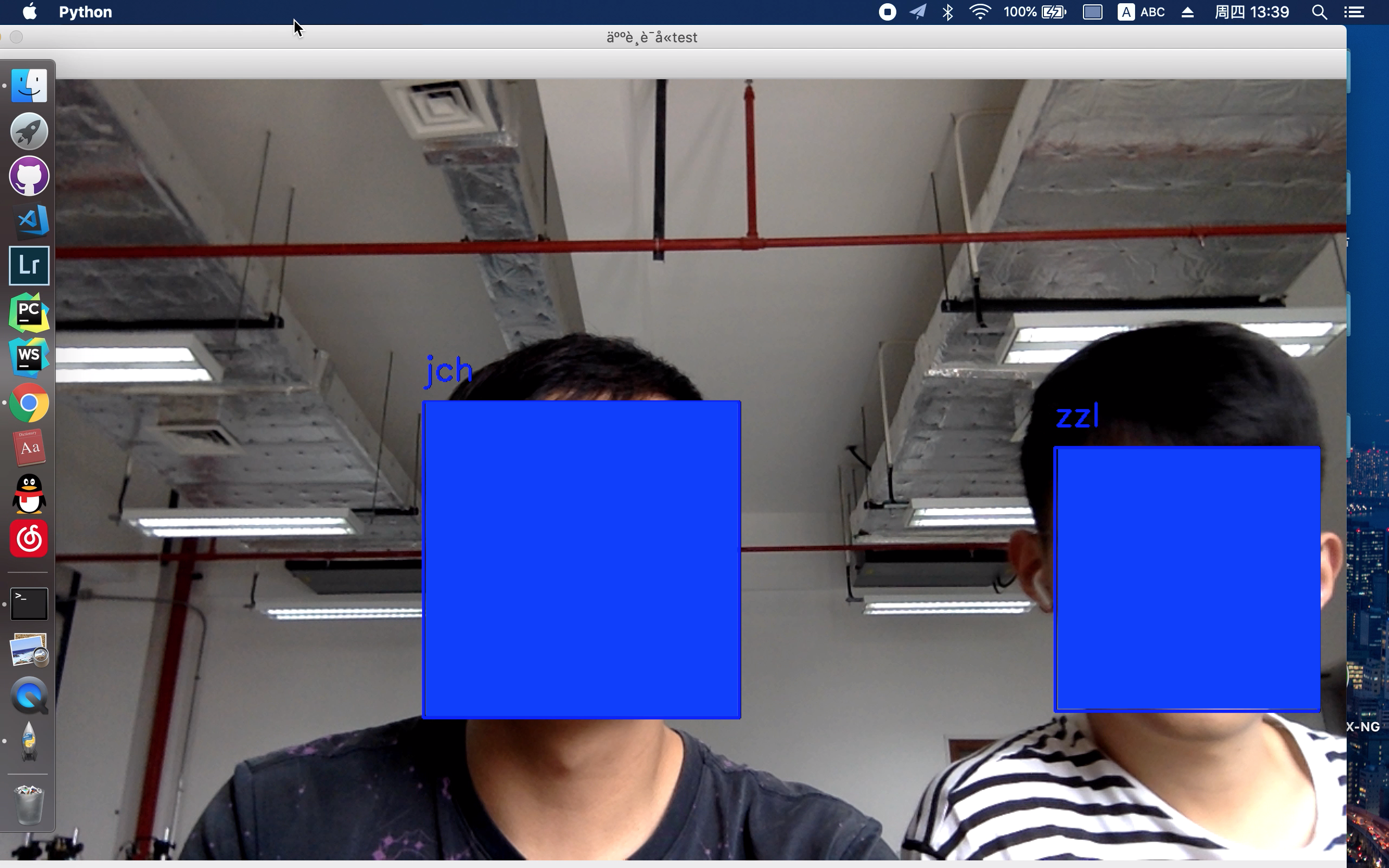
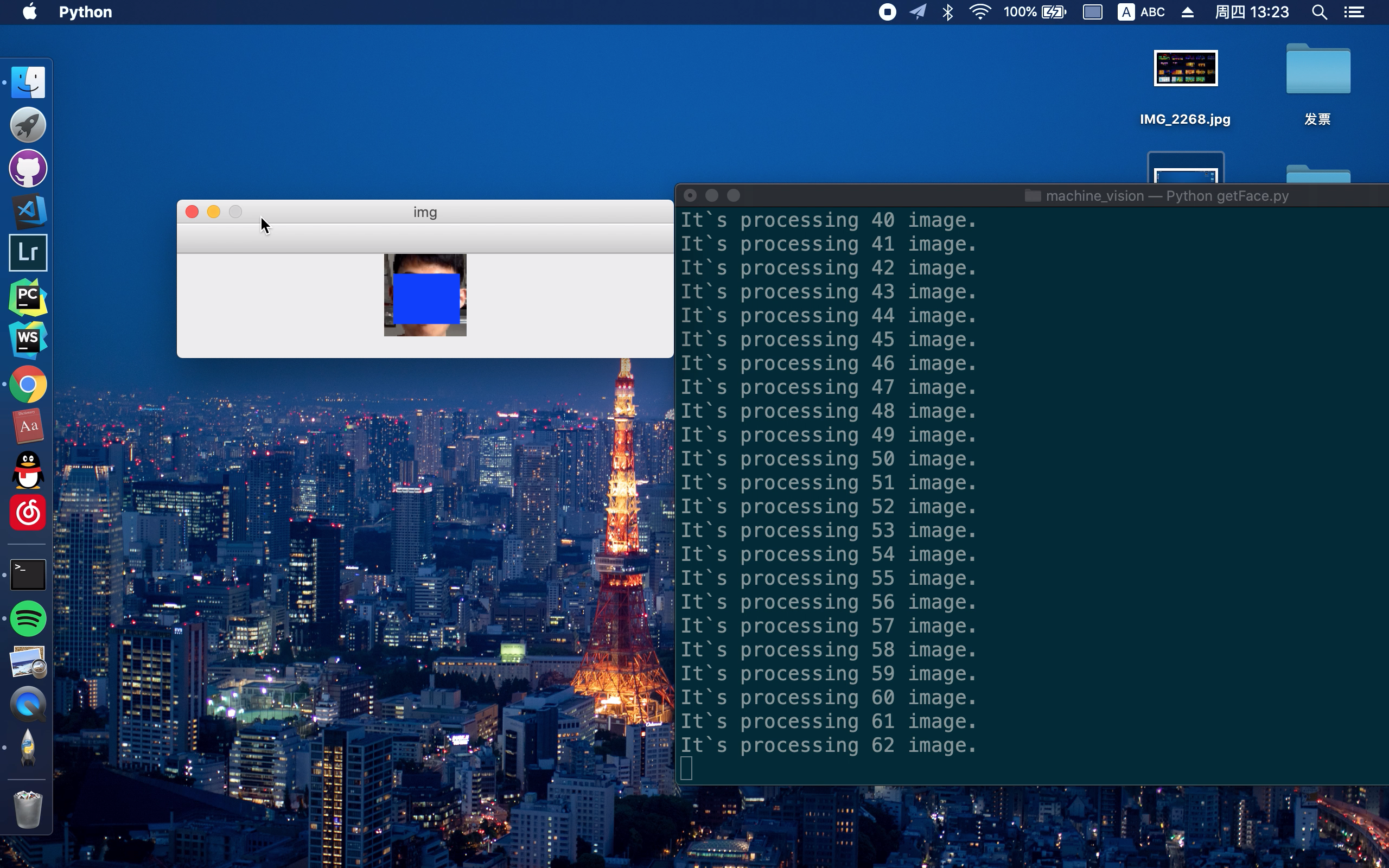
原理是通过oepncv内置的haar算法检测人脸,仅截取人脸部分图片,保存为64*64的png格式图片。png是无损图片压缩,而jpg是有损的,做图像处理当然是无损的好,所以选择png格式。
import cv2
import os
out_dir = 'xxx'
if not os.path.exists(out_dir):
os.makedirs(out_dir)
# 获取分类器
haar = cv2.CascadeClassifier('haarcascade_frontalface_default.xml')
# 打开摄像头 参数为输入流,可以为摄像头或视频文件
camera = cv2.VideoCapture(0)
n = 1
while 1:
if n <= 100:
print('It`s processing %s image.' % n)
# 读帧
success, img = camera.read()
# 将图像转化为灰度图像
gray_img = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
# scaleFactor 图像尺寸减小的比例
# minNeighobrs 目标监测到5次才算真正的目标
faces = haar.detectMultiScale(image=gray_img, scaleFactor=1.3, minNeighbors=5)
for f_x, f_y, f_w, f_h in faces:
# 裁剪 剩下面部
face = img[f_y:f_y+f_h, f_x:f_x+f_w]
face = cv2.resize(src=face, dsize=(64, 64))
