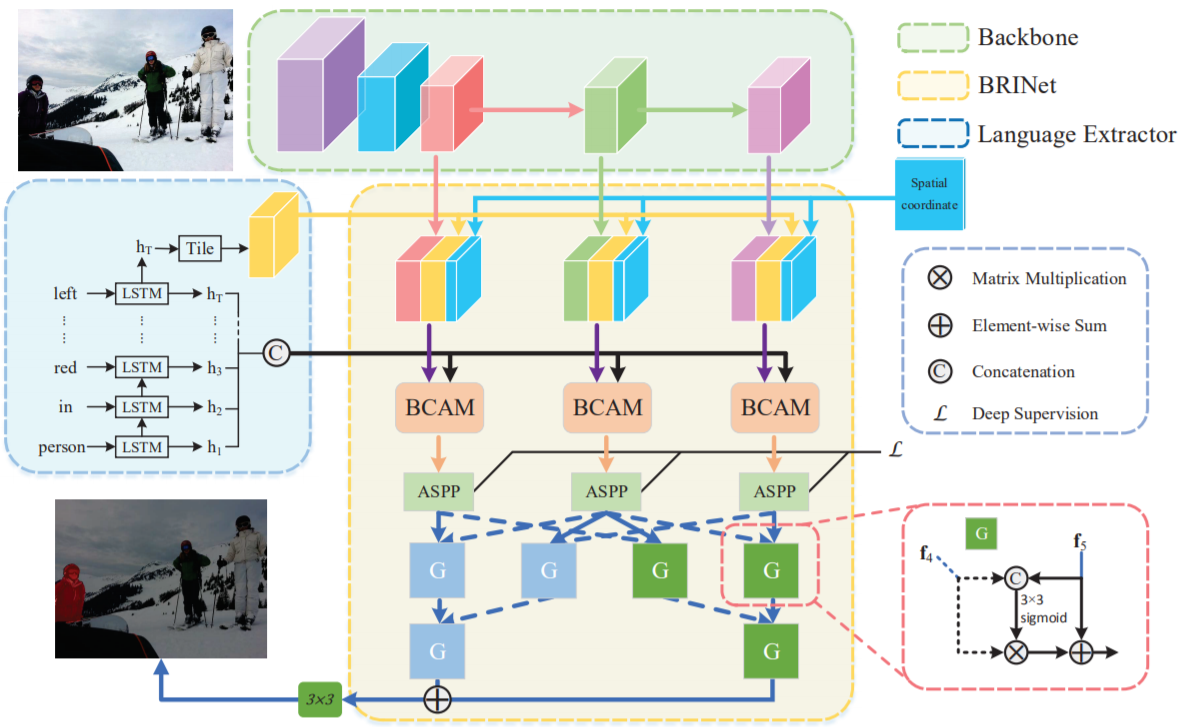
Bi-Directional Relationship Inferring Network for Referring Image Segmentation
Huchuan Ludetails
-
Cops-Ref: A New Dataset and Task on Compositional Referring Expression Comprehension
Qi Wudetails
-
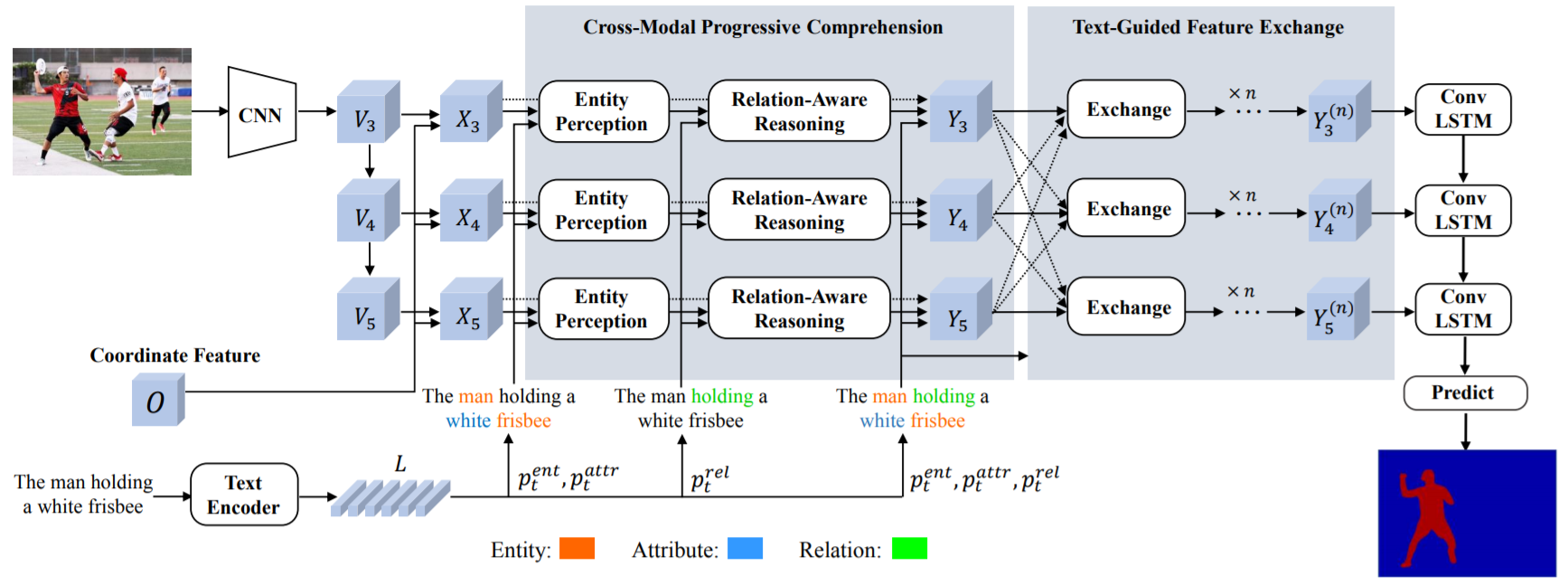
Referring Image Segmentation via Cross-Modal Progressive Comprehension
Si Liudetails
-
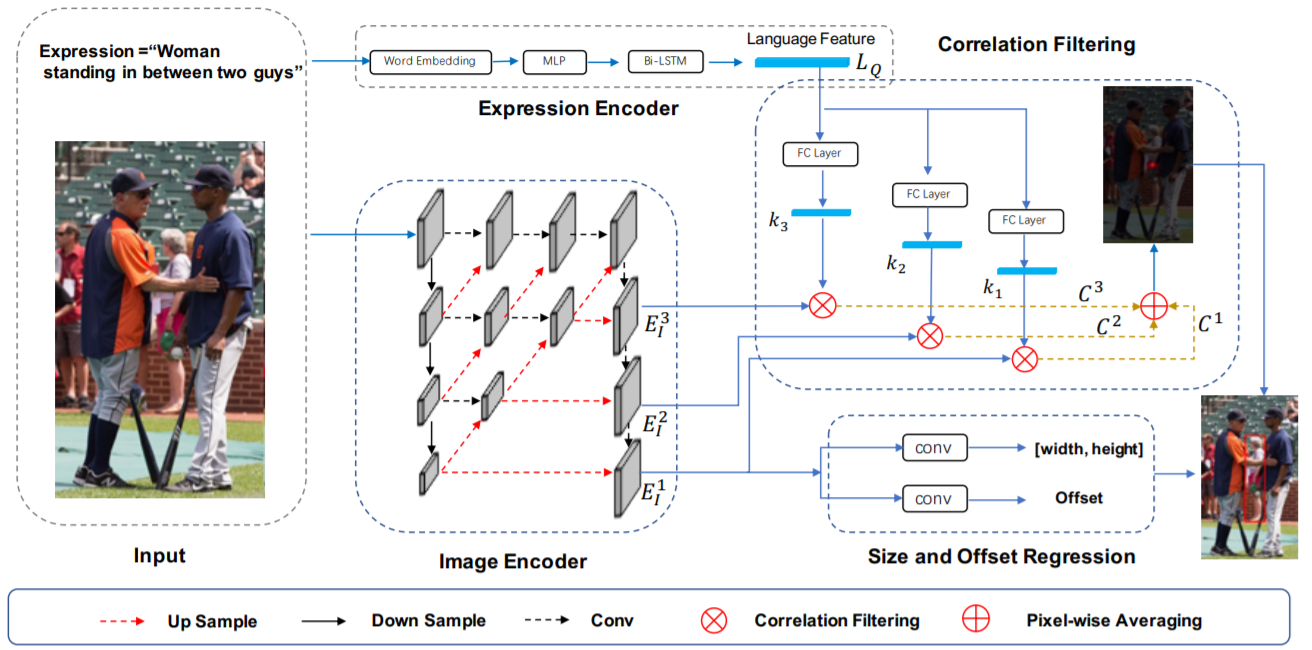
A Real-Time Cross-Modality Correlation Filtering Method for Referring Expression Comprehension
Si Liudetails
-
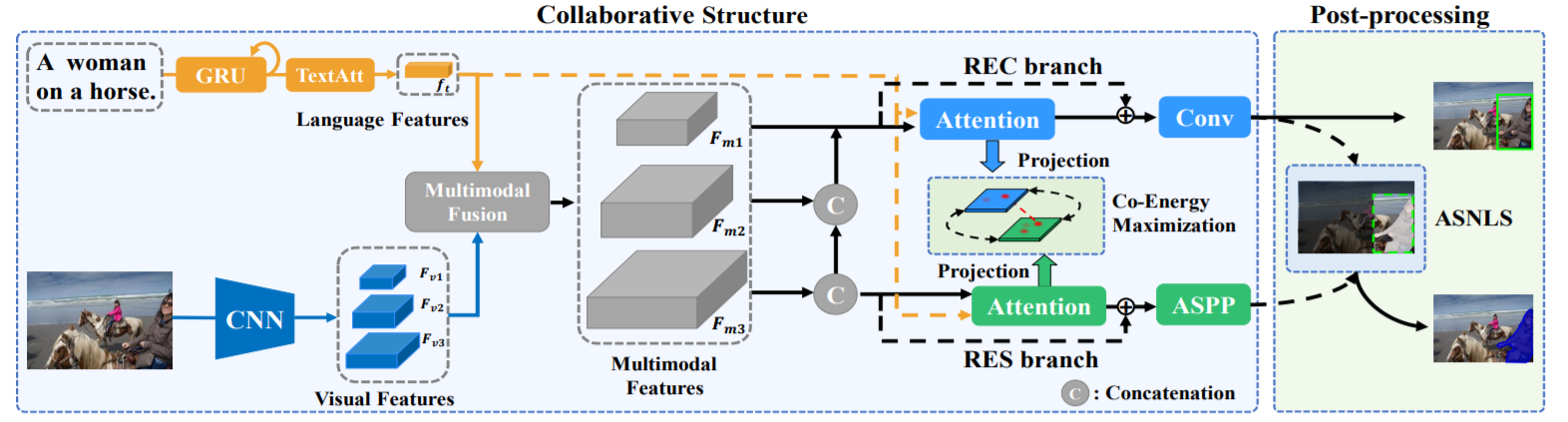
PhraseCut: Language-Based Image Segmentation in the Wild