cv2.imshow('img', face)
# png rather than jpg
cv2.imwrite(out_dir+'/'+str(n)+'.png', face)
n += 1
key = cv2.waitKey(30) & 0xff
if key == 27:
break
else:
break在采集人脸图像上,主要通过opencv 调用电脑的摄像头,人在摄像头下作出不同表情,读取摄像头传输的帧,检测人脸并保存。如下图所示。
原理是利用opencv的cv2.face.EigenFaceRecognizer_create()函数,导入人脸数据,进行训练,通过调用返回结果来预测人脸类别,即使用predict()函数,在程序中我只训练了两类,多类的训练方法类似。
import cv2
import os
import numpy as np
def LoadImages(data):
'''
加载图片数据用于训练
params:
data:训练数据所在的目录,要求图片尺寸一样
ret:
images:[m,height,width] m为样本数,height为高,width为宽
names:名字的集合
labels:标签
'''
images = []
names = []
labels = []
label = 0
# 遍历所有文件夹
for subdir in os.listdir(data):
# os.path.join 路径拼接
subpath = os.path.join(data, subdir)
# 判断是否是目录
if os.path.isdir(subpath):
# 在每一个文件夹中存放着一个人的许多照片
names.append(subdir)
# 遍历文件夹中的图片文件
for filename in os.listdir(subpath):
if filename.startswith("."):