Adobedetails


-
Dense Regression Network for Video Grounding
details
-
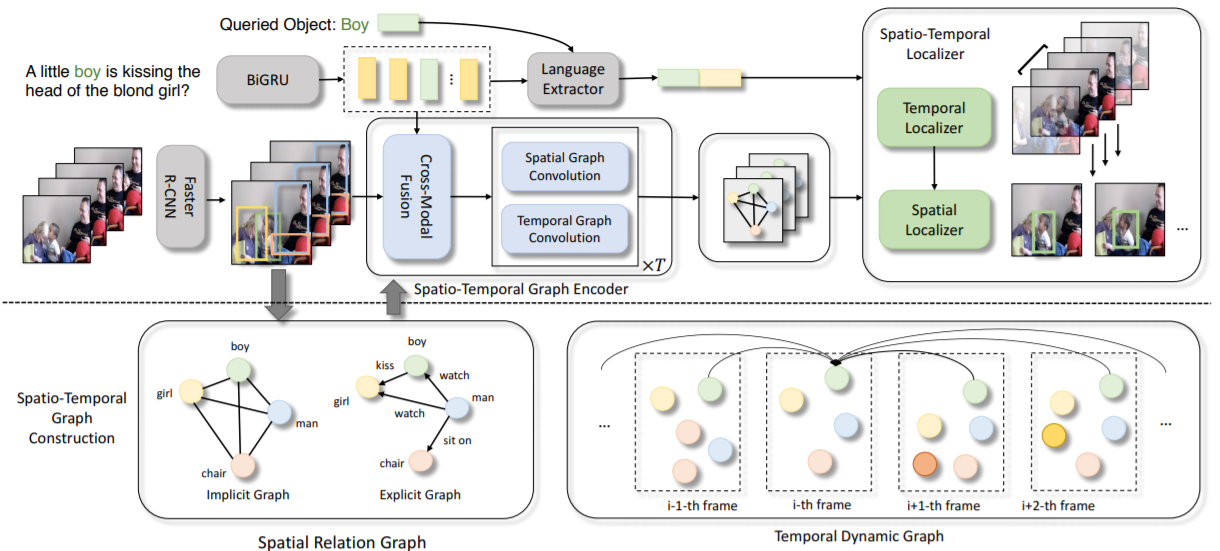
Video Object Grounding using Semantic Roles in Language Description
Arka Sadhudetails
-
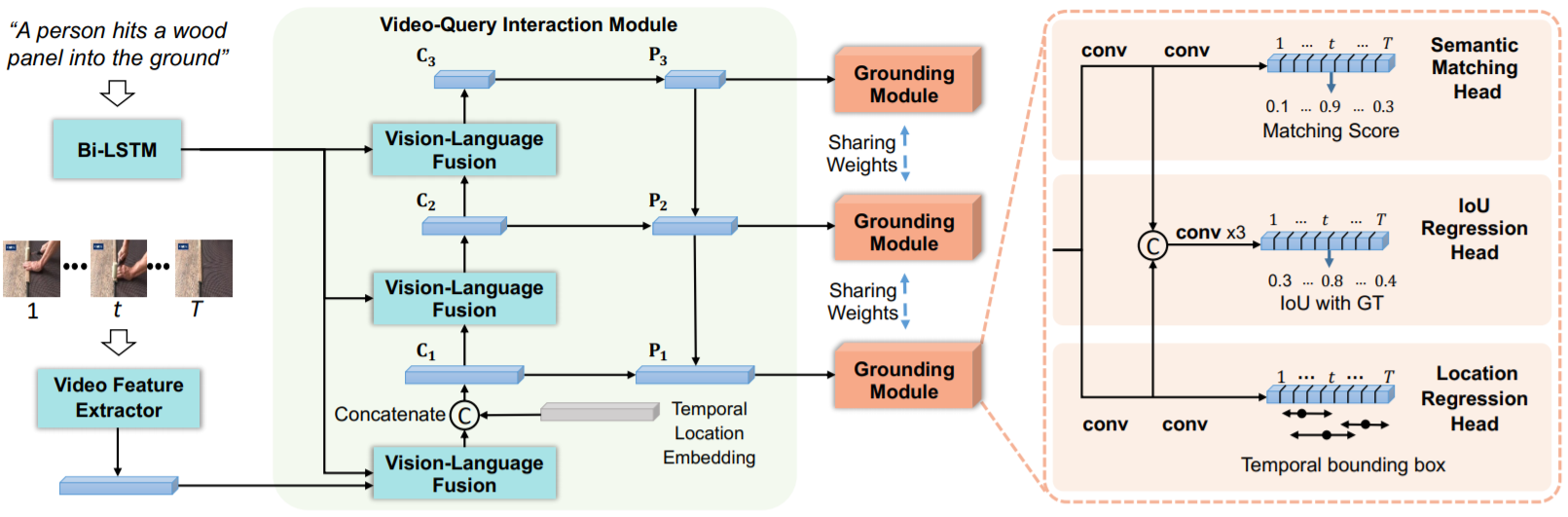
Where Does It Exist: Spatio-Temporal Video Grounding for Multi-Form Sentences
Alibabadetails
-
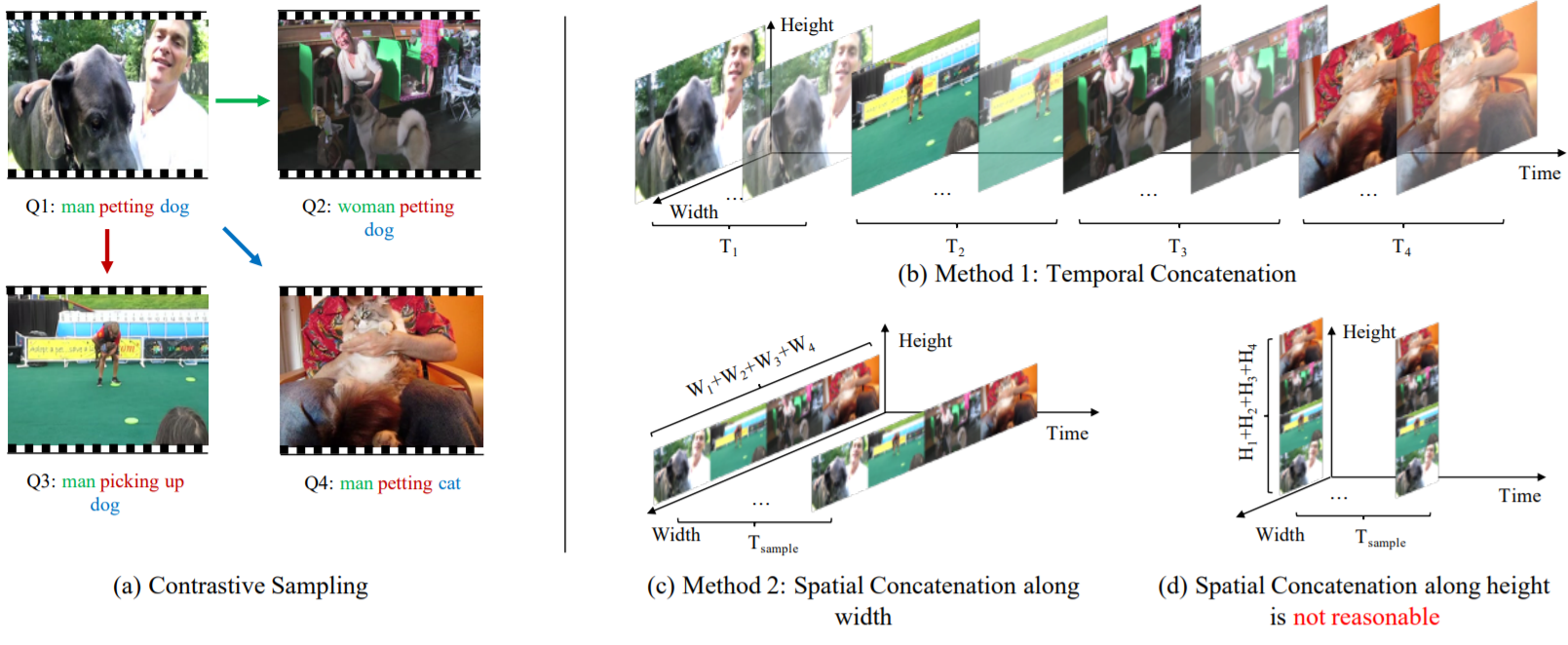
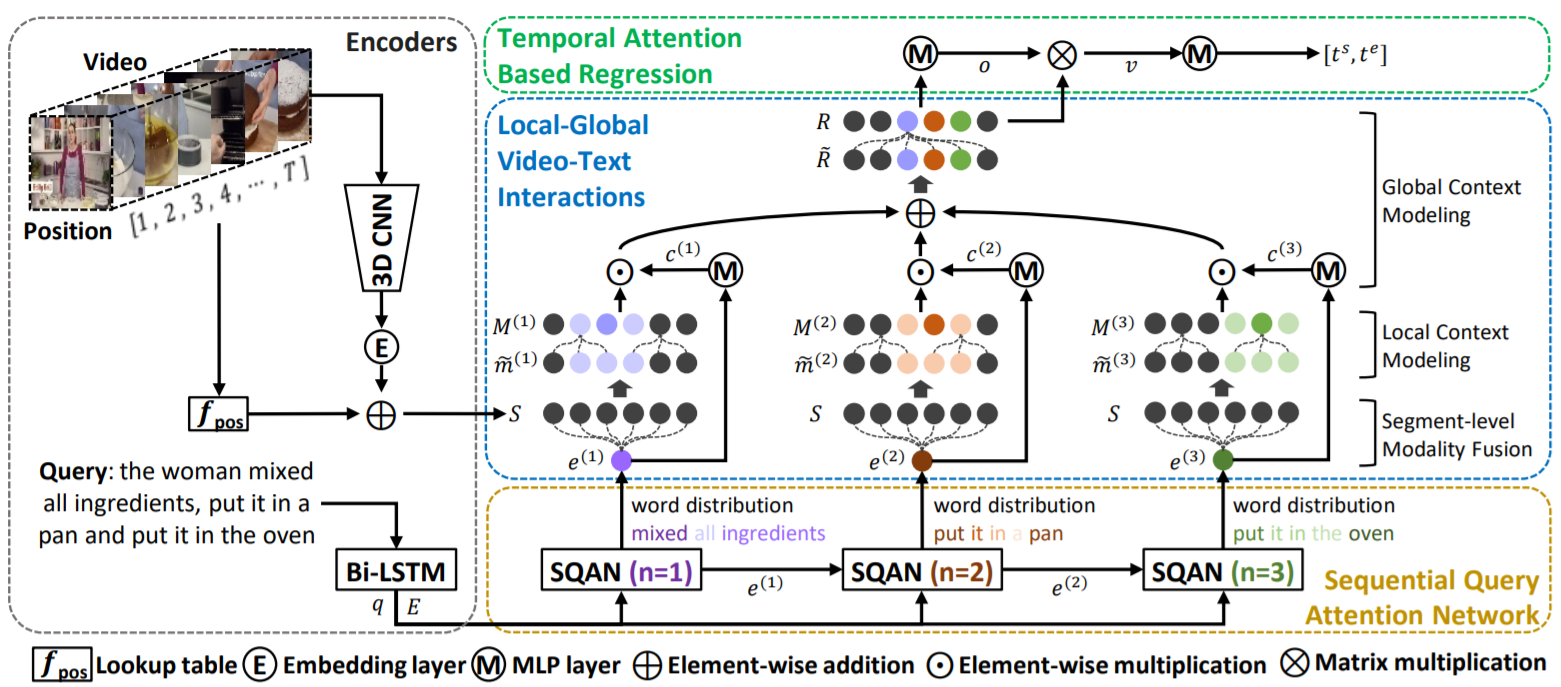
Local-Global Video-Text Interactions for Temporal Grounding
details
-
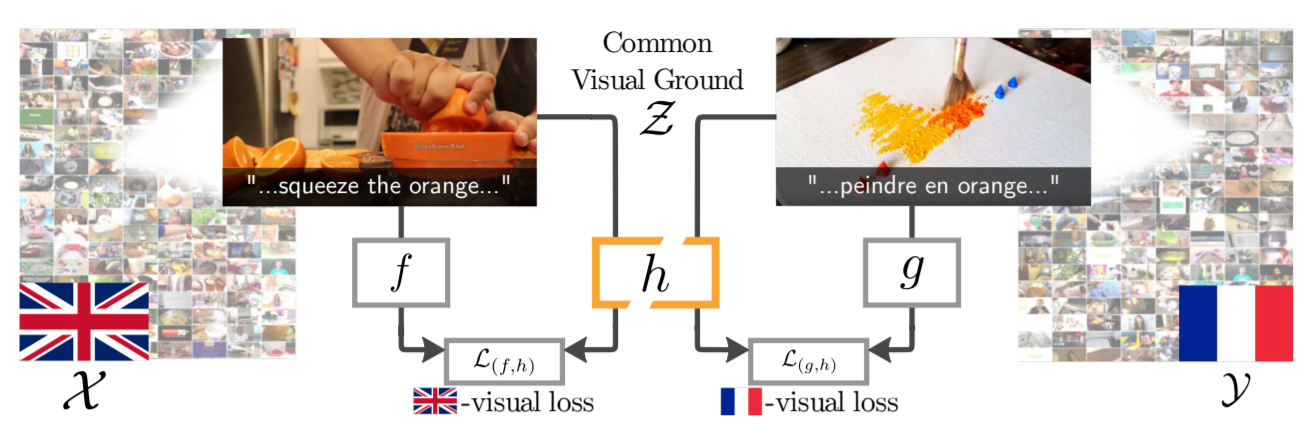
Visual Grounding in Video for Unsupervised Word Translation
details
-
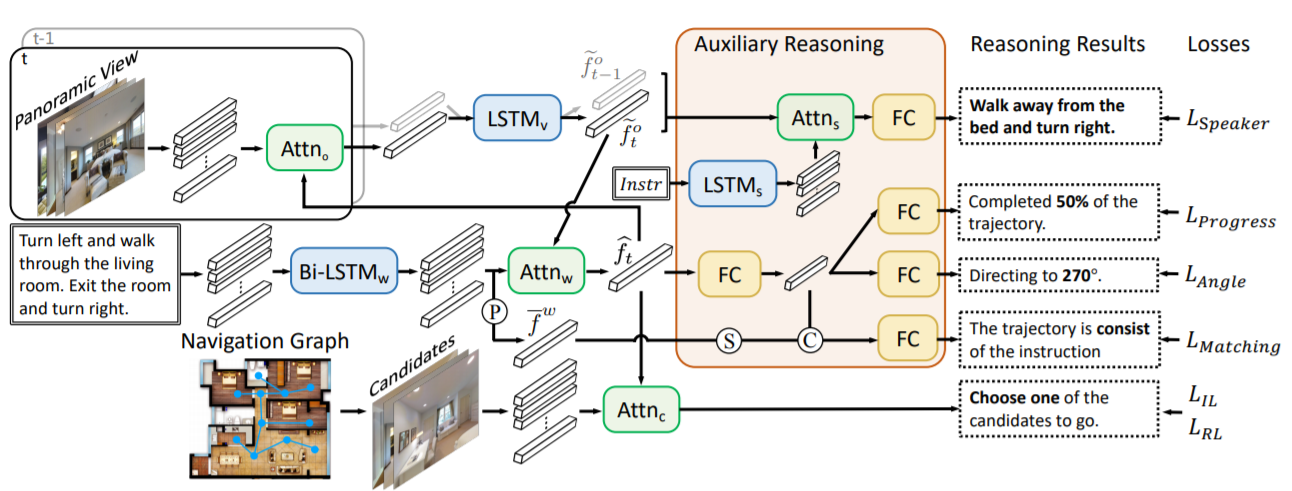
Vision-Language Navigation With Self-Supervised Auxiliary Reasoning Tasks
oraldetails
-
REVERIE: Remote Embodied Visual Referring Expression in Real Indoor Environments
oralPeter Anderson Qi Wu, William Yang Wangdetails
-
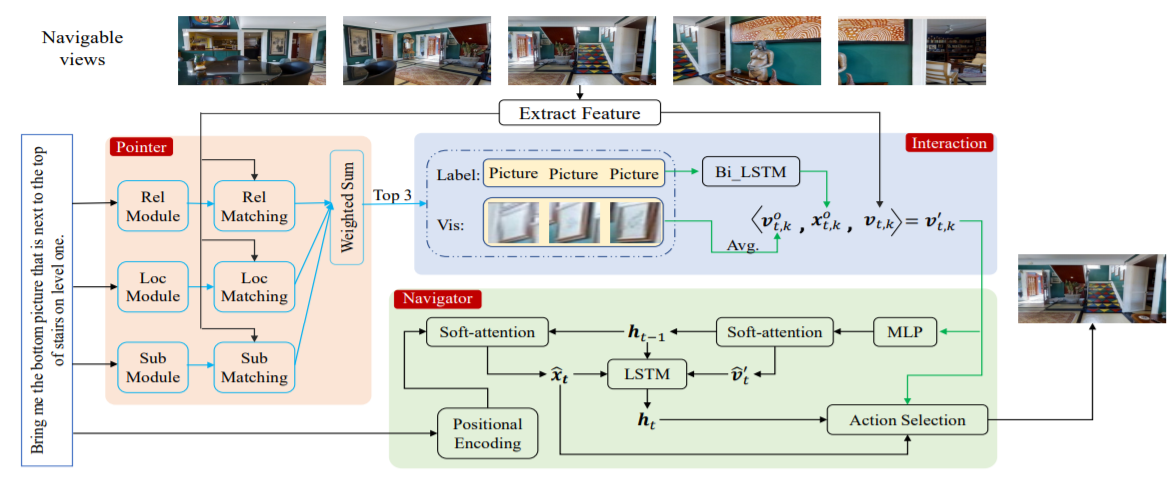
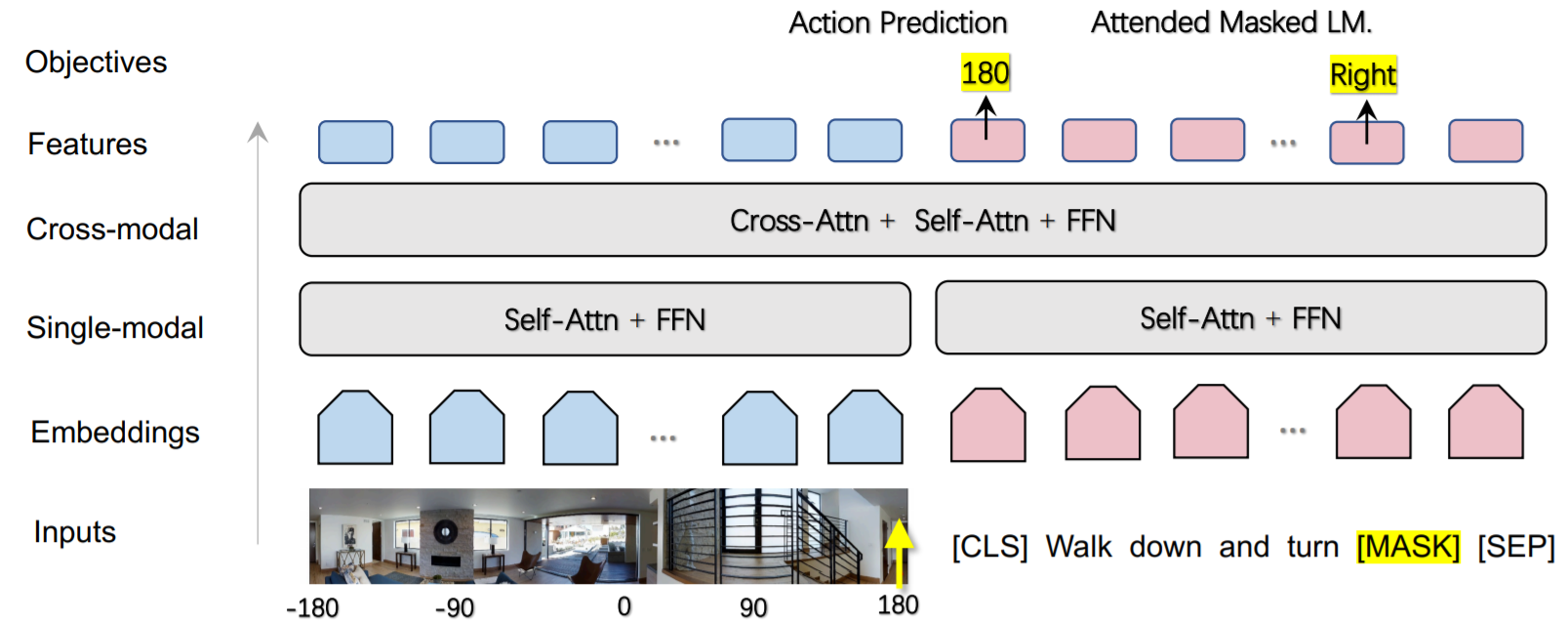
Towards Learning a Generic Agent for Vision-and-Language Navigation via Pre-training
details
-
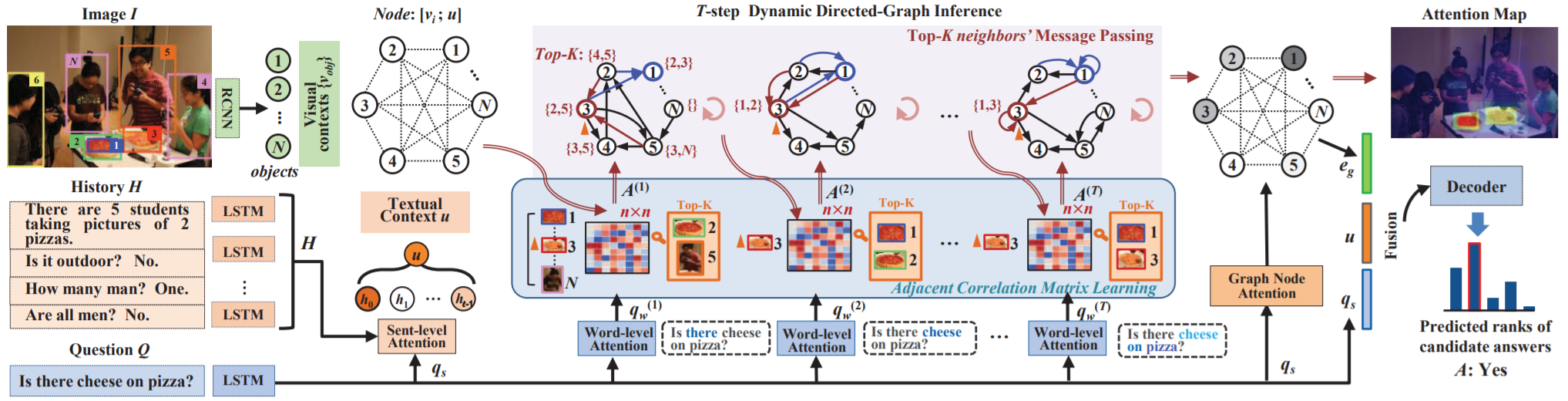
Iterative Context-Aware Graph Inference for Visual Dialog
oralZheng-jun Zhadetails
-
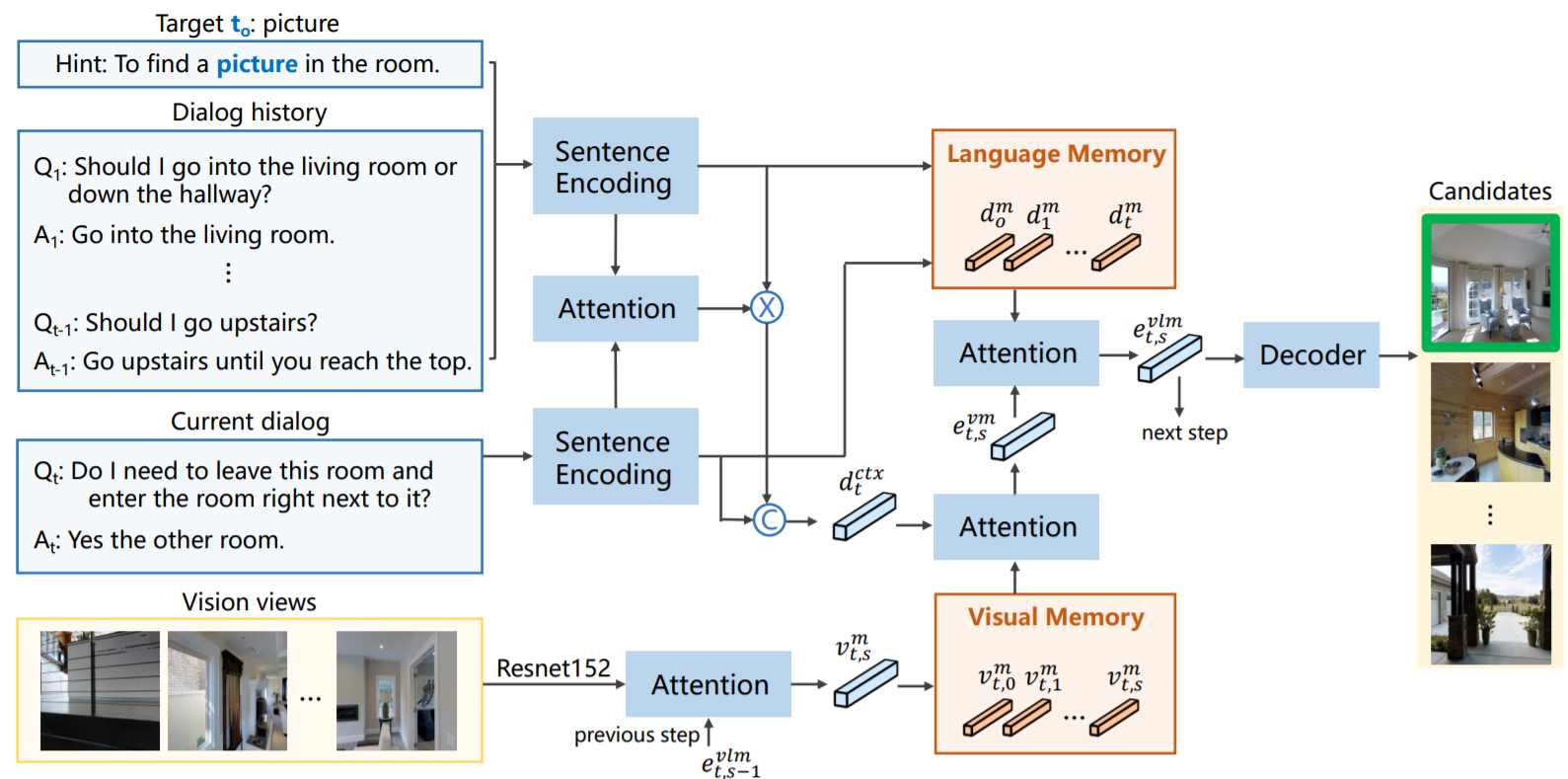
Vision-Dialog Navigation by Exploring Cross-modal Memory
details
-
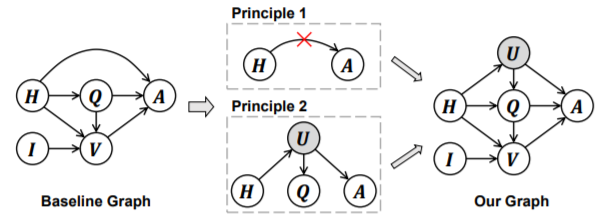
Two Causal Principles for Improving Visual Dialog
Hanwang Zhangdetails
-
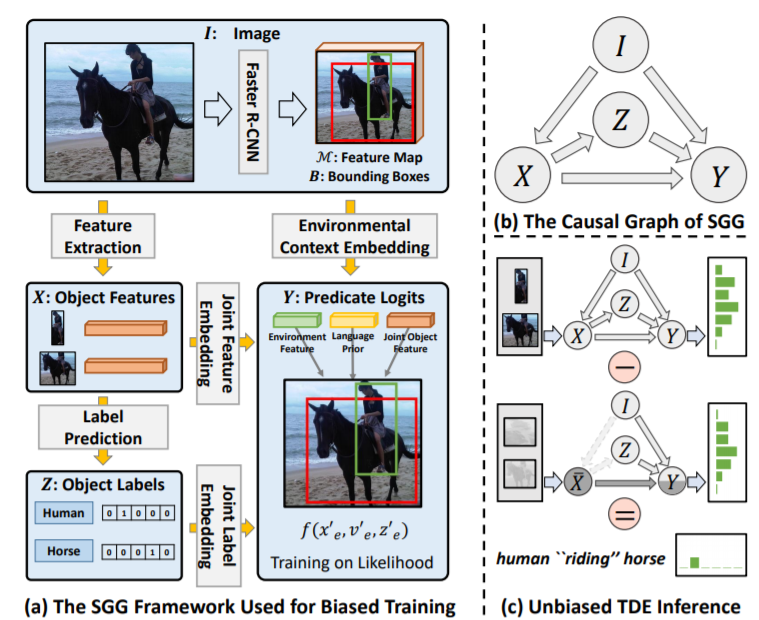
Unbiased Scene Graph Generation From Biased Training
oralHanwang Zhangdetails
-
GPS-Net: Graph Property Sensing Network for Scene Graph Generation
oralDacheng Taodetails
-
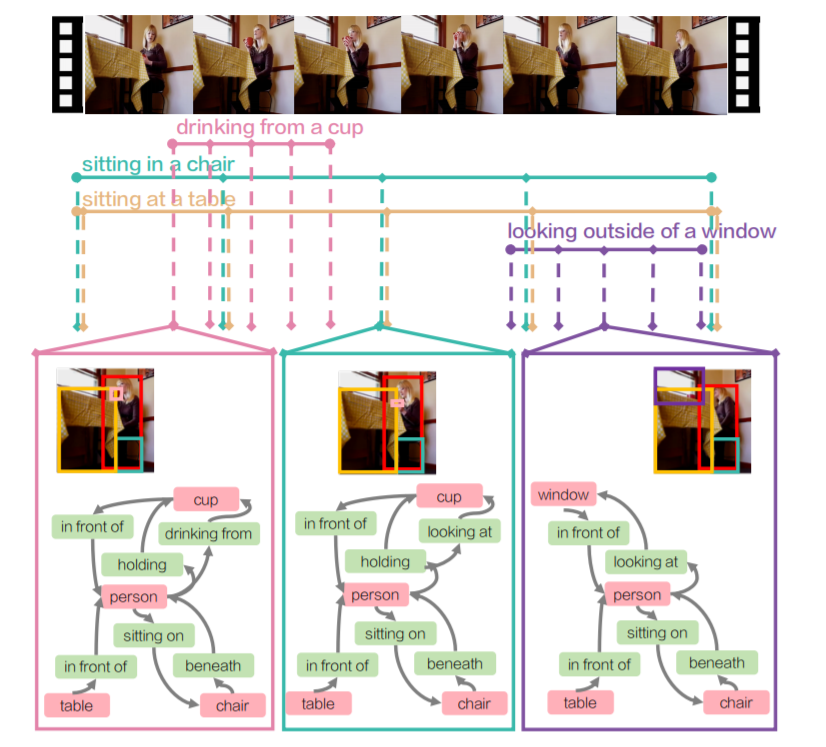
Action Genome: Actions as Composition of Spatio-temporal Scene Graphs
Feifei Lidetails

- SmallBigNet: Integrating Core and Contextual Views for Video Classification
Yu Qiao - 3DV: 3D Dynamic Voxel for Action Recognition in Depth Video
- Video Modeling with Correlation Networks
Facebook AI - X3D: Expanding Architectures for Efficient Video Recognition
Facebook AI - Regularization on Spatio-Temporally Smoothed Feature for Action Recognition
- Listen to Look: Action Recognition by Previewing Audio
- Speech2Action: Cross-modal Supervision for Action Recognition
VGG - Uncertainty-aware Score Distribution Learning for Action Quality Assessment
- FineGym: A Hierarchical Video Dataset for Fine-grained Action Understanding
Dahua Lin - Something-Else: Compositional Action Recognition with Spatial-Temporal Interaction Networks
- TEA: Temporal Excitation and Aggregation for Action Recognition
- Intra- and Inter-Action Understanding via Temporal Action Parsing
Dahua lin - Temporal Pyramid Network for Action Recognition
- Multi-Modal Domain Adaptation for Fine-Grained Action Recognition
- Context Aware Graph Convolution for Skeleton-Based Action Recognition
Dacheng Tao - PREDICT & CLUSTER: Unsupervised Skeleton Based Action Recognition
- Semantics-Guided Neural Networks for Efficient Skeleton-Based Human Action Recognition
MSRA - Skeleton-Based Action Recognition with Shift Graph Convolutional Network
- Disentangling and Unifying Graph Convolutions for Skeleton-Based Action Recognition
Wanli Ouyang
- G-TAD: Sub-Graph Localization for Temporal Action Detection
- Learning Temporal Co-Attention Models for Unsupervised Video Action Localization
- Weakly-Supervised Action Localization by Generative Attention Modeling
- Learning to Discriminate Information for Online Action Detection
- Action Segmentation with Joint Self-Supervised Temporal Domain Adaptation
- SCT: Set Constrained Temporal Transformer for Set Supervised Action Segmentation
- Improving Action Segmentation via Graph Based Temporal Reasoning
- Set-Constrained Viterbi for Set-Supervised Action Segmentation
- Large Scale Video Representation Learning via Relational Graph Clustering
- Screencast Tutorial Video Understanding
- Evolving Losses for Unsupervised Video Representation Learning
- A Multigrid Method for Efficiently Training Video Models
Kaiming He
-
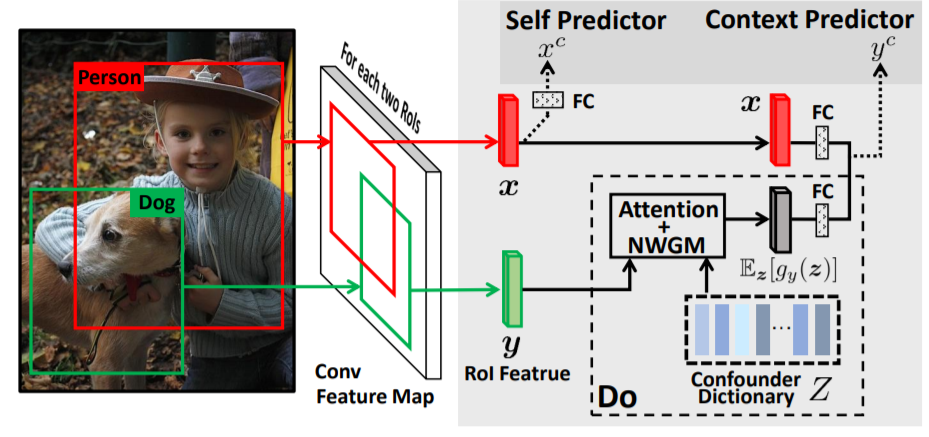
Visual Commonsense R-CNN
Hanwang Zhangdetails
-
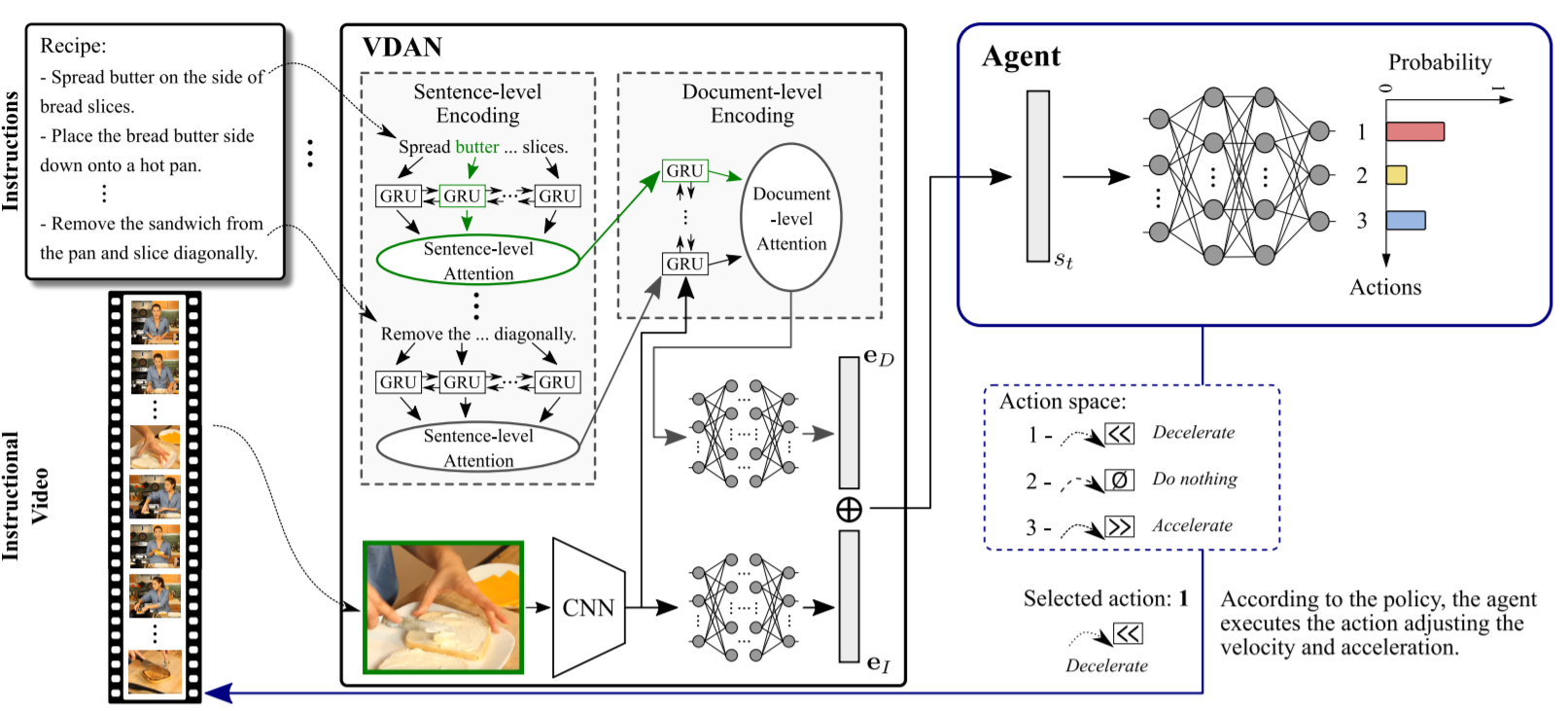
Straight to the Point: Fast-forwarding Videos via Reinforcement Learning Using Textual Data
details