continue
imgpath = os.path.join(subpath, filename)
img = cv2.imread(imgpath, cv2.IMREAD_COLOR)
gray_img = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
images.append(gray_img)
labels.append(label)
label += 1
images = np.asarray(images)
labels = np.asarray(labels)
return images, labels, names
# 检验训练结果
def FaceRec(data):
# 加载训练的数据
X, y, names = LoadImages(data)
model=cv2.face.EigenFaceRecognizer_create()
model.train(X, y)
# 打开摄像头
camera = cv2.VideoCapture(0)
cv2.namedWindow('faceRecognition')
# 创建级联分类器
face_casecade = cv2.CascadeClassifier('haarcascade_frontalface_default.xml')
while True:
# 读取一帧图像
# ret:图像是否读取成功
# frame:该帧图像
ret, frame = camera.read()
# 判断图像是否读取成功
# print('ret',ret)
if ret:
# 转换为灰度图
gray_img = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
# 利用级联分类器鉴别人脸
faces = face_casecade.detectMultiScale(gray_img, 1.3, 5)
# 遍历每一帧图像,画出矩形
for (x, y, w, h) in faces:
frame = cv2.rectangle(frame, (x, y), (x + w, y + h), (255, 0, 0), 2) # 蓝色
roi_gray = gray_img[y:y + h, x:x + w]
try:
# 将图像转换为宽64 高64的图像
# resize(原图像,目标大小,(插值方法)interpolation=,)
roi_gray = cv2.resize(roi_gray, (64, 64), interpolation=cv2.INTER_LINEAR)
params = model.predict(roi_gray)
print('Label:%s,confidence:%.2f' % (params[0], params[1]))
'''
putText:给照片添加文字
putText(输入图像,'所需添加的文字',左上角的坐标,字体,字体大小,颜色,字体粗细)
'''
cv2.putText(frame, names[params[0]], (x, y - 20), cv2.FONT_HERSHEY_SIMPLEX, 1, 255, 2)
except:
continue
cv2.imshow('人脸识别test', frame)
# 按下esc键退出
if cv2.waitKey(100) & 0xFF == 27:
break
camera.release()
cv2.destroyAllWindows()
if __name__ == '__main__':
data = "training-data"
FaceRec(data)人脸识别结果,终端输出的是此类的置信度。
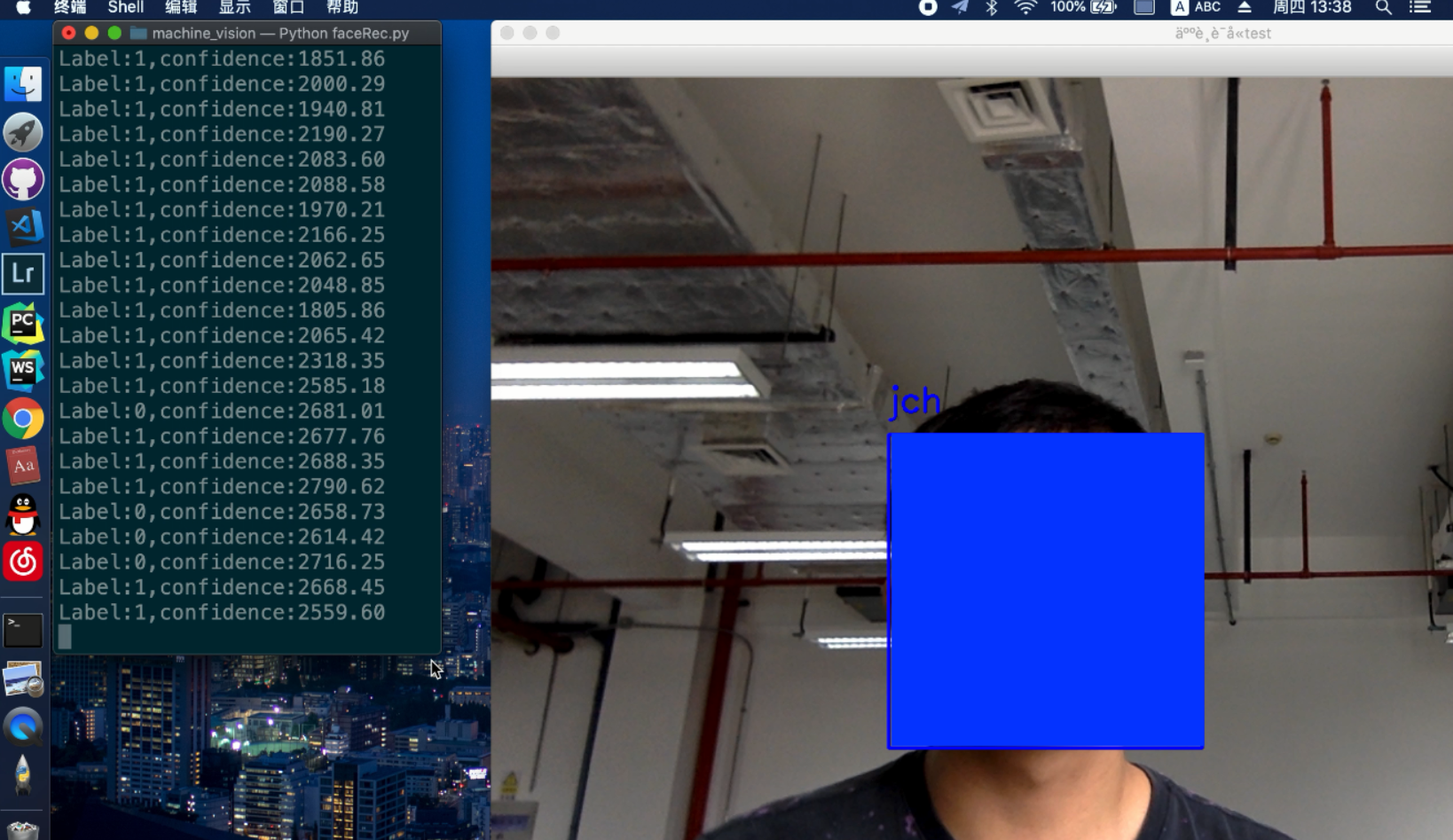
两类样本识别结果